Parallelisms Guide#
Megatron Bridge supports various data-parallel and model-parallel deep learning workload deployment methods, which can be mixed together arbitrarily. These parallelism strategies are configured through model provider classes and leverage Megatron Core’s implementation for performance and memory efficiency.
Data Parallelism#
Data Parallelism (DP) replicates the model across multiple GPUs. Data batches are evenly distributed between GPUs and the data-parallel GPUs process them independently. While the computation workload is efficiently distributed across GPUs, inter-GPU communication is required to keep the model replicas consistent between training steps.
Distributed Data Parallelism#
Distributed Data Parallelism (DDP) keeps the model copies consistent by synchronizing parameter gradients across data-parallel GPUs before each parameter update. More specifically, it sums the gradients of all model copies using all-reduce communication collectives.
 Figure: Distributed Data Parallelism synchronizes gradients across multiple GPUs using all-reduce operations.
Figure: Distributed Data Parallelism synchronizes gradients across multiple GPUs using all-reduce operations.
Distributed Optimizer#
Distributed optimizer is a memory-optimized data-parallel deployment method. It shards the optimizer states and the high-precision master parameters across data-parallel GPUs instead of replicating them. At the parameter optimizer step, each data-parallel GPU updates its shard of parameters. Since each GPU needs its own gradient shard, the distributed optimizer conducts reduce-scatter of the parameter gradients instead of all-reduce of them. Then, the updated parameter shards are all-gathered across data-parallel GPUs. This approach significantly reduces the memory need of large-scale LLM training.
Enable Data Parallelism#
In Megatron Bridge, DDP is the default parallel deployment method. The total number of GPUs corresponds to the size of the DP group, and training an LLM with model parallelism decreases the size of the DP group.
To enable the distributed optimizer, configure the bridge.training.config.OptimizerConfig and bridge.training.config.DistributedDataParallelConfig
from megatron.bridge.training.config import ConfigContainer, DistributedDataParallelConfig, OptimizerConfig
optimizer_config = OptimizerConfig(
optimizer="adam",
lr=3e-4,
weight_decay=0.1,
adam_beta1=0.9,
adam_beta2=0.95,
use_distributed_optimizer=True,
clip_grad=1.0,
)
ddp_config = DistributedDataParallelConfig(use_distributed_optimizer=True)
config = ConfigContainer(
ddp=ddp_config,
optimizer=optimizer_config,
# ... other config parameters
)
For more optimizer options, refer to the bridge.training.config.OptimizerConfig API documentation.
Model Parallelism#
Model Parallelism (MP) is a distributed model deployment method that partitions the model parameters across GPUs to reduce the need for per-GPU memory. Megatron Bridge supports various model-parallel methods through Megatron Core, which can be mixed to maximize LLM training performance.
Tensor Parallelism#
Tensor Parallelism (TP) is a model-parallel partitioning method that distributes the parameter tensor of an individual layer across GPUs. In addition to reducing model state memory usage, it also saves activation memory as the per-GPU tensor sizes shrink. However, the reduced per-GPU tensor size increases CPU overhead due to smaller per-GPU kernel workloads.
 Figure 1: Tensor Parallelism distributes individual layer parameters across multiple GPUs.
Figure 1: Tensor Parallelism distributes individual layer parameters across multiple GPUs.
 Figure 2: Detailed view of how tensor parallelism splits weight matrices and synchronizes computations.
Figure 2: Detailed view of how tensor parallelism splits weight matrices and synchronizes computations.
Enable Tensor Parallelism#
To enable TP in Megatron Bridge, configure the tensor_model_parallel_size parameter in your model provider. This parameter determines the number of GPUs among which the model’s tensors are partitioned.
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.config import ConfigContainer
# Configure model with tensor parallelism
model_config = GPTModelProvider(
tensor_model_parallel_size=2, # Enable TP across 2 GPUs
# ... other model parameters
)
config = ConfigContainer(
model=model_config,
# ... other config parameters
)
Implement Tensor Parallelism#
Megatron Bridge integrates TP through the implementation from Megatron Core. For detailed API usage and additional configurations, consult the Megatron Core Developer Guide.
Pipeline Parallelism#
Pipeline Parallelism (PP) is a technique that assigns consecutive layers or segments of a neural network to different GPUs. This division allows each GPU to process different stages of the network sequentially.
 Figure: Pipeline Parallelism distributes consecutive layers across multiple GPUs, processing batches in a pipeline fashion.
Figure: Pipeline Parallelism distributes consecutive layers across multiple GPUs, processing batches in a pipeline fashion.
Enable Pipeline Parallelism#
To utilize Pipeline Parallelism in Megatron Bridge, set the pipeline_model_parallel_size parameter in your model configuration. This parameter specifies the number of GPUs among which the model’s layers are distributed.
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.config import ConfigContainer
# Configure model with pipeline parallelism
model_config = GPTModelProvider(
pipeline_model_parallel_size=4, # Distribute layers across 4 GPUs
# ... other model parameters
)
config = ConfigContainer(
model=model_config,
# ... other config parameters
)
Interleaved Pipeline Parallel Schedule#
To minimize the pipeline bubble, the computation on each GPU can be divided into multiple subsets of layers (referred to as model chunks), rather than a single contiguous block. Enable this by setting virtual_pipeline_model_parallel_size:
model_config = GPTModelProvider(
pipeline_model_parallel_size=4,
virtual_pipeline_model_parallel_size=2, # 2 model chunks per pipeline stage
# ... other model parameters
)
For more insights into this approach, see the detailed blog: Scaling Language Model Training.
Implement Pipeline Parallelism#
The Megatron Bridge implementation of PP leverages functionalities from Megatron Core. For more detailed API usage and configurations related to PP, visit the Megatron Core Developer Guide.
Expert Parallelism and Mixture of Experts (MoE)#
Expert Parallelism (EP) is a type of model parallelism that distributes experts of a Mixture of Experts (MoE) model across GPUs. Unlike other model-parallel techniques, EP is applied to only the expert layers and does not impact the parallel mapping of the rest of the layers.
MoE is a machine learning technique where multiple specialized models (experts, usually multi-layer perceptrons) are combined to solve a complex task. Each expert focuses on a specific subtask or domain, while a gating network dynamically activates the most appropriate expert based on the current input.
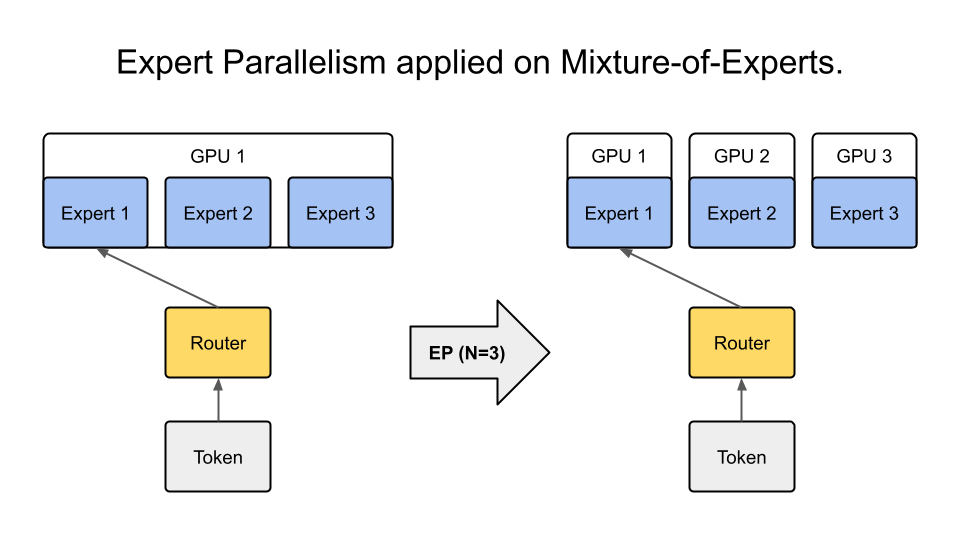 Figure: Expert Parallelism distributes MoE experts across multiple GPUs while keeping other layers replicated.
Figure: Expert Parallelism distributes MoE experts across multiple GPUs while keeping other layers replicated.
Basic MoE Configuration#
To enable MoE in Megatron Bridge, configure the basic MoE parameters in your model provider:
from megatron.bridge.models import GPTModelProvider
# Configure basic MoE model
model_config = GPTModelProvider(
num_moe_experts=8, # Number of experts in the MoE module
moe_router_topk=2, # Number of experts activated per token
moe_ffn_hidden_size=8192, # Hidden size for expert FFN layers
# ... other model parameters
)
Enable Expert Parallelism#
To enable EP, set expert_model_parallel_size in your model configuration. For example, if the model has eight experts (num_moe_experts=8), then setting expert_model_parallel_size=4 results in each GPU processing two experts. The number of experts should be divisible by the expert parallel size.
# Configure MoE model with expert parallelism
model_config = GPTModelProvider(
num_moe_experts=8,
expert_model_parallel_size=4, # Distribute 8 experts across 4 GPUs (2 experts per GPU)
# ... other model parameters
)
Enable Expert Tensor Parallelism#
To enable Expert Tensor Parallelism (ETP), set expert_tensor_parallel_size in your model configuration:
model_config = GPTModelProvider(
num_moe_experts=8,
expert_model_parallel_size=4,
expert_tensor_parallel_size=2, # Apply tensor parallelism within each expert
# ... other model parameters
)
Advanced MoE Features#
Megatron Bridge provides several advanced optimizations for MoE models to improve performance on modern GPU architectures.
DeepEP and HybridEP Optimizations#
DeepEP and HybridEP are high-performance MoE token dispatchers that improve throughput and efficiency on specific GPU architectures:
DeepEP: Optimized for Ampere, Hopper, B200, and B300 GPUs
HybridEP: Optimized for GB200, GB300 with NVL72, and Ampere, Hopper, B200, B300 GPUs
These dispatchers replace the standard token routing mechanism with an optimized “flex” dispatcher that provides better performance for MoE workloads.
Enable DeepEP:
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.flex_dispatcher_backend import apply_flex_dispatcher_backend
model_config = GPTModelProvider(
num_moe_experts=8,
expert_model_parallel_size=4,
# ... other model parameters
)
# Apply DeepEP optimization
apply_flex_dispatcher_backend(model_config, moe_flex_dispatcher_backend="deepep")
Enable HybridEP:
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.flex_dispatcher_backend import apply_flex_dispatcher_backend
model_config = GPTModelProvider(
num_moe_experts=8,
expert_model_parallel_size=4,
# ... other model parameters
)
# Apply HybridEP optimization
apply_flex_dispatcher_backend(model_config, moe_flex_dispatcher_backend="hybridep")
GPU Architecture Requirements:
DeepEP: Ampere (SM 8.x), Hopper (SM 9.x), B200, B300
HybridEP: GB200, GB300 with NVL72, Ampere (SM 8.x), Hopper (SM 9.x), B200, B300
The system automatically validates GPU compatibility and issues warnings if the dispatcher is not supported on the current hardware.
Token Dropping for Load Balancing#
Token dropping improves MoE performance by balancing work across experts through capacity factors. This feature allows the model to drop tokens when experts are overloaded, preventing stragglers and improving overall throughput.
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.utils.moe_token_drop import apply_moe_token_drop
model_config = GPTModelProvider(
num_moe_experts=8,
moe_router_topk=2,
moe_token_dispatcher_type="alltoall", # Required for token dropping
moe_router_load_balancing_type="aux_loss", # Required load balancing type
# ... other model parameters
)
# Apply token dropping with capacity factor
apply_moe_token_drop(
model_config,
moe_expert_capacity_factor=1.0, # Capacity multiplier per expert
moe_pad_expert_input_to_capacity=True, # Pad inputs to capacity length
)
Configuration Parameters:
moe_expert_capacity_factor: Controls the maximum number of tokens each expert can process. A factor of 1.0 means each expert can handle exactly its proportional share of tokens. Lower values (e.g., 0.8) drop more tokens but improve load balancing.moe_pad_expert_input_to_capacity: When enabled, pads expert inputs to the capacity length for consistent batch sizes.
Requirements:
Token dispatcher must be
alltoalloralltoall_seqLoad balancing type must be
aux_loss,seq_aux_loss, ornone
Trade-offs:
Token dropping can improve training throughput by 10-30% in imbalanced MoE models, but may affect convergence if too aggressive. Start with a capacity factor of 1.0 and gradually reduce if needed.
Complete MoE Configuration Example#
Here’s a complete example showing how to configure an MoE model with advanced optimizations:
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.config import ConfigContainer
from megatron.bridge.training.flex_dispatcher_backend import apply_flex_dispatcher_backend
from megatron.bridge.training.utils.moe_token_drop import apply_moe_token_drop
# Configure MoE model with expert parallelism
model_config = GPTModelProvider(
num_layers=32,
hidden_size=4096,
num_attention_heads=32,
# MoE configuration
num_moe_experts=8, # 8 experts total
moe_router_topk=2, # Activate 2 experts per token
moe_ffn_hidden_size=8192, # Expert FFN hidden dimension
moe_token_dispatcher_type="alltoall", # Token dispatcher type
moe_router_load_balancing_type="aux_loss", # Load balancing
# Expert parallelism
expert_model_parallel_size=4, # Distribute experts across 4 GPUs
expert_tensor_parallel_size=2, # Apply TP within each expert
# ... other model parameters
)
# Apply DeepEP optimization (for Ampere/Hopper GPUs)
apply_flex_dispatcher_backend(model_config, moe_flex_dispatcher_backend="deepep")
# Apply token dropping for load balancing
apply_moe_token_drop(
model_config,
moe_expert_capacity_factor=1.0,
moe_pad_expert_input_to_capacity=True,
)
config = ConfigContainer(
model=model_config,
# ... other config parameters
)
Expert Parallelism Implementation#
The Megatron Bridge implementation of EP uses functionality from Megatron Core. Please consult the Megatron Core MoE layer for more MoE implementation details.
Activation Partitioning#
In LLM training, a large memory space is needed to store the input activations of the network layers. Megatron Bridge provides effective activation distribution methods through Megatron Core, which is critical in training LLMs with large sequence lengths or large per-GPU micro-batch sizes.
Sequence Parallelism#
Sequence Parallelism (SP) extends tensor-level model parallelism by distributing computing load and activation memory across multiple GPUs along the sequence dimension of transformer layers. This method is particularly useful for portions of the layer that have previously not been parallelized, enhancing overall model performance and efficiency.
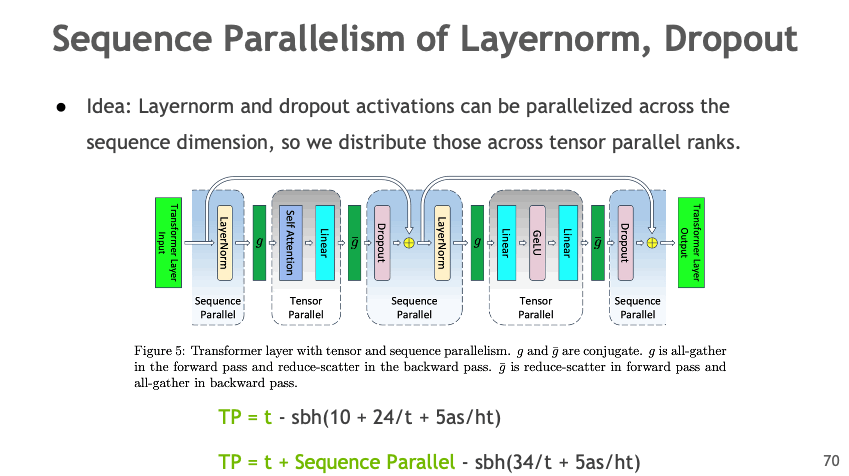 Figure: Sequence Parallelism distributes the sequence dimension across multiple GPUs, reducing activation memory.
Figure: Sequence Parallelism distributes the sequence dimension across multiple GPUs, reducing activation memory.
Enable Sequence Parallelism#
To utilize SP in Megatron Bridge, set the sequence_parallel parameter to True in your model configuration. Note that this feature is effective only when the tensor parallel size (tensor_model_parallel_size) is greater than 1.
from megatron.bridge.models import GPTModelProvider
# Configure model with sequence parallelism
model_config = GPTModelProvider(
tensor_model_parallel_size=2, # Required for sequence parallelism
sequence_parallel=True, # Enable sequence parallelism
# ... other model parameters
)
Implement Sequence Parallelism#
The Megatron Bridge implementation of SP utilizes functionality from Megatron Core. For an in-depth look at how Sequence Parallelism is integrated into the Megatron Core architecture, you can examine the source code: Megatron-LM Sequence Parallel Source Code.
Context Parallelism#
Context Parallelism (CP) is a method for parallelizing the processing of neural network activations across multiple GPUs by partitioning the input tensors along the sequence dimension. Unlike Sequence Parallelism (SP) that partitions the activations of specific layers, CP divides the activations of all layers.
CP is critical for training long context models, as it allows the model to handle longer sequences by distributing the sequence activations across multiple GPUs. This method reduces the memory footprint and computational cost of processing long sequences.
Enable Context Parallelism#
To activate CP in Megatron Bridge, set the context_parallel_size parameter in your model configuration. This parameter specifies the number of GPUs across which the model’s sequence activations are distributed.
from megatron.bridge.models import GPTModelProvider
# Configure model with context parallelism
model_config = GPTModelProvider(
context_parallel_size=2, # Distribute sequence across 2 GPUs
# ... other model parameters
)
For long context training scenarios, context parallelism is particularly effective and essential for handling sequences that exceed the memory capacity of individual GPUs.
Implement Context Parallelism#
Megatron Bridge leverages functionalities from both Megatron Core and Transformer Engine to implement CP efficiently. During forward propagation, each GPU handles a segment of the sequence, storing only the necessary Key and Value (KV) pairs. In the backward pass, these KV pairs are reassembled across GPUs using advanced communication schemes like all-gather and reduce-scatter transformed into point-to-point communications in a ring topology. This method reduces the memory footprint significantly while maintaining computational efficiency.
For more detailed technical information and implementation details, visit:
Combined Parallelism Example#
Megatron Bridge allows you to combine multiple parallelism strategies for optimal performance and memory efficiency:
from megatron.bridge.models import GPTModelProvider
from megatron.bridge.training.config import ConfigContainer, OptimizerConfig
# Configure model with multiple parallelism strategies
model_config = GPTModelProvider(
# Model parallelism
tensor_model_parallel_size=2, # 2-way tensor parallelism
pipeline_model_parallel_size=4, # 4-way pipeline parallelism
virtual_pipeline_model_parallel_size=2, # Interleaved pipeline
# Activation partitioning
sequence_parallel=True, # Enable sequence parallelism (requires TP > 1)
context_parallel_size=2, # 2-way context parallelism
# Expert parallelism (for MoE models)
num_moe_experts=8, # 8 experts
expert_model_parallel_size=4, # Distribute experts across 4 GPUs
# ... other model parameters
)
# Configure distributed optimizer
optimizer_config = OptimizerConfig(
optimizer="adam",
use_distributed_optimizer=True, # Enable distributed optimizer
# ... other optimizer parameters
)
config = ConfigContainer(
model=model_config,
optimizer=optimizer_config,
# ... other config parameters
)
Data Parallel Size Calculation#
The data parallel size is automatically calculated based on the total world size and model parallelism settings:
data_parallel_size = world_size / (tensor_model_parallel_size × pipeline_model_parallel_size × context_parallel_size)
For example, with 32 GPUs total and the configuration above:
tensor_model_parallel_size = 2pipeline_model_parallel_size = 4context_parallel_size = 2data_parallel_size = 32 / (2 × 4 × 2) = 2
Strategy Selection Guide#
Choosing the right combination depends on model size, hardware topology, and sequence length.
Dense Models by Size#
Model size |
GPUs |
Recommended starting point |
|---|---|---|
< 1B |
1-8 |
DP only |
1-10B |
8-16 |
TP=2-4 + DP |
10-70B |
16-64 |
TP=4-8 + PP=2-4 + DP |
70-175B |
64-256 |
TP=8 + PP=4-8 + DP |
175-500B |
256-1024 |
TP=8 + PP=8-16 + CP=2 + DP |
MoE Models#
MoE models differ fundamentally from dense models: only a fraction of parameters are active per token, so TP can often stay at 1 or 2. EP is the primary scaling dimension.
Total / active params |
Typical layout |
|---|---|
< 20B |
EP only (TP=1, PP=1) |
20-100B |
TP=1-2 + PP=2-4 + EP=8-16 |
100-500B |
TP=2-4 + PP=8-16 + EP=8-32 |
500B+ |
TP=2 + PP=16 + EP=32-64 |
By Hardware Topology#
Single node with NVLink: maximize TP within the node (up to TP=8).
Multiple nodes with InfiniBand: keep TP within a node, use PP across nodes.
Limited network (Ethernet): minimize TP, prefer PP for cross-node scaling.
By Sequence Length#
Sequence length |
Recommendation |
|---|---|
< 2K |
standard TP + PP + DP |
2K-8K |
add SP ( |
8K-32K |
add CP=2 |
32K+ |
add CP=4-8, consider hierarchical CP |
For operational details on configuring combined parallelism, troubleshooting layouts, and memory estimation, see the parallelism strategies skill.
Configuration Guidelines#
Memory Optimization#
Use distributed optimizer to reduce optimizer state memory
Enable sequence parallelism when using tensor parallelism to reduce activation memory
Use context parallelism for long sequence training
Consider pipeline parallelism for very large models that don’t fit on a single GPU
Performance Optimization#
Tensor parallelism works best within a single node (high bandwidth)
Pipeline parallelism can work across nodes but requires careful batch size tuning
Context parallelism is essential for long context scenarios
Expert parallelism is specific to MoE models and should match the number of experts
DeepEP/HybridEP provide optimized MoE token dispatching on supported GPU architectures
Compatibility#
Sequence parallelism requires
tensor_model_parallel_size > 1Expert parallelism requires MoE models (
num_moe_experts > 0)DeepEP requires Ampere, Hopper, B200, or B300 GPUs
HybridEP requires GB200, GB300 with NVL72, or Ampere, Hopper, B200, B300 GPUs
Token dropping requires
alltoalloralltoall_seqtoken dispatcherAll parallelism strategies can be combined, but total parallelism must divide evenly into the world size