SDK Sample Applications
This section explains how the user can run the Clara Holoscan sample apps. The sample apps include
tool tracking in endoscopy video using an LSTM model
semantic segmentation bone contours with hyperechoic lines
Each app comes with support for an AJA capture card or replay from a video file included in the sample app container.
The Endoscopy tool tracking application provides an example of how an endoscopy data stream can be captured and processed using the GXF framework on multiple hardware platforms.
Input source: Video Stream Replayer
The GXF pipeline in a graph form is defined at apps/endoscopy_tool_tracking/tracking_replayer.yaml in Holoscan Embedded SDK Github Repository.
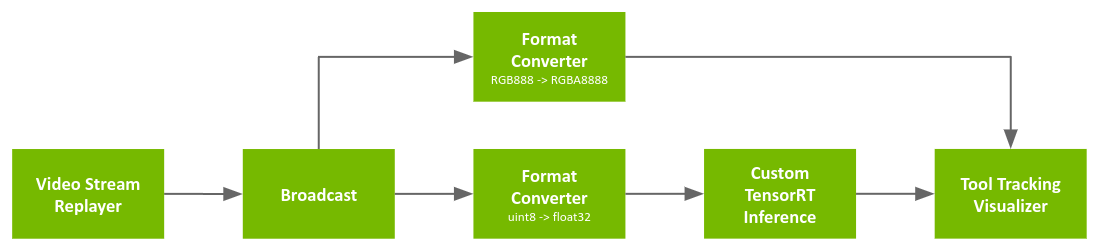
Fig. 3 Tool tracking app with replay from file
The pipeline uses a recorded endoscopy video file (generated by convert_video_to_gxf_entities script) for input frames.
Each input frame in the file is loaded by Video Stream Replayer and Broadcast node passes the frame to the following two nodes (Entities):
Format Converter: Convert image format from
RGB888(24-bit pixel) toRGBA8888(32-bit pixel) for visualization (Tool Tracking Visualizer)Format Converter: Convert the data type of the image from
uint8tofloat32for feeding into the tool tracking model (by Custom TensorRT Inference)
Then, Tool Tracking Visualizer uses outputs from the first Format Converter and Custom TensorRT Inference to render overlay frames (mask/point/text) on top of the original video frames.
To run the Endoscopy Tool Tracking Application with the recorded video as source, run the following commands after setting up the Holoscan SDK:
In the container runtime (from NGC):
cd /opt/holoscan_sdk/tracking_replayer
./apps/endoscopy_tool_tracking/run_tracking_replayer
In the development container (from source):
cd /workspace/holoscan-sdk/build
./apps/endoscopy_tool_tracking/tracking_replayer
Input source: AJA
The GXF pipeline in a graph form is defined at apps/endoscopy_tool_tracking/tracking_aja.yaml in Holoscan Embedded SDK Github Repository.
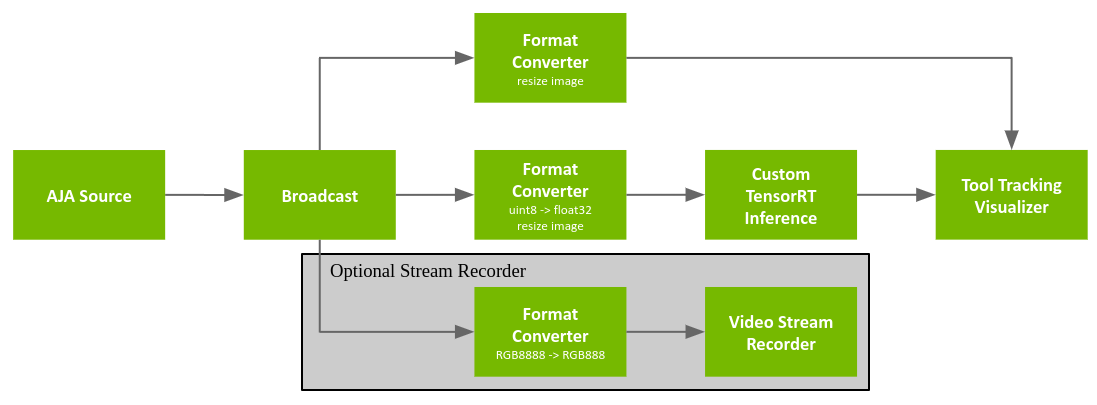
Fig. 4 AJA tool tracking app
The pipeline is similar with Input source: Video Stream Replayer but the input source is replaced with AJA Source.
The pipeline graph also defines an optional Video Stream Recorder that can be enabled to record the original video stream to disk. This stream recorder (and its associated Format Converter) are commented out in the graph definition and thus are disabled by default in order to maximize performance. To enable the stream recorder, uncomment all of the associated components in the graph definition.
AJA Source: Get video frame from AJA HDMI capture card (pixel format is
RGBA8888with the resolution of 1920x1080)Format Converter: Convert image format from
RGB8888(32-bit pixel) toRGBA888(24-bit pixel) for recording (Video Stream Recorder)Video Stream Recorder: Record input frames into a file
Please follow these steps to run the Endoscopy Tool Tracking Application:
To run the Endoscopy Tool Tracking Application with AJA capture, run the following commands after setting up the Holoscan SDK and your AJA system:
In the container runtime (from NGC):
cd /opt/holoscan_sdk/tracking_aja
./apps/endoscopy_tool_tracking/run_tracking_aja
In the development container (from source):
cd /workspace/holoscan-sdk/build
./apps/endoscopy_tool_tracking/tracking_aja
This section will describe the details of the ultrasound segmentation example app as well as how to load a custom inference model into the app for some limited customization. Out of the box, the ultrasound segmentation app comes as a “video replayer” and “AJA source”, where the user can replay a pre-recorded ultrasound video file included in the runtime container or stream data from an AJA capture device directly through the GPU respectively.
Input source: Video Stream Replayer
The replayer pipeline is defined in apps/ultrasound_segmentation/segmentation_replayer.yaml in Holoscan Embedded SDK Github Repository.

Fig. 5 Segmentation app with replay from file
The pipeline uses a pre-recorded endoscopy video stream stored in nvidia::gxf::Tensor format as input. The tensor-formatted file is generated via convert_video_to_gxf_entities from a pre-recorded MP4 video file.
Input frames are loaded by Video Stream Replayer and Broadcast node passes the frame to two branches in the pipeline.
In the inference branch the video frames are converted to floating-point precision using the format converter, pixel-wise segmentation is performed, and the segmentation result if post-processed for the visualizer.
The visualizer receives the original frame as well as the result of the inference branch to show an overlay.
To run the Ultrasound Segmentation Application with the recorded video as source, run the following commands after setting up the Holoscan SDK:
In the container runtime (from NGC):
cd /opt/holoscan_sdk/segmentation_replayer
./apps/ultrasound_segmentation/run_segmentation_replayer
In the development container (from source):
cd /workspace/holoscan-sdk/build
./apps/ultrasound_segmentation/segmentation_replayer
Input source: AJA
The AJA pipeline is defined in apps/ultrasound_segmentation/segmentation_aja.yaml in Holoscan Embedded SDK Github Repository.

Fig. 6 AJA segmentation app
This pipeline is exactly the same as the pipeline described in the previous section except the Video Stream Replayer has been substituted with an AJA Video Source.
To run the Ultrasound Segmentation Application with AJA capture, run the following commands after setting up the Holoscan SDK and your AJA system:
In the container runtime (from NGC):
cd /opt/holoscan_sdk/segmentation_aja
./apps/ultrasound_segmentation/run_segmentation_aja
In the development container (from source):
cd /workspace/holoscan-sdk/build
./apps/ultrasound_segmentation/segmentation_aja
Customizing the Sample Ultrasound Segmentation App
This section will show how the user can trivially update the model in the sample ultrasound segmentation app. The runtime containers contain only binaries of the sample applications therefore the users may not modify the extensions, however, the users can substitute the ultrasound model with their own and add, remove, or replace the extensions used in the application.
For a comprehensive guide on building your own Holoscan extensions and apps please refer to Clara Holoscan Development Guide.
The sample ultrasound segmentation model expects a gray-scale image of 256 x 256 and outputs a semantic segmentation of the same size with two channels representing bone contours with hyperechoic lines (foreground) and hyperechoic acoustic shadow (background).
Currently, the sample apps are able to load ONNX models, or TensorRT engine files built for the architecture on which you will be running the model only. TRT engines are automatically generated from ONNX by the app when it is run.
Assuming a single-input/single-output custom model we can trivially substitute the model in the application as follows.
Enter the sample app container, but ensure to load your model from the host into the container. Assuming your model is in
${my_model_path_dir}and your data is in${my_data_path_dir}then you can execute the following:docker run -it --rm --runtime=nvidia \ -e NVIDIA_DRIVER_CAPABILITIES=graphics,video,compute,utility \ -v ${my_model_path_dir}:/workspace/my_model \ -v ${my_data_path_dir}:/workspace/my_data \ -v /tmp/.X11-unix:/tmp/.X11-unix \ -e DISPLAY=${DISPLAY} \ nvcr.io/nvidia/clara-holoscan/clara_holoscan_sample_runtime:0.2.0-arm64
Check that the model and data correctly appear under
/workspace/my_modeland/workspace/my_data.Now we are ready to make small modifications to the ultrasound sample app to have the new model load.
cd /opt/holoscan_sdk/segmentation_replayer/ vi ./apps/ultrasound_segmentation/segmentation_replayer.yaml
In the editor navigate to the
segmentation_inferenceentity. In this entity, the component we will modify isnvidia::gxf::TensorRtInferencewhere we want to specify the input and output names.a. In line
146specify the names of the inputs specified in your model underinput_binding_names. In the case of ONNX models converted from PyTorch inputs names take the formINPUT__0.b. In line
150specify the names of the inputs specified in your model underoutput_binding_names. In the case of ONNX models converted from PyTorch inputs names take the formOUTPUT__0.Assuming the custom model input and output bindings are
MY_MODEL_INPUT_NAMEandMY_MODEL_OUTPUT_NAME, thenvidia::gxf::TensorRtInferencecomponent would result in:- type: nvidia::gxf::TensorRtInference parameters: input_binding_names: - MY_MODEL_INPUT_NAME output_binding_names: - MY_MODEL_OUTPUT_NAME
TipThe
nvidia::gxf::TensorRtInferencecomponent binds the names of the Holoscan component inputs to the model inputs via theinput_tensor_namesandinput_binding_nameslists, where the first specifies the name of the tensor used by the Holoscan componentnvidia::gxf::TensorRtInferenceand the latter specifies the name of the model input. Similarly,output_tensor_namesandoutput_binding_nameslink the component output names to the model output (see extensions).To be able to play the desired video through the custom model we first need to convert the video file into a GXF replayable tensor format. In the container perform the following actions.
apt update && DEBIAN_FRONTEND=noninteractive apt install -y ffmpeg cd /workspace git clone https://github.com/NVIDIA/clara-holoscan-embedded-sdk.git cd clara-holoscan-embedded-sdk/scripts ffmpeg -i /workspace/my_data/${my_video} -pix_fmt rgb24 -f rawvideo pipe:1 | python3 convert_video_to_gxf_entities.py --width ${my_width} --height ${my_height} --directory /workspace/my_data --basename my_video
The above commands should yield two Holoscan tensor replayer files in
/workspace/my_data, namelymy_video.gxf_indexandmy_video.gxf_entities. These will be used to run the app in the next step.Update the
sourceentity (line3) to read from the newly generated tensor data. In the./apps/ultrasound_segmentation/segmentation_replayer.yamlfile, update lines22,23with the path and basename used in the data generation.name: source components: - type: nvidia::holoscan::stream_playback::VideoStreamReplayer parameters: directory: "/workspace/my_data" basename: "my_video"
Run the application with the new model and data.
cd /opt/holoscan_sdk/segmentation_replayer/ ./apps/ultrasound_segmentation/run_segmentation_replayer