Examples#
4T4R Scheduler Performance Test#
cuMAC contains a testbench (/opt/nvidia/cuBB/cuMAC/examples/multiCellSchedulerUeSelection) for performing
simplified system-level simulations to evaluate the performance of the 4T4R scheduler algorithm implementations.
For each simulation, the testbench runs for a given number of contiguous time slots, and in each slot executes scheduling algorithms sequentially in the following order:
UE selection > PRG allocation > layer selection > MCS selection.
The parameter setup for the simulation is configured using the file /opt/nvidia/cuBB/cuMAC/examples/parameters.h.
Parameters like the simulation duration numSimChnRlz, the number of cells numCellConst, and the number of gNB/UE antennas nBsAntConst / nUeAntConst,
among others, can be adjusted in this file to meet the specific simulation requirements.
KPIs such as the sum cell throughput, per-UE throughput, and proportional fairness metrics can be obtained from the simulations for analyzing the scheduler algorithms’ performance.
This testbench supports running different 4T4R scheduler algorithms on GPU and CPU, e.g., a multi-cell scheduler running on GPU versus a single-cell scheduler running on CPU.
It enables the comparison of different algorithms’ performance through a single simulation run.
An example figure with the cell sum throughput curves of the multi-cell and single-cell schedulers is provided below:
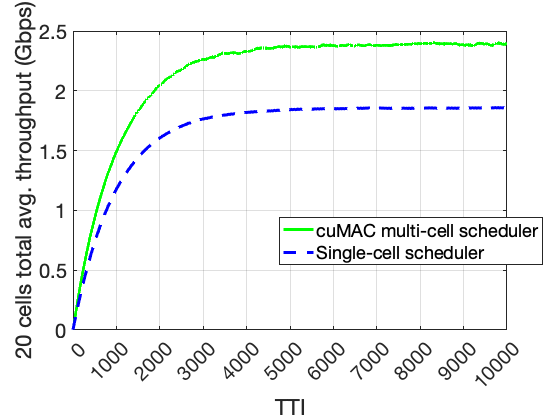
Cell sum throughput curves comparison: multi-cell scheduler vs. single-cell scheduler#
This testbench can be also used to validate the GPU/CUDA algorithm implementations against the CPU C++ versions of the same algorithm. This can be done by configuring the same scheduler algorithm for both GPU and CPU in the simulation. At the end of the simulation, the gaps between the GPU and CPU performance curves are evaluated. The testbench returns 0 (success) if the performance curve gaps are less than the tolerance threshold; otherwise, it returns 1 (failure).
After building cuMAC, use the following command to check input arguments of the testbench:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellSchedulerUeSelection/multiCellSchedulerUeSelection -h
The testbench currently supports two different channel modeling approaches in the system simulations, including a time-correlated Rayleigh fading model and a GPU-accelerated TDL channel model.
Use the input argument -f 0 or -f 1 to specify the desired channel model: -f 0 for Rayleigh fading and -f 1 for the TDL channel model.
To run system simulation with the DL/UL scheduler pipeline:
Configure simulation parameters in the
/opt/nvidia/cuBB/cuMAC/examples/parameters.hfile.Build cuMAC under
/opt/nvidia/cuBB/cuMAC.Run simulation with the DL/UL scheduler pipeline:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellSchedulerUeSelection/multiCellSchedulerUeSelection -d [0 or 1 for DL/UL] -f [0 or 1 for channel model] -b [0 or 1 for CPU algorithm choice] -p [0 or 1 for FP32/FP16 on GPU]
Passing criteria:
Performance curves achieved by GPU and CPU scheduler implementations should match: testbench returns 0 (PASS) or 1 (FAIL)
Two types of performance curves are considered:
Sum throughput of all cells
CDF of per-UE throughput
cuMAC Test Vector Generation#
cuMAC supports the generation of HDF5 test vectors using the multiCellSchedulerUeSelection system simulation testbench.
Each test vector contains parameters and data arrays defined in the cuMAC API structures (/opt/nvidia/cuBB/cuMAC/src/api.h):
cumacCellGrpUeStatus, cumacCellGrpPrms, and cumacSchdSol.
When a simulation with the testbench is completed (after a configured number of time slots), a HDF5 test vector file is created, with data collected from the last simulated slot.
A number of pre-generated test vectors are located in the /opt/nvidia/cuBB/cuMAC/testVectors directory.
To enable the test vector generation, use the input argument -t 1 with the multiCellSchedulerUeSelection testbench along with other input arguments.
For example:
Generate a DL test vector:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellSchedulerUeSelection/multiCellSchedulerUeSelection -t 1
Generate a UL test vector:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellSchedulerUeSelection/multiCellSchedulerUeSelection -d 0 -t 1
Test Vector Loading Test#
cuMAC has a testbench (/opt/nvidia/cuBB/cuMAC/examples/tvLoadingTest) to load pre-generated HDF5 test vectors and call the DL/UL scheduler modules/pipeline to compute scheduling solutions based on the input data contained in the test vector.
This testbench can be used to verify the implementation correctness of GPU/CUDA scheduler algorithms by comparing the solutions computed from both GPU and CPU versions of the same algorithms.
Basically, given the same input data from a test vector, GPU and CPU
implementations of the same scheduler algorithms should produce the same
output solution.
Two types of tests are supported:
Per DL/UL scheduler module test: UE selection, PRG allocation, layer selection, and MCS selection
Complete DL/UL scheduler pipeline test
After building cumac, use the following command to check input arguments of the testbench:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -h
Per scheduler module tests:
DL UE selection:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 1 -m 01000
DL PRG allocation:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 1 -m 00100
DL layer selection:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 1 -m 00010
DL MCS selection:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 1 -m 00001
UL scheduler modules can be tested by setting input argument:
-d 0
Complete DL/UL scheduler pipeline tests
DL/UL scheduler modules executed sequentially: UE selection > PRG allocation > layer selection > MCS selection
DL scheduler pipeline:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 1 -m 01111
UL scheduler pipeline:
./opt/nvidia/cuBB/cuMAC/build/examples/tvLoadingTest/tvLoadingTest -i [path to TV] -g 2 -d 0 -m 01111
Passing criteria:
Solutions computed by CPU and GPU should match exactly: testbench returns 0 (PASS) or 1 (FAIL)
DRL MCS Selection Test#
Aerial cuMAC introduced a new DRL-based MCS selection module that can be used
as part of the 4T4R multi-cell scheduler (to replace the basic OLLA algorithm for MCS selection).
A testbench designed for testing the DRL MCS selection module is available under /opt/nvidia/cuBB/cuMAC/examples/drlMcsSelection.
Along with the testbench, there is a pre-trained neural network for MCS selection inference saved in a model.onnx file
under /opt/nvidia/cuBB/cuMAC/testVectors/trtEngine and a number of pre-generated HDF5 test vectors under /opt/nvidia/cuBB/cuMAC/testVectors/mlSim.
To check all supported input arguments to this testbench, use the following command:
./opt/nvidia/cuBB/cuMAC/build/examples/drlMcsSelection/drlMcsSelection -h.
For a test run of the testbench using the test vectors, use the following command: ./opt/nvidia/cuBB/cuMAC/build/examples/drlMcsSelection/drlMcsSelection -i [path to /opt/nvidia/cuBB/cuMAC/testVectors/mlSim] -m [path to /opt/nvidia/cuBB/cuMAC/testVectors/trtEngine/model.onnx] -g [GPU device index].
If the test passes, the following messages will be printed at the end of the program:
...
Test based on the provided HDF5 test vectors
=========================================
Event queue lengths: (UE 0, 49) (UE 1, 49) (UE 2, 49) (UE 3, 49) (UE 4, 49) (UE 5, 49)
=========================================
Start per time slot processing:
=========================================
Testing complete
PASSED!
For a test run without test vectors (using the default test scenario setup), use the following command: ./opt/nvidia/cuBB/cuMAC/build/examples/drlMcsSelection/drlMcsSelection -m [path to /opt/nvidia/cuBB/cuMAC/testVectors/trtEngine/model.onnx] -g [GPU device index].
If the test passes, the following messages will be printed at the end of the program:
...
=========================================
Event queue lengths: (UE 0, 61) (UE 1, 61) (UE 2, 61) (UE 3, 61) (UE 4, 61) (UE 5, 61)
=========================================
Start per time slot processing:
Slot #0 - selected MCS: (UE 0, 0) (UE 1, 0) (UE 2, 0) (UE 3, 0) (UE 4, 0) (UE 5, 0)
Slot #27 - selected MCS: (UE 0, 0) (UE 1, 0) (UE 2, 0) (UE 3, 0) (UE 4, 0) (UE 5, 0)
Slot #56 - selected MCS: (UE 0, 3) (UE 1, 0) (UE 2, 1) (UE 3, 2) (UE 4, 3) (UE 5, 0)
...
=========================================
Testing complete
PASSED!
64T64R MU-MIMO Scheduler Test#
Aerial cuMAC 25-1 Release includes an initial CUDA-based 64T64R MU-MIMO scheduler implementation.
A testbench is available under /opt/nvidia/cuBB/cuMAC/examples/multiCellMuMimoScheduler for checking the computed MU-MIMO scheduling solution.
Currently there is an HDF5 test vector file TV_AODT_64TR_MUMIMO_3PC_DL_HARQ.h5 available under /opt/nvidia/cuBB/cuMAC/testVectors/aodt that was pre-generated using the AODT platform.
When the test runs, the testbench checks if the computed solutions from the MU-MIMO scheduler modules match with the reference results saved in the test vector.
To check all supported input arguments to this testbench, use the following command:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellMuMimoScheduler/multiCellMuMimoScheduler -h.
For a test run of the testbench using the pre-generated test vector, follow the steps below:
Modify the following fields in the
/opt/nvidia/cuBB/cuMAC/examples/parameters.hconfiguration file (keep default values for fields not listed below)gpuDeviceIdxshould be set to the GPU device index on the test equipmentnumCellConstshould be set to 3numActiveUePerCellConstshould be set to 100nBsAntConstshould be set to 64gpuAllocTypeConstshould be set to 1nPrbsPerGrpConstshould be set to 2nPrbGrpsConstshould be set to 136
Build cuMAC under
/opt/nvidia/cuBB/cuMAC.Run the 64TR MU-MIMO scheduler test using the following command:
./opt/nvidia/cuBB/cuMAC/build/examples/multiCellMuMimoScheduler/multiCellMuMimoScheduler -i [path to /opt/nvidia/cuBB/cuMAC/testVectors/asim/TV_cumac_64TR_2PC_DL.h5] -a 1 -r 1.
If the test passes, you would be able to see the following prints at the end:
cuMAC 64TR MU-MIMO scheduler pipeline test: Downlink
cuMAC 64TR MU-MIMO scheduler pipeline test: Running on GPU device 2
Multi-cell scheduler, Type-1 allocate
nBsAnt X nUeAnt = 64 X 4
UE sorting setup completed
UE sorting run completed
UE grouping setup completed
UE grouping run completed
MCS selection setup completed
MCS selection run completed
sortedUeList solution check: PASS
muMimoInd solution check: PASS
setSchdUePerCellTTI solution check: PASS
allocSol solution check: PASS
layerSelSol solution check: PASS
layerSelUegSol solution check: PASS
nSCID solution check: PASS
rsrpCurrTx solution check: PASS
rsrpLastTx solution check: PASS
mcsSelSol solution check: PASS
ollaParamActUe update check: PASS
Summary - cuMAC multi-cell MU-MIMO scheduler solution check: PASS
When the testbench returns, the computed MU-MIMO scheduling solutions are saved in a result HDF5 file TV_cumac_result_64TR_3PC_DL.h5.
To check the computed solutions, manually open the result HDF5 file using the following tools:
To check all dataset names in the HDF5 file, use command:
h5ls TV_cumac_result_64TR_3PC_DL.h5To open a dataset in the HDF5 file, use command:
h5dump -d [dataset name] TV_cumac_result_64TR_3PC_DL.h5
The dataset names of the MU-MIMO scheduling solutions are as follows:
UE down-selection:
setSchdUePerCellTTIPRBG (PRB group) allocation:
allocSollayer allocation:
layerSelSolMCS selection:
mcsSelSolnSCID allocation:
nSCID
All input data to the MU-MIMO scheduler can be checked as well using the tool h5dump.
For detailed definitions and formats of the data fields, refer to the cuMAC API reference section.