Scheduling APIs#
PVA applications can be further accelerated by fully utilizing all processing units of the PVA hardware. Task-level parallelism can be achieved when tasks are distributed to multiple VPU engines. cuPVA provides scheduling APIs to map tasks to VPUs and synchronize execution when needed.
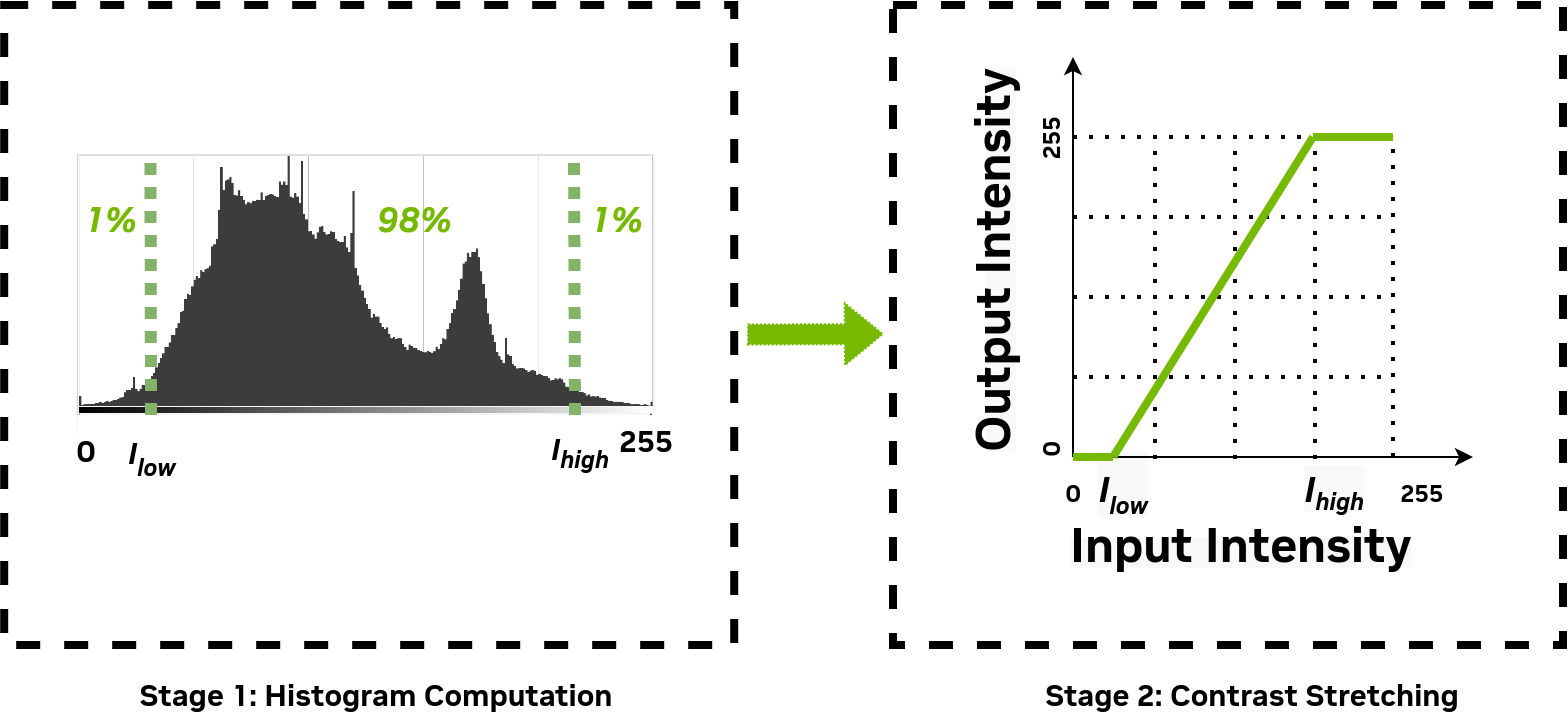
In this tutorial, we extend the contrast stretching example we used in the previous tutorials. A pre-processing stage that involves image histogram computation is carried out to determine the input dynamic range of pixel values that is stretched. 1% of the pixels with low intensity and 1% of the pixels with high intensity ware saturated as shown in the figure below.
Input Image#
We split both histogram computation and contrast stretching stages into two parallel tasks by processing top and bottom halves of the image on two different VPUs. Note that histogram for the whole image should be computed before contrast stretching tasks are launched.
In this tutorial, two different ways to achieve parallelization and synchronization are demonstrated.
Parallelization using two streams and synchronization with CmdWaitOnFences
Automatic parallel scheduling in a single stream and synchronization with CmdBarriers.
Host Code#
The input/output buffers for the histogram computation and contrast stretching tasks are allocated first. The histogram for the top and bottom halves of the image are computed separately and merged within the contrast stretching task.
int main(int argc, char **argv) { int err = 0; if (GetAssetsDirectory(argc, argv, assetsDirectory, MAX_IMAGE_PATH_LENGTH) != 0) { return err; } uint8_t *inputImage_d = nullptr; uint8_t *outputImage_d = nullptr; int32_t *topHalfHistogram_d = nullptr; int32_t *bottomHalfHistogram_d = nullptr; try { cupva::SetVPUPrintBufferSize(64 * 1024); inputImage_d = (uint8_t *)mem::Alloc(IMAGE_WIDTH * REPLICATED_HEIGHT * sizeof(uint8_t)); uint8_t *inputImage_h = (uint8_t *)mem::GetHostPointer(inputImage_d); if (ReadImageBuffer(inputImageName.c_str(), assetsDirectory, inputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT) != 0) { mem::Free(inputImage_d); err = -1; return err; } // Replicate the image to get more meaningful profiling results for (int32_t i = 1; i < REPLICATION_FACTOR; i++) { memcpy(inputImage_h + i * IMAGE_WIDTH * IMAGE_HEIGHT, inputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT); } outputImage_d = (uint8_t *)mem::Alloc(IMAGE_WIDTH * REPLICATED_HEIGHT * sizeof(uint8_t)); uint8_t *outputImage_h = (uint8_t *)mem::GetHostPointer(outputImage_d); topHalfHistogram_d = (int32_t *)mem::Alloc(BIN_COUNT * sizeof(int32_t)); bottomHalfHistogram_d = (int32_t *)mem::Alloc(BIN_COUNT * sizeof(int32_t));
Executables for the histogram computation and contrast stretching algorithms are declared. The tutorial directory includes the VPU codes that use vector instructions for histogram computation and contrast stretching. The device code implementation is not discussed here. Please refer to the code for the details.
Executable execComputeHistogram = Executable::Create(PVA_EXECUTABLE_DATA(scheduling_apis_compute_histogram_dev), PVA_EXECUTABLE_SIZE(scheduling_apis_compute_histogram_dev)); Executable execContrastStretch = Executable::Create(PVA_EXECUTABLE_DATA(contrast_stretch_dev), PVA_EXECUTABLE_SIZE(contrast_stretch_dev));
Two separate CmdPrograms are created for top and bottom halves of the images for each stage. Region-of-Interest (RoI) structures for two halves are used as parameters when setting up to the DataFlows for the CmdPrograms. We do not go into the details for creating the CmdPrograms in this tutorial. The program creation function codes can be examined to see how the DataFlows and program parameters are set.
roiParams roiTopHalf = {.x = 0, // .y = 0, // .width = IMAGE_WIDTH, // .height = REPLICATED_HEIGHT >> 1}; roiParams roiBottomHalf = {.x = 0, // .y = REPLICATED_HEIGHT >> 1, // .width = IMAGE_WIDTH, // .height = REPLICATED_HEIGHT >> 1}; CmdProgram progComputeHistogramTopHalf = CreateComputeHistogramProg(execComputeHistogram, inputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiTopHalf, topHalfHistogram_d); CmdProgram progComputeHistogramBottomHalf = CreateComputeHistogramProg(execComputeHistogram, inputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiBottomHalf, bottomHalfHistogram_d); ContrastStretchParams algParams = { .inputLowPixelValue = 0, .outputLowPixelValue = 0, .inputHighPixelValue = 0, .outputHighPixelValue = 255, .saturationHistogramCountLow = IMAGE_WIDTH * REPLICATED_HEIGHT * SATURATED_PIXEL_PERCENTAGE_LOW_INTENSITY / 100, .saturationHistogramCountHigh = IMAGE_WIDTH * REPLICATED_HEIGHT * SATURATED_PIXEL_PERCENTAGE_HIGH_INTENSITY / 100}; CmdProgram progContrastStretchTopHalf = CreateContrastStretchProg( execContrastStretch, inputImage_d, outputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiTopHalf, &algParams, topHalfHistogram_d, bottomHalfHistogram_d); CmdProgram progContrastStretchBottomHalf = CreateContrastStretchProg( execContrastStretch, inputImage_d, outputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiBottomHalf, &algParams, topHalfHistogram_d, bottomHalfHistogram_d);
Two streams are created for demonstrating the first way of utilizing the two VPU engines in parallel. The VPU affinity for the stream0 and stream1 are set to VPU0 and VPU1 engines of the PVA, respectively. Therefore, we force commands submitted to a stream to be executed on the corresponding VPU.
Stream stream0 = Stream::Create(cupva::PVA0, cupva::VPU0); Stream stream1 = Stream::Create(cupva::PVA0, cupva::VPU1);
The histogram and contrast stretch computation stages for the top half are carried out on VPU0 as you see in the next step. We create two fences per stream to signal the completion of each stage.
fence0_0signals the completion of the histogram computation submitted to stream0 andfence0_1signals the completion of contrast stretching task on the same stream. Similar notation is used for the fences that are triggered in stream1.SyncObj sync0 = SyncObj::Create(); SyncObj sync1 = SyncObj::Create(); Fence fence0_0{sync0}; Fence fence0_1{sync0}; Fence fence1_0{sync1}; Fence fence1_1{sync1};
The second stage of the application, contrast stretching, requires the histogram for the whole image. Therefore, the ComputeHistogram programs for the top and bottom halves are submitted first. They execute in parallel on two separate VPUs.
The CmdRequestFences commands are initialized with the fences that signal the completion of histogram computation tasks. The fences are triggered when the corresponding CmdRequestFences commands are executed. Note that stream submission is a non-blocking call that does not wait for the command execution.
CmdRequestFences requestFences0_0{fence0_0}; CmdRequestFences requestFences1_0{fence1_0}; stream0.submit({&progComputeHistogramTopHalf, &requestFences0_0}); stream1.submit({&progComputeHistogramBottomHalf, &requestFences1_0});
Contrast stretching tasks require the histogram output from the first stage tasks.
progContrastStretchTopHalfis guaranteed to execute afterprogComputeHistogramTopHalfsince both are submitted to stream0. Note that the tasks submitted to the same stream are executed in submission order by default.We need to make sure
progComputeHistogramBottomHalfsubmitted to stream1 also gets completed prior to the execution ofprogContrastStretchTopHalf.CmdWaitOnFencesAPI enables synchronization between tasks executed on different processing units. TheCmdWaitOnFencescommand,waitOnFences1, submitted to stream0 before the CmdProgram blocks the execution until fence1_0 is triggered.Expiration of both fence0_1 and fence1_1 means the stage two for the whole image is completed.
CmdWaitOnFences waitOnFences0{fence0_0}; CmdWaitOnFences waitOnFences1{fence1_0}; CmdRequestFences requestFences0_1{fence0_1}; CmdRequestFences requestFences1_1{fence1_1}; stream0.submit({&waitOnFences1, &progContrastStretchTopHalf, &requestFences0_1}); stream1.submit({&waitOnFences0, &progContrastStretchBottomHalf, &requestFences1_1}); fence0_1.wait(); fence1_1.wait();
cuPVA also provides an alternative mechanism to automatically achieve task level parallelism with a single stream. Different VPU engines can be used to process multiple independent commands in parallel when commands are submitted to a stream, configured to use VPU_ANY affinity, using the OUT_OF_ORDER option.
Commands submitted in OUT_OF_ORDER mode begin execution in submission order, but may complete out of order. Completion ordering in OUT_OF_ORDER mode can be enforced via CmdBarrier command. CmdBarrier blocks stream processing until all preceding commands are completed.
The barrier command submitted in between the histogram and stretching programs makes sure top and bottom histograms are computed first. A barrier is also inserted before the final CmdRequestFences command so that it is executed after the contrast stretching tasks are completed.
OUT_OF_ORDER mode provides a simple and efficient task scheduling method for fully utilizing the PVA hardware.
Stream stream2 = Stream::Create(); cupva::CmdBarrier barrier; stream2.submit({&progComputeHistogramTopHalf, &progComputeHistogramBottomHalf, &barrier, &progContrastStretchTopHalf, &progContrastStretchBottomHalf, &barrier, &requestFences1_1}, nullptr, cupva::OUT_OF_ORDER); fence1_1.wait();
The main function gets terminated after freeing the allocated buffers.
if (WriteImageBuffer(outputImageName.c_str(), ".", outputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT) != 0) { err = -1; } } catch (cupva::Exception const &e) { std::cout << "Caught a cuPVA exception with message: " << e.what() << std::endl; err = 1; } mem::Free(inputImage_d); mem::Free(outputImage_d); mem::Free(topHalfHistogram_d); mem::Free(bottomHalfHistogram_d); return err; }
The input/output buffers for the histogram computation and contrast stretching tasks are allocated first. The histogram for the top and bottom halves of the image are computed separately and merged within the contrast stretching task.
int main(int argc, char **argv) { int32_t err = 0; int32_t createdExecCount = 0; int32_t createdStreamCount = 0; int32_t createdSyncObjCount = 0; if (GetAssetsDirectory(argc, argv, assetsDirectory, MAX_IMAGE_PATH_LENGTH) != 0) { return 0; } CHECK_ERROR_GOTO(CupvaSetVPUPrintBufferSize(64 * 1024), err, MemAllocFailed); uint8_t *inputImage_d = NULL; uint8_t *outputImage_d = NULL; int32_t *topHalfHistogram_d = NULL; int32_t *bottomHalfHistogram_d = NULL; CHECK_ERROR_GOTO(CupvaMemAlloc((void **)&inputImage_d, IMAGE_WIDTH * REPLICATED_HEIGHT * sizeof(uint8_t), CUPVA_READ_WRITE, CUPVA_ALLOC_DRAM), err, MemAllocFailed); uint8_t *inputImage_h = NULL; CHECK_ERROR_GOTO(CupvaMemGetHostPointer((void **)&inputImage_h, (void *)inputImage_d), err, MemAllocFailed); if (ReadImageBuffer(INPUT_IMAGE_NAME, assetsDirectory, inputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT) != 0) { err = -1; goto MemAllocFailed; } /* Replicate the image to get more meaningful profiling results */ for (int32_t i = 1; i < REPLICATION_FACTOR; i++) { memcpy(inputImage_h + i * IMAGE_WIDTH * IMAGE_HEIGHT, inputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT); } CHECK_ERROR_GOTO(CupvaMemAlloc((void **)&outputImage_d, IMAGE_WIDTH * REPLICATED_HEIGHT * sizeof(uint8_t), CUPVA_READ_WRITE, CUPVA_ALLOC_DRAM), err, MemAllocFailed); uint8_t *outputImage_h = NULL; CHECK_ERROR_GOTO(CupvaMemGetHostPointer((void **)&outputImage_h, (void *)outputImage_d), err, MemAllocFailed); CHECK_ERROR_GOTO( CupvaMemAlloc((void **)&topHalfHistogram_d, BIN_COUNT * sizeof(int32_t), CUPVA_READ_WRITE, CUPVA_ALLOC_DRAM), err, MemAllocFailed); CHECK_ERROR_GOTO( CupvaMemAlloc((void **)&bottomHalfHistogram_d, BIN_COUNT * sizeof(int32_t), CUPVA_READ_WRITE, CUPVA_ALLOC_DRAM), err, MemAllocFailed);
Executables for the histogram computation and contrast stretching algorithms are declared. The tutorial directory includes the VPU codes that use vector instructions for histogram computation and contrast stretching. The device code implementation is not discussed here. Please refer to the code for the details.
cupvaExecutable_t execs[2]; CHECK_ERROR_GOTO( CupvaExecutableCreate(&execs[0], PVA_EXECUTABLE_DATA(scheduling_apis_compute_histogram_dev), PVA_EXECUTABLE_SIZE(scheduling_apis_compute_histogram_dev)), err, ExecutableCreateFailed); createdExecCount++; CHECK_ERROR_GOTO(CupvaExecutableCreate(&execs[1], PVA_EXECUTABLE_DATA(contrast_stretch_dev), PVA_EXECUTABLE_SIZE(contrast_stretch_dev)), err, ExecutableCreateFailed); createdExecCount++;
Two separate CmdPrograms are created for top and bottom halves of the images for each stage. Region-of-Interest (RoI) structures for two halves are used as parameters when setting up to the DataFlows for the CmdPrograms. We do not go into the details for creating the CmdPrograms in this tutorial. The program creation function codes can be examined to see how the DataFlows and program parameters are set.
roiParams roiTopHalf = {.x = 0, // .y = 0, // .width = IMAGE_WIDTH, // .height = REPLICATED_HEIGHT >> 1}; roiParams roiBottomHalf = {.x = 0, // .y = REPLICATED_HEIGHT >> 1, // .width = IMAGE_WIDTH, // .height = REPLICATED_HEIGHT >> 1}; int32_t createdCmdProgramCount = 0; cupvaCmd_t progs[4]; CHECK_ERROR_GOTO( CreateComputeHistogramProg(&progs[0], &execs[0], inputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiTopHalf, topHalfHistogram_d, &createdCmdProgramCount), err, CmdProgramCreateFailed); CHECK_ERROR_GOTO( CreateComputeHistogramProg(&progs[1], &execs[0], inputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiBottomHalf, bottomHalfHistogram_d, &createdCmdProgramCount), err, CmdProgramCreateFailed); ContrastStretchParams algParams = { .inputLowPixelValue = 0, .outputLowPixelValue = 0, .inputHighPixelValue = 0, .outputHighPixelValue = 255, .saturationHistogramCountLow = IMAGE_WIDTH * REPLICATED_HEIGHT * SATURATED_PIXEL_PERCENTAGE_LOW_INTENSITY / 100, .saturationHistogramCountHigh = IMAGE_WIDTH * REPLICATED_HEIGHT * SATURATED_PIXEL_PERCENTAGE_HIGH_INTENSITY / 100}; CHECK_ERROR_GOTO(CreateContrastStretchProg(&progs[2], &execs[1], inputImage_d, outputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiTopHalf, &algParams, topHalfHistogram_d, bottomHalfHistogram_d, &createdCmdProgramCount), err, CmdProgramCreateFailed); CHECK_ERROR_GOTO(CreateContrastStretchProg(&progs[3], &execs[1], inputImage_d, outputImage_d, IMAGE_WIDTH, REPLICATED_HEIGHT, TILE_WIDTH, TILE_HEIGHT, &roiBottomHalf, &algParams, topHalfHistogram_d, bottomHalfHistogram_d, &createdCmdProgramCount), err, CmdProgramCreateFailed);
Two streams are created for demonstrating the first way of utilizing the two VPU engines in parallel. The VPU affinity for the streams[0] and streams[1] are set to VPU0 and VPU1 engines of the PVA, respectively. Therefore, we force commands submitted to a stream to be executed on the corresponding VPU.
cupvaStream_t streams[3]; CHECK_ERROR_GOTO(CupvaStreamCreate(&streams[0], CUPVA_PVA0, CUPVA_VPU0), err, StreamSyncObjCreateFailed); createdStreamCount++; CHECK_ERROR_GOTO(CupvaStreamCreate(&streams[1], CUPVA_PVA0, CUPVA_VPU1), err, StreamSyncObjCreateFailed); createdStreamCount++;
The histogram and contrast stretch computation stages for the top half are carried out on VPU0 as you see in the next step. We create two fences per stream to signal the completion of each stage.
fences0[0]signals the completion of the histogram computation submitted to stream0 andfences0[1]signals the completion of contrast stretching task on the same stream. Similar notation is used for the fences that are triggered in stream[1].cupvaSyncObj_t syncs[2]; for (int32_t i = 0; i < 2; i++) { CHECK_ERROR_GOTO(CupvaSyncObjCreate(&syncs[i], false, CUPVA_SIGNALER_WAITER, CUPVA_SYNC_YIELD), err, StreamSyncObjCreateFailed); createdSyncObjCount++; } cupvaFence_t fences0[2]; for (int32_t i = 0; i < 2; i++) { CHECK_ERROR_GOTO(CupvaFenceInit(&fences0[i], syncs[0]), err, StreamSyncObjCreateFailed); } cupvaFence_t fences1[2]; for (int32_t i = 0; i < 2; i++) { CHECK_ERROR_GOTO(CupvaFenceInit(&fences1[i], syncs[1]), err, StreamSyncObjCreateFailed); }
The second stage of the application, contrast stretching, requires the histogram for the whole image. Therefore, the ComputeHistogram programs for the top and bottom halves are submitted first. They execute in parallel on two separate VPUs.
The CmdRequestFences commands are initialized with the fences that signal the completion of histogram computation tasks. The fences are triggered when the corresponding CmdRequestFences commands are executed. Note that stream submission is a non-blocking call that does not wait for the command execution.
cupvaCmd_t requestFences0[2]; cupvaCmd_t requestFences1[2]; CHECK_ERROR_GOTO(CupvaCmdRequestFencesInit(&requestFences0[0], &fences0[0], 1), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaCmdRequestFencesInit(&requestFences1[0], &fences1[0], 1), err, StreamSyncObjCreateFailed); cupvaCmd_t const *histogramComputeCmds0[2] = {&progs[0], &requestFences0[0]}; CHECK_ERROR_GOTO(CupvaStreamSubmit(streams[0], histogramComputeCmds0, NULL, 2, CUPVA_IN_ORDER, -1, -1), err, StreamSyncObjCreateFailed); cupvaCmd_t const *histogramComputeCmds1[2] = {&progs[1], &requestFences1[0]}; CHECK_ERROR_GOTO(CupvaStreamSubmit(streams[1], histogramComputeCmds1, NULL, 2, CUPVA_IN_ORDER, -1, -1), err, StreamSyncObjCreateFailed);
Contrast stretching tasks require the histogram output from the first stage tasks. Contrast Stretch program for the Top Half (progs[2]) is guaranteed to execute after Compute Histogram program for the Top Half (progs[0]) since both are submitted to stream[0]. Note that the tasks submitted to the same stream are executed in submission order by default.
We need to make sure Compute Histogram program for Bottom Half (progs[1]) submitted to stream[1] also gets completed prior to the execution of Contrast Stretch program for the Top Half (progs[3]). CmdWaitOnFences API enables synchronization between tasks executed on different processing units. The CmdWaitOnFences command, waitOnFences1, submitted to stream[0] before the CmdProgram blocks the execution until fences1[0] is triggered.
Expiration of both fences0[1] and fences1[1] means the stage two for the whole image is completed.
cupvaCmd_t waitOnFences0; cupvaCmd_t waitOnFences1; CHECK_ERROR_GOTO(CupvaCmdWaitOnFencesInit(&waitOnFences0, &fences0[0], 1), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaCmdWaitOnFencesInit(&waitOnFences1, &fences1[0], 1), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaCmdRequestFencesInit(&requestFences0[1], &fences0[1], 1), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaCmdRequestFencesInit(&requestFences1[1], &fences1[1], 1), err, StreamSyncObjCreateFailed); cupvaCmd_t const *contrastStretchCmds0[3] = {&waitOnFences1, &progs[2], &requestFences0[1]}; CHECK_ERROR_GOTO(CupvaStreamSubmit(streams[0], contrastStretchCmds0, NULL, 3, CUPVA_IN_ORDER, -1, -1), err, StreamSyncObjCreateFailed); cupvaCmd_t const *contrastStretchCmds1[3] = {&waitOnFences0, &progs[3], &requestFences1[1]}; CHECK_ERROR_GOTO(CupvaStreamSubmit(streams[1], contrastStretchCmds1, NULL, 3, CUPVA_IN_ORDER, -1, -1), err, StreamSyncObjCreateFailed); bool waitSuccess; CHECK_ERROR_GOTO(CupvaFenceWait(&fences0[1], -1, &waitSuccess), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaFenceWait(&fences1[1], -1, &waitSuccess), err, StreamSyncObjCreateFailed);
cuPVA also provides an alternative mechanism to automatically achieve task level parallelism with a single stream. Different VPU engines can be used to process multiple independent commands in parallel when commands are submitted to a stream, configured to use
CUPVA_VPU_ANYaffinity, using theCUPVA_OUT_OF_ORDERoption.Commands submitted in OUT_OF_ORDER mode begin execution in submission order, but may complete out of order. Completion ordering in OUT_OF_ORDER mode can be enforced via CmdBarrier command. CmdBarrier blocks stream processing until all preceding commands are completed.
The barrier command submitted in between the histogram and stretching programs makes sure top and bottom histograms are computed first. A barrier is also inserted before the final CmdRequestFences command so that it is executed after the contrast stretching tasks are completed.
OUT_OF_ORDER mode provides a simple and efficient task scheduling method for fully utilizing the PVA hardware.
CHECK_ERROR_GOTO(CupvaStreamCreate(&streams[2], CUPVA_PVA0, CUPVA_VPU_ANY), err, StreamSyncObjCreateFailed); createdStreamCount++; cupvaCmd_t barrier; CHECK_ERROR_GOTO(CupvaCmdBarrierInit(&barrier), err, StreamSyncObjCreateFailed); cupvaCmd_t const *cmds[7] = {&progs[0], &progs[1], &barrier, &progs[2], &progs[3], &barrier, &requestFences1[1]}; CHECK_ERROR_GOTO(CupvaStreamSubmit(streams[2], cmds, NULL, 7, CUPVA_OUT_OF_ORDER, -1, -1), err, StreamSyncObjCreateFailed); CHECK_ERROR_GOTO(CupvaFenceWait(&fences1[1], -1, &waitSuccess), err, StreamSyncObjCreateFailed);
The main function gets terminated after deallocating the resources.
if (WriteImageBuffer(OUTPUT_IMAGE_NAME, ".", outputImage_h, IMAGE_WIDTH * IMAGE_HEIGHT) != 0) { err = -1; goto StreamSyncObjCreateFailed; } StreamSyncObjCreateFailed: for (int32_t i = 0; i < createdSyncObjCount; i++) { CupvaSyncObjDestroy(syncs[i]); } for (int32_t i = 0; i < createdStreamCount; i++) { CupvaStreamDestroy(streams[i]); } CmdProgramCreateFailed: for (int32_t i = 0; i < createdCmdProgramCount; i++) { CupvaCmdDestroy(&progs[i]); } ExecutableCreateFailed: for (int32_t i = 0; i < createdExecCount; i++) { CupvaExecutableDestroy(execs[i]); } MemAllocFailed: CupvaMemFree(inputImage_d); CupvaMemFree(outputImage_d); CupvaMemFree(topHalfHistogram_d); CupvaMemFree(bottomHalfHistogram_d); return err; }
Output#
The path to the Tutorial assets directory containing the input image file low-contrast-kodim08-768x512-grayscale.data
should be provided as an argument.
The enhanced image output file unsharp-masked-kodim08-768x512-grayscale.data is written to the current working directory.
$ ./scheduling_apis_cpp -a <Tutorial Assets Directory Path>
Read 393216 bytes from <Tutorial Assets Directory Path>/low-contrast-kodim08-768x512-grayscale.data
Wrote 393216 bytes to ./contrast-stretched-kodim08-768x512-grayscale.data
$ ./scheduling_apis_c -a <Tutorial Assets Directory Path>
Read 393216 bytes from <Tutorial Assets Directory Path>/low-contrast-kodim08-768x512-grayscale.data
Wrote 393216 bytes to ./contrast-stretched-kodim08-768x512-grayscale.data
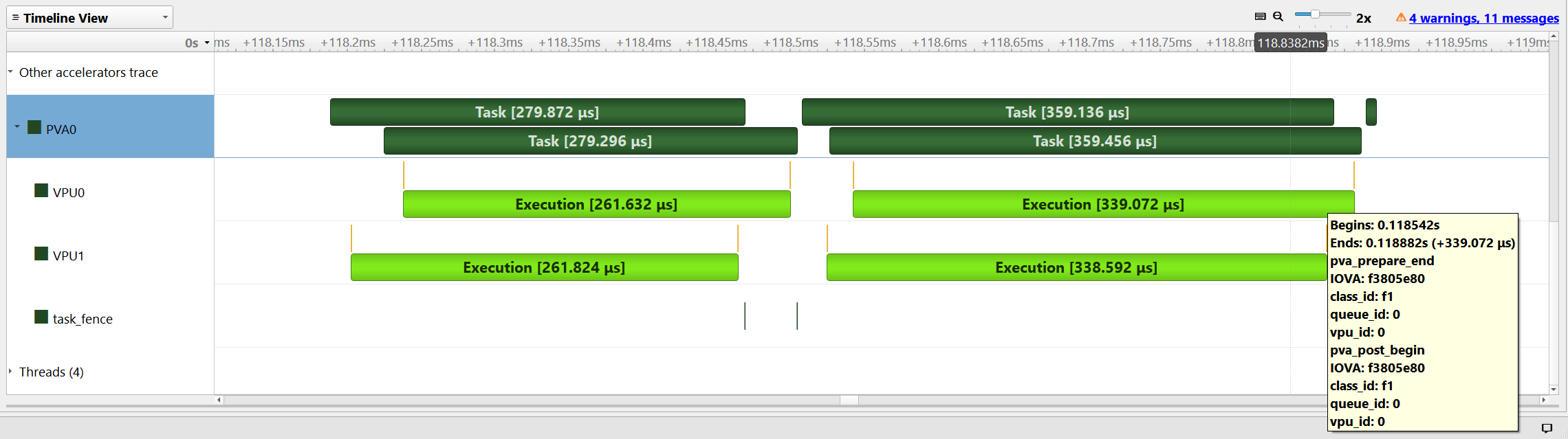
The Nsight Systems profiling output is presented to demonstrate the scheduling of the tasks. The timing diagrams for both two stream scheduling and single stream out-of-order execution is provided. The parallel execution of the independent tasks can be seen in both diagrams.
Two rows under the PVA0 tab named as “VPU0” and “VPU1” display the VPU specific execution schedule. The details of a specific task can be viewed when the mouse pointer hovers over the light green colored VPU task bars, as can be seen in the below screenshots.
Note that the timings are acquired for a ~ 6 MP (768 x 8172) image to clearly highlight parallel execution since the VPU execution if very fast.
1. Two Streams - In-order execution#
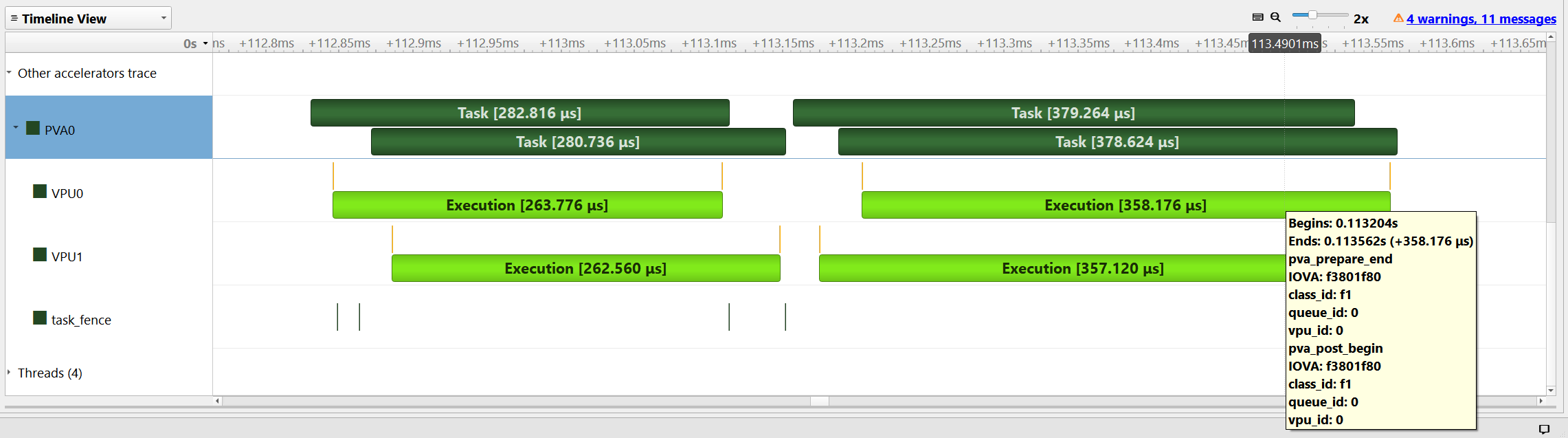
2. Single Stream - Out-of-order execution#