4.11. Asynchronous Data Copies#
Building on Section 3.2.5, this section provides detailed guidance and examples for asynchronous data movement within the GPU memory hierarchy. It covers LDGSTS for element-wise copies, the Tensor Memory Accelerator (TMA) for bulk (one-dimensional and multi-dimensional) transfers, and STAS for register to distributed shared memory copies, and shows how these mechanisms integrate with asynchronous barriers and pipelines.
4.11.1. Using LDGSTS#
Many CUDA applications require frequent data movement between global and shared memory. Often, this involves copying smaller data elements or performing irregular memory access patterns. The primary goal of LDGSTS (CC 8.0+, see PTX documentation) is to provide an efficient asynchronous data transfer mechanism from global memory to shared memory for smaller, element-wise data transfers while enabling better utilization of compute resources through overlapped execution.
Dimensions. LDGSTS supports copying 4, 8, or 16 bytes. Copying 4 or 8 bytes always happens in the so called L1 ACCESS mode, in which case data is also cached in the L1, while copying 16-bytes enables the L1 BYPASS mode, in which case the L1 is not polluted.
Source and destination. The only direction supported for asynchronous copy operations with LDGSTS is from global to shared memory. The pointers need to be aligned to 4, 8, or 16 bytes depending on the size of the data being copied. Best performance is achieved when the alignment of both shared memory and global memory is 128 bytes.
Asynchronicity. Data transfers using LDGSTS are asynchronous and are modeled as async thread operations (see Async Thread and Async Proxy). This allows the initiating thread to continue computing while the hardware asynchronously copies the data. Whether the data transfer occurs asynchronously in practice is up to the hardware implementation and may change in the future.
LDGSTS must provide a signal when the operation is complete. LDGSTS can use shared memory barriers or pipelines as mechanisms to provide completion signals. By default, each thread only waits for its own LDGSTS copies. Thus, if you use LDGSTS to prefetch some data that will be shared with other threads, a __syncthreads() is necessary after synchronizing with the LDGSTS completion mechanism.
Direction |
Asynchronous Copy (LDGSTS, CC 8.0+) |
||
|---|---|---|---|
Source |
Destination |
Completion Mechanism |
API |
global |
global |
||
shared::cta |
global |
||
global |
shared::cta |
shared memory barrier, pipeline |
|
global |
shared::cluster |
||
shared::cluster |
shared::cta |
||
shared::cta |
shared::cta |
||
In the following sections, we will demonstrate how to use LDGSTS through examples and explain the differences between the different APIs.
4.11.1.1. Batching Loads in Conditional Code#
In this stencil example, the first warp of the thread block is responsible for collectively loading all the required data from the center as well as the left and right halos. With synchronous copies, due to the conditional nature of the code, the compiler may choose to generate a sequence of load-from-global (LDG) store-to-shared (STS) instructions instead of 3 LDGs followed by 3 STSs, which would be the optimal way to load the data to hide the global memory latency.
__global__ void stencil_kernel(const float *left, const float *center, const float *right)
{
// Left halo (8 elements) - center (32 elements) - right halo (8 elements)
__shared__ float buffer[8 + 32 + 8];
const int tid = threadIdx.x;
if (tid < 8) {
buffer[tid] = left[tid]; // Left halo
} else if (tid >= 32 - 8) {
buffer[tid + 16] = right[tid]; // Right halo
}
if (tid < 32) {
buffer[tid + 8] = center[tid]; // Center
}
__syncthreads();
// Compute stencil
}
To ensure that the data is loaded in the optimal way, we can replace the synchronous memory copies with asynchronous copies that load data directly from global memory to shared memory. This not only reduces register usage by copying the data directly to shared memory, but also ensures all loads from global memory are in-flight.
#include <cooperative_groups.h>
#include <cuda/barrier>
__global__ void stencil_kernel(const float *left, const float *center, const float *right)
{
auto block = cooperative_groups::this_thread_block();
auto thread = cooperative_groups::this_thread();
using barrier_t = cuda::barrier<cuda::thread_scope_block>;
__shared__ barrier_t barrier;
__shared__ float buffer[8 + 32 + 8];
// Initialize synchronization object.
if (block.thread_rank() == 0) {
init(&barrier, block.size());
}
__syncthreads();
// Version 1: Issue the copies in individual threads.
if (tid < 8) {
cuda::memcpy_async(buffer + tid, left + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier); // Left halo
// or cuda::memcpy_async(thread, buffer + tid, left + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier);
} else if (tid >= 32 - 8) {
cuda::memcpy_async(buffer + tid + 16, right + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier); // Right halo
// or cuda::memcpy_async(thread, buffer + tid + 16, right + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier);
}
if (tid < 32) {
cuda::memcpy_async(buffer + 40, right + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier); // Center
// or cuda::memcpy_async(thread, buffer + 40, right + tid, cuda::aligned_size_t<4>(sizeof(float)), barrier);
}
// Version 2: Cooperatively issue the copies across all threads.
cuda::memcpy_async(block, buffer, left, cuda::aligned_size_t<4>(8 * sizeof(float)), barrier); // Left halo
cuda::memcpy_async(block, buffer + 8, center, cuda::aligned_size_t<4>(32 * sizeof(float)), barrier); // Center
cuda::memcpy_async(block, buffer + 40, right, cuda::aligned_size_t<4>(8 * sizeof(float)), barrier); // Right halo
// Wait for all copies to complete.
barrier.arrive_and_wait();
__syncthreads();
// Compute stencil
}
|
#include <cooperative_groups.h>
#include <cooperative_groups/memcpy_async.h>
namespace cg = cooperative_groups;
__global__ void stencil_kernel(const float *left, const float *center, const float *right)
{
cg::thread_block block = cg::this_thread_block();
// Left halo (8 elements) - center (32 elements) - right halo (8 elements).
__shared__ float buffer[8 + 32 + 8];
// Cooperatively issue the copies across all threads.
cg::memcpy_async(block, buffer, left, 8 * sizeof(float)); // Left halo
cg::memcpy_async(block, buffer + 8, center, 32 * sizeof(float)); // Center
cg::memcpy_async(block, buffer + 40, right, 8 * sizeof(float)); // Right halo
cg::wait(block); // Waits for all copies to complete.
__syncthreads();
// Compute stencil.
}
|
#include <cuda_pipeline.h>
__global__ void stencil_kernel(const float *left, const float *center, const float *right)
{
// Left halo (8 elements) - center (32 elements) - right halo (8 elements).
__shared__ float buffer[8 + 32 + 8];
const int tid = threadIdx.x;
if (tid < 8) {
__pipeline_memcpy_async(buffer + tid, left + tid, sizeof(float)); // Left halo
} else if (tid >= 32 - 8) {
__pipeline_memcpy_async(buffer + tid + 16, right + tid, sizeof(float)); // Right halo
}
if (tid < 32) {
__pipeline_memcpy_async(buffer + tid + 8, center + tid, sizeof(float)); // Center
}
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
// Compute stencil.
}
|
The cuda::memcpy_async overload for cuda::barrier enables synchronizing asynchronous data transfers using an asynchronous barrier. This overload executes the copy operation as-if performed by another thread bound to the barrier by incrementing the expected count of the current phase on creation, and decrementing it on completion of the copy operation, such that the phase of the barrier will only advance when all threads participating in the barrier have arrived, and all memcpy_async bound to the current phase of the barrier have completed. We use a block-wide barrier, where all threads in the block participate, and merge the arrival and wait on the barrier with arrive_and_wait, since we do not perform any work between the phases.
Note that we can either use thread-level copies (version 1) or collective copies (version 2) to achieve the same result. In version 2, the API will automatically handle how the copies are done under the hood. In both versions, we use cuda::aligned_size_t<4>() to inform the compiler that the data is aligned to 4 bytes and the size of the data to copy is a multiple of 4 to enable use of LDGSTS. Note that for interoperability with cuda::barrier, cuda::memcpy_async from the cuda/barrier header is used here.
The cooperative_groups::memcpy_async implementation coordinates the memory transfers collectively across all threads in the block, but synchronizes completion with cg::wait(block) instead of explicit barrier operations.
The implementation based on the low-level primitives uses __pipeline_memcpy_async() to initiate element-wise memory transfers, __pipeline_commit() to commit the batch of copies, and __pipeline_wait_prior(0) to wait for all operations in the pipeline to complete. This provides the most direct control at the expense of more verbose code compared to the higher-level APIs. It also ensures LDGSTS will be used under the hood, which is not guaranteed with the higher-level APIs.
Note
The cooperative_groups::memcpy_async API is less efficient than the other APIs in this example because it automatically commits each copy operation immediately upon launch, preventing the optimization of batching multiple copies before a single commit operation that the other APIs enable.
4.11.1.2. Prefetching Data#
In this example, we will demonstrate how to use asynchronous data copies to prefetch data from global memory to shared memory. In an iterative copy and compute pattern, this allows hiding the latency of data transfers of future iterations with computation on the current iteration, potentially increasing bytes-in-flight.
#include <cooperative_groups.h>
#include <cuda/pipeline>
template <size_t num_stages = 2 /* Pipeline with num_stages stages */>
__global__ void prefetch_kernel(int* global_out, int const* global_in, size_t size, size_t batch_size) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
auto thread = cooperative_groups::this_thread();
assert(size == batch_size * grid.size()); // Assume input size fits batch_size * grid_size
extern __shared__ int shared[]; // num_stages * block.size() * sizeof(int) bytes
size_t shared_offset[num_stages];
for (int s = 0; s < num_stages; ++s) shared_offset[s] = s * block.size();
cuda::pipeline<cuda::thread_scope_thread> pipeline = cuda::make_pipeline();
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
// Fill the pipeline with the first ``num_stages`` batches.
for (int s = 0; s < num_stages; ++s) {
pipeline.producer_acquire();
cuda::memcpy_async(shared + shared_offset[s] + tid, global_in + block_batch(s) + tid, cuda::aligned_size_t<4>(sizeof(int)), pipeline);
pipeline.producer_commit();
}
int stage = 0;
// compute_batch: next batch to process
// fetch_batch: next batch to fetch from global memory
for (size_t compute_batch = 0, fetch_batch = num_stages; compute_batch < batch_size; ++compute_batch, ++fetch_batch) {
// Wait for the first requested stage to complete.
constexpr size_t pending_batches = num_stages - 1;
cuda::pipeline_consumer_wait_prior<pending_batches>(pipeline);
__syncthreads(); // Not required if each thread works on the data it copied.
// Compute on the current batch
compute(global_out + block_batch(compute_batch) + tid, shared + shared_offset[stage] + tid);
// Release the current stage.
pipeline.consumer_release();
__syncthreads(); // Not required if each thread works on the data it copied.
// Load future stage ``num_stages`` ahead of current compute batch.
pipeline.producer_acquire();
if (fetch_batch < batch_size) {
cuda::memcpy_async(shared + shared_offset[stage] + tid, global_in + block_batch(fetch_batch) + tid, cuda::aligned_size_t<4>(sizeof(int)), pipeline);
}
pipeline.producer_commit();
stage = (stage + 1) % num_stages;
}
}
|
#include <cooperative_groups.h>
#include <cooperative_groups/memcpy_async.h>
namespace cg = cooperative_groups;
template <size_t num_stages = 2 /* Pipeline with num_stages stages */>
__global__ void prefetch_kernel(int* global_out, int const* global_in, size_t size, size_t batch_size) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_size * grid.size()); // Assume input size fits batch_size * grid_size
extern __shared__ int shared[]; // num_stages * block.size() * sizeof(int) bytes
size_t shared_offset[num_stages];
for (int s = 0; s < num_stages; ++s) shared_offset[s] = s * block.size();
cuda::pipeline<cuda::thread_scope_thread> pipeline = cuda::make_pipeline();
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
// Fill the pipeline with the first ``num_stages`` batches.
for (int s = 0; s < num_stages; ++s) {
size_t block_batch_idx = block_batch(s);
cg::memcpy_async(block, shared + shared_offset[s], global_in + block_batch_idx, cuda::aligned_size_t<4>(sizeof(int));
}
int stage = 0;
// compute_batch: next batch to process
// fetch_batch: next batch to fetch from global memory
for (size_t compute_batch = 0, fetch_batch = num_stages; compute_batch < batch_size; ++compute_batch, ++fetch_batch) {
// Wait for the first requested stage to complete.
size_t pending_batches = (fetch_batch < batch_size - num_stages) ? num_stages - 1 : batch_size - fetch_batch - 1;
cg::wait_prior(pending_batches);
__syncthreads(); // Not required if each thread works on the data it copied.
// Compute on the current batch.
compute(global_out + block_batch(compute_batch) + tid, shared + shared_offset[stage] + tid);
__syncthreads(); // Not required if each thread works on the data it copied.
// Load future stage ``num_stages`` ahead of current compute batch.
size_t fetch_batch_idx = block_batch(fetch_batch);
if (fetch_batch < batch_size) {
cg::memcpy_async(block, shared + shared_offset[stage], global_in + block_batch(fetch_batch), cuda::aligned_size_t<4>(sizeof(int)) * block.size());
}
stage = (stage + 1) % num_stages;
}
}
|
#include <cooperative_groups.h>
#include <cuda_awbarrier_primitives.h>
template <size_t num_stages = 2 /* Pipeline with num_stages stages */>
__global__ void prefetch_kernel(int* global_out, int const* global_in, size_t size, size_t batch_size) {
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
assert(size == batch_size * grid.size()); // Assume input size fits batch_size * grid_size
extern __shared__ int shared[]; // num_stages * block.size() * sizeof(int) bytes
size_t shared_offset[num_stages];
for (int s = 0; s < num_stages; ++s) shared_offset[s] = s * block.size();
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
// Fill the pipeline with the first ``num_stages`` batches.
for (int s = 0; s < num_stages; ++s) {
__pipeline_memcpy_async(shared + shared_offset[s] + tid, global_in + block_batch(s)+ tid, cuda::aligned_size_t<4>(sizeof(int)));
__pipeline_commit();
}
// compute_batch: next batch to process
// fetch_batch: next batch to fetch from global memory
for (size_t compute_batch = 0, fetch_batch = num_stages; compute_batch < batch_size; ++compute_batch, ++fetch_batch) {
// Wait for the first requested stage to complete.
constexpr size_t pending_batches = num_stages - 1;
__pipeline_wait_prior<pending_batches>();
__syncthreads(); // Not required if each thread works on the data it copied.
// Compute on the current batch.
compute(global_out + block_batch(compute_batch) + tid, shared + shared_offset[stage] + tid);
__syncthreads(); // Not required if each thread works on the data it copied.
// Load future stage ``num_stages`` ahead of current compute batch.
if (fetch_batch < batch_size) {
__pipeline_memcpy_async(shared + shared_offset[stage] + tid, global_in + block_batch(fetch_batch) + tid, cuda::aligned_size_t<4>(sizeof(int)));
}
__pipeline_commit();
stage = (stage + 1) % num_stages;
}
}
|
The cuda::memcpy_async implementation demonstrates a multi-stage data prefetching using cuda::pipeline (see Pipelines) with cuda::memcpy_async. It:
Initializes a pipeline that is local to the thread.
Kick-starts the pipeline by scheduling
num_stagesmemcpy_asyncoperations.Loops over all the batches: it blocks all threads on the completion of the current batch, then performs the computation on the current batch and finally schedules the next
memcpy_asyncif there is one.
The cooperative_groups::memcpy_async implementation demonstrates multi-stage data prefetching using cooperative_groups::memcpy_async. The main difference with the previous implementation is that we do not use a pipeline object, but instead rely on cooperative_groups::memcpy_async to schedule the memory transfers in stages under the hood.
The CUDA C primitives implementation demonstrates multi-stage data prefetching using the low-level primitives in a quite similar manner to the first.
An important detail to enable efficient code generation in this example is to keep num_stages batches in the pipeline, even if there are no more batches to fetch. This is done by committing to the pipeline even if there are no more batches to fetch (pipeline.producer_commit() or __pipeline_commit()). Note that this is not possible with the cooperative groups API as we have no access to the internal pipeline.
4.11.1.3. Producer-Consumer Pattern Through Warp Specialization#
In this example, we will demonstrate how to implement a producer-consumer pattern where a single warp is specialized as the producer performing asynchronous data copies from global to shared memory, while the remaining warps consume the data from shared memory and perform computations. To enable concurrency between the producer and the consumer threads, we use double-buffering in shared memory. While consumer warps process data in one buffer, the producer warp asynchronously fetches the next batch of data into the other buffer.
#include <cooperative_groups.h>
#include <cuda/pipeline>
#pragma nv_diag_suppress static_var_with_dynamic_init
using pipeline = cuda::pipeline<cuda::thread_scope_block>;
__device__ void produce(pipeline &pipe, int num_stages, int stage, int num_batches, int batch, float *buffer, int buffer_len, float *in, int N)
{
if (batch < num_batches)
{
pipe.producer_acquire();
/* copy data from in(batch) to buffer(stage) using asynchronous memory copies */
cuda::memcpy_async(buffer + stage * buffer_len + threadIdx.x, in + batch * buffer_len + threadIdx.x, cuda::aligned_size_t<4>(sizeof(float)), pipe);
pipe.producer_commit();
}
}
__device__ void consume(pipeline &pipe, int num_stages, int stage, int num_batches, int batch, float *buffer, int buffer_len, float *out, int N)
{
pipe.consumer_wait();
/* consume buffer(stage) and update out(batch) */
pipe.consumer_release();
}
__global__ void producer_consumer_pattern(float *in, float *out, int N, int buffer_len)
{
auto block = cooperative_groups::this_thread_block();
constexpr int warpSize = 32;
/* Shared memory buffer declared below is of size 2 * buffer_len
so that we can alternatively work between two buffers.
buffer_0 = buffer and buffer_1 = buffer + buffer_len */
__shared__ extern float buffer[];
const int num_batches = N / buffer_len;
// Create a partitioned pipeline with 2 stages where the first warp is the producer and the other warps are consumers.
constexpr auto scope = cuda::thread_scope_block;
constexpr int num_stages = 2;
cuda::std::size_t producer_count = warpSize;
__shared__ cuda::pipeline_shared_state<scope, num_stages> shared_state;
pipeline pipe = cuda::make_pipeline(block, &shared_state, producer_count);
// Producer fills the pipeline
if (block.thread_rank() < producer_count)
for (int s = 0; s < num_stages; ++s)
produce(pipe, num_stages, s, num_batches, s, buffer, buffer_len, in, N);
// Process the batches
int stage = 0;
for (size_t b = 0; b < num_batches; ++b)
{
if (block.thread_rank() < producer_count)
{
// Producers prefetch the next batch
produce(pipe, num_stages, stage, num_batches, b + num_stages, buffer, buffer_len, in, N);
}
else
{
// Consumers consume the oldest batch
consume(pipe, num_stages, stage, num_batches, b, buffer, buffer_len, out, N);
}
stage = (stage + 1) % num_stages;
}
}
|
#include <cooperative_groups.h>
#include <cuda_awbarrier_primitives.h>
__device__ void produce(__mbarrier_t ready[], __mbarrier_t filled[], float *buffer, int buffer_len, float *in, int N)
{
for (int i = 0; i < N / buffer_len; ++i)
{
__mbarrier_token_t token = __mbarrier_arrive(&ready[i % 2]); /* wait for buffer_(i%2) to be ready to be filled */
while(!__mbarrier_try_wait(&ready[i % 2], token, 1000)) {}
/* produce, i.e., fill in, buffer_(i%2) */
__pipeline_memcpy_async(buffer + i * buffer_len + threadIdx.x, in + i * buffer_len + threadIdx.x, cuda::aligned_size_t<4>(sizeof(float)));
__pipeline_arrive_on(filled[i % 2]);
__mbarrier_arrive(filled[i % 2]); /* buffer_(i%2) is filled */
}
}
__device__ void consume(__mbarrier_t ready[], __mbarrier_t filled[], float *buffer, int buffer_len, float *out, int N)
{
__mbarrier_arrive(&ready[0]); /* buffer_0 is ready for initial fill */
__mbarrier_arrive(&ready[1]); /* buffer_1 is ready for initial fill */
for (int i = 0; i < N / buffer_len; ++i)
{
__mbarrier_token_t token = __mbarrier_arrive(&filled[i % 2]);
while(!__mbarrier_try_wait(&filled[i % 2], token, 1000)) {}
/* consume buffer_(i%2) */
__mbarrier_arrive(&ready[i % 2]); /* buffer_(i%2) is ready to be re-filled */
}
}
__global__ void producer_consumer_pattern(int N, float *in, float *out, int buffer_len)
{
/* Shared memory buffer declared below is of size 2 * buffer_len
so that we can alternatively work between two buffers.
buffer_0 = buffer and buffer_1 = buffer + buffer_len */
__shared__ extern float buffer[];
/* bar[0] and bar[1] track if buffers buffer_0 and buffer_1 are ready to be filled,
while bar[2] and bar[3] track if buffers buffer_0 and buffer_1 are filled-in respectively */
__shared__ __mbarrier_t bar[4];
// Initialize the barriers
auto block = cooperative_groups::this_thread_block();
if (block.thread_rank() < 4)
__mbarrier_init(bar + block.thread_rank(), block.size());
__syncthreads();
if (block.thread_rank() < warpSize)
produce(bar, bar + 2, buffer, buffer_len, in, N);
else
consume(bar, bar + 2, buffer, buffer_len, out, N);
}
|
The cuda::memcpy_async implementation demonstrates the API with the highest level of abstraction with cuda::memcpy_async and a cuda::pipeline with 2 stages. It uses a partitioned pipeline (see Pipelines) where the first warp serves as a producer and the remaining warps as consumers. Producers initially fill both pipeline stages. Then, in the main processing loop, while consumers process the current batch, producers fetch data for future batches, maintaining a steady flow of work.
The CUDA C primitives implementation based on primitives combines __pipeline_memcpy_async() with shared memory barriers as the completion mechanism to coordinate the asynchronous memory transfers. The __pipeline_arrive_on() function associates the memory copy with the barrier. It increments the barrier arrival count by one and when all asynchronous operations sequenced before it have completed, the arrival count is automatically decremented by one and hence the net effect on the arrival count is zero. For this reason, we also need to explicitly arrive at the barrier with __mbarrier_arrive().
4.11.2. Using the Tensor Memory Accelerator (TMA)#
Many applications need to move large amounts of data to and from global memory. Often, the data is laid out in global memory as a multi-dimensional array with non-sequential data access patterns. To reduce global memory accesses, sub-tiles of such arrays are copied to shared memory before use in computations. The loading and storing involves address-calculations that can be error-prone and repetitive. To offload these computations, compute capability 9.0 (Hopper) and later (see PTX documentation) have a tensor memory accelerator (TMA). The primary goal of the TMA is to provide an efficient data transfer mechanism from global memory to shared memory for multi-dimensional arrays.
Naming. Tensor memory accelerator (TMA) is a broad term used to refer to the features described in this section. For the purpose of forward-compatibility and to reduce discrepancies with the PTX ISA, the text in this section refers to TMA operations as either bulk-asynchronous copies or bulk-tensor asynchronous copies, depending on the specific type of copy used. The term “bulk” is used to contrast these operations with the asynchronous memory operations described in the previous section.
Dimensions. TMA supports copying both one-dimensional and multi-dimensional arrays (up to 5-dimensional). The programming model for bulk-asynchronous copies of one-dimensional contiguous arrays is different from the programming model for bulk-tensor asynchronous copies of multi-dimensional arrays. To perform a bulk-tensor asynchronous copy of a multi-dimensional array, the hardware requires a tensor map. This object describes the layout of the multi-dimensional array in global and shared memory. A tensor map is typically created on the host using the cuTensorMapEncode API and then transferred from host to device as a const kernel parameter annotated with __grid_constant__ (see __grid_constant__ Parameters). The tensor map is transferred from host to device as a const kernel parameter annotated with __grid_constant__, and can be used on the device to copy a tile of data between shared and global memory. In contrast, performing a bulk-asynchronous copy of a contiguous one-dimensional array does not require a tensor map: it can be performed on-device with a pointer and size parameter.
Source and destination. The source and destination addresses of TMA operations can be in shared or global memory. The operations can read data from global to shared memory, write data from shared to global memory, and also copy from shared memory to distributed shared memory of another block in the same cluster. In addition, when in a cluster, a bulk-asynchronous tensor operation can be specified as being multicast. In this case, data can be transferred from global memory to the shared memory of multiple blocks within the cluster. The multicast feature is optimized for target architecture sm_90a and may have significantly reduced performance on other targets. Hence, it is advised to be used with compute architecture sm_90a.
Asynchronicity. Data transfers using TMA are asynchronous and are modeled as async proxy operations (see Async Thread and Async Proxy). This allows the initiating thread to continue computing while the hardware asynchronously copies the data. Whether the data transfer occurs asynchronously in practice is up to the hardware implementation and may change in the future. There are several completion mechanisms that bulk-asynchronous operations can use to signal that they have completed. When the operation reads from global to shared memory, any thread in the block can wait for the data to be readable in shared memory by waiting on a shared memory barrier. When the bulk-asynchronous operation writes data from shared memory to global or distributed shared memory, only the initiating thread can wait for the operation to have completed. This is accomplished using a bulk async-group based completion mechanism. A table describing the completion mechanisms can be found below and in the PTX ISA.
Direction |
Asynchronous Copy (TMA, CC 9.0+) |
|
|---|---|---|
Source |
Destination |
Completion Mechanism |
global |
global |
|
shared::cta |
global |
bulk async-group |
global |
shared::cta |
shared memory barrier |
global |
shared::cluster |
shared memory barrier (multicast) |
shared::cta |
shared::cluster |
shared memory barrier |
shared::cta |
shared::cta |
|
4.11.2.1. Using TMA to transfer one-dimensional arrays#
The following table summarizes the possible source and destination memory spaces and completion mechanisms for bulk-asynchronous TMA along with the API that exposes it.
Direction |
Bulk-Asynchronous Copy (TMA, CC9.0+) |
||
|---|---|---|---|
Source |
Destination |
Completion Mechanism |
API |
global |
global |
||
shared::cta |
global |
bulk async-group |
|
global |
shared::cta |
shared memory barrier |
cuda::memcpy_async, cuda::device::memcpy_async_tx, cuda::ptx::cp_async_bulk |
global |
shared::cluster |
shared memory barrier |
|
shared::cta |
shared::cluster |
shared memory barrier |
|
shared::cta |
shared::cta |
||
Some functionality requires inline PTX that is currently made available through the cuda::ptx namespace in the CUDA Standard C++ library. The availability of these wrappers can be checked with the following code:
#if defined(__CUDA_MINIMUM_ARCH__) && __CUDA_MINIMUM_ARCH__ < 900
static_assert(false, "Device code is being compiled with older architectures that are incompatible with TMA.");
#endif // __CUDA_MINIMUM_ARCH__
Note that cuda::memcpy_async uses TMA if the source and destination addresses are 16-byte aligned and the size is a multiple of 16 bytes, otherwise it falls back to synchronous copies. On the other hand, cuda::device::memcpy_async_tx and cuda::ptx::cp_async_bulk always use TMA and will result in undefined behavior if the requirements are not met.
In the following, we demonstrate how to use bulk-asynchronous copies through an example. The example read-modify-writes a one-dimensional array. The kernel goes through the following steps:
Initialize a shared memory barrier as a completion mechanism for the bulk-asynchronous copy from global to shared memory.
Initiate the copy of a block of memory from global to shared memory.
Arrive and wait on the shared memory barrier for completion of the copy.
Increment the shared memory buffer values.
Use a proxy fence to ensure shared memory writes (generic proxy) become visible to the subsequent bulk-asynchronous copy (async proxy).
Initiate a bulk-asynchronous copy of the buffer in shared memory to global memory.
Wait for the bulk-asynchronous copy to have finished reading shared memory.
#include <cuda/barrier>
#include <cuda/ptx>
using barrier = cuda::barrier<cuda::thread_scope_block>;
namespace ptx = cuda::ptx;
static constexpr size_t buf_len = 1024;
__device__ inline bool is_elected()
{
unsigned int tid = threadIdx.x;
unsigned int warp_id = tid / 32;
unsigned int uniform_warp_id = __shfl_sync(0xFFFFFFFF, warp_id, 0); // Broadcast from lane 0.
return (uniform_warp_id == 0 && ptx::elect_sync(0xFFFFFFFF)); // Elect a leader thread among warp 0.
}
__global__ void add_one_kernel(int* data, size_t offset)
{
// Shared memory buffer. The destination shared memory buffer of
// a bulk operation should be 16 byte aligned.
__shared__ alignas(16) int smem_data[buf_len];
// 1. Initialize shared memory barrier with the number of threads participating in the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
init(&bar, blockDim.x);
}
__syncthreads();
// 2. Initiate TMA transfer to copy global to shared memory from a single thread.
if (is_elected()) {
// Launch the async copy and communicate how many bytes are expected to come in (the transaction count).
// Version 1: cuda::memcpy_async
cuda::memcpy_async(
smem_data, data + offset,
cuda::aligned_size_t<16>(sizeof(smem_data)),
bar);
// Version 2: cuda::device::memcpy_async_tx
// cuda::device::memcpy_async_tx(
// smem_data, data + offset,
// cuda::aligned_size_t<16>(sizeof(smem_data)),
// bar);
// cuda::device::barrier_expect_tx(
// cuda::device::barrier_native_handle(bar),
// sizeof(smem_data));
// Version 3: cuda::ptx::cp_async_bulk
// ptx::cp_async_bulk(
// ptx::space_shared, ptx::space_global,
// smem_data, data + offset,
// sizeof(smem_data),
// cuda::device::barrier_native_handle(bar));
// cuda::device::barrier_expect_tx(
// cuda::device::barrier_native_handle(bar),
// sizeof(smem_data));
}
// 3a. All threads arrive on the barrier.
barrier::arrival_token token = bar.arrive();
// 3b. Wait for the data to have arrived.
bar.wait(std::move(token));
// 4. Compute saxpy and write back to shared memory.
for (int i = threadIdx.x; i < buf_len; i += blockDim.x) {
smem_data[i] += 1;
}
// 5. Wait for shared memory writes to be visible to TMA engine.
ptx::fence_proxy_async(ptx::space_shared);
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// 6. Initiate TMA transfer to copy shared memory to global memory.
if (is_elected()) {
ptx::cp_async_bulk(
ptx::space_global, ptx::space_shared,
data + offset, smem_data, sizeof(smem_data));
// 7. Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
ptx::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
ptx::cp_async_bulk_wait_group_read(ptx::n32_t<0>());
}
}
Barrier initialization. The barrier is initialized with the number of threads participating in the block. As a result, the barrier will flip only if all threads have arrived on this barrier. Shared memory barriers are described in more detail in shared memory barriers.
TMA read. The bulk-asynchronous copy instruction directs the hardware to copy a large chunk of data into shared memory, and to update the transaction count of the shared memory barrier after completing the read. In general, issuing as few bulk copies with as big a size as possible results in the best performance. Because the copy can be performed asynchronously by the hardware, it is not necessary to split the copy into smaller chunks.
The thread that initiates the bulk-asynchronous copy operation also tells the barrier how many transactions (tx) are expected to arrive.
In this case, the transactions are counted in bytes. This is automatically performed by cuda::memcpy_async, but not by
cuda::device::memcpy_async_tx and cuda::ptx::cp_async_bulk after which we need to explicitly call cuda::ptx::mbarrier_expect_tx.
If multiple threads update the transaction count, the expected transaction count will be the sum
of the updates. The barrier will only flip once all threads have arrived and
all bytes have arrived. Once the barrier has flipped, the bytes are safe to read
from shared memory, both by the threads as well as by subsequent
bulk-asynchronous copies. More information about barrier transaction accounting
can be found in Tracking Asynchronous Memory Operations.
Barrier wait. Waiting for the barrier to flip is done using tokens with bar.wait(). It can be more efficient to use explicit phase tracking of the barrier (see Explicit Phase Tracking).
SMEM write and sync. The increment of the buffer values reads and writes to shared
memory. To make the writes visible to subsequent bulk-asynchronous copies, the
cuda::ptx::fence_proxy_async function is used. This orders the writes to
shared memory before subsequent reads from bulk-asynchronous copy operations,
which read through the async proxy. So each thread first orders the writes to
objects in shared memory in the async proxy via the
cuda::ptx::fence_proxy_async, and these operations by all threads are
ordered before the async operation performed in thread 0 using
__syncthreads().
TMA write and sync. The write from shared to global memory is again
initiated by a single thread. The completion of the write is not tracked by a
shared memory barrier. Instead, a thread-local mechanism is used. Multiple
writes can be batched into a so-called bulk async-group. Afterwards, the
thread can wait for all operations in this group to have completed reading from
shared memory (as in the code above) or to have completed writing to global
memory, making the writes visible to the initiating thread. For more information,
refer to the PTX ISA documentation of cp.async.bulk.wait_group.
Note that the bulk-asynchronous and non-bulk-asynchronous copy instructions have
different async-groups: there exist both cp.async.wait_group and
cp.async.bulk.wait_group instructions.
Note
It is recommended to initiate TMA operations by a single thread in the block.
While using if (threadIdx.x == 0) might seem sufficient, the compiler cannot
verify that indeed only one thread is initiating the copy and may insert a peeling
loop over all active threads, which results in warp serialization and reduced
performance. To prevent this, we define the is_elected() helper function that
uses cuda::ptx::elect_sync to select one thread from warp 0 – which is known to
the compiler – to execute the copy allowing it to generate more efficient code.
Alternatively, the same effect can be achieved with cooperative_groups::invoke_one.
The bulk-asynchronous instructions have specific alignment requirements on their source and destination addresses. More information can be found in the table below.
Address / Size |
Alignment |
|---|---|
Global memory address |
Must be 16 byte aligned. |
Shared memory address |
Must be 16 byte aligned. |
Shared memory barrier address |
Must be 8 byte aligned (this is guaranteed by |
Size of transfer |
Must be a multiple of 16 bytes. |
4.11.2.1.1. Prefetching Data#
In this example, we will demonstrate how to use TMA to prefetch data from global memory to shared memory. In an iterative copy and compute pattern, this allows hiding the latency of data transfers of future iterations with computation on the current iteration, potentially increasing bytes-in-flight.
#include <cooperative_groups.h>
#include <cuda/barrier>
#include <cuda/ptx>
namespace ptx = cuda::ptx;
namespace cg = cooperative_groups;
__device__ inline bool is_elected()
{
unsigned int tid = threadIdx.x;
unsigned int warp_id = tid / 32;
unsigned int uniform_warp_id = __shfl_sync(0xFFFFFFFF, warp_id, 0); // Broadcast from lane 0.
return (uniform_warp_id == 0 && ptx::elect_sync(0xFFFFFFFF)); // Elect a leader thread among warp 0.
}
template <int block_size, int num_stages>
__global__ void prefetch_kernel(int* global_out, int const* global_in, size_t size, size_t batch_size) {
auto grid = cg::this_grid();
auto block = cg::this_thread_block();
const int tid = threadIdx.x;
assert(size == batch_size * grid.size()); // Assume input size fits batch_size * grid_size
// 1. Initialization Phase
__shared__ int shared[num_stages * block_size];
size_t shared_offset[num_stages];
for (int s = 0; s < num_stages; ++s) shared_offset[s] = s * block.size();
auto block_batch = [&](size_t batch) -> int {
return block.group_index().x * block.size() + grid.size() * batch;
};
// Initialize shared memory barrier with the number of threads participating in the barrier.
// We will use explicit phase tracking for the barrier, which allows us to have only one
// thread arrive on the barrier to set the transaction count and other threads wait for
// a parity-based phase flip.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ cuda::barrier<cuda::thread_scope_block> bar[num_stages];
if (tid == 0) {
#pragma unroll num_stages
for (int i = 0; i < num_stages; i++) {
init(&bar[i], 1);
}
}
__syncthreads();
// Fill the pipeline with the first ``num_stages`` batches.
if (is_elected()) {
size_t num_bytes = block_size * sizeof(int);
#pragma unroll num_stages
for (int s = 0; s < num_stages; ++s) {
cuda::device::memcpy_async_tx(&shared[shared_offset[s]], &global_in[block_batch(s)], cuda::aligned_size_t<16>(num_bytes), bar[s]);
(void)cuda::device::barrier_arrive_tx(bar[s], 1, num_bytes);
}
}
// 2. Main Processing Loop.
// compute_batch: next batch to process.
// fetch_batch: next batch to fetch from global memory.
int stage = 0; // current stage in the shared memory buffer.
uint32_t parity = 0; // barrierparity
for (size_t compute_batch = 0, fetch_batch = num_stages; compute_batch < batch_size; ++compute_batch, ++fetch_batch) {
// (a) Wait on current batch.
while (!ptx::mbarrier_try_wait_parity(ptx::sem_acquire, ptx::scope_cta, cuda::device::barrier_native_handle(bar[stage]), parity)) {}
// (b) Compute on the current batch.
compute(global_out + block_batch(compute_batch) + tid, shared + shared_offset[stage] + tid);
__syncthreads();
// (c) Load next stage ``num_stages`` ahead of current compute batch.
if (is_elected() && fetch_batch < batch_size) {
size_t num_bytes = block_size * sizeof(int);
cuda::device::memcpy_async_tx(&shared[shared_offset[stage]], &global_in[block_batch(fetch_batch)], cuda::aligned_size_t<16>(num_bytes), bar[stage]);
(void)cuda::device::barrier_arrive_tx(bar[stage], 1, num_bytes);
}
// (d) Stage management.
stage++;
if (stage == num_stages) {
stage = 0;
parity ^= 1;
}
}
}
|
This example implements multi-stage data prefetching using cuda::device::memcpy_async_tx for the TMA copies and employs shared memory barriers with explicit phase tracking for synchronization of the copies.
Initialization Phase: Sets up shared memory barriers (one per stage) and pre-loads the first
num_stagesbatches into different shared memory sections.Main Processing Loop:
Wait: Uses
mbarrier_try_wait_parity()to wait for the current batch to complete copying.Compute: Processes the current batch data.
Prefetch: Schedules the next
memcpy_async_txoperation for future data (stayingnum_stagesahead).Stage Management: Cycles through stages using a rotating buffer approach and tracks barrier parity.
4.11.2.2. Using TMA to transfer multi-dimensional arrays#
In this section, we will focus on multi-dimensional TMA copies. The primary difference between the one-dimensional and multi-dimensional case is that a tensor map must be created on the host and passed to the CUDA kernel.
The following table summarizes the possible source and destination memory spaces and completion mechanisms for bulk-tensor asynchronous TMA along with the API that exposes it in device code.
Direction |
Bulk-Tensor Asynchronous Copy (TMA, CC9.0+) |
||
|---|---|---|---|
Source |
Destination |
Completion Mechanism |
API |
global |
global |
||
shared::cta |
global |
bulk async-group |
|
global |
shared::cta |
shared memory barrier |
|
global |
shared::cluster |
shared memory barrier |
|
shared::cta |
shared::cluster |
shared memory barrier |
|
shared::cta |
shared::cta |
||
All functionality requires inline PTX that is currently made available through the cuda::ptx namespace in the CUDA Standard C++ library.
In the following, we describe how to create a tensor map using the CUDA driver API, how to pass it to the device, and how to use it on the device.
Driver API. A tensor map is created using the cuTensorMapEncodeTiled
driver API. This API can be accessed by linking to the driver directly
(-lcuda) or by using the cudaGetDriverEntryPointByVersion
API. Below, we show how to get a pointer to the cuTensorMapEncodeTiled API.
For more information, refer to Driver Entry Point Access.
#include <cudaTypedefs.h> // PFN_cuTensorMapEncodeTiled, CUtensorMap
PFN_cuTensorMapEncodeTiled_v12000 get_cuTensorMapEncodeTiled() {
// Get pointer to cuTensorMapEncodeTiled
cudaDriverEntryPointQueryResult driver_status;
void* cuTensorMapEncodeTiled_ptr = nullptr;
CUDA_CHECK(cudaGetDriverEntryPointByVersion("cuTensorMapEncodeTiled", &cuTensorMapEncodeTiled_ptr, 12000, cudaEnableDefault, &driver_status));
assert(driver_status == cudaDriverEntryPointSuccess);
return reinterpret_cast<PFN_cuTensorMapEncodeTiled_v12000>(cuTensorMapEncodeTiled_ptr);
}
Creation. Creating a tensor map requires many parameters. Among
them are the base pointer to an array in global memory, the size of the array
(in number of elements), the stride from one row to the next (in bytes), the
size of the shared memory buffer (in number of elements). The code below creates
a tensor map to describe a two-dimensional row-major array of size GMEM_HEIGHT
x GMEM_WIDTH. Note the order of the parameters: the fastest moving dimension
comes first.
CUtensorMap tensor_map{};
// rank is the number of dimensions of the array.
constexpr uint32_t rank = 2;
uint64_t size[rank] = {GMEM_WIDTH, GMEM_HEIGHT};
// The stride is the number of bytes to traverse from the first element of one row to the next.
// It must be a multiple of 16.
uint64_t stride[rank - 1] = {GMEM_WIDTH * sizeof(int)};
// The box_size is the size of the shared memory buffer that is used as the
// destination of a TMA transfer.
uint32_t box_size[rank] = {SMEM_WIDTH, SMEM_HEIGHT};
// The distance between elements in units of sizeof(element). A stride of 2
// can be used to load only the real component of a complex-valued tensor, for instance.
uint32_t elem_stride[rank] = {1, 1};
// Get a function pointer to the cuTensorMapEncodeTiled driver API.
auto cuTensorMapEncodeTiled = get_cuTensorMapEncodeTiled();
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
// Interleave patterns can be used to accelerate loading of values that
// are less than 4 bytes long.
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// Swizzling can be used to avoid shared memory bank conflicts.
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
// L2 Promotion can be used to widen the effect of a cache-policy to a wider
// set of L2 cache lines.
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
// Any element that is outside of bounds will be set to zero by the TMA transfer.
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE
);
Host-to-device transfer. There are three ways to make a tensor map accessible to
device code. The recommended approach is to pass the tensor map as a const __grid_constant__
parameter to a kernel. The other possibilities are copying the tensor map into device __constant__
memory using cudaMemcpyToSymbol or accessing it via global memory. When passing the tensor map as a parameter, some versions of the
GCC C++ compiler issue the warning “the ABI for passing parameters with 64-byte
alignment has changed in GCC 4.6”. This warning can be ignored.
#include <cuda.h>
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map)
{
// Use tensor_map here.
}
int main() {
CUtensorMap map;
// [ ..Initialize map.. ]
kernel<<<1, 1>>>(map);
}
As an alternative to the __grid_constant__ kernel parameter, a global
__constant__ variable can be used. An example is included
below.
#include <cuda.h>
__constant__ CUtensorMap global_tensor_map;
__global__ void kernel()
{
// Use global_tensor_map here.
}
int main() {
CUtensorMap local_tensor_map;
// [ ..Initialize map.. ]
cudaMemcpyToSymbol(global_tensor_map, &local_tensor_map, sizeof(CUtensorMap));
kernel<<<1, 1>>>();
}
Finally, it is possible to copy the tensor map to global memory. Using a pointer to a tensor map in global device memory requires a fence in each thread block before any thread in the block uses the updated tensor map. Further uses of the tensor map by that thread block do not need to be fenced unless the tensor map is modified again. Note that this mechanism may be slower than the two mechanisms described above.
#include <cuda.h>
#include <cuda/ptx>
namespace ptx = cuda::ptx;
__device__ CUtensorMap global_tensor_map;
__global__ void kernel(CUtensorMap *tensor_map)
{
// Fence acquire tensor map:
ptx::n32_t<128> size_bytes;
// Since the tensor map was modified from the host using cudaMemcpy,
// the scope should be .sys.
ptx::fence_proxy_tensormap_generic(
ptx::sem_acquire, ptx::scope_sys, tensor_map, size_bytes
);
// Safe to use tensor_map after fence inside this thread.
}
int main() {
CUtensorMap local_tensor_map;
// [ ..Initialize map.. ]
cudaMemcpy(&global_tensor_map, &local_tensor_map, sizeof(CUtensorMap), cudaMemcpyHostToDevice);
kernel<<<1, 1>>>(global_tensor_map);
}
Use. The kernel below loads a 2D tile of size SMEM_HEIGHT x SMEM_WIDTH
from a larger 2D array. The top-left corner of the tile is indicated by the
indices x and y. The tile is loaded into shared memory, modified, and
written back to global memory.
#include <cuda.h> // CUtensormap
#include <cuda/barrier>
using barrier = cuda::barrier<cuda::thread_scope_block>;
namespace ptx = cuda::ptx;
__device__ inline bool is_elected()
{
unsigned int tid = threadIdx.x;
unsigned int warp_id = tid / 32;
unsigned int uniform_warp_id = __shfl_sync(0xFFFFFFFF, warp_id, 0); // Broadcast from lane 0.
return (uniform_warp_id == 0 && ptx::elect_sync(0xFFFFFFFF)); // Elect a leader thread among warp 0.
}
__global__ void kernel(const __grid_constant__ CUtensorMap tensor_map, int x, int y) {
// The destination shared memory buffer of a bulk tensor operation should be
// 128 byte aligned.
__shared__ alignas(128) int smem_buffer[SMEM_HEIGHT][SMEM_WIDTH];
// Initialize shared memory barrier with the number of threads participating in the barrier.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
// Initialize barrier. All `blockDim.x` threads in block participate.
init(&bar, blockDim.x);
}
// Syncthreads so initialized barrier is visible to all threads.
__syncthreads();
barrier::arrival_token token;
if (is_elected()) {
// Initiate bulk tensor copy.
int32_t tensor_coords[2] = { x, y };
ptx::cp_async_bulk_tensor(
ptx::space_shared, ptx::space_global,
&smem_buffer, &tensor_map, tensor_coords,
cuda::device::barrier_native_handle(bar));
// Arrive on the barrier and tell how many bytes are expected to come in.
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
// Other threads just arrive.
token = bar.arrive();
}
// Wait for the data to have arrived.
bar.wait(std::move(token));
// Symbolically modify a value in shared memory.
smem_buffer[0][threadIdx.x] += threadIdx.x;
// Wait for shared memory writes to be visible to TMA engine.
ptx::fence_proxy_async(ptx::space_shared);
__syncthreads();
// After syncthreads, writes by all threads are visible to TMA engine.
// Initiate TMA transfer to copy shared memory to global memory
if (is_elected()) {
int32_t tensor_coords[2] = { x, y };
ptx::cp_async_bulk_tensor(
ptx::space_global, ptx::space_shared,
&tensor_map, tensor_coords, &smem_buffer);
// Wait for TMA transfer to have finished reading shared memory.
// Create a "bulk async-group" out of the previous bulk copy operation.
ptx::cp_async_bulk_commit_group();
// Wait for the group to have completed reading from shared memory.
ptx::cp_async_bulk_wait_group_read(ptx::n32_t<0>());
}
// Destroy barrier. This invalidates the memory region of the barrier. If
// further computations were to take place in the kernel, this allows the
// memory location of the shared memory barrier to be reused.
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
Negative indices and out of bounds. When part of the tile that is being read from global to shared memory is out of bounds, the shared memory that corresponds to the out of bounds area is zero-filled. The top-left corner indices of the tile may also be negative. When writing from shared to global memory, parts of the tile may be out of bounds, but the top left corner cannot have any negative indices.
Size and stride. The size of a tensor is the number of elements along one dimension. All sizes must be greater than one. The stride is the number of bytes between elements of the same dimension. For instance, a 4 x 4 matrix of integers has sizes 4 and 4. Since it has 4 bytes per element, the strides are 4 and 16 bytes. Due to alignment requirements, a 4 x 3 row-major matrix of integers must have strides of 4 and 16 bytes as well. Each row is padded with 4 extra bytes to ensure that the start of the next row is aligned to 16 bytes. More information about alignment requirements can be found in the table below.
Address / Size |
Alignment |
|---|---|
Global memory address |
Must be 16 byte aligned. |
Global memory sizes |
Must be greater than or equal to one. Does not have to be a multiple of 16 bytes. |
Global memory strides |
Must be multiples of 16 bytes. |
Shared memory address |
Must be 128 byte aligned. |
Shared memory barrier address |
Must be 8 byte aligned (this is guaranteed by |
Size of transfer |
Must be a multiple of 16 bytes. |
4.11.2.2.1. Encoding a Tensor Map on Device#
Previous sections have described how to create a tensor map on the host using the CUDA driver API.
This section explains how to encode a tiled-type tensor map on device. This is useful in situations where the typical
way of transferring the tensor map (using const __grid_constant__ kernel parameters) is undesirable, for instance,
when processing a batch of tensors of various sizes in a single kernel launch.
The recommended pattern is as follows:
Create a tensor map “template”,
template_tensor_map, using the Driver API on the host.In a device kernel, copy the
template_tensor_map, modify the copy, store in global memory, and appropriately fence.Use the tensor map in a kernel with appropriate fencing.
The high-level code structure is as follows:
// Initialize device context:
CUDA_CHECK(cudaDeviceSynchronize());
// Create a tensor map template using the cuTensorMapEncodeTiled driver function
CUtensorMap template_tensor_map = make_tensormap_template();
// Allocate tensor map and tensor in global memory
CUtensorMap* global_tensor_map;
CUDA_CHECK(cudaMalloc(&global_tensor_map, sizeof(CUtensorMap)));
char* global_buf;
CUDA_CHECK(cudaMalloc(&global_buf, 8 * 256));
// Fill global buffer with data.
fill_global_buf<<<1, 1>>>(global_buf);
// Define the parameters of the tensor map that will be created on device.
tensormap_params p{};
p.global_address = global_buf;
p.rank = 2;
p.box_dim[0] = 128; // The box in shared memory has half the width of the full buffer
p.box_dim[1] = 4; // The box in shared memory has half the height of the full buffer
p.global_dim[0] = 256; //
p.global_dim[1] = 8; //
p.global_stride[0] = 256; //
p.element_stride[0] = 1; //
p.element_stride[1] = 1; //
// Encode global_tensor_map on device:
encode_tensor_map<<<1, 32>>>(template_tensor_map, p, global_tensor_map);
// Use it from another kernel:
consume_tensor_map<<<1, 1>>>(global_tensor_map);
// Check for errors:
CUDA_CHECK(cudaDeviceSynchronize());
The following sections describe the high-level steps. Throughout the examples, the following tensormap_params
struct contains the new values of the fields to be updated. It is included here to reference when reading the examples.
struct tensormap_params {
void* global_address;
int rank;
uint32_t box_dim[5];
uint64_t global_dim[5];
size_t global_stride[4];
uint32_t element_stride[5];
};
4.11.2.2.2. Device-side Encoding and Modification of a Tensor Map#
The recommended process of encoding a tensor map in global memory proceeds as follows.
Pass an existing tensor map, the
template_tensor_map, to the kernel. In contrast to kernels that use the tensor map in acp.async.bulk.tensorinstruction, this may be done in any way: a pointer to global memory, kernel parameter, a__constant___variable, and so on.Copy-initialize a tensor map in shared memory with the template_tensor_map value.
Modify the tensor map in shared memory using the cuda::ptx::tensormap_replace functions. These functions wrap the tensormap.replace PTX instruction, which can be used to modify any field of a tiled-type tensor map, including the base address, size, stride, and so on.
Using the cuda::ptx::tensormap_copy_fenceproxy function, copy the modified tensor map from shared memory to global memory and perform any necessary fencing.
The following code contains a kernel that follows these steps. For completeness, it modifies all the fields of the tensor map. Typically, a kernel will modify just a few fields.
In this kernel, template_tensor_map is passed as a kernel parameter. This is the preferred way of moving template_tensor_map
from the host to the device. If the kernel is intended to update an existing tensor map in device memory, it can take a
pointer to the existing tensor map to modify.
Note
The format of the tensor map may change over time. Therefore, the cuda::ptx::tensormap_replace
functions and corresponding tensormap.replace.tile
PTX instructions are marked as specific to sm_90a. To use them, compile using nvcc -arch sm_90a .....
Tip
On sm_90a, a zero-initialized buffer in shared memory may also be used as the initial tensor map value. This
enables encoding a tensor map purely on device, without using the driver API to encode the template_tensor_map value.
Note
On-device modification is only supported for tiled-type tensor maps; other tensor map types cannot be modified on device. For more information on the tensor map types, refer to the Driver API reference.
#include <cuda/ptx>
namespace ptx = cuda::ptx;
// launch with 1 warp.
__launch_bounds__(32)
__global__ void encode_tensor_map(const __grid_constant__ CUtensorMap template_tensor_map, tensormap_params p, CUtensorMap* out) {
__shared__ alignas(128) CUtensorMap smem_tmap;
if (threadIdx.x == 0) {
// Copy template to shared memory:
smem_tmap = template_tensor_map;
const auto space_shared = ptx::space_shared;
ptx::tensormap_replace_global_address(space_shared, &smem_tmap, p.global_address);
// For field .rank, the operand new_val must be ones less than the desired
// tensor rank as this field uses zero-based numbering.
ptx::tensormap_replace_rank(space_shared, &smem_tmap, p.rank - 1);
// Set box dimensions:
if (0 < p.rank) { ptx::tensormap_replace_box_dim(space_shared, &smem_tmap, ptx::n32_t<0>{}, p.box_dim[0]); }
if (1 < p.rank) { ptx::tensormap_replace_box_dim(space_shared, &smem_tmap, ptx::n32_t<1>{}, p.box_dim[1]); }
if (2 < p.rank) { ptx::tensormap_replace_box_dim(space_shared, &smem_tmap, ptx::n32_t<2>{}, p.box_dim[2]); }
if (3 < p.rank) { ptx::tensormap_replace_box_dim(space_shared, &smem_tmap, ptx::n32_t<3>{}, p.box_dim[3]); }
if (4 < p.rank) { ptx::tensormap_replace_box_dim(space_shared, &smem_tmap, ptx::n32_t<4>{}, p.box_dim[4]); }
// Set global dimensions:
if (0 < p.rank) { ptx::tensormap_replace_global_dim(space_shared, &smem_tmap, ptx::n32_t<0>{}, (uint32_t) p.global_dim[0]); }
if (1 < p.rank) { ptx::tensormap_replace_global_dim(space_shared, &smem_tmap, ptx::n32_t<1>{}, (uint32_t) p.global_dim[1]); }
if (2 < p.rank) { ptx::tensormap_replace_global_dim(space_shared, &smem_tmap, ptx::n32_t<2>{}, (uint32_t) p.global_dim[2]); }
if (3 < p.rank) { ptx::tensormap_replace_global_dim(space_shared, &smem_tmap, ptx::n32_t<3>{}, (uint32_t) p.global_dim[3]); }
if (4 < p.rank) { ptx::tensormap_replace_global_dim(space_shared, &smem_tmap, ptx::n32_t<4>{}, (uint32_t) p.global_dim[4]); }
// Set global stride:
if (1 < p.rank) { ptx::tensormap_replace_global_stride(space_shared, &smem_tmap, ptx::n32_t<0>{}, p.global_stride[0]); }
if (2 < p.rank) { ptx::tensormap_replace_global_stride(space_shared, &smem_tmap, ptx::n32_t<1>{}, p.global_stride[1]); }
if (3 < p.rank) { ptx::tensormap_replace_global_stride(space_shared, &smem_tmap, ptx::n32_t<2>{}, p.global_stride[2]); }
if (4 < p.rank) { ptx::tensormap_replace_global_stride(space_shared, &smem_tmap, ptx::n32_t<3>{}, p.global_stride[3]); }
// Set element stride:
if (0 < p.rank) { ptx::tensormap_replace_element_size(space_shared, &smem_tmap, ptx::n32_t<0>{}, p.element_stride[0]); }
if (1 < p.rank) { ptx::tensormap_replace_element_size(space_shared, &smem_tmap, ptx::n32_t<1>{}, p.element_stride[1]); }
if (2 < p.rank) { ptx::tensormap_replace_element_size(space_shared, &smem_tmap, ptx::n32_t<2>{}, p.element_stride[2]); }
if (3 < p.rank) { ptx::tensormap_replace_element_size(space_shared, &smem_tmap, ptx::n32_t<3>{}, p.element_stride[3]); }
if (4 < p.rank) { ptx::tensormap_replace_element_size(space_shared, &smem_tmap, ptx::n32_t<4>{}, p.element_stride[4]); }
// These constants are documented in this table:
// https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#tensormap-new-val-validity
auto u8_elem_type = ptx::n32_t<0>{};
ptx::tensormap_replace_elemtype(space_shared, &smem_tmap, u8_elem_type);
auto no_interleave = ptx::n32_t<0>{};
ptx::tensormap_replace_interleave_layout(space_shared, &smem_tmap, no_interleave);
auto no_swizzle = ptx::n32_t<0>{};
ptx::tensormap_replace_swizzle_mode(space_shared, &smem_tmap, no_swizzle);
auto zero_fill = ptx::n32_t<0>{};
ptx::tensormap_replace_fill_mode(space_shared, &smem_tmap, zero_fill);
}
// Synchronize the modifications with other threads in warp
__syncwarp();
// Copy the tensor map to global memory collectively with threads in the warp.
// In addition: make the updated tensor map visible to other threads on device that
// for use with cp.async.bulk.
ptx::n32_t<128> bytes_128;
ptx::tensormap_cp_fenceproxy(ptx::sem_release, ptx::scope_gpu, out, &smem_tmap, bytes_128);
}
4.11.2.2.3. Usage of a Modified Tensor Map#
In contrast to using a tensor map that is passed as a const __grid_constant__ kernel parameter, using a tensor map in
global memory requires explicitly establishing a release-acquire pattern in the tensor map proxy between the threads
that modify the tensor map and the threads that use it.
The release part of the pattern was shown in the previous section. It is accomplished using the cuda::ptx::tensormap.cp_fenceproxy function.
The acquire part is accomplished using the cuda::ptx::fence_proxy_tensormap_generic
function that wraps the fence.proxy.tensormap::generic.acquire
instruction. If the two threads participating in the release-acquire pattern are on the same device, the .gpu scope suffices. If the threads are on
different devices, the .sys scope must be used. Once a tensor map has been acquired by one thread, it can be used by other threads in the block
after sufficient synchronization, for example, using __syncthreads(). The thread that uses the tensor map and the thread that performs the fence
must be in the same block. That is, if the threads are in, for example, two different thread blocks of the same cluster, the same grid, or a
different kernel, synchronization APIs such as cooperative_groups::cluster or grid_group::sync() or stream-order synchronization do not
suffice to establish ordering for tensor map updates, that is, threads in these other thread blocks still need to acquire the tensor map proxy
at the right scope before using the updated tensor map. If there are no intermediate modifications, the fence does not have to be repeated
before each cp.async.bulk.tensor instruction.
The fence and subsequent use of the tensor map is shown in the following example.
// Consumer of tensor map in global memory:
__global__ void consume_tensor_map(CUtensorMap* tensor_map) {
// Fence acquire tensor map:
ptx::n32_t<128> size_bytes;
ptx::fence_proxy_tensormap_generic(ptx::sem_acquire, ptx::scope_sys, tensor_map, size_bytes);
// Safe to use tensor_map after fence.
__shared__ uint64_t bar;
__shared__ alignas(128) char smem_buf[4][128];
if (threadIdx.x == 0) {
// Initialize barrier
ptx::mbarrier_init(&bar, 1);
// Issue TMA request
ptx::cp_async_bulk_tensor(ptx::space_cluster, ptx::space_global, smem_buf, tensor_map, {0, 0}, &bar);
// Arrive on barrier. Expect 4 * 128 bytes.
ptx::mbarrier_arrive_expect_tx(ptx::sem_release, ptx::scope_cta, ptx::space_shared, &bar, sizeof(smem_buf));
}
const int parity = 0;
// Wait for load to have completed
while (!ptx::mbarrier_try_wait_parity(&bar, parity)) {}
// print items:
printf("Got:\n\n");
for (int j = 0; j < 4; ++j) {
for (int i = 0; i < 128; ++i) {
printf("%3d ", smem_buf[j][i]);
if (i % 32 == 31) { printf("\n"); };
}
printf("\n");
}
}
4.11.2.2.4. Creating a Template Tensor Map Value Using the Driver API#
The following code creates a minimal tiled-type tensor map that can be subsequently modified on device.
CUtensorMap make_tensormap_template() {
CUtensorMap template_tensor_map{};
auto cuTensorMapEncodeTiled = get_cuTensorMapEncodeTiled();
uint32_t dims_32 = 16;
uint64_t dims_strides_64 = 16;
uint32_t elem_strides = 1;
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&template_tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_UINT8,
1, // cuuint32_t tensorRank,
nullptr, // void *globalAddress,
&dims_strides_64, // const cuuint64_t *globalDim,
&dims_strides_64, // const cuuint64_t *globalStrides,
&dims_32, // const cuuint32_t *boxDim,
&elem_strides, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_NONE,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE);
CU_CHECK(res);
return template_tensor_map;
}
4.11.2.2.5. Shared-Memory Bank Swizzling#
By default, the TMA engine loads data to shared memory in the same order as it is laid out in global memory. However, this layout may not be optimal for certain shared memory access patterns, as it could cause shared memory bank conflicts. To improve performance and reduce bank conflicts, we can change the shared memory layout by applying a ‘swizzle pattern’.
Shared memory has 32 banks that are organized such that successive 32-bit words map to successive banks. Each bank has a bandwidth of 32 bits per clock cycle. When loading and storing shared memory, bank conflicts arise if the same bank is used multiple times within a transaction, resulting in reduced bandwidth. See Shared Memory Access Patterns.
To ensure that data is laid out in shared memory in such a way that user code can avoid shared memory bank conflicts, the TMA engine can be instructed to ‘swizzle’ the data before storing it in shared memory and ‘unswizzle’ it when copying the data back from shared memory to global memory. The tensor map encodes the ‘swizzle mode’ indicating which swizzle pattern is used.
Example: Matrix Transpose
An example is the transpose of a matrix where data is mapped from row to column first access. The data is stored row major in global memory, but we want to also access it column wise in shared memory, which leads to bank conflicts. However, by using the 128 bytes ‘swizzle’ mode and new shared memory indices, they are eliminated.
In the example, we load an 8x8 matrix of type int4, stored as row major in global memory to shared memory. Then, each set of eight
threads loads a row from the shared memory buffer and stores it to a column in a separate transpose shared memory buffer. This
results in an eight-way bank conflict when storing. Finally, the transpose buffer is written back to global memory.
To avoid bank conflicts, the CU_TENSOR_MAP_SWIZZLE_128B layout can be used. This layout matches the 128 bytes row length and
changes the shared memory layout in a way that both the column wise and row wise access don’t require the same banks per transaction.
The two tables, Figure 51 and Figure 52, below show the normal and the swizzled shared memory layout of the 8x8 matrix of type int4 and
its transpose matrix. The colors indicate which of the eight groups of four banks the matrix element is mapped to, and
the margin row and margin column list the global memory row and column indices. The entries show the shared memory
indices of the 16-byte matrix elements.
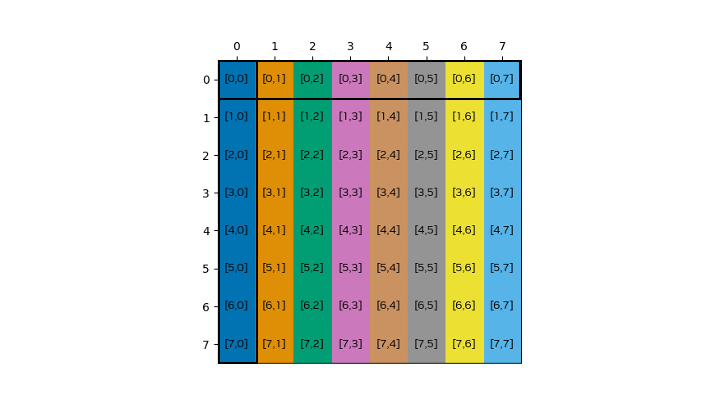
Figure 51 In the shared memory data layout without swizzle, the shared memory indices are equivalent to the global memory indices. Per load instruction, one row is read and stored in a column of the transpose buffer. Since all matrix elements of the column in the transpose fall in the same bank, the store must be serialized, resulting in eight store transactions, giving an eight-way bank conflict per stored column.#
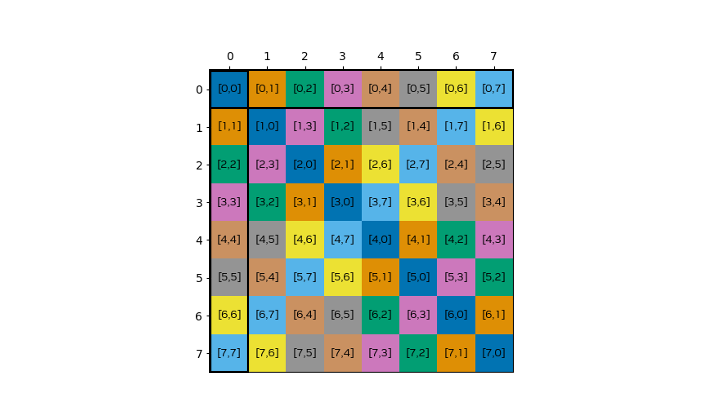
Figure 52 The shared memory data layout with CU_TENSOR_MAP_SWIZZLE_128B swizzle. One row is stored in a column, each matrix
element is from a different bank for both the rows and columns, and so without any bank conflicts.#
__global__ void kernel_tma(const __grid_constant__ CUtensorMap tensor_map) {
// The destination shared memory buffer of a bulk tensor operation
// with the 128-byte swizzle mode, it should be 1024 bytes aligned.
__shared__ alignas(1024) int4 smem_buffer[8][8];
__shared__ alignas(1024) int4 smem_buffer_tr[8][8];
// Initialize shared memory barrier
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier bar;
if (threadIdx.x == 0) {
init(&bar, blockDim.x);
}
__syncthreads();
barrier::arrival_token token;
if (is_elected()) {
// Initiate bulk tensor copy from global to shared memory,
// in the same way as without swizzle.
int32_t tensor_coords[2] = { 0, 0 };
ptx::cp_async_bulk_tensor(
ptx::space_shared, ptx::space_global,
&smem_buffer, &tensor_map, tensor_coords,
cuda::device::barrier_native_handle(bar));
token = cuda::device::barrier_arrive_tx(bar, 1, sizeof(smem_buffer));
} else {
token = bar.arrive();
}
bar.wait(std::move(token));
/* Matrix transpose
* When using the normal shared memory layout, there are eight
* 8-way shared memory bank conflict when storing to the transpose.
* When enabling the 128-byte swizzle pattern and using the according access pattern,
* they are eliminated both for load and store. */
for(int sidx_j =threadIdx.x; sidx_j < 8; sidx_j+= blockDim.x){
for(int sidx_i = 0; sidx_i < 8; ++sidx_i){
const int swiz_j_idx = (sidx_i % 8) ^ sidx_j;
const int swiz_i_idx_tr = (sidx_j % 8) ^ sidx_i;
smem_buffer_tr[sidx_j][swiz_i_idx_tr] = smem_buffer[sidx_i][swiz_j_idx];
}
}
// Wait for shared memory writes to be visible to TMA engine.
ptx::fence_proxy_async(ptx::space_shared);
__syncthreads();
/* Initiate TMA transfer to copy the transposed shared memory buffer back to global memory,
* it will 'unswizzle' the data. */
if (is_elected()) {
int32_t tensor_coords[2] = { x, y };
ptx::cp_async_bulk_tensor(
ptx::space_global, ptx::space_shared,
&tensor_map, tensor_coords, &smem_buffer_tr);
ptx::cp_async_bulk_commit_group();
ptx::cp_async_bulk_wait_group_read(ptx::n32_t<0>());
}
// Destroy barrier
if (threadIdx.x == 0) {
(&bar)->~barrier();
}
}
// --------------------------------- main ----------------------------------------
int main(){
...
void* tensor_ptr = d_data;
CUtensorMap tensor_map{};
// rank is the number of dimensions of the array.
constexpr uint32_t rank = 2;
// global memory size
uint64_t size[rank] = {4*8, 8};
// global memory stride, must be a multiple of 16.
uint64_t stride[rank - 1] = {8 * sizeof(int4)};
// The inner shared memory box dimension in bytes, equal to the swizzle span.
uint32_t box_size[rank] = {4*8, 8};
uint32_t elem_stride[rank] = {1, 1};
// Create the tensor descriptor.
CUresult res = cuTensorMapEncodeTiled(
&tensor_map, // CUtensorMap *tensorMap,
CUtensorMapDataType::CU_TENSOR_MAP_DATA_TYPE_INT32,
rank, // cuuint32_t tensorRank,
tensor_ptr, // void *globalAddress,
size, // const cuuint64_t *globalDim,
stride, // const cuuint64_t *globalStrides,
box_size, // const cuuint32_t *boxDim,
elem_stride, // const cuuint32_t *elementStrides,
CUtensorMapInterleave::CU_TENSOR_MAP_INTERLEAVE_NONE,
// Using a swizzle pattern of 128 bytes.
CUtensorMapSwizzle::CU_TENSOR_MAP_SWIZZLE_128B,
CUtensorMapL2promotion::CU_TENSOR_MAP_L2_PROMOTION_NONE,
CUtensorMapFloatOOBfill::CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE
);
kernel_tma<<<1, 8>>>(tensor_map);
...
}
Remark. This example is supposed to show the use of swizzle and ‘as-is’ is not performant nor does it scale beyond the given dimensions.
Explanation. During data transfer, the TMA engine shuffles the data according to the swizzle pattern, as described in the following
tables. These swizzle patterns define the mapping of the 16-byte chunks along the swizzle width to subgroups of four banks.
It is of type CUtensorMapSwizzle and has four options: none, 32 bytes, 64 bytes and 128 bytes. Note that the shared memory box’s
inner dimension must be less than or equal to the span of the swizzle pattern.
The Swizzle Modes
As previously mentioned, there are four swizzle modes. The following tables show the different swizzle patterns, including the relation of the new shared memory indices. The tables define the mapping of the 16-byte chunks along the 128 bytes to eight subgroups of four banks.
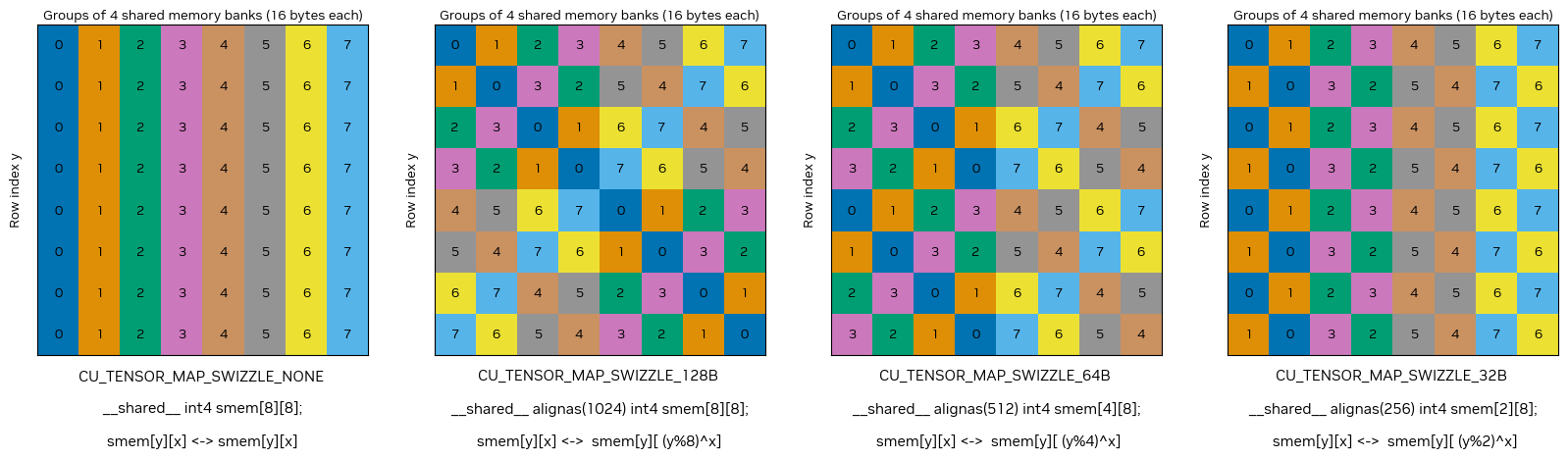
Figure 53 An Overview of TMA Swizzle Patterns#
Considerations. When applying a TMA swizzle pattern, it is crucial to adhere to specific memory requirements:
Global memory alignment: Global memory must be aligned to 128 bytes.
Shared memory alignment: For simplicity shared memory should be aligned according to the number of bytes after which the swizzle pattern repeats. When the shared memory buffer is not aligned by the number of bytes by which the swizzle pattern repeats itself, there is an offset between the swizzle pattern and the shared memory. See comment, below.
Inner dimension: The inner dimension of the shared memory block must meet the size requirements specified in Table 25. If these requirements are not met, the instruction is considered invalid. Additionally, if the swizzle width exceeds the inner dimension, ensure that the shared memory is allocated to accommodate the full swizzle width.
Granularity: The granularity of swizzle mapping is fixed at 16 bytes. This means that data is organized and accessed in chunks of 16 bytes, which must be considered when planning memory layout and access patterns.
Swizzle Pattern Pointer Offset Computation. Here, we describe how to determine the offset between the swizzle pattern and the shared memory, when the shared memory buffer is not aligned by the number of bytes by which the swizzle pattern repeats itself. When using TMA, the shared memory is required to be aligned to 128 bytes. To find how many times the shared memory buffer relative to the swizzle pattern is shifted by that, apply the corresponding offset formula.
Swizzle Mode |
Offset Formula |
Index Relation |
|---|---|---|
CU_TENSOR_MAP_SWIZZLE_128B |
|
|
CU_TENSOR_MAP_SWIZZLE_64B |
|
|
CU_TENSOR_MAP_SWIZZLE_32B |
|
|
In Figure 53, this offset represents the initial row offset, thus, in the swizzle index calculation, it is added to the row index y.
The following snippet shows how to access the swizzled shared memory in the CU_TENSOR_MAP_SWIZZLE_128B mode.
data_t* smem_ptr = &smem[0][0];
int offset = (reinterpret_cast<uintptr_t>(smem_ptr)/128)%8;
smem[y][((y+offset)%8)^x] = ...
Summary. The following Table 25 summarizes the requirements and properties of the different swizzle patterns for Compute Capability 9.
Pattern |
Swizzle width |
Shared box’s inner dimension |
Repeats after |
Shared memory alignment |
Global memory alignment |
|---|---|---|---|---|---|
CU_TENSOR_MAP_SWIZZLE_128B |
128 bytes |
<=128 bytes |
1024 bytes |
128 bytes |
128 bytes |
CU_TENSOR_MAP_SWIZZLE_64B |
64 bytes |
<=64 bytes |
512 bytes |
128 bytes |
128 bytes |
CU_TENSOR_MAP_SWIZZLE_32B |
32 bytes |
<=32 bytes |
256 bytes |
128 bytes |
128 bytes |
CU_TENSOR_MAP_SWIZZLE_NONE (default) |
128 bytes |
16 bytes |
4.11.3. Using STAS#
CUDA applications using thread block clusters may need to move small data elements between thread blocks within the cluster. STAS instructions (CC 9.0+, see PTX documentation) enable asynchronous data copies directly from registers to distributed shared memory. STAS is only exposed through a lower-level cuda::ptx::st_async API available in the libcu++ library.
Dimensions. STAS supports copying 4, 8 or 16 bytes.
Source and destination. The only direction supported for asynchronous copy operations with STAS is from registers to distributed shared memory. The destination pointer needs to be aligned to 4, 8, or 16 bytes depending on the size of the data being copied.
Asynchronicity. Data transfers using STAS are asynchronous and are modeled as async thread operations (see Async Thread and Async Proxy). This allows the initiating thread to continue computing while the hardware asynchronously copies the data. Whether the data transfer occurs asynchronously in practice is up to the hardware implementation and may change in the future. The completion mechanisms that STAS operations can use to signal that they have completed are shared memory barriers.
In the following example, we show how to use STAS to implement a producer-consumer pattern within a thread-block cluster. This kernel creates a circular communication pipeline where 8 thread blocks are arranged in a ring, and each block simultaneously:
Produces data for the next block in the sequence.
Consumes data from the previous block in the sequence.
To implement this pattern, we need 2 shared memory barriers per thread block, one to notify the consumer block that the data has been copied to the shared memory buffer (filled) and one to notify the producer block that the buffer on the consumer is ready to be filled (ready).
#include <cooperative_groups.h>
#include <cuda/barrier>
#include <cuda/ptx>
__global__ __cluster_dims__(8, 1, 1) void producer_consumer_kernel()
{
using namespace cooperative_groups;
using namespace cuda::device;
using namespace cuda::ptx;
using barrier_t = cuda::barrier<cuda::thread_scope_block>;
auto cluster = this_cluster();
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ int buffer[BLOCK_SIZE];
__shared__ barrier_t filled;
__shared__ barrier_t ready;
// Initialize shared memory barriers.
if (threadIdx.x == 0) {
init(&filled, 1);
init(&ready, BLOCK_SIZE);
}
// Sync cluster to ensure remote barriers are initialized.
cluster.sync();
// Define my own and my neighbor's ranks.
int rk = cluster.block_rank();
int rk_next = (rk + 1) % 8;
int rk_prev = (rk + 7) % 8;
// Get addresses of remote buffer we are writing to and remote barriers of previous and next blocks.
auto buffer_next = cluster.map_shared_rank(buffer, rk_next);
auto bar_next = cluster.map_shared_rank(barrier_native_handle(filled), rk_next);
auto bar_prev = cluster.map_shared_rank(barrier_native_handle(ready), rk_prev);
int phase = 0;
for (int it = 0; it < 1000; ++it) {
// As producers, send data to our right neighbor.
st_async(&buffer_next[threadIdx.x], rk, bar_next);
if (threadIdx.x == 0) {
// Thread 0 arrives on local barrier and indicates it expects to receive a certain number of bytes.
mbarrier_arrive_expect_tx(sem_release, scope_cluster, space_shared, barrier_native_handle(filled), sizeof(buffer));
}
// As consumers, wait on local barrier for data from left neighbor to arrive.
while (!mbarrier_try_wait_parity(barrier_native_handle(filled), phase, 1000)) {}
// At this point, the data has been copied to our local buffer.
int r = buffer[threadIdx.x];
// Use the data to do something.
// As consumers, notify our left neighbor that we are done with the data.
mbarrier_arrive(sem_release, scope_cluster, space_cluster, bar_prev);
// As producers, wait on local barrier until the right neighbor is ready to receive new data.
while (!mbarrier_try_wait_parity(barrier_native_handle(ready), phase, 1000)) {}
phase ^= 1;
}
}
|
Shared memory barriers are initialized by the first thread of each block. Barrier
filledis initialized to 1 and barrierreadyis initialized to the number of threads in the block.A cluster-wide synchronization is performed to ensure that all barriers are initialized before any thread starts communication.
Each thread determines its neighbors’ ranks and uses them to map the remote shared memory barriers and the remote shared memory buffer to write data to.
In each iteration:
As a producer, each thread sends data to its right neighbor.
As a consumer, thread 0 arrives on the local
filledbarrier and indicates it expects to receive a certain number of bytes.As a consumer, each thread waits on the local
filledbarrier for data from the left neighbor to arrive.As a consumer, each thread uses the data to do something.
As a consumer, each thread notifies the left neighbor that it is done with the data.
As a producer, each thread waits on the local
readybarrier until the right neighbor is ready to receive new data.
Note that for each barrier, we need to use the correct space. For mapped remote barriers, we need to use the space_cluster space, while for local barriers, we need to use the space_shared space.