Overview
NVIDIA Clara Holoscan is the AI computing platform for medical devices, consisting of Clara Developer Kits and the Clara Holoscan SDK. Clara Holoscan allows medical device developers to create the next-generation of AI-enabled medical devices and take it to the market using Clara Holoscan MGX.
The Clara Holoscan SDK version 0.2.0 provides the foundation to run streaming applications on Clara Developer Kits, enabling real-time AI inference and fast IO. These capabilities are showcased within the reference extensions and applications described below.
Extensions
The core of the Clara Holoscan SDK is implemented within extensions. The extensions packaged in the SDK cover tasks such as IO, inference, image processing, and visualization. They rely on a set of Core Technologies highlighted below.
This guide will provide more information on the existing extensions, and how to create your own.
Applications
This SDK includes two sample applications to show how users can implement their own end-to-end inference pipeline for streaming use cases. This guide provides detailed information on the inner-workings of those applications, and how to create your own.
See below for some information regarding the two sample applications:
Ultrasound Segmentation
Generic visualization of segmentation results based on a spinal scoliosis segmentation model of ultrasound videos. The model used is stateless, so this workflow could be configured to adapt to any vanilla DNN model. This guide will provide more details on the inner-workings of the Ultrasound Segmentation application and how to adjust it to use your own data.
The model is from a King’s College London research project, created by Richard Brown and released under the Apache 2.0 license.
The ultrasound dataset is released under the CC BY 4.0 license. When using this data, please cite the following paper:
Ungi et al., “Automatic Spine Ultrasound Segmentation for Scoliosis Visualization and Measurement,” in IEEE Transactions on Biomedical Engineering, vol. 67, no. 11, pp. 3234-3241, Nov. 2020, doi: 10.1109/TBME.2020.2980540.
Refer to the sample data resource on NGC for more information related to the model and video.
Endoscopy Tool Tracking
Leveraging a long-short term memory (LSTM) stateful model, this application demonstrate the use of custom components for surgical tool tracking and classification, as well as composition and rendering of text, tool position, and mask (as heatmap) overlayed on the original frames. This guide provides more details on the inner-workings of the Endoscopy Tool Tracking application.
The convolutional LSTM model and sample surgical video data were kindly provided by Research Group Camma, IHU Strasbourg & University of Strasbourg:
Nwoye, C.I., Mutter, D., Marescaux, J. and Padoy, N., 2019. Weakly supervised convolutional LSTM approach for tool tracking in laparoscopic videos. International journal of computer assisted radiology and surgery, 14(6), pp.1059-1067
Refer to the sample data resource on NGC for more information related to the model and video.
Video Pipeline Latency Tool
To help developers make sense of the overall end-to-end latency that could be added to a video stream by augmenting it through a GPU-powered Holoscan platform such as the Clara Holoscan Developer Kit, the Holoscan SDK includes a Video Pipeline Latency Measurement Tool. This tool can be used to measure and estimate the total end-to-end latency of a video streaming application including the video capture, processing, and output using various hardware and software components that are supported by Clara Holoscan platforms. The measurements taken by this tool can then be displayed with a comprehensive and easy-to-read visualization of the data.
The following table outlines the component versions that have been upgraded or removed in version 0.2.0:
Component |
Holoscan 0.2.0 |
Holoscan 0.1.0 |
|---|---|---|
JetPack |
5.0 HP1 |
4.5 |
Jetson Linux |
34.1.2 |
32.5 |
Ubuntu |
20.04 |
18.04 |
dGPU Drivers |
510.73.08 |
465 |
CUDA |
11.6.1 |
11.1 |
TensorRT |
8.2.3 |
7.2.2 |
cuDNN |
8.3.3.40 |
8.0 |
GXF |
2.4.2 |
- |
DeepStream |
- |
5.0 |
GXF Relative to DeepStream
The most significant change in Holoscan 0.2.0 is the shift of the core backend from Deepstream to NVIDIA’s Graphical eXecution Framework (GXF) for improved latency of real-time streaming applications in healthcare settings.
While DeepStream is built on top of GStreamer and is primarily focused on audio and video streams, GXF provides much more flexibility as it can support any type of streaming data and can be used in endoscopy, ultrasound, genomics, microscopy, robotics, and more. This user guide goes into more details on GXF’s core and how to leverage it.
Release Artifacts
The delivery and installation method used by Holoscan 0.2.0 has also changed. Components that were once installed as Debian packages by SDK Manager are now provided via open-source GitHub repositories and/or container images on the NVIDIA GPU Cloud (NGC). These repositories and container images will be documented in the relevant sections throughout this documentation.
Clara Holoscan accelerates streaming AI applications by leveraging both hardware and software. On the software side, the Clara Holoscan SDK 0.2.0 relies on multiple core technologies to achieve low latency and high throughput, including:
The GXF Framework
At its core, GXF provides a very thin API with a plug-in model to load in custom extensions. Applications built on top
of GXF are composed of components. The primary component is a Codelet that provides an interface for
start(), tick(), and stop() functions. Configuration parameters are bound within the
registerInterface() function.
In addition to the Codelet class, there are several others providing the underpinnings of Holoscan:
Scheduler and Scheduling Terms: components that determine how and when the tick() of a Codelet executes. This can be single or multithreaded, support conditional execution, asynchronous scheduling, and other custom behavior.
Memory Allocator: provides a system for up-front allocating a large contiguous memory pool and then re-using regions as needed. Memory can be pinned to the device (enabling zero-copy between Codelets when messages are not modified) or host or customized for other potential behavior.
Transmitters, Receivers, and Message Router: a message passing system between Codelets that supports zero-copy.
Tensor: the common message type is a tensor. It provides a simple abstraction for numeric data that can be allocated, serialized, sent between Codelets, etc. Tensors can be rank 1 to 7 supporting a variety of common data types like arrays, vectors, matrices, multi-channel images, video, regularly sampled time-series data, and higher dimensional constructs popular with deep learning flows.
Parameters: configuration variables that specify constants used by the Codelet loaded from the application yaml file modifiable without recompiling.
GPUDirect RDMA
Copying data between a third party PCIe device and a GPU traditionally requires two DMA operations: first the data is copied from the PCIe device to system memory, then it’s copied from system memory to the GPU.
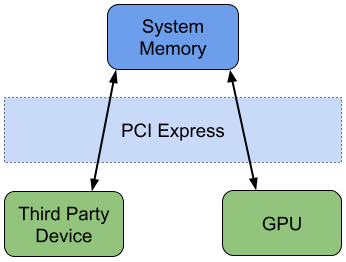
Fig. 1 Data Transfer Between PCIe Device and GPU Without GPUDirect RDMA
For data that will be processed exclusively by the GPU, this additional data copy to system memory goes unused and wastes both time and system resources. GPUDirect RDMA optimizes this use case by enabling third party PCIe devices to DMA directly to or from GPU memory, bypassing the need to first copy to system memory.
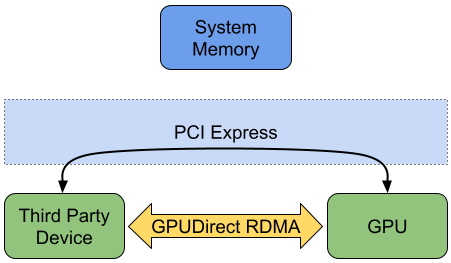
Fig. 2 Data Transfer Between PCIe Device and GPU With GPUDirect RDMA
NVIDIA takes advantage of RDMA in many of its SDKs, including Rivermax for GPUDirect support with ConnectX network adapters, and GPUDirect Storage for transfers between a GPU and storage device. NVIDIA is also committed to supporting hardware vendors enable RDMA within their own drivers, an example of which is provided by AJA Video Systems as part of a partnership with NVIDIA for the Clara Holoscan SDK. The AJASource extension is an example of how the SDK can leverage RDMA.
For more information about GPUDirect RDMA, see the following:
Minimal GPUDirect RDMA Demonstration source code, which provides a real hardware example of using RDMA and includes both kernel drivers and userspace applications for the RHS Research PicoEVB and HiTech Global HTG-K800 FPGA boards.
TensorRT Optimized Inference
NVIDIA TensorRT is a deep learning inference framework based on CUDA that provided the highest optimizations to run on NVIDIA GPUs, including the Clara Developer Kits.
GXF comes with a TensorRT base extension which is extended in the Holoscan SDK: the updated TensorRT extension is able to selectively load a cached TensorRT model based on the system GPU specifications, making it ideal to interface with both the Clara AGX Developer Kit and the Clara Holoscan Developer Kit.
CUDA and OpenGL Interoperability
OpenGL is commonly used for realtime visualization, and like CUDA, is executed on the GPU. This provides an opportunity for efficient sharing of resources between CUDA and OpenGL.
The OpenGL and Segmentation Visualizer extensions use the OpenGL interoperability functions provided by the CUDA runtime API. This API is documented further in the CUDA Toolkit Documentation
This concept can be extended to other rendering frameworks such as Vulkan.
Accelerated Image Transformations
Streaming image processing often requires common 2D operations like resizing, converting bit widths, and changing color formats. NVIDIA has built the CUDA accelerated NVIDIA Performance Primitive Library (NPP) that can help with many of these common transformations. NPP is extensively showcased in the Format Converter extension of the Clara Holoscan SDK.