

Dev Notes
Welcome to NeMo Data Designer Dev Notes — in-depth guides, benchmark write-ups, and insights from the team building NeMo Data Designer.

Pause, Inspect, Resume
Workflow chaining turns long generation jobs into resumable stages you can inspect, override, compare, and hand off. Human review is one useful pattern.

Image Generation for Multimodal Data Pipelines
From document VQA to autonomous-vehicle scenes, X-rays, drone frames, and funny pet edits — controlled image datasets you can inspect row by row.
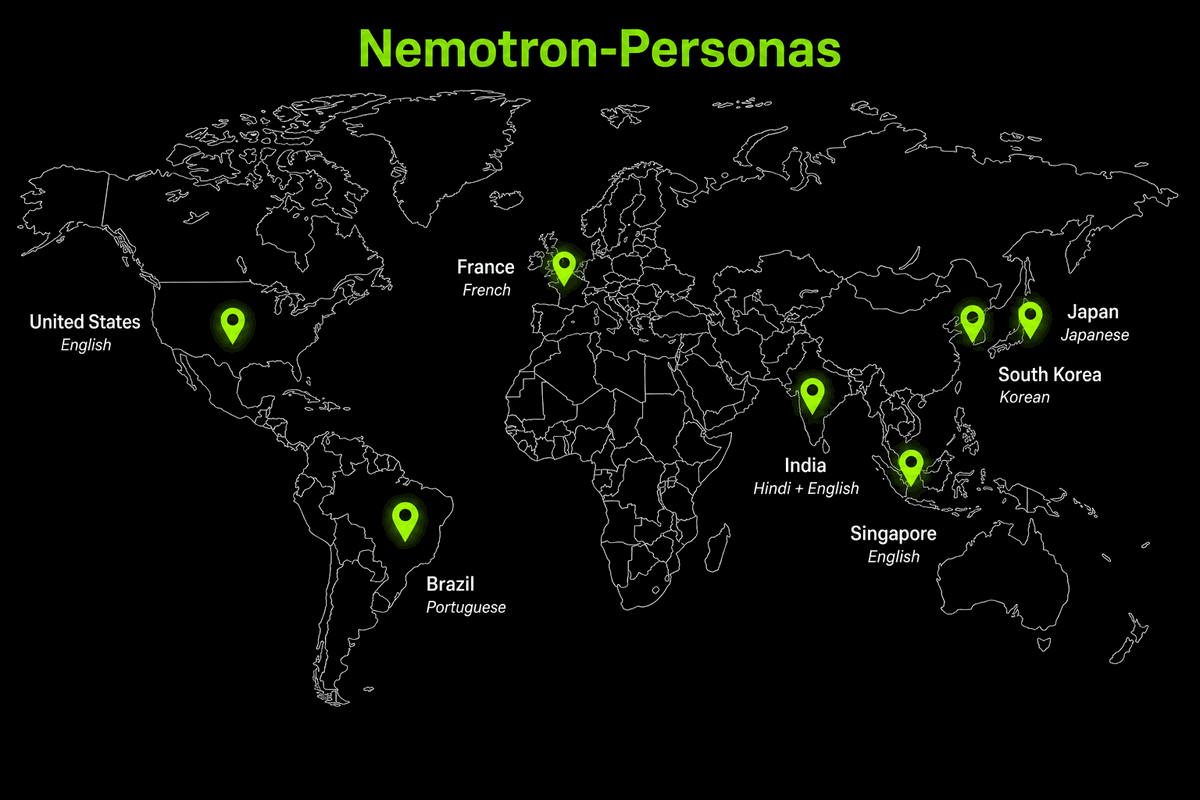
Designing Nemotron-Personas
The compound-AI pipeline behind Nemotron-Personas seeding Nemotron training. Now open-sourced: fork it, add your data, ship personas for any use case.

Mitigating Prompt Sensitivity
A Data Designer pipeline that generates thousands of regex-paired prompt preambles to manufacture format robustness — six diversity samplers, four quality judges, dual-purpose for SFT and RL.

Retriever SDG Plugin
The Data Designer plugin behind NVDocs and the bootstrap SDG stage for NeMo embedding and reranking recipes.

Have It Your Way
A plugin framework for the custom pieces every real project ends up needing.

Training a VLM to Understand Long Documents
An iterative SDG story: 11.4M synthetic visual QA pairs, document-reasoning pipelines, and long-context VLM training lessons.

Push Datasets to Hugging Face Hub
Call .push_to_hub() and ship a generated dataset straight to a live HF dataset card. Done and dusted.
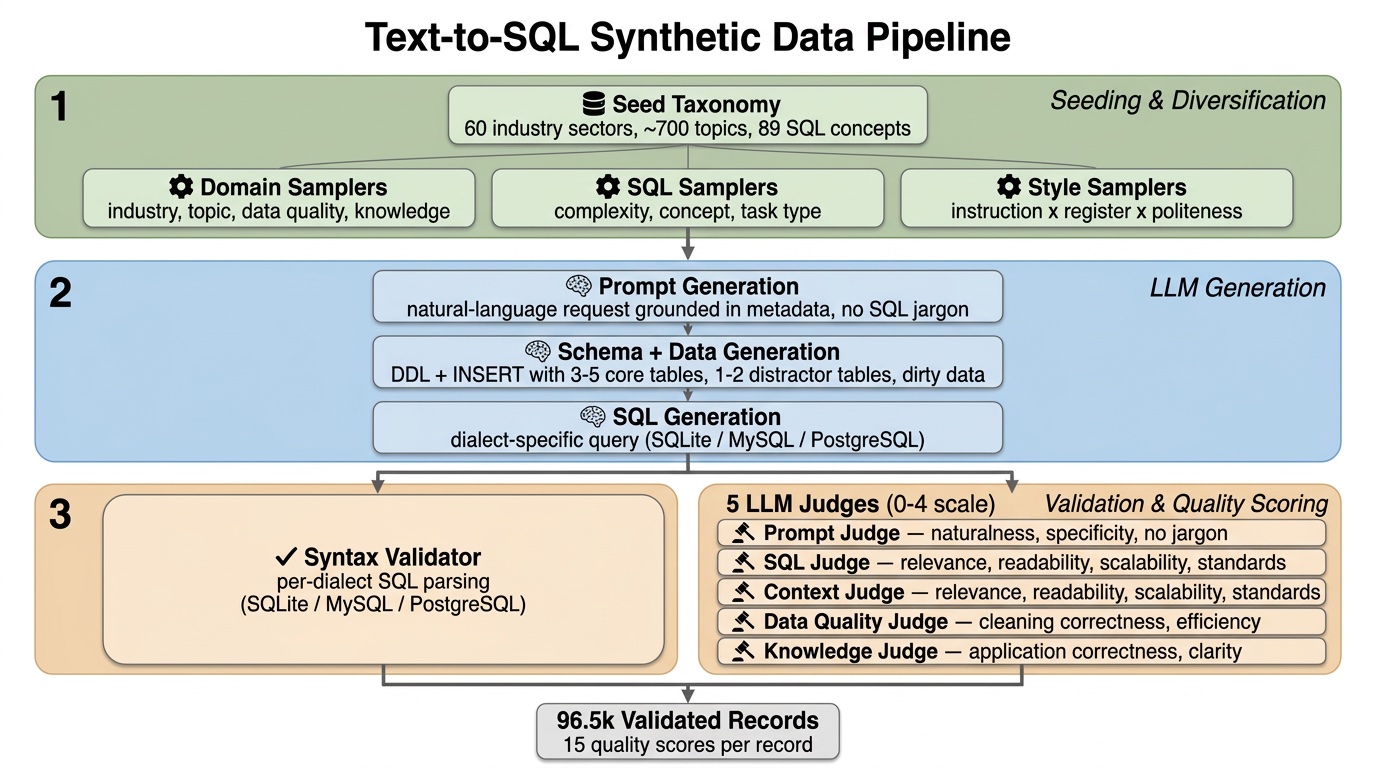
Engineering an Enterprise-Grade Text-to-SQL Dataset
A pipeline with conditional sampling, three-stage LLM generation, code validators, and judge scoring — boosting Nemotron Super on BIRD from 26.77 → 41.80.
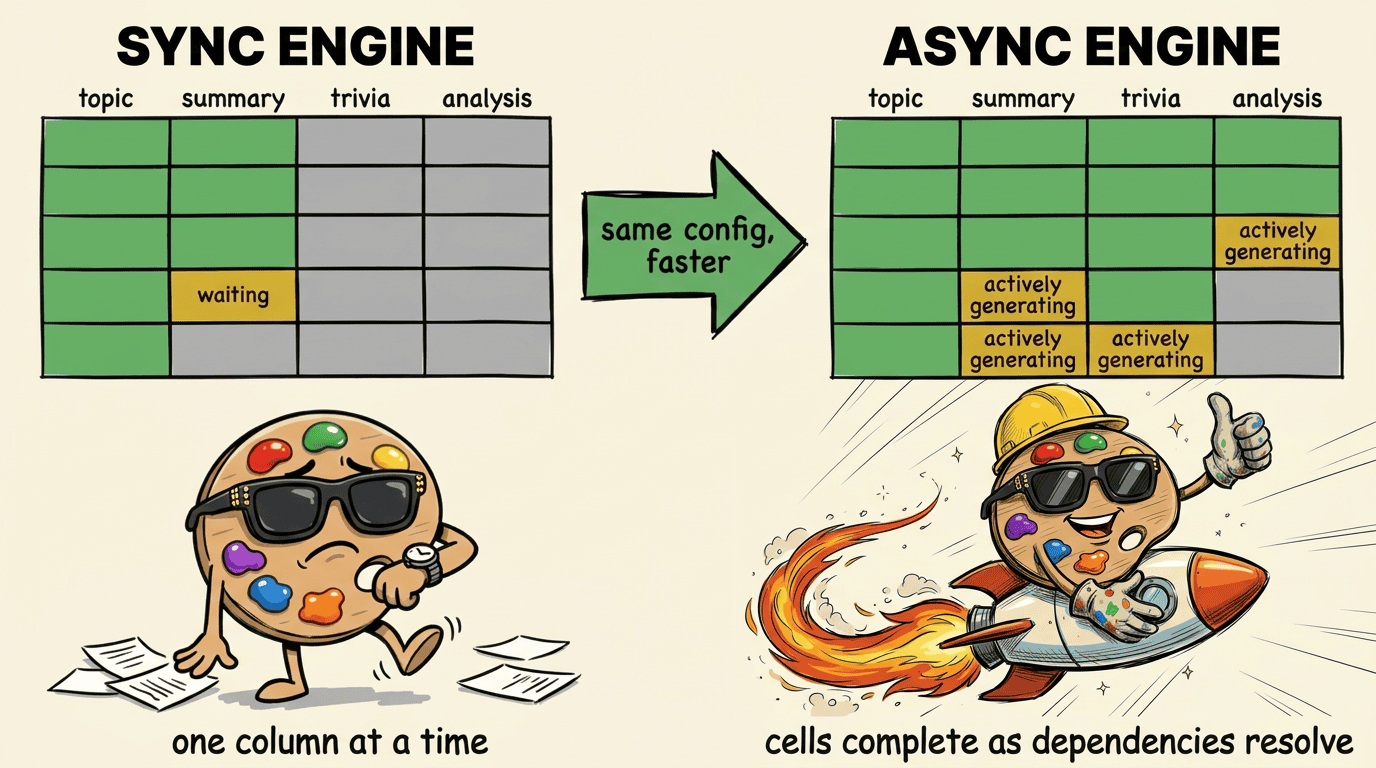
Async All the Way Down
How async dispatch in the engine cuts wall time across deep dependency pipelines — same config, same prompts, 1.3× faster on average.
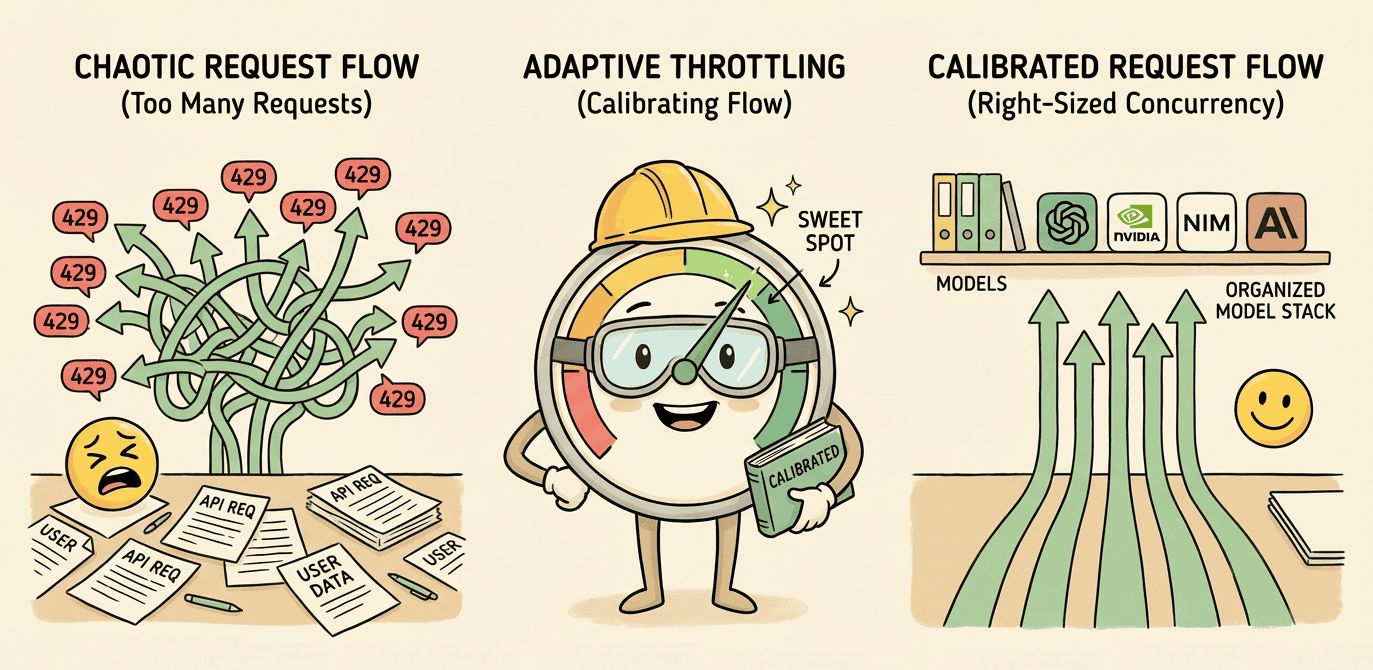
Owning the Model Stack
Adaptive concurrency, throttle keying, retry boundaries — owning the whole model client to discover provider capacity at runtime.
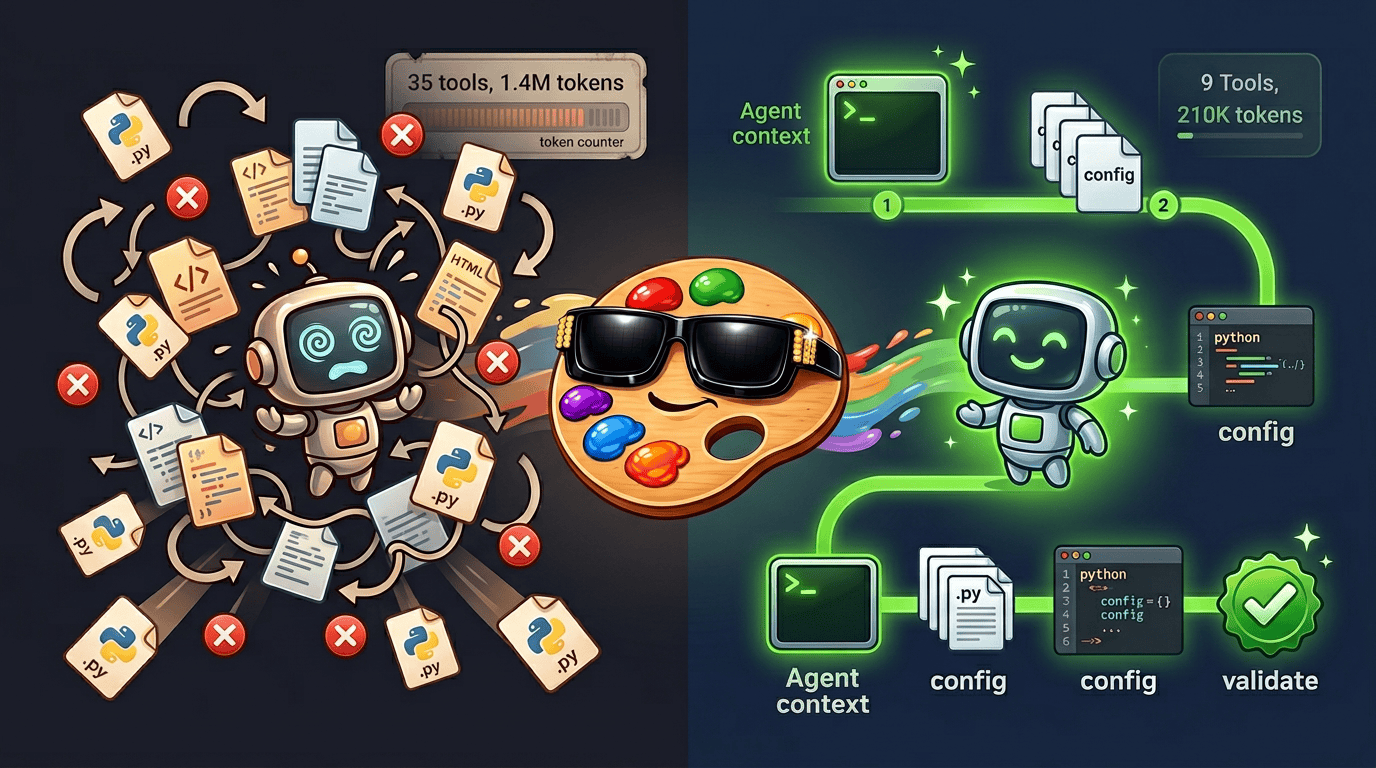
Data Designer Got Skills
A CLI and skill workflow that lets agents drive Data Designer end-to-end — leaner context, fewer tool calls, the same output.
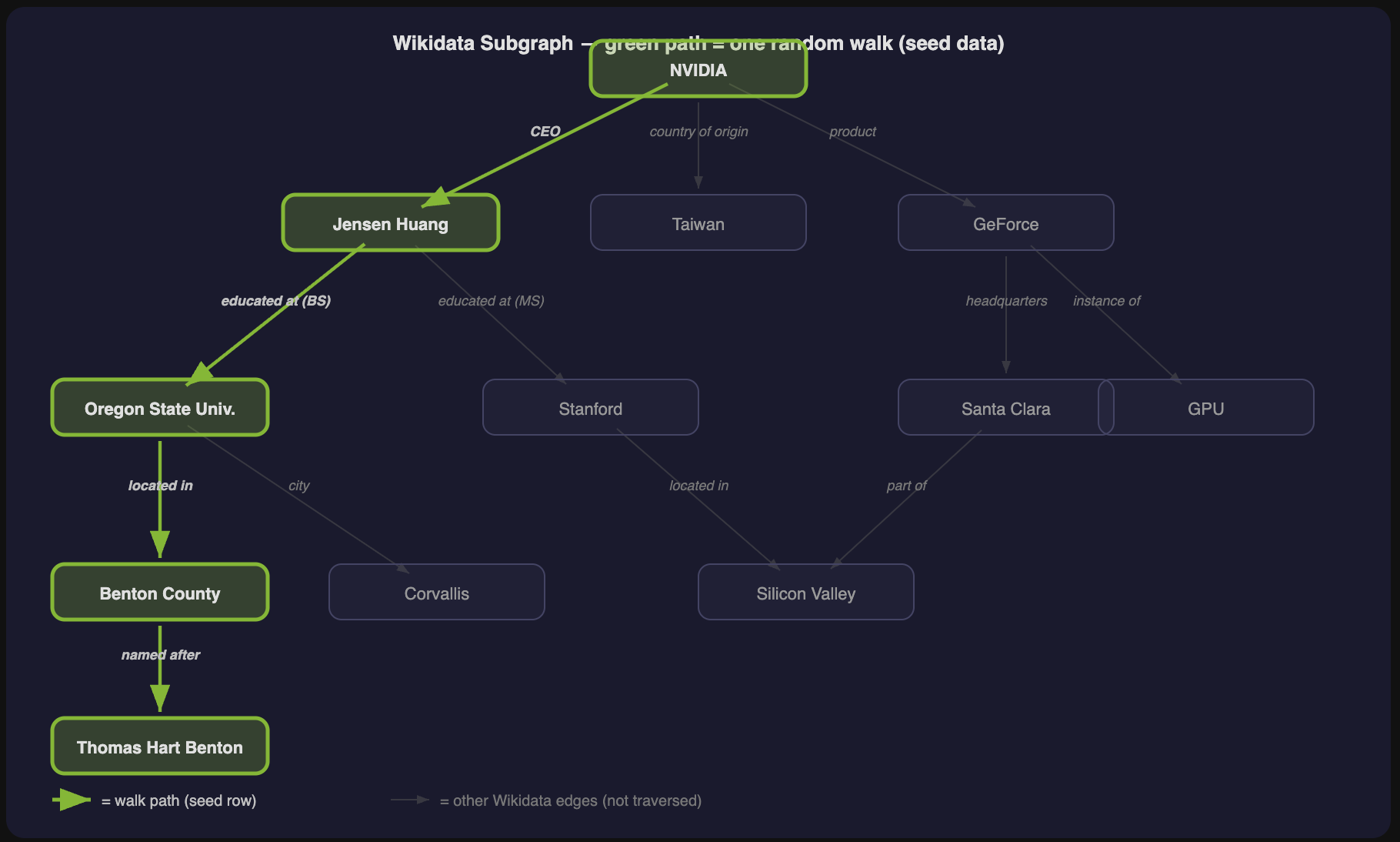
Search Agent SFT Data
Multi-turn search agent trajectories for Nemotron Super post-training — Tavily web search, Wikidata KG seeding, BrowseComp-style obfuscation.
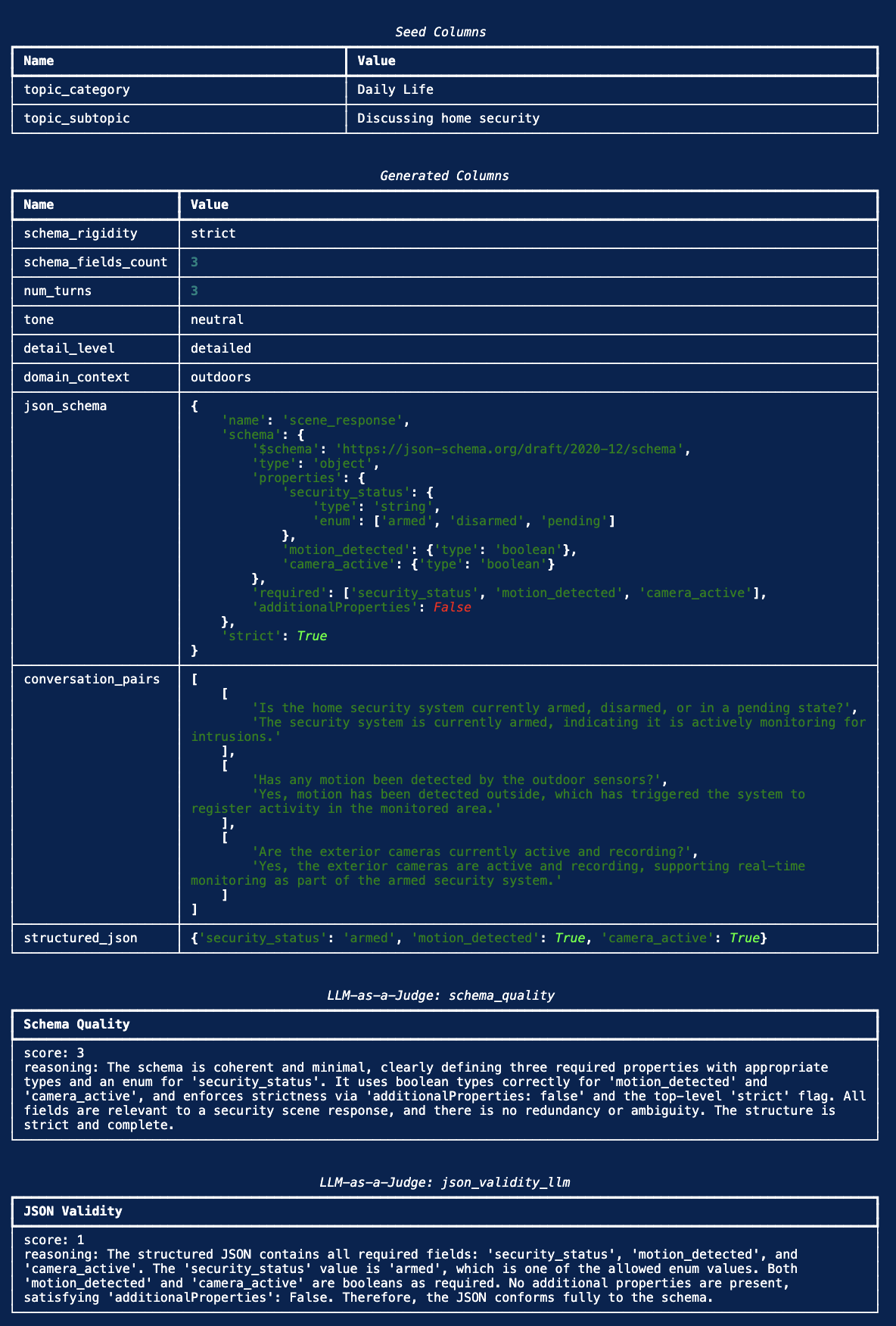
Structured Outputs from Nemotron
Schema-constrained outputs across CSV / JSON / TOML / XML / YAML — JSONSchemaBench and StructEval-Text results, plus the recipe.
Deep Research Trajectories
MCP tool-use trajectories for training deep research agents — search, open, find, answer over a static BM25 corpus, no web APIs needed.
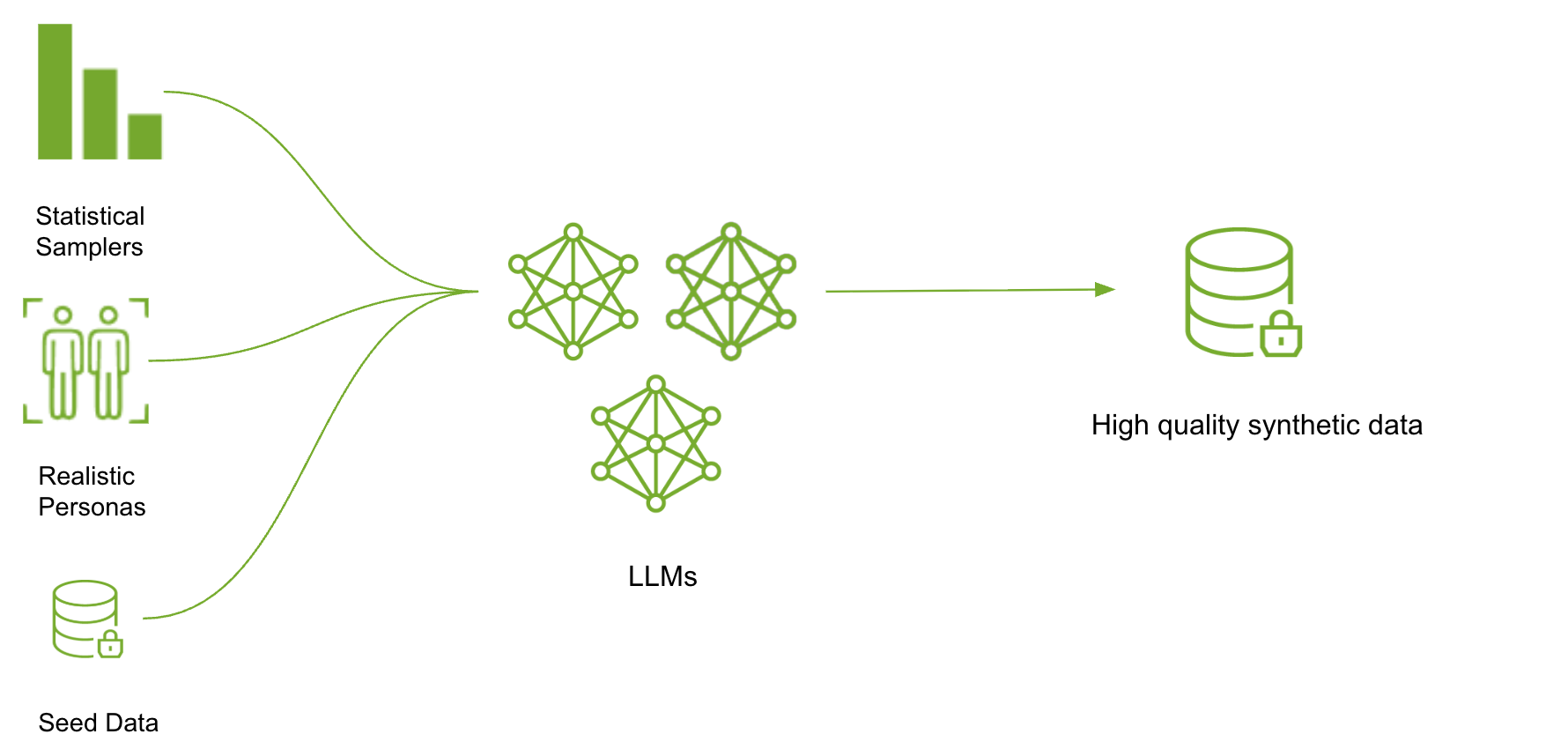
Designing Data Designer
Why SDG is a systems problem, and the design principles behind a composable orchestration framework — declarative columns, imperative engine.
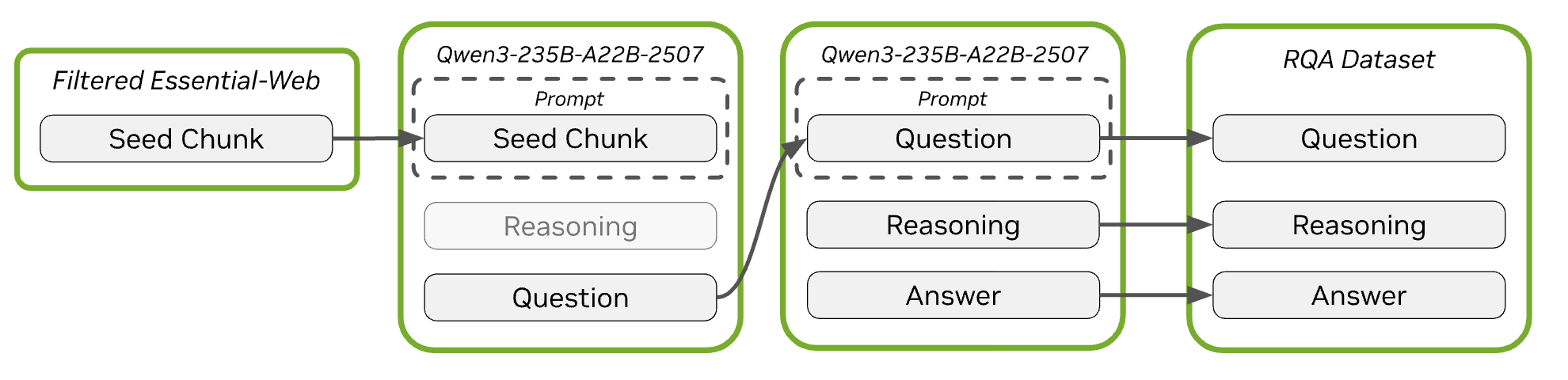
Graduate-Level Science Reasoning (RQA)
A massive collection of graduate-level reasoning samples seeded from Common Crawl — improves Nemotron 3 Nano on MMLU-Pro, Math 500, GSM8K.