

Blob Downloader
Blob Downloader
Blob downloader is AIStore’s facility for downloading large remote objects (BLOBs) using concurrent range-reads.
Instead of pulling a 10–100+ GiB object with a single sequential stream, blob downloader:
- splits the object into chunks (configurable chunk size),
- fetches those chunks in parallel from the remote backend (configurable number of workers),
- writes them directly into AIStore’s chunked object layout so all target disks are writing in parallel, effectively aggregating the full disk write bandwidth of the node.
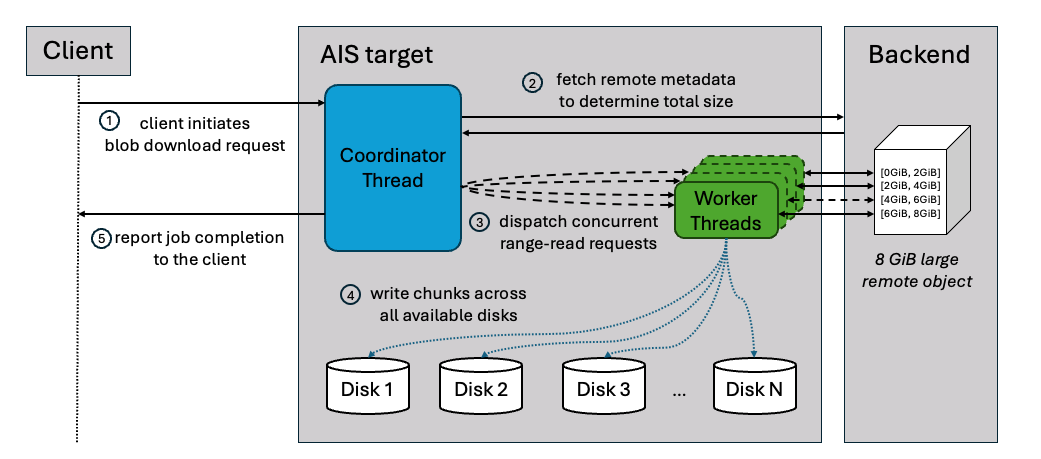
The result is that, beyond a certain object size, blob downloader can deliver much higher throughput than a regular cold GET. In our internal benchmarks, a 4 GiB S3 object fetched with blob downloader was up to 4× faster than a monolithic cold GET.
Blob downloader is also load‑aware: it consults AIStore’s internal load advisors to avoid overcommitting memory or disks, backing off when the node is under pressure and running at full speed when the system has headroom.
For a deeper dive into the internals and detailed benchmarks, see the blog post.
Usage
AIStore exposes blob download functionality through three distinct interfaces, each suited to different use cases.
- Single object blob-download job – explicitly start a blob-download job for one or more objects.
- Prefetch + blob-threshold – route large objects in the prefetch job through blob downloader.
- Streaming GET – stream a large object from blob downloader while it is being cached in AIS.
1. Single object blob-download job
Use this when you want direct control over which/how objects are fetched with blob downloader.
Help and options:
Examples:
-
Single large object
-
Multiple objects in one job
2. Prefetch with blob-threshold
prefetch is AIStore’s multi‑object “warm‑up” job for remote buckets. When you add a blob size threshold, it automatically decides which objects are large enough to benefit from blob downloader:
- Objects ≥
--blob-thresholdare fetched via blob downloader (parallel range‑reads, chunked writes). - Objects <
--blob-thresholdare fetched with the normal cold GET path.
This lets you get the large‑object gains of blob downloader by just tuning prefetch’s knobs.
Example:
Key prefetch options:
--blob-threshold SIZE: turn blob downloader on for objects at/aboveSIZE.--blob-chunk-size SIZE(if available in your build): override default blob chunk size for this prefetch.--prefix/--list/--template: scope which objects are prefetched.
3. Streaming GET (Python SDK Only)
In addition to CLI jobs, blob downloader can be used to stream large objects while they are concurrently downloaded in the cluster. This is useful when you want to feed data directly into an application (for example, model loading or preprocessing) and still keep a local cached copy in AIS.
Selecting an effective blob-threshold for prefetch
The ideal --blob-threshold depends on your cluster (CPU, disks, network), backend (S3/GCS/…), and object size distribution.
Running full prefetch experiments for many candidate values can easily take hours, so instead we recommend using a shorter single‑object blob-download benchmark to pick a good starting point and then using that value directly in your prefetch job.
To do this in practice, compare cold GET vs. blob-download on a single object:
-
Pick a representative large remote object in your bucket (for example, a model shard or big archive).
-
Evict it from AIStore to ensure a cold path:
-
Measure cold GET time for that object:
-
Measure blob-download time for the same object:
-
Repeat the above for a few object sizes (for example: 64 MiB, 256 MiB, 1 GiB, 4 GiB) until you see a pattern:
- Below some size, cold GET is as fast or faster (blob overhead dominates).
- Above that size, blob-download is consistently faster.
The crossover size where blob-download wins is your blob-threshold for prefetch: use that size as --blob-threshold when you run your real ais prefetch job. This single‑object comparison gives you a quick, reasonable approximation.
In our internal 1.56 TiB S3 benchmark, applying this method led us to a threshold of about 256 MiB. This value provided the best trade‑off for that specific cluster and workload and delivered roughly 2.3× faster end‑to‑end prefetch compared to a pure cold‑GET baseline.