4.5. Programmatic Dependent Launch and Synchronization#
The Programmatic Dependent Launch mechanism allows for a dependent secondary kernel to launch before the primary kernel it depends on in the same CUDA stream has finished executing. Available starting with devices of compute capability 9.0, this technique can provide performance benefits when the secondary kernel can complete significant work that does not depend on the results of the primary kernel.
4.5.1. Background#
A CUDA application utilizes the GPU by launching and executing multiple kernels on it. A typical GPU activity timeline is shown in Figure 42.

Figure 42 GPU activity timeline#
Here, secondary_kernel is launched after primary_kernel finishes its execution.
Serialized execution is usually necessary because secondary_kernel depends on result data
produced by primary_kernel. If secondary_kernel has no dependency on primary_kernel,
both of them can be launched concurrently by using CUDA Streams.
Even if secondary_kernel is dependent on primary_kernel, there is some potential for
concurrent execution. For example, almost all the kernels have
some sort of preamble section during which tasks such as zeroing buffers or loading
constant values are performed.
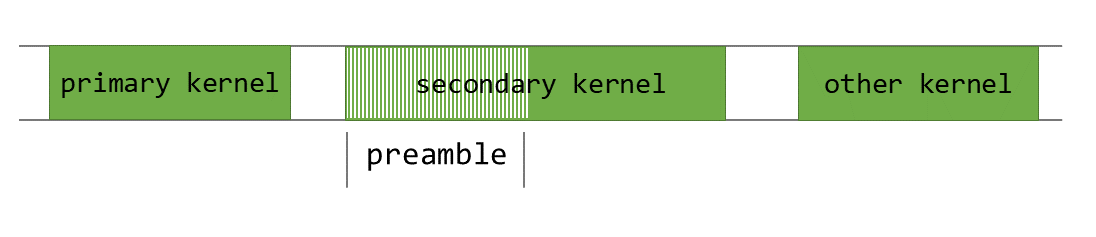
Figure 43 Preamble section of secondary_kernel#
Figure 43 demonstrates the portion of secondary_kernel that could
be executed concurrently without impacting the application.
Note that concurrent launch also allows us to hide the launch latency of secondary_kernel behind
the execution of primary_kernel.
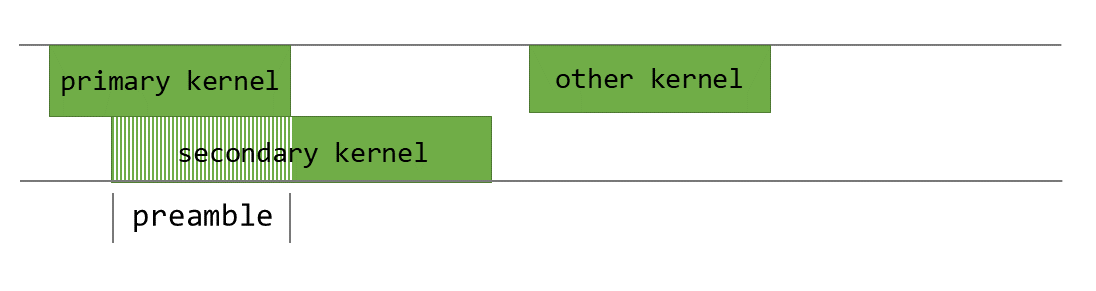
Figure 44 Concurrent execution of primary_kernel and secondary_kernel#
The concurrent launch and execution of secondary_kernel shown in Figure 44 is
achievable using Programmatic Dependent Launch.
Programmatic Dependent Launch introduces changes to the CUDA kernel launch APIs as explained in following section. These APIs require at least compute capability 9.0 to provide overlapping execution.
4.5.2. API Description#
In Programmatic Dependent Launch, a primary and a secondary kernel are launched in the same CUDA stream.
The primary kernel should execute cudaTriggerProgrammaticLaunchCompletion with all thread blocks when
it’s ready for the secondary kernel to launch. The secondary kernel must be launched using the extensible launch API as shown.
__global__ void primary_kernel() {
// Initial work that should finish before starting secondary kernel
// Trigger the secondary kernel
cudaTriggerProgrammaticLaunchCompletion();
// Work that can coincide with the secondary kernel
}
__global__ void secondary_kernel()
{
// Independent work
// Will block until all primary kernels the secondary kernel is dependent on have completed and flushed results to global memory
cudaGridDependencySynchronize();
// Dependent work
}
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeProgrammaticStreamSerialization;
attribute[0].val.programmaticStreamSerializationAllowed = 1;
configSecondary.attrs = attribute;
configSecondary.numAttrs = 1;
primary_kernel<<<grid_dim, block_dim, 0, stream>>>();
cudaLaunchKernelEx(&configSecondary, secondary_kernel);
When the secondary kernel is launched using the cudaLaunchAttributeProgrammaticStreamSerialization attribute,
the CUDA driver is safe to launch the secondary kernel early and not wait on the
completion and memory flush of the primary before launching the secondary.
The CUDA driver can launch the secondary kernel when all primary thread blocks have launched and executed
cudaTriggerProgrammaticLaunchCompletion.
If the primary kernel doesn’t execute the trigger, it implicitly occurs after
all thread blocks in the primary kernel exit.
In either case, the secondary thread blocks might launch
before data written by the primary kernel is visible. As such, when the secondary kernel is configured with Programmatic Dependent Launch,
it must always use cudaGridDependencySynchronize
or other means to verify that the result data from the primary is available.
Please note that these methods provide the opportunity for the primary and secondary kernels to execute concurrently, however this behavior is opportunistic and not guaranteed to lead to concurrent kernel execution. Reliance on concurrent execution in this manner is unsafe and can lead to deadlock.
4.5.3. Use in CUDA Graphs#
Programmatic Dependent Launch can be used in CUDA Graphs via stream capture or
directly via edge data. To program this feature in a CUDA Graph with edge data, use a cudaGraphDependencyType
value of cudaGraphDependencyTypeProgrammatic on an edge connecting two kernel nodes. This edge type makes the upstream kernel
visible to a cudaGridDependencySynchronize() in the downstream kernel. This type must be used with an outgoing port of
either cudaGraphKernelNodePortLaunchCompletion or cudaGraphKernelNodePortProgrammatic.
The resulting graph equivalents for stream capture are as follows:
Stream code (abbreviated) |
Resulting graph edge |
|---|---|
cudaLaunchAttribute attribute;
attribute.id = cudaLaunchAttributeProgrammaticStreamSerialization;
attribute.val.programmaticStreamSerializationAllowed = 1;
|
cudaGraphEdgeData edgeData;
edgeData.type = cudaGraphDependencyTypeProgrammatic;
edgeData.from_port = cudaGraphKernelNodePortProgrammatic;
|
cudaLaunchAttribute attribute;
attribute.id = cudaLaunchAttributeProgrammaticEvent;
attribute.val.programmaticEvent.triggerAtBlockStart = 0;
|
cudaGraphEdgeData edgeData;
edgeData.type = cudaGraphDependencyTypeProgrammatic;
edgeData.from_port = cudaGraphKernelNodePortProgrammatic;
|
cudaLaunchAttribute attribute;
attribute.id = cudaLaunchAttributeProgrammaticEvent;
attribute.val.programmaticEvent.triggerAtBlockStart = 1;
|
cudaGraphEdgeData edgeData;
edgeData.type = cudaGraphDependencyTypeProgrammatic;
edgeData.from_port = cudaGraphKernelNodePortLaunchCompletion;
|