Radar Processing Pipeline#
Radar Pipeline Architecture Overview#
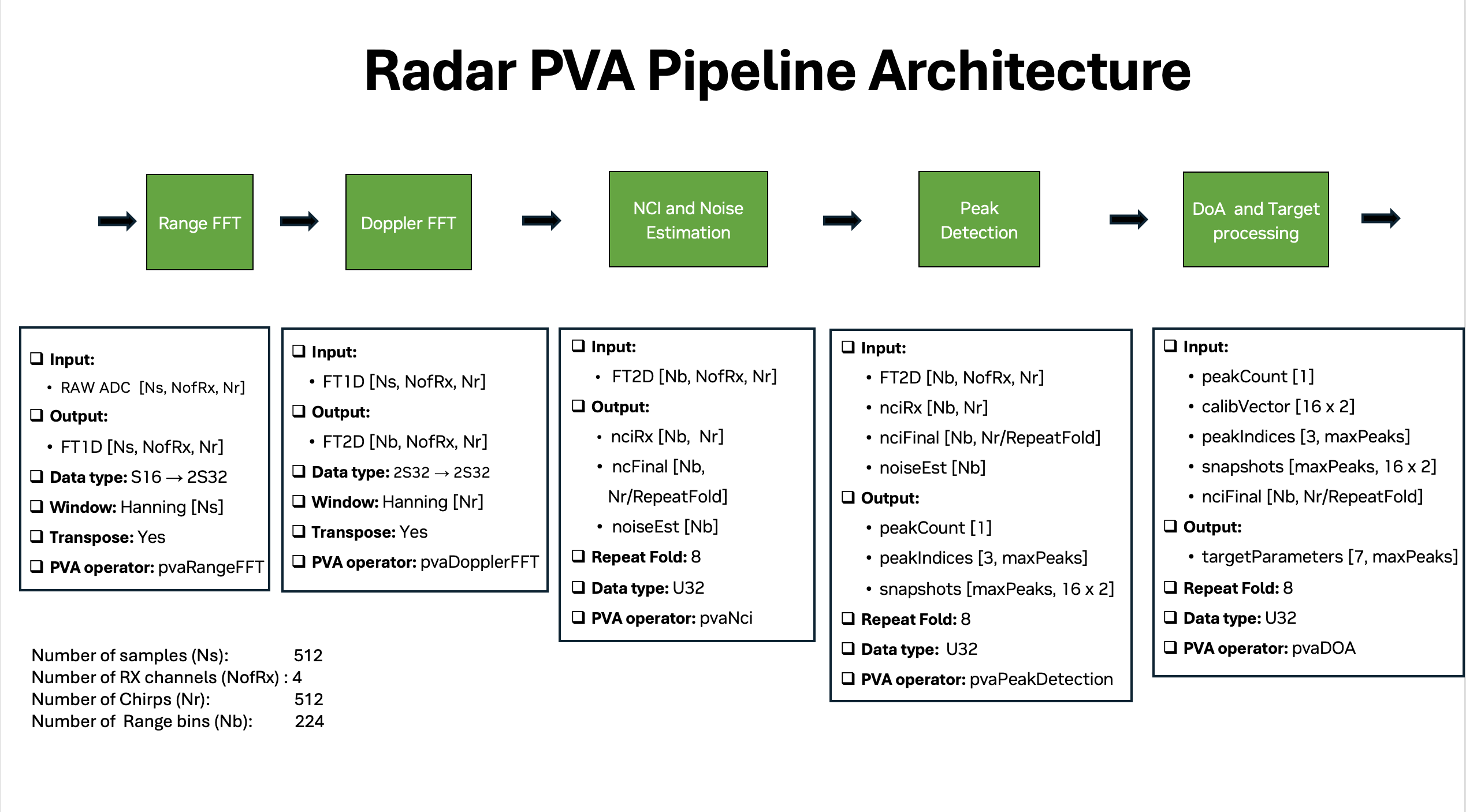
The radar PVA pipeline architecture is designed to process raw radar data (ADC samples) and generate a point cloud. The pipeline architecture consists of 5 stages. The Range-fft, Doppler-fft and Peak Detection stages are implemented using fixed-point arithmetic, and NCI and DOA algorithms employ a hybrid approach, utilizing fixed-point arithmetic for computational efficiency while incorporating floating-point operations where the operations do not have native HW support.
|
Range FFT Processing -> Converts time-domain samples to range-frequency domain using windowed FFT. The PVA operator used for this stage is pvaRangeFFT.
Doppler FFT Processing -> Processes the range data to extract velocity of targets. The PVA operator used for this stage is pvaDopplerFFT.
NCI Processing -> Performs noise estimation and non-coherent integration to improve signal-to-noise ratio. The PVA operator used is pvaNci.
Peak Detection -> Performs local maximum detection in both range and doppler dimensions, followed by transmitter-specific peak identification and snapshot data extraction. The PVA operator is pvaPeakDetection.
DOA Processing -> Calculates the direction of arrivals of the radar signals. It uses input tensors including peak count, calibration vector, and range-doppler snapshots to calculate target information such as azimuth, elevation, range, velocity and 3D points. The output is a 2D tensor with shape of [7, DOA_MAX_TARGET_COUNT]. The PVA operator is pvaDOA.
Radar fixed-point pipeline sample application#
The Radar fixed-point pipeline sample application is a comprehensive, reference implementation for processing radar data through multiple computational stages using NVIDIA’s PVA (Programmable Vision Accelerator) platform.
Key Characteristics:
Fixed-Point Arithmetic: The entire pipeline operates using mixed fixed-point and floating-point data types (S32, 2S32, U32, F32) to ensure deterministic computation, reduce memory bandwidth, and optimize for PVA hardware acceleration
Multi-Stage Processing: Five sequential processing stages that progressively refine raw radar data into target detection and tracking information
Hardware Acceleration: Leverages NVIDIA PVA for parallel processing of computationally intensive operations like FFT, non-coherent integration, and peak detection
Reference Validation: Each stage includes CPU-based reference implementations for accuracy validation and regression testing
Batch Processing: Supports processing multiple radar data files in sequence with efficient resource reuse
Configurable Parameters: Flexible configuration for different radar configurations (transmit/receive channels, range bins, sampling rates)
Pipeline Data Flow:
The pipeline processes radar data through the following transformation sequence:
Raw ADC Data → Range FFT → Doppler FFT → NCI Processing → Peak Detection → DOA Processing → Target Information
Technical Implementation:
The implementation follows a modular, object-oriented design pattern with clear separation of concerns:
Resource Management: RAII-based tensor and operator lifecycle management with automatic cleanup
Memory Optimization: Uses PVA-optimized memory allocators for efficient data placement and access patterns. In production code, users can leverage NvSci and CUDA interop APIs to eliminate memory copies required for input and output data in the end-to-end pipeline.
Synchronization: PVA SDK based synchronization primitives for coordinating PVA and CPU operations
Error Handling: Comprehensive error checking with graceful degradation and resource cleanup
Validation Framework: Built-in reference implementations and tolerance-based output validation
Supported Radar Configurations:
Multi-Channel Processing:
PVA_RADAR_RX_ANTENNA_COUNT(4) receive channels andPVA_RADAR_TX_ANTENNA_COUNT(4) transmit channelsConfigurable Resolution: Adjustable range bins (Nb), sample count (sampleCount), and Doppler bins (chirpCount)
Doppler Fold Processing: Support for non-coherent integration across multiple pulse repetition intervals (
PVA_RADAR_DOPPLER_FOLD_COUNT)Peak Capacity: Handles up to
PVA_RADAR_MAX_TARGET_COUNT(8192) simultaneous target detectionsTarget Properties: Outputs
PVA_RADAR_NUM_TARGET_DETECTION_PROPERTIES(7) detection properties per target
Performance Features:
Pipeline Mapping: Efficiently map the pipeline stages to the PVA hardware resources to maximize throughput
Deterministic Timing: Fixed-point operations provide consistent execution times for real-time applications
Design Details#
The radar pipeline consists of the following main components:
RadarPipelineTensorRequirements: Holds tensor requirements without allocation (used for operator creation)
RadarPipelineTensors: Manages all tensor allocations for processing a single radar data file
RadarPipelineOperators: Manages PVA operator handles (created once, reused across multiple files)
RadarPipelinePVAWorkloadParams: Handles CUPVA synchronization objects and allocator
Fixed-Point Data Types and Precision:
The pipeline uses carefully selected fixed-point data types optimized for radar signal processing:
NVCV_DATA_TYPE_S32: 32-bit signed integers for input radar samples and window coefficients
NVCV_DATA_TYPE_2S32: Complex 32-bit signed integers (real + imaginary) for FFT operations
NVCV_DATA_TYPE_U32: 32-bit unsigned integers for NCI outputs and peak detection results
NVCV_DATA_TYPE_F32: 32-bit floating-point for final DOA calculations requiring high precision
Quantization and Q-Format:
The implementation uses Q-format fixed-point arithmetic with configurable precision:
Range FFT: Requires QBits = 20 for input tensor to maintain high precision for subsequent pipeline stages, e.g. Peak Detection, NCI and DOA processing
Peak Detection: Integer arithmetic for robust threshold comparison and peak identification
Doppler Fold Count:
PVA_RADAR_DOPPLER_FOLD_COUNTdefines non-coherent integration factor
Memory Layout and Tensor Organization:
Tensors are organized with optimal memory layouts for PVA processing:
HCW Layout: Height-Channel-Width organization for efficient parallel processing
Transpose: Uses transpose operations to optimize memory access patterns
Stride Optimization: Memory strides aligned to PVA requirements for maximum throughput
Buffer Reuse: Input tensors for subsequent stages point to output tensors of previous stages (e.g.,
inDopplerFFTTensorHandle = outRangeFFTTensorHandle)
Execution Model and Workload Management:
The pipeline implements a sophisticated execution model optimized for batch processing with operator reuse:
- Phase 1: Operator Creation (Once per Configuration)
PVA operators created once using
RadarPipelineTensorRequirementsTensor requirements calculated without actual memory allocation
Operators shared across all data files for efficiency
Geometric parameters (GP) initialized with calibration data
- Phase 2: Per-File Processing
RadarPipelineTensorscreated for each file with actual memory allocationRAII (Resource Acquisition Is Initialization) ensures automatic cleanup
Input data loaded into tensors
All pipeline stages submitted sequentially to PVA
PVA SDK based synchronization ensures proper execution ordering
- Phase 3: Reference Validation
CPU-based reference implementations execute after PVA processing
Tolerance-based comparison validates numerical accuracy
Multi-File Batch Processing:
The implementation supports efficient processing of multiple radar data files with operator reuse:
// Create operators once (shared across all files)
RadarPipelineOperators operators{};
RadarPipelineTensorRequirements tensorReqs(sampleCount, rxAntennaCount,
chirpCount, dopplerFoldCount, txAntennaCount);
radar_create_pva_workloads(operators, tensorReqs, txAntennaCount, dopplerFoldCount);
// Process each file
for (const auto &file : files) {
// Tensors created per file (RAII cleanup)
RadarPipelineTensors tensors(allocatorHandle, sampleCount, rxAntennaCount,
chirpCount, dopplerFoldCount, txAntennaCount);
// Submit workloads and execute
radar_submit_pva_workloads(operators, tensors, pvaWorkloadParams);
radar_execute_ref_workloads(tensors, txAntennaCount, rxAntennaCount, dopplerFoldCount);
} // Tensors automatically destroyed here
Pipeline Stages#
Range FFT Processing
Purpose: Converts time-domain radar samples to range-frequency domain for target range estimation
Algorithm: Windowed FFT with Hanning window (
PVA_BATCH_FFT_WINDOW_HANNING) to minimize spectral leakageInput: Raw radar ADC samples [sampleCount=512][rxAntennaCount][chirpCount=512] as 32-bit signed integers
Output: Complex range FFT data [chirpCount=512][rxAntennaCount][NbNci=224] as complex 32-bit signed integers
Window Function: Pre-computed Hanning window coefficients applied to reduce sidelobe artifacts
Validation: Reference implementation comparison with configurable tolerance (0.0f for exact match)
Doppler FFT Processing
Purpose: Extracts target velocity information through coherent processing across pulse repetition intervals
Algorithm: Windowed FFT with output transpose (
transposeOutput = 1) for optimal memory layoutInput: Range FFT output [chirpCount][rxAntennaCount][224] as complex 32-bit signed integers
Output: Doppler FFT data [224][rxAntennaCount][chirpCount] as complex 32-bit signed integers (transposed)
Window Function: Range-domain Hanning window to suppress range sidelobes in velocity processing
Memory Optimization: Transpose operation optimizes subsequent NCI processing access patterns
NCI (Non Coherent Integration) Processing
Purpose: Performs noise estimation and non-coherent integration to improve signal-to-noise ratio
Algorithm: Multi-output non-coherent integration with configurable doppler fold processing
Input: Doppler FFT output [224][rxAntennaCount][chirpCount] with 20-bit Q-format precision
Processing Parameters:
dopplerFoldCount = PVA_RADAR_DOPPLER_FOLD_COUNT: Non-coherent integration factor for SNR improvement
Outputs:
NCI RX: [Nb=224][chirpCount=512] - Receive-channel non-coherent integration results
NCI Final: [Nb=224][chirpCount/dopplerFoldCount=64] - Final non-coherent integration across doppler fold
Noise Estimate: [Nb=224] - Range-dependent noise floor estimation
Peak Detection
Purpose: Identifies potential targets by detecting peaks above noise threshold
Algorithm: Configurable threshold-based peak detection with spatial clustering and Doppler disambiguation
Input: All NCI outputs (original input, RX, final, noise estimate)
Processing Parameters:
txAntennaCount: Number of transmit channels for beamforming considerationsdopplerFoldCount: Coherent integration factor for detection threshold calculation
Outputs:
Peak Count: [1] - Number of detected peaks (up to
PVA_RADAR_MAX_TARGET_COUNT = 8192)Peak Indices: [
PVA_RADAR_PEAKDET_NUM_PEAK_INDICES][8192] - Range, Doppler, and receive channel indices for each peakPeak Snap: [8192][16] - Local neighborhood data around each peak for sub-bin interpolation
Capacity: Supports up to 8192 simultaneous target detections
DOA (Direction of Arrival) Processing
Purpose: Calculates target position, velocity, and angular information using array processing
Algorithm: FFT-based digital beamforming and dual-aperture interferometry with geometric parameter (GP) calibration
Input Components:
Peak detection outputs (count, indices, snap data)
Calibration vector [1][
PVA_RADAR_NUM_TOTAL_ANTENNA_ELEMENTS] - Complex antenna array calibration coefficientsNCI final data for amplitude/phase reference
Geometric parameters (
PVARadarGP GP) for coordinate transformation
Calibration:
populateCalibVector(calibVector, 30)- 30-element calibration for array processingOutput: DOA results [
PVA_RADAR_NUM_TARGET_DETECTION_PROPERTIES][PVA_RADAR_MAX_TARGET_COUNT] containing:Velocity: Target radial velocity (m/s)
Range: Target distance (m)
Azimuth: Horizontal angle (degrees)
Elevation: Vertical angle (degrees)
X, Y, Z: Cartesian coordinates (m)
Validation: Tolerance-based comparison (
2e-4f) between PVA and reference implementations
Classes and Components#
RadarPipelineTensorRequirements#
A C++ class that holds tensor requirements without actual memory allocation. Used for operator creation.
Constructor Parameters:
sampleCount(int32_t): Number of samples per chirprxAntennaCount(int32_t): Number of receive antenna channelschirpCount(int32_t): Number of chirps per framedopplerFoldCount(int32_t): Doppler fold factor for non-coherent integrationtxAntennaCount(int32_t): Number of transmit antenna channels
Key Components:
Tensor Requirements: Requirements for all pipeline tensors (shape, layout, data type)
NCI Output Requirements Vector:
outNciTensorReqs- Pointer array for NCI output requirementsDOA Input Requirements Vector:
inDOATensorReqs- Pointer array for DOA input requirementsGeometric Parameters:
PVARadarGP GP- Radar system geometric calibration
RadarPipelineTensors#
A C++ class that manages all tensor allocations for processing a single radar data file. Uses RAII for automatic cleanup.
Constructor Parameters:
allocatorHandle(NVCVAllocatorHandle): PVA memory allocatorsampleCount(int32_t): Number of samples per chirprxAntennaCount(int32_t): Number of receive antenna channelschirpCount(int32_t): Number of chirps per framedopplerFoldCount(int32_t): Doppler fold factor for non-coherent integrationtxAntennaCount(int32_t): Number of transmit antenna channels
Key Methods:
void initRadarPipelineTensors();
void cleanupRadarPipelineTensors();
void createRadarPipelineTensors(NVCVAllocatorHandle allocatorHandle,
const int32_t sampleCount,
const int32_t rxAntennaCount,
const int32_t chirpCount,
const int32_t dopplerFoldCount,
const int32_t txAntennaCount);
Tensor Categories:
Range FFT Tensors: Input, window, output, and reference tensors
Doppler FFT Tensors: Input, window, output, and reference tensors
NCI Tensors: Input and multiple output tensors for different NCI stages
Peak Detection Tensors: Output tensors for peak count, indices, and snap data
DOA Tensors: Input calibration vectors and output result tensors
Geometric Parameters:
PVARadarGP GP- Shared with requirements object
RadarPipelineOperators#
A C++ class that manages PVA operator handles. Created once and reused across multiple files.
Key Components:
Operator Handles: For each processing stage (Range FFT, Doppler FFT, NCI, Peak Detection, DOA)
Lifetime: Created once per radar configuration, destroyed at end of application
Key Methods:
void initRadarPipelineOperators();
void cleanupRadarPipelineOperators();
RadarPipelinePVAWorkloadParams#
A C++ class that handles CUPVA synchronization objects and allocator.
Key Components:
Allocator Handle:
NVCVAllocatorHandle- PVA memory allocator for tensor allocationCUPVA Objects: Synchronization objects (sync, fence, stream) for PVA execution
Key Methods:
void initRadarPipelinePVAWorkloadParams();
void cleanupRadarPipelinePVAWorkloadParams();
API Functions#
Workload Management Functions#
radar_create_pva_workloads()#
Creates all PVA operators for the radar pipeline. Called once per configuration.
Parameters:
operators(RadarPipelineOperators&): Operator management object (output)tensorReqs(RadarPipelineTensorRequirements&): Tensor requirements objectNofTx(int32_t): Number of transmit channelsrepeatFold(int32_t): Doppler fold factor
Returns: 0 on success, non-zero error code on failure
radar_submit_pva_workloads()#
Submits all PVA workloads for execution.
Parameters:
operators(RadarPipelineOperators&): Operator management objecttensors(RadarPipelineTensors&): Tensor management object for current filepvaWorkloadParams(RadarPipelinePVAWorkloadParams&): PVA workload parameters
Returns: 0 on success, non-zero error code on failure
radar_execute_ref_workloads()#
Executes reference implementations and validates PVA outputs.
Parameters:
tensors(RadarPipelineTensors&): Tensor management objectNofTx(int32_t): Number of transmit channelsNofRx(int32_t): Number of receive channelsrepeatFold(int32_t): Doppler fold factor
Returns: 0 on success, non-zero error code on failure
Processing Stage Functions#
range_fft_processing()#
Processes Range FFT stage with validation against reference implementation.
Parameters:
tensors(RadarPipelineTensors&): Tensor management object
Returns: 0 on success, non-zero error code on failure
doppler_fft_processing()#
Processes Doppler FFT stage with validation against reference implementation.
Parameters:
tensors(RadarPipelineTensors&): Tensor management object
Returns: 0 on success, non-zero error code on failure
nci_processing()#
Processes NCI stage with configurable tolerance values.
Parameters:
tensors(RadarPipelineTensors&): Tensor management object
Returns: 0 on success, non-zero error code on failure
peak_detection()#
Performs peak detection and extracts peak information.
Parameters:
tensors(RadarPipelineTensors&): Tensor management objectNofTx(int32_t): Number of transmit channelsNofRx(int32_t): Number of receive channelsrepeatFold(int32_t): Doppler fold factorpeakCount(int32_t&): Output parameter for number of detected peaks
Returns: 0 on success, non-zero error code on failure
doa_processing()#
Calculates direction of arrival and target information.
Parameters:
tensors(RadarPipelineTensors&): Tensor management objectpeakCount(int32_t): Number of detected peaks from peak detection stage
Returns: 0 on success, non-zero error code on failure
Utility Functions#
readFilesWithPrefix()#
Reads files with a specific prefix from a directory.
Parameters:
directoryPath(const std::string&): Directory to searchprefix(const std::string&): File prefix to match
Returns: Vector of matching file paths
Configuration and Constants#
Default Pipeline Parameters#
const int32_t sampleCount = 512; // Number of samples per chirp
const int32_t chirpCount = 512; // Number of chirps per frame
const int32_t rxAntennaCount = PVA_RADAR_RX_ANTENNA_COUNT; // Receive channels (4)
const int32_t txAntennaCount = PVA_RADAR_TX_ANTENNA_COUNT; // Transmit channels (4)
const int32_t dopplerFoldCount = PVA_RADAR_DOPPLER_FOLD_COUNT; // Doppler fold factor (8)
Tensor Dimensions#
Range FFT: [chirpCount][rxAntennaCount][224]
Doppler FFT: [224][rxAntennaCount][chirpCount]
NCI RX: [224][chirpCount]
NCI Final: [224][chirpCount/dopplerFoldCount]
Noise Estimate: [224]
Peak Indices: [
PVA_RADAR_PEAKDET_NUM_PEAK_INDICES][8192]Peak Snap: [8192][16]
DOA Output: [
PVA_RADAR_NUM_TARGET_DETECTION_PROPERTIES][8192]
Usage Example#
Basic Pipeline Execution#
#include "radar_pipeline_pva.hpp"
#include "radar_pipeline_reference.hpp"
#include "radar_pipeline_tensors.hpp"
#include "range_fft_ref.h"
#include "utils/radar_file_parser.h"
int main(int argc, char** argv) {
// Pipeline parameters
const int32_t sampleCount = 512;
const int32_t chirpCount = 512;
const int32_t rxAntennaCount = PVA_RADAR_RX_ANTENNA_COUNT;
const int32_t txAntennaCount = PVA_RADAR_TX_ANTENNA_COUNT;
const int32_t dopplerFoldCount = PVA_RADAR_DOPPLER_FOLD_COUNT;
// Initialize PVA workload parameters
RadarPipelinePVAWorkloadParams pvaWorkloadParams{};
// Create operators once (shared across all files)
RadarPipelineOperators operators{};
RadarPipelineTensorRequirements tensorReqs(sampleCount, rxAntennaCount,
chirpCount, dopplerFoldCount, txAntennaCount);
// Create PVA operators
printf("Creating PVA operators\n");
int err = radar_create_pva_workloads(operators, tensorReqs,
txAntennaCount, dopplerFoldCount);
if (err != 0) {
printf("Failed to create PVA workloads: %d\n", err);
return err;
}
// Read input data files
std::string assetsDir = "/path/to/assets/radar/";
std::vector<std::string> files = readFilesWithPrefix(assetsDir, "data_");
// Process each file
for (const auto &file : files) {
printf("Processing file %s\n", file.c_str());
// Read raw data
auto raw_data = rsps_RawFileRead<int32_t>(file);
// Create tensors for this file (RAII cleanup)
RadarPipelineTensors tensors(pvaWorkloadParams.allocatorHandle,
sampleCount, rxAntennaCount, chirpCount,
dopplerFoldCount, txAntennaCount);
// Load input data
load_range_fft_input(tensors.inRangeFFTTensorHandle, raw_data.second);
// Submit PVA workloads
printf("Submitting PVA workloads\n");
err = radar_submit_pva_workloads(operators, tensors, pvaWorkloadParams);
if (err != 0) {
printf("Failed to submit PVA workloads: %d\n", err);
break;
}
// Execute and validate
printf("Executing reference workloads\n");
err = radar_execute_ref_workloads(tensors, txAntennaCount,
rxAntennaCount, dopplerFoldCount);
if (err != 0) {
printf("Reference workload execution failed: %d\n", err);
break;
}
printf("Successfully processed file\n");
} // Tensors automatically destroyed here
return err;
}
Command Line Usage#
# Basic usage
./radar_pipeline_test
# Show help
./radar_pipeline_test --help
./radar_pipeline_test -h
./radar_pipeline_test -a /path/to/assets
Error Handling#
The pipeline uses comprehensive error checking throughout all stages:
NVCV_CHECK_ERROR_GOTO: For NVCV API calls
CUPVA_CHECK_ERROR_GOTO: For CUPVA API calls
Return code validation: All functions return 0 on success, non-zero on error
Resource cleanup: Automatic cleanup in destructors and error paths
Common error scenarios:
Asset directory not found
Input data file missing or corrupted
PVA operator creation failure
Tensor allocation failure
Output validation mismatch
Performance Considerations#
Memory Management: Uses PVA allocator for optimal memory placement
Parallel Processing: Multiple files can be processed in batches
Resource Reuse: Tensors and operators are reused across files
Dependencies#
NVCV: NVIDIA Computer Vision library
PVA: Programmable Vision Accelerator
PVA-SDK: PVA SDK library
Standard C++: For file I/O and container operations
Radar Operators: Radar operators library
Radar File Parser: Radar file parser library
Radar Range FFT Reference: Radar range FFT reference implementation
Radar Doppler FFT Reference: Radar Doppler FFT reference implementation
Radar NCI Reference: Radar NCI reference implementation
Radar Peak Detection Reference: Radar Peak Detection reference implementation
Radar DOA Reference: Radar DOA reference implementation
Performance#
The performance of the radar pipeline is primarily determined by the size of the input tensor and the number of detected peaks, which is decided by the pipeline stages.
Execution Time is the average time required to execute the operator on a single VPU core.
Note that each PVA contains two VPU cores, which can operate in parallel to process two streams simultaneously, or reduce execution time by approximately half by splitting the workload between the two cores.
Total Power represents the average total power consumed by the module when the operator is executed concurrently on both VPU cores.
Idle power is approximately 7W when the PVA is not processing data.
For detailed information on interpreting the performance table below and understanding the benchmarking setup, see Performance Benchmark.
SampleCount |
RxAntennaCount |
ChirpCount |
DataFile |
InputDataType |
OutputDataType |
Execution Time |
Submit Latency |
Total Power |
|---|---|---|---|---|---|---|---|---|
512 |
4 |
512 |
data_1 |
S32 |
F32 |
1.456ms |
0.287ms |
14.754W |