Data Lake#
Aerial CUDA-Accelerated RAN supports data capture for offline processing using logging, which is useful for debugging and performance analysis. It also captures richer control and data plane data in real time in Data Lake for offline and real-time usage.
Data captured from systems operating in realistic deployment conditions can be used offline to train AI/ML models. It can also be used in real time by dApps, written by 3rd parties to achieve new RAN functionality.
Data Lake is a real-time platform running on the O-DU platform that captures L1 and L2 data from O-RUs and the O-DU. It consists of a data capture application, a database to store samples collected by the application, and an API for accessing the database.
Key Features#
Data Lake has the following features:
Real-time capture of Fronthaul IO samples
The data passed to L2 via RX_Data.Indication and UL_TTI.Request are exported to the database.
API access to the database
Scalable and time coherent over arbitrary number of BSs
The data collection app runs on the same CPU that supports the DU. It runs on a single core, and the database runs on free cores. Because each gNB is responsible for collecting its own uplink data, the collection process scales as more gNBs are added to the network testbed. Database entries are time-stamped so data collected over multiple gNBs can be used in a training flow in a time-coherent manner.
Use in conjunction with pyAerial to generate training data for neural network physical layer designs
Data Lake can be used in conjunction with the NVIDIA pyAerial CUDA-Accelerated Python L1 library. Using the Data Lake database APIs, pyAerial can access RF samples in a Data Lake database and transform those samples into training data for all the signal processing functions in an uplink or downlink pipeline.
Use by dApps
dApps can use real-time data from the database to analyze system performance and/or to trigger real-time actions on the gNB based on the analysis.
Example: Training Data Generation Using pyAerial#
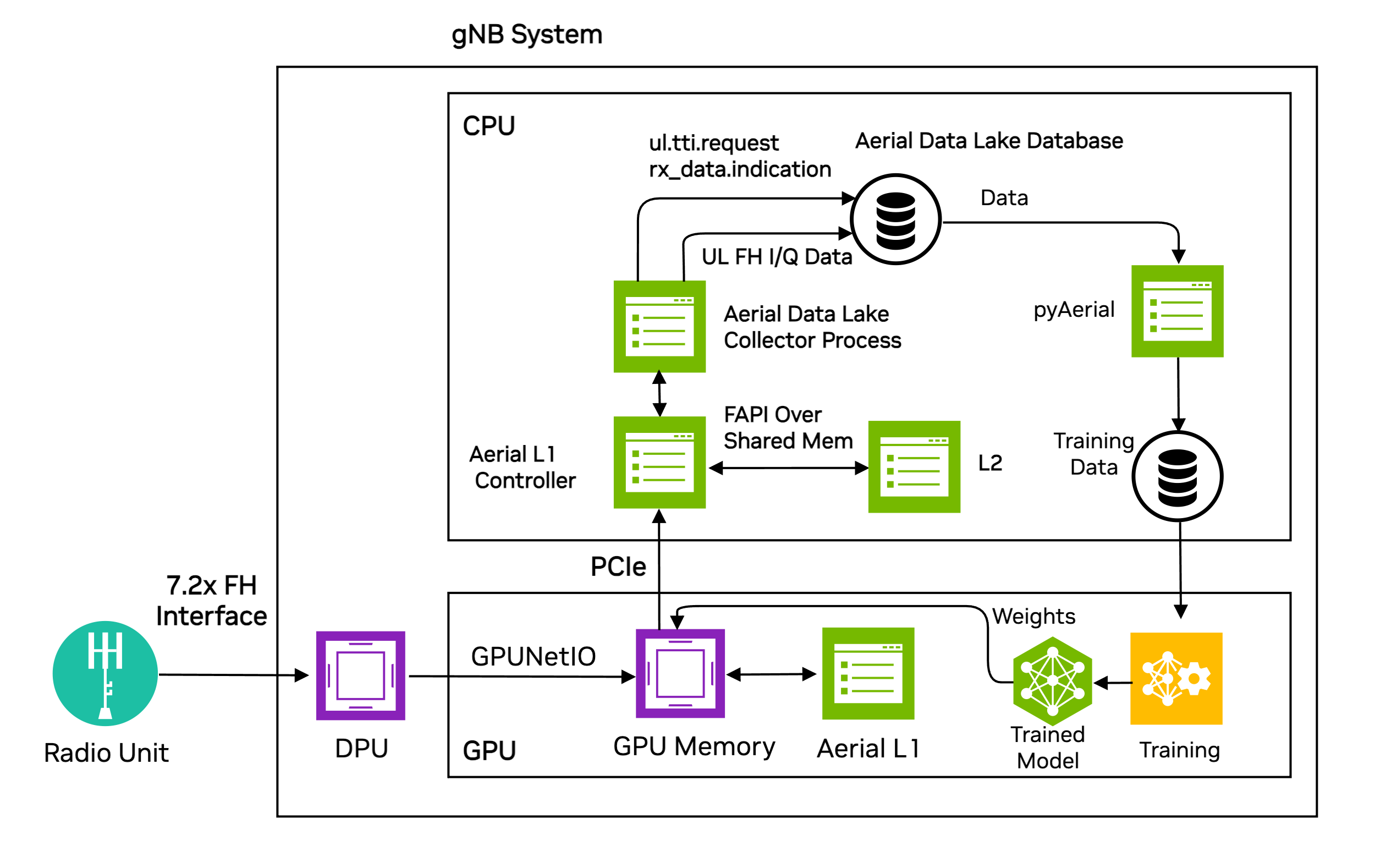
Figure 1: The Data Lake data capture and usage by pyAerial for model training#
Uplink I/Q data from one or more O-RAN radio units (O-RUs) is delivered
to GPU memory where it is both processed by the L1 PUSCH baseband
pipeline and delivered to host CPU memory. The Data Lake
collector process writes the I/Q samples to the Data Lake
database in the fh table.
The fh table has columns for SFN, Slot, IQ samples as fhData,
and the start time of that SFN.slot as TsTaiNs.
The collector app saves data that the L2 sent to L1 to describe UL OTA transmissions in UL_TTI.Request messages as well as data returned to the L2 via RX_Data.Indication and CRC.Indication. This data is then written to the fapi database table. These messages and the fields within them are described in SCF 5G FAPI PHY Spec version 10.02, sections 3.4.3, 3.4.7, and 3.4.8.
Each gNB in a network testbed collects data from all O-RUs associated with it. That is, data collection over the span of a network is performed in a distributed manner, each gNB is building its own local database. Training can be performed locally at each gNB, and site-specific optimizations can be realized with this approach. Since the data in a database is time-stamped, the local databases can be consolidated at a centralized compute resource and training performed using the time aligned aggregated data.
In cases where the PUSCH pipeline was unable to decode due to channel conditions, retransmissions can be used as ground truth as long as one of the retransmissions succeeds, allowing the user to test algorithms with better performance than the originals.
The Data Lake database storage requirements depend on the number of O-RUs, the antenna configuration of the O-RU, the carrier bandwidth, the TDD pattern and the number of samples to be collected. Collecting IQ samples of 1 million transmissions from a single RU 4T4R O-RU employing a single 100MHz carrier will consume approximately 660 GB of storage.
The Data Lake database comprises the fronthaul RF data. However, for many training applications access to data at other nodes in the receive pipeline is required. A pyAerial pipeline, together with the Data Lake database APIs, can access samples from an Data Lake database and transform that data into training data for any function in the pipeline.
Figure 2 illustrates data ingress from a Data Lake database into a pyAerial pipeline and using standard Python file I/O to generate training data for a soft de-mapper.
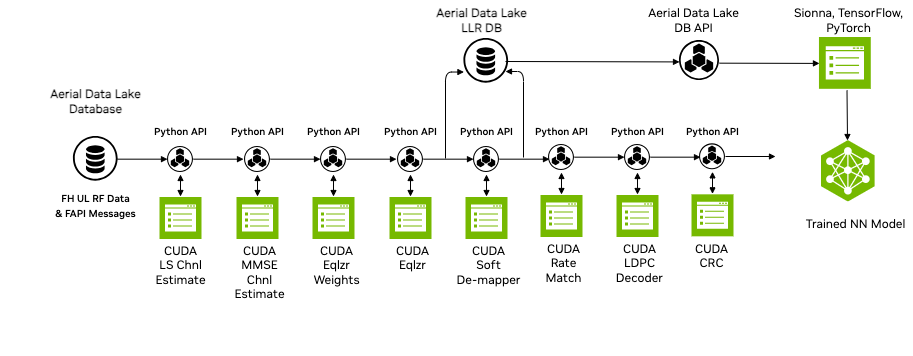
Figure 2: pyAerial and Data Lake data flow for building training datasets for a neural network soft de-mapper#
Installation#
Data Lake is compiled by default as part of cuphycontoller. To record fresh data every time cuphycontroller is started, refer to the section on Fresh Data.
Start by installing Clickhouse database on the server collecting the data. The command below will download and run an instance of the clickhouse server in a docker container.
docker run -d \
--network=host \
-v $(realpath ./ch_data):/var/lib/clickhouse/ \
-v $(realpath ./ch_logs):/var/log/clickhouse-server/ \
--cap-add=SYS_NICE --cap-add=NET_ADMIN --cap-add=IPC_LOCK \
--name my-clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server
By default clickhouse will not drop large tables, and may not return an error if attempted. The clickhouse-cpp library does not return exceptions so to avoid what looks like a cuphycontroller crash or hang we recommend allowing it to drop large tables using the following command:
sudo touch './ch_data/flags/force_drop_table' && sudo chmod 444 './ch_data/flags/force_drop_table'
Previously this was mode 666, but in that case clickhouse deletes the file after dropping a single large table.
Usage#
In the cuphycontoller adapter yaml configuration file, enable data collection by specifying a core then start cuphycontroller as usual. The core should be on the same NUMA node as the rest of cuphycontroller, i.e. should follow the same pattern as the rest of the cores. An example of this can be found commented out in cuphycontroller_P5G_FXN_GH.yaml. datalake_core is required.
cuphydriver_config:
data_config:
datalake_core: 19 # Core on which data collection runs. E.g isolated odd on R750, any isolated core on gigabyte
The following options are optional with functional defaults:
cuphydriver_config:
data_config:
# datalake_db_write_enable: 1 # Enable/disable ClickHouse writes based on datalake_data_types. Default: enabled
# datalake_samples: 1000000 # Number of samples to capture per UE (by RNTI)
# datalake_address: localhost
# datalake_engine: "MergeTree() PRIMARY KEY (TsTaiNs)" # Default: Memory()
# datalake_drop_tables: 0 # Set to 1 to drop Clickhouse tables at startup
# datalake_data_types: [fh, pusch, hest] # Data types to write to ClickHouse DB (all types always collected in memory for E3 Agent):
# fh = Fronthaul IQ samples,pusch = PUSCH/FAPI data, hest = channel estimates
# datalake_store_failed_pdu: 0 # Set to 1 to store PDU data even when CRC fails
# num_rows_fh: 120 # These set the number of samples to collect in memory before writing them to database.
# num_rows_pusch: 200 # Ideally these should have a large least common multiple so insertions do not occur simultaneously
# num_rows_hest: 140
Aerial 25-3 Adds the E3-Agent. To enable it:
cuphydriver_config:
data_config:
e3_agent_enable: 1 # Enable/disable E3 Agent and dApp capabilities
# e3_pub_port: 5555 # E3 publisher port for indication messages
# e3_rep_port: 5556 # E3 reply port for E3AP requests
# e3_sub_port: 5560 # E3 subscriber port for Manager messages
When enabled the DataLake object is created and DataLake::dbInit() initializes the two tables in the database. After cuphycontroller runs the PUSCH pipeline, cupycontroller calls DataLake::notify() with the addresses of the data to be saved, which DataLake then saves. When DataLake::waitForLakeData wakes up it calls DataLake::dbInsert() which appends data to respective Clickhouse columns, then sleeps waiting for more data. Once 50 PUSCH transmissions have been stored or a total of datalake_samples have been received the columns are appended to a Clickhouse::Block and inserted into the respective table.
Multi-Cell#
Data Lake can be configured to capture data from multiple cells controlled by the same L1. The Jupyter notebook datalake_pusch_multicell.ipynb shows an example of
using data captured from multiple cells. To capture the data for this example, cell 41 was controlled by testmac and cell 51 was controlled by a real L2.
In order to do this the cuphycontroller L2 interface needs to be configured to work with two cells and L2s, and testmac needs to be configured to use /dev/shm/nvipc1
rather than /dev/shm/nvipc. L2 should use the slot pattern DDDSU. Core allocations will need to be adjusted to suite the server being used.
Using Data Lake in Notebooks#
Follow pyAerial instructions to build and launch that container. It must be run on a server with a GPU.
datalake_channel_estimation.ipynb performs channel estimation and plots the result.datalake_pusch_decoding.ipynb goes further and runs the full PUSCH decoding pipeline, both a fused version and a version built up of constituent parts.datalake_pusch_multicell.ipynb shows an example of trying to decode the same transmissions from multiple UEs across two cells.See the pyAerial examples section for details.
Database Administration#
Note
$
and this denotes a clickhouse client prompt
aerial-gnb :)
Database Import#
There are example fapi and fh tables included in Aerial CUDA-Accelerated RAN container. These tables can be imported into the clickhouse database by copying them from the container to the clickhouse user_files folder, then using the client to import them:
$ docker cp cuBB:/opt/nvidia/cuBB/pyaerial/notebooks/data/fh.parquet .
$ docker cp cuBB:/opt/nvidia/cuBB/pyaerial/notebooks/data/fapi.parquet .
$ sudo cp *.parquet ./ch_data/user_files/
A clickhouse client is needed to interact with the server. To download it and run it do the following:
curl https://clickhouse.com/ | sh
./clickhouse client
aerial@aerial-gnb:~$ ./clickhouse client
ClickHouse client version 24.3.1.1159 (official build).
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 24.3.1.
aerial-gnb :)
This is the clickhouse client prompt. Use the client to import the sample data into the clickhouse server using these commands:
aerial-gnb :) create table fh ENGINE = MergeTree primary key TsTaiNs settings allow_nullable_key=1 as select * from file('fh.parquet',Parquet)
aerial-gnb :) create table fapi ENGINE = MergeTree primary key TsTaiNs settings allow_nullable_key=1 as select * from file('fapi.parquet',Parquet)
Now check that they have been imported:
aerial-gnb :) select table, formatReadableSize(sum(bytes)) as size from system.parts group by table
The output will look similar to this:
SELECT
`table`,
formatReadableSize(sum(bytes)) AS size
FROM system.parts
GROUP BY `table`
Query id: 95451ea7-6ea9-4eec-b297-15de78036ada
┌─table───────────────────┬─size───────┐
│ fh │ 5.55 MiB │
│ fapi │ 3.88 KiB │
└─────────────────────────┴────────────┘
There are now three slots of PUSCH transmissions from 5-6 real UEs recieved by two cells loaded in the database. The example notebooks can be run after this.
Database Queries#
Run the following at the clickhouse client prompt to show some information about the entries (rows). This shows counts of transmissions for all RNTIs:
aerial-gnb :) select rnti, count(*) from fapi group by rnti
The output will look similar to this:
SELECT
rnti,
count(*)
FROM fapi
GROUP BY rnti
Query id: 603141a2-bc02-4950-8e9e-1d3f366263c6
┌──rnti─┬─count()─┐
│ 1624 │ 3 │
│ 20000 │ 3 │
│ 20216 │ 3 │
│ 47905 │ 2 │
│ 53137 │ 2 │
│ 57375 │ 3 │
│ 62290 │ 3 │
└───────┴─────────┘
Use the following command to select information from all rows of the fapi table:
aerial-rf-gnb :) from fapi select TsTaiNs,SFN,Slot,nUEs,rbStart,rbSize,tbCrcStatus,CQI order by TsTaiNs,rbStart
Output:
SELECT
TsTaiNs,
SFN,
Slot,
nUEs,
rbStart,
rbSize,
tbCrcStatus,
CQI
FROM fapi
ORDER BY
TsTaiNs ASC,
rbStart ASC
Query id: f42d9192-1de1-4cc6-b3eb-932b22ecab3e
┌───────────────────────TsTaiNs─┬─SFN─┬─Slot─┬─nUEs─┬─rbStart─┬─rbSize─┬─tbCrcStatus─┬───────CQI─┐
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 0 │ 8 │ 1 │ -7.352562 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 0 │ 5 │ 0 │ 31.75534 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 5 │ 5 │ 0 │ 30.275444 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 10 │ 5 │ 0 │ 31.334328 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 15 │ 5 │ 0 │ 30.117304 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 20 │ 5 │ 0 │ 29.439499 │
│ 2024-07-19 10:42:46.272000000 │ 391 │ 4 │ 7 │ 25 │ 248 │ 0 │ 25.331459 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 0 │ 8 │ 1 │ -7.845479 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 0 │ 5 │ 0 │ 29.412682 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 5 │ 5 │ 0 │ 30.186537 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 10 │ 5 │ 0 │ 30.366463 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 15 │ 5 │ 0 │ 29.590645 │
│ 2024-07-19 10:42:47.292000000 │ 493 │ 4 │ 6 │ 20 │ 253 │ 0 │ 28.494812 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 0 │ 8 │ 1 │ -8.030928 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 0 │ 5 │ 0 │ 31.359173 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 5 │ 5 │ 0 │ 30.353489 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 10 │ 5 │ 0 │ 29.3033 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 15 │ 5 │ 0 │ 28.298597 │
│ 2024-07-19 10:42:48.212000000 │ 585 │ 4 │ 6 │ 20 │ 253 │ 0 │ 26.621593 │
└───────────────────────────────┴─────┴──────┴──────┴─────────┴────────┴─────────────┴───────────┘
19 rows in set. Elapsed: 0.002 sec.
Use the following command to show start times of the fh table:
aerial-rf-gnb :) from fh select TsTaiNs,TsSwNs,SFN,Slot,CellId,nUEs
The output will look similar to this:
SELECT
TsTaiNs,
TsSwNs,
SFN,
Slot,
CellId,
nUEs
FROM fh
Query id: 6926d88e-6e9c-4818-b127-aef96913cfc0
┌───────────────────────TsTaiNs─┬────────────────────────TsSwNs─┬─SFN─┬─Slot─┬─CellId─┬─nUEs─┐
│ 2024-07-19 10:42:46.272000000 │ 2024-07-19 10:42:46.273113183 │ 391 │ 4 │ 41 │ 7 │
│ 2024-07-19 10:42:46.272000000 │ 2024-07-19 10:42:46.273113183 │ 391 │ 4 │ 51 │ 7 │
│ 2024-07-19 10:42:47.292000000 │ 2024-07-19 10:42:47.293139202 │ 493 │ 4 │ 41 │ 6 │
│ 2024-07-19 10:42:47.292000000 │ 2024-07-19 10:42:47.293139202 │ 493 │ 4 │ 51 │ 6 │
│ 2024-07-19 10:42:48.212000000 │ 2024-07-19 10:42:48.213139622 │ 585 │ 4 │ 41 │ 6 │
│ 2024-07-19 10:42:48.212000000 │ 2024-07-19 10:42:48.213139622 │ 585 │ 4 │ 51 │ 6 │
└───────────────────────────────┴───────────────────────────────┴─────┴──────┴────────┴──────┘
6 rows in set. Elapsed: 0.002 sec.
Fresh Data#
The database of IQ samples grows quite quickly. To get fresh data on every run,
you can automatically remove the tables by uncommenting the following lines in
cuPHY-CP/data_lakes/data_lakes.cpp:
//dbClient->Execute("DROP TABLE IF EXISTS fapi");
//dbClient->Execute("DROP TABLE IF EXISTS fh");
Dropping Data#
Drop all of the data from the database with these commands:
aerial-gnb :) drop table fh
aerial-gnb :) drop table fapi
Notes and Known Limitations#
Currently Data Lake converts complex half floating point values to floats in c++ which takes ~2ms per cell. During that time, when samples are being inserted into the database, PUSCH notifications can be missed and a note will be printed in the phy log:
[CTL.DATA_LAKE] Notify not called for 39.4 dbInsert busy