NVIPC Overview#
This section provides an overview of NVIPC messaging functionality.
NVIPC Message Transfer#
To achieve low-latency and high performance, NVIPC uses lock-free memory pools and lock-free queues to deliver the messages. The message transfer module architecture is as below.
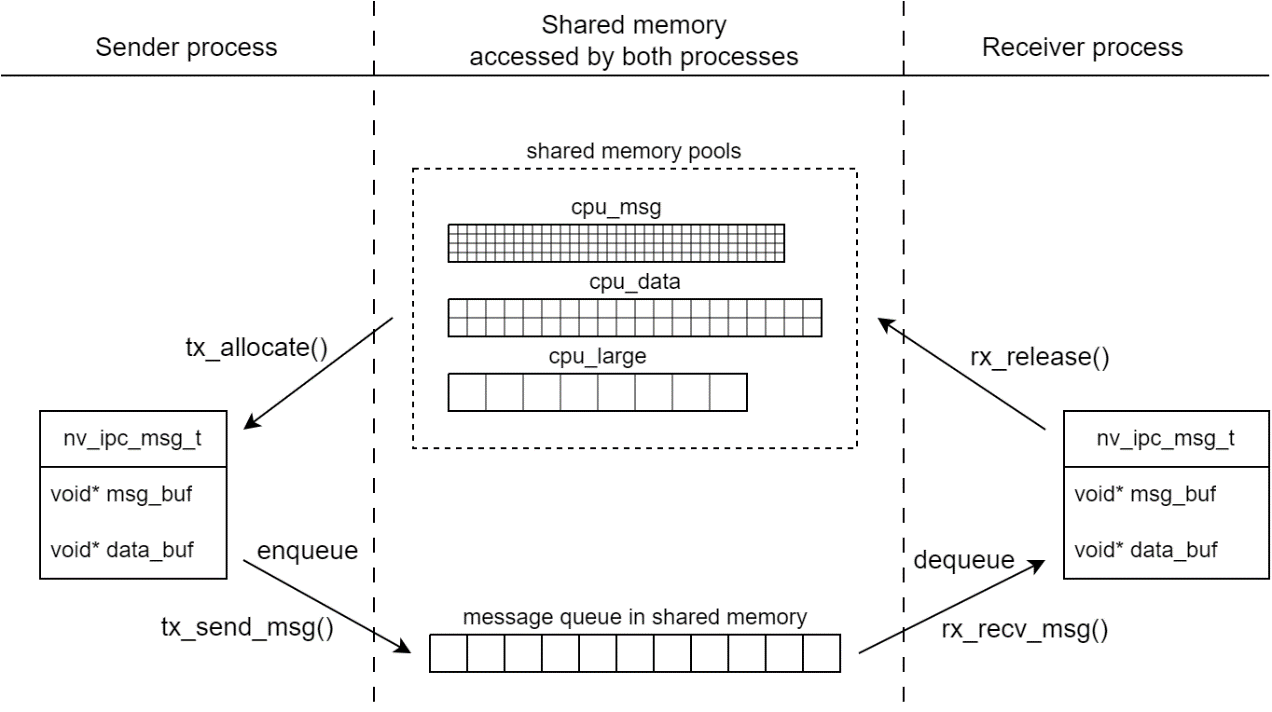
NVIPC API Definitions#
An NVIPC message is divided into two parts:
MSG: Handled in control logic which runs in CPU thread.
DATA: Handled with high performance computing which runs in CPU thread or GPU context.
A struct nv_ipc_msg_t is defined to represent a generic NVIPC message, as shown
below.
typedef struct
{
int32_t msg_id; // IPC message ID
int32_t cell_id; // Cell ID
int32_t msg_len; // MSG part length
int32_t data_len; // DATA part length
int32_t data_pool; // DATA memory pool ID
void* msg_buf; // MSG buffer pointer
void* data_buf; // DATA buffer pointer
} nv_ipc_msg_t;
The MSG part and DATA part are stored in different buffers. MSG part
presence is mandatory, DATA part presence is optional. data_buf is null
when there is no DATA part present.
NVIPC creates multiple memory pools at initial to manage the MSG part
and DATA part buffers. An enum type nv_ipc_mempool_id_t is defined as
the memory pool indicator. MSG buffer is allocated from CPU shared
memory pool. DATA buffer can be allocated from CPU shared memory pool or
CUDA shared memory pool.
typedef enum
{
NV_IPC_MEMPOOL_CPU_MSG = 0, // CPU SHM pool for MSG part
NV_IPC_MEMPOOL_CPU_DATA = 1, // CPU SHM pool for DATA part
NV_IPC_MEMPOOL_CPU_LARGE = 2, // CPU SHM pool for large DATA part
NV_IPC_MEMPOOL_CUDA_DATA = 3, // CUDA SHM pool for DATA part
NV_IPC_MEMPOOL_GPU_DATA = 4, // CUDA SHM pool which supports GDR copy
NV_IPC_MEMPOOL_NUM = 5
} nv_ipc_mempool_id_t;
And a series of APIs are defined in struct
struct nv_ipc_t
{
// De-initiate and destroy the nv_ipc_t instance
int (*ipc_destroy)(nv_ipc_t* ipc);
// Memory allocate/release for TX side
int (*tx_allocate)(nv_ipc_t* ipc, nv_ipc_msg_t* msg, uint32_t options);
int (*tx_release)(nv_ipc_t* ipc, nv_ipc_msg_t* msg);
// Memory allocate/release for RX side
int (*rx_allocate)(nv_ipc_t* ipc, nv_ipc_msg_t* msg, uint32_t options);
int (*rx_release)(nv_ipc_t* ipc, nv_ipc_msg_t* msg);
// Send a ipc_msg_t message. Return -1 if failed
int (*tx_send_msg)(nv_ipc_t* ipc, nv_ipc_msg_t* msg);
// Call tx_tti_sem_post() at the end of a TTI
int (*tx_tti_sem_post)(nv_ipc_t* ipc);
// Call rx_tti_sem_wait() and then receive all messages in a TTI
int (*rx_tti_sem_wait)(nv_ipc_t* ipc);
// Get a ipc_msg_t message. Return -1 if no available.
int (*rx_recv_msg)(nv_ipc_t* ipc, nv_ipc_msg_t* msg);
// Get SHM event FD or UDP socket FD for epoll
int (*get_fd)(nv_ipc_t* ipc);
// Write tx_fd to notify the event, Only need for SHM
int (*notify)(nv_ipc_t* ipc, int value);
// Read rx_fd to clear the event. Only need for SHM
int (*get_value)(nv_ipc_t* ipc);
// CUDA memory copy function
int (*cuda_memcpy_to_host)(nv_ipc_t* ipc, void* host, const void* device, size_t size);
int (*cuda_memcpy_to_device)(nv_ipc_t* ipc, void* device, const void* host, size_t size);
// GDR copy function
int (*gdr_memcpy_to_host)(nv_ipc_t* ipc, void* host, const void* device, size_t size);
int (*gdr_memcpy_to_device)(nv_ipc_t* ipc, void* device, const void* host, size_t size);
};
Lock-Free Data Structures#
A lock-free queue named “array queue” is implemented in NVIPC. The array queue has the following features:
FIFO (first in first out).
Lock-free: supports multiple producers and multiple consumers without lock.
Finite size: max length is defined at initial: N.
Valid values are integers:
0, 1, …, N-1,can be used as the node index/pointer.Doesn’t support duplicate values.
Based on the lock-free array queue, generic memory pools and ring queues are implemented, and they are also lock-free:
Memory pool: array queue + memory buffer array
FIFO ring queue: array queue + element node array
NVIPC Memory Pools#
Several shared memory pools are implemented in NVIPC. They are accessible by both the primary process and the secondary process. Each memory pool is an array of fixed size buffers. Buffer size and pool length (buffer count) are configurable by yaml file. If the buffer size or pool length is configured to 0, that memory pool will not be created. Below is the default NVIPC memory pools configuration which is used in cuPHY-CP.
Memory Pool ID |
SHM file name at |
Comment |
|---|---|---|
|
|
CPU memory for transfer MSG part. |
|
|
CPU memory for transfer DATA part. |
|
|
CPU memory for transfer large DATA part. |
|
|
GPU memory. Not used. |
|
|
GPU memory with GDR copy. Not used. |
After NVIPC primary app initialized, the SHM files will present in
/dev/shm/ folder.
Bi-Directional Message Queues#
Two ring queues will be created to deliver the message buffer indices. The TX ring in sender app and RX ring in receiver app are the same ring in shared memory of the system. Both DL and UL ring queues are stored in the same shared memory file.
SHM file name at |
Internal code name |
IPC direction |
PHY /PRIMARY |
MAC /SECONDARY |
|---|---|---|---|---|
|
|
Uplink |
TX |
RX |
|
|
Downlink |
RX |
TX |
NVIPC message notification#
NVIPC uses Linux event_fd to make notifications. It supports multiple
I/O with select /poll/epoll mechanism. The message notification module
architecture is as below.
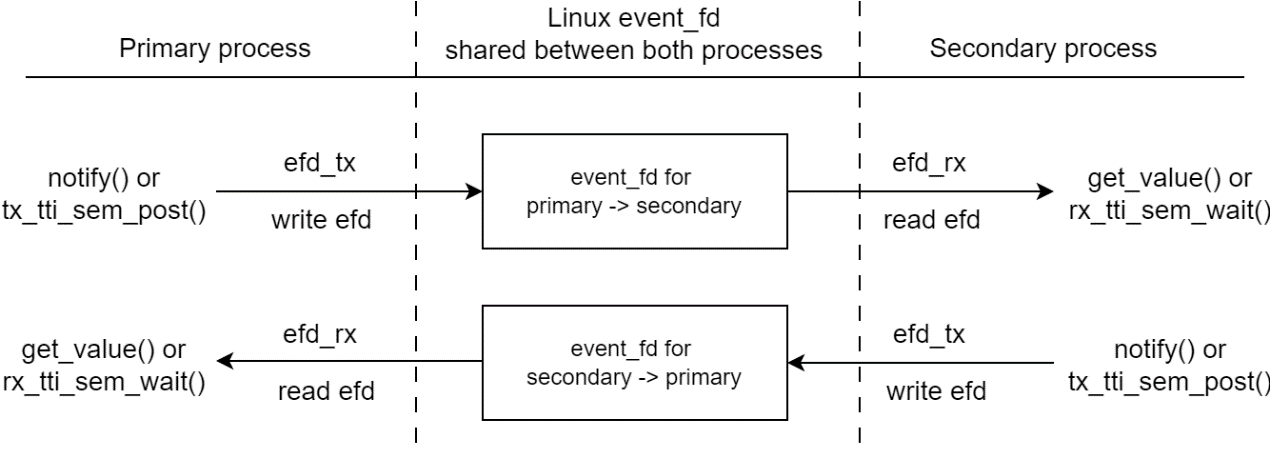
Each process creates an event_fd file descriptor efd_rx for incoming
message notification and share it with peer process. The local efd_rx
for receiving is shared as efd_tx for sending in peer side. Receiver
process can call get_fd() to get the I/O descriptor and use poll/epoll
to get the notification. Besides, the event_fd is initiated with
EFD_SEMAPHORE flag so it can work like a semaphore. NVIPC provides both
event/select style and semaphore style notification APIs.
NVIPC message flow#
A typical message transfer flow is shown below.

Since the memory pools and ring queues support lockless concurrency,
the use of notification APIs is not mandatory. If users don’t want to use
notification, the receiver should poll the incoming message queue by
keep dequeueing from the lock-free queue. rx_recv_msg() function returns
-1 when the queue is empty.