YOLOv3
YOLOv3 is an object detection model that is included in the TAO Toolkit. YOLOv3 supports the following tasks:
kmeans
train
evaluate
inference
prune
export
These tasks can be invoked from the TAO Toolkit Launcher using the following convention on the command line:
tao yolo_v3 <sub_task> <args_per_subtask>
where args_per_subtask are the command line arguments required for a given subtask. Each
subtask is explained in detail below.
Below is a sample for the YOLOv3 spec file. It has six major components: yolov3_config,
training_config, eval_config, nms_config, augmentation_config, and
dataset_config. The format of the spec file is a protobuf text (prototxt) message and each
of its fields can be either a basic data type or a nested message. The top level structure of the
spec file is summarized in the table below.
random_seed: 42
yolov3_config {
big_anchor_shape: "[(114.94, 60.67), (159.06, 114.59), (297.59, 176.38)]"
mid_anchor_shape: "[(42.99, 31.91), (79.57, 31.75), (56.80, 56.93)]"
small_anchor_shape: "[(15.60, 13.88), (30.25, 20.25), (20.67, 49.63)]"
matching_neutral_box_iou: 0.7
arch: "resnet"
nlayers: 18
arch_conv_blocks: 2
loss_loc_weight: 0.8
loss_neg_obj_weights: 100.0
loss_class_weights: 1.0
freeze_bn: false
#freeze_blocks: 0
force_relu: false
}
training_config {
batch_size_per_gpu: 8
num_epochs: 80
enable_qat: false
checkpoint_interval: 10
learning_rate {
soft_start_annealing_schedule {
min_learning_rate: 1e-6
max_learning_rate: 1e-4
soft_start: 0.1
annealing: 0.5
}
}
regularizer {
type: L1
weight: 3e-5
}
optimizer {
adam {
epsilon: 1e-7
beta1: 0.9
beta2: 0.999
amsgrad: false
}
}
pretrain_model_path: "EXPERIMENT_DIR/pretrained_resnet18/tlt_pretrained_object_detection_vresnet18/resnet_18.hdf5"
}
eval_config {
average_precision_mode: SAMPLE
batch_size: 8
matching_iou_threshold: 0.5
}
nms_config {
confidence_threshold: 0.001
clustering_iou_threshold: 0.5
top_k: 200
force_on_cpu: True
}
augmentation_config {
hue: 0.1
saturation: 1.5
exposure:1.5
vertical_flip:0
horizontal_flip: 0.5
jitter: 0.3
output_width: 1248
output_height: 384
output_channel: 3
randomize_input_shape_period: 0
}
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tao-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tao-experiments/data/training"
}
include_difficult_in_training: true
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
Training Config
The training configuration (training_config) defines the parameters needed for the
training, evaluation and inference. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
batch_size_per_gpu |
The batch size for each GPU, so the effective batch size is batch_size_per_gpu * num_gpus |
Unsigned int, positive |
– |
checkpoint_interval |
The number of training epochs per model checkpoint / validation that should run |
Unsigned int, positive |
10 |
num_epochs |
The number of epochs to train the network |
Unsigned int, positive. |
– |
enable_qat |
Whether to use quantization-aware training |
Boolean |
Note: YOLOv3 does not support loading a pruned QAT model and retraining
it with QAT disabled, or vice versa. For example, to get a pruned QAT model,
perform the initial training with QAT enabled or |
learning_rate |
Only “soft_start_annealing_schedule” with these nested parameters is supported:
|
Message type. |
– |
regularizer |
This parameter configures the regularizer to be used while training and contains the following nested parameters:
|
Message type. |
L1 (Note: NVIDIA suggests using L1 regularizer when training a network before pruning as L1 regularization helps making the network weights more prunable.) |
optimizer |
Can be one of “adam”, “sgd”, or “rmsprop”. Each type has the following parameters:
The parameters are same as those in Keras. |
Message type. |
– |
pretrain_model_path |
The path to the pretrained model, if any At most one of pretrain_model_path, resume_model_path, or pruned_model_path may present. |
String |
– |
resume_model_path |
The path to a TAO checkpoint model to resume training, if any At most one of pretrain_model_path, resume_model_path, or pruned_model_path may present. |
String |
– |
pruned_model_path |
The path to a TAO pruned model for re-training, if any At most one of pretrain_model_path, resume_model_path, or pruned_model_path may present. |
String |
– |
max_queue_size |
The number of prefetch batches in data loading |
Unsigned int, positive |
– |
n_workers |
The number of workers for data loading per GPU |
Unsigned int, positive |
– |
use_multiprocessing |
Whether to use multiprocessing mode of keras sequence data loader |
Boolean |
true (in case of deadlock, restart training and use False) |
The learning rate is automatically scaled with the number of GPUs used during training, or the effective learning rate is learning_rate * n_gpu.
Evaluation Config
The evaluation configuration (eval_config) defines the parameters needed for evaluation
either during training or as a standalone procedure. Details are summarized in the table
below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
average_precision_mode |
Average Precision (AP) calculation mode can be either SAMPLE or INTEGRATE. SAMPLE is used as VOC metrics for VOC 2009 or before. INTEGRATE is used for VOC 2010 or after that. |
ENUM type ( SAMPLE or INTEGRATE) |
SAMPLE |
matching_iou_threshold |
The lowest IoU of predicted box and ground truth box that can be considered a match. |
float |
0.5 |
NMS Config
The NMS configuration (nms_config) defines the parameters needed for the NMS postprocessing.
NMS config applies to the NMS layer of the model in training, validation, evaluation, inference
and export. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
confidence_threshold |
Boxes with a confidence score less than confidence_threshold are discarded before applying NMS. |
float |
0.01 |
cluster_iou_threshold |
The IoU threshold below which boxes will go through the NMS process. |
float |
0.6 |
top_k |
top_k boxes will be output after the NMS keras layer. If the number of valid boxes is less than k, the returned array will be padded with boxes whose confidence score is 0. |
Unsigned int |
200 |
infer_nms_score_bits |
The number of bits to represent the score values in NMS plugin in TensorRT OSS. The valid range is integers in [1, 10]. Setting it to any other values will make it fall back to ordinary NMS. Currently this optimized NMS plugin is only avaible in FP16 but it should also be selected by INT8 data type as there is no INT8 NMS in TensorRT OSS and hence this fastest implementation in FP16 will be selected. If falling back to ordinary NMS, the actual data type when building the engine will decide the exact precision(FP16 or FP32) to run at. |
int. In the interval [1, 10]. |
0 |
force_on_cpu |
A flag to force NMS to run on CPU. Setting it to True will force NMS to run on CPU during training. This is useful when using TFRecord dataset for validation during training since there is a known issue with TensorFlow NMS on GPU when using TFRecord dataset for validation. Note Note that this flag does not have any impact on TAO export and TensorRT/DeepStream inference. |
Boolean |
False |
Augmentation Config
The augmentation configuration (augmentation_config) defines the parameters needed for online
data augmentation. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
hue |
Image hue to be changed within [-hue, hue] * 180.0 |
float of [0, 1] |
0.1 |
saturation |
Image saturation to be changed within [1.0 / saturation, saturation] times |
float >= 1.0 |
1.5 |
exposure |
Image exposure to be changed within [1.0 / exposure, exposure] times |
float >= 1.0 |
1.5 |
vertical_flip |
The probability of images to be vertically flipped |
float of [0, 1] |
0 |
horizontal_flip |
The probability of images to be horizontally flipped |
float of [0, 1] |
0.5 |
jitter |
The maximum jitter allowed in augmentation. Jitter here refers to jitter augmentation in YOLO networks |
float of [0, 1] |
0.3 |
output_width |
The base output image width of augmentation pipeline. |
integer, multiple of 32 |
– |
output_height |
The base output image height of augmentation pipeline |
integer, multiple of 32 |
– |
output_channel |
The number of output channels of augmentation pipeline |
1 or 3 |
– |
randomize_input_shape_period |
The batch interval to randomly change the output width and height. For value K, the augmentation pipeline will adjust the output shape per K batches and the adjusted output width/height will be within 0.6 to 1.5 times of base width/height. Note: if K=0, the output width/height will always match the base width/height as configured and training will be much faster, but the accuracy of trained network might not be as good. |
non-negative integer |
10 |
image_mean |
A key/value pair to specify image mean values. If omitted, ImageNet mean will be used for image preprocessing. If set, depending on output_channel, either ‘r/g/b’ or ‘l’ key/value pair must be configured. |
dict |
– |
Dataset Config
YOLOv3 supports two data formats: the sequence format (KITTI images folder and raw labels folder) and the TFRecords format (KITTI images folder and TFRecords). Training with TFRecord dataset in most cases are faster than sequence format and hence TFRecord dataset is the recommended format. However, in some cases like small input resolutions(e.g., 416x416), the sequence format is slightly faster TFRecord.
The YOLOv3 dataloader assumes the training/validation split is already done and the data is
prepared in KITTI format: images and labels are in two separate folders, where each image in the
image folder has a .txt label file with the same filename in the label folder, and the
label file content follows KITTI format.
Below is an example dataset_config for TFRecord dataset.
dataset_config {
data_sources: {
tfrecords_path: "/workspace/tao-experiments/data/tfrecords/kitti_trainval/kitti_trainval*"
image_directory_path: "/workspace/tao-experiments/data/training"
}
include_difficult_in_training: true
image_extension: "png"
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_fold: 0
}
The following is an example dataset_config element if you want to use sequence format:
dataset_config {
data_sources: {
label_directory_path: "/workspace/tao-experiments/data/training/label_2"
image_directory_path: "/workspace/tao-experiments/data/training/image_2"
}
data_sources: {
label_directory_path: "/workspace/tao-experiments/data/training/label_3"
image_directory_path: "/workspace/tao-experiments/data/training/image_3"
}
include_difficult_in_training: true
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "pedestrian"
value: "pedestrian"
}
target_class_mapping {
key: "cyclist"
value: "cyclist"
}
target_class_mapping {
key: "van"
value: "car"
}
target_class_mapping {
key: "person_sitting"
value: "pedestrian"
}
validation_data_sources: {
label_directory_path: "/workspace/tao-experiments/data/val/label_1"
image_directory_path: "/workspace/tao-experiments/data/val/image_1"
}
}
The parameters in dataset_config are defined as follows:
data_sources: Captures the path to datasets to train on. If you have multiple data sources for training, you may use multipledata_sources. For sequence format, this field contains 2 parameters:label_directory_path: Path to the data source label folderimage_directory_path: Path to the data source image folder
For TFRecord format, this field contains 2 parameters:
tfrecords_path: Path to the TFRecord files, this can be a pattern to match multiple TFrecord files.image_directory_path: Path to the data source image folder. Make sure this aligns with the path specified indataset_convertcommand.
include_difficult_in_training: Specifies whether to include difficult boxes in training. If set to False, difficult boxes will be ignored. Difficult boxes are those with non-zero occlusion levels in KITTI labels.image_extension: The suffix(extension) of the image file. For example,pngorjpg, etc. This parameter is only useful when using TFRecord dataset.target_class_mapping: This parameter maps the class names in the labels to the target class to be trained in the network. An element is defined for every source class to target class mapping. This field is included with the intention of grouping similar class objects under one umbrella. For example, “car”, “van”, “heavy_truck”, etc. may be grouped under “automobile”. The “key” field is the value of the class name in the tfrecords file, and the “value” field corresponds to the value that the network is expected to learn.validation_data_sources: Captures the path to datasets to validate on. If you have multiple data sources for validation, you may use multiplevalidation_data_sources. Likedata_sources, this field contains two same parameters. This parameter is exclusive withvalidation_fold.validation_fold: When using TFRecord dataset for training, the validation dataset can be a split(fold) in the training dataset. This parameter is exclusive withvalidation_data_sources.
The class names key in the target_class_mapping must be identical to the one shown in the KITTI labels so that the correct classes are picked up for training.
YOLOv3 Config
The YOLOv3 configuration (yolov3_config) defines the parameters needed for building the
YOLOv3 model. Details are summarized in the table below.
Field |
Description |
Data Type and Constraints |
Recommended/Typical Value |
big_anchor_shape, mid_anchor_shape, and small_anchor_shape |
These settings should be 1-d arrays inside quotation marks. The elements of these arrays are tuples representing the pre-defined anchor shape in the order of width, height. By default, YOLOv3 has nine predefined anchor shapes, divided into three groups
corresponding to big, medium, and small objects. The detection output corresponding to
different groups are from different depths in the network. Users should run the kmeans
command ( |
string |
Use tao yolo_v3 kmeans command to generate those shapes |
matching_neutral_box_iou |
This field should be a float number between 0 and 1. Any inferred bounding box with IOU higher than this float value to any ground truth box, will not have their objectiveness loss back-propagated during training. This is to reduce false negatives. |
float |
0.5 |
arch_conv_blocks |
Supported values are 0, 1 and 2. This value controls how many convolutional blocks are present among detection output layers. Setting this value to 2 if you want to reproduce the meta architecture of the original YOLOv3 model coming with DarkNet 53. Please note this config setting only controls the size of the YOLO meta architecture and the size of the feature extractor has nothing to do with this config field. |
0, 1 or 2 |
2 |
loss_loc_weight, loss_neg_obj_weights, and loss_class_weights |
Those loss weights can be configured as float numbers. The YOLOv3 loss is a summation of localization loss, negative objectiveness loss, positive objectiveness loss and classification loss. The weight of positive objectiveness loss is set to 1 while the weights of other losses are read from config file. |
float |
loss_loc_weight: 5.0 loss_neg_obj_weights: 50.0 loss_class_weights: 1.0 |
arch |
Backbone for feature extraction. Currently, “resnet”, “vgg”, “darknet”, “googlenet”, “mobilenet_v1”, “mobilenet_v2” and “squeezenet” are supported. |
string |
resnet |
nlayers |
Number of conv layers in specific arch. For “resnet”, 10, 18, 34, 50 and 101 are supported. For “vgg”, 16 and 19 are supported. For “darknet”, 19 and 53 are supported. All other networks don’t have this configuration and users should just delete this config from the config file. |
Unsigned int |
– |
freeze_bn |
Whether to freeze all batch normalization layers during training. |
boolean |
False |
freeze_blocks |
The list of block IDs to be frozen in the model during training. You can choose to freeze some of the CNN blocks in the model to make the training more stable and/or easier to converge. The definition of a block is heuristic for a specific architecture. For example, by stride or by logical blocks in the model, etc. However, the block ID numbers identify the blocks in the model in a sequential order so you don’t have to know the exact locations of the blocks when you do training. A general principle to keep in mind is: the smaller the block ID, the closer it is to the model input; the larger the block ID, the closer it is to the model output. You can divide the whole model into several blocks and optionally freeze a subset of it. Note that for FasterRCNN you can only freeze the blocks that are before the ROI pooling layer. Any layer after the ROI pooling layer will not be frozen any way. For different backbones, the number of blocks and the block ID for each block are different. It deserves some detailed explanations on how to specify the block ID’s for each backbone. |
list(repeated integers)
|
– |
force_relu |
Whether to replace all activation functions with ReLU. This is useful for training models for NVDLA. |
boolean |
False |
The anchor shape should match most ground truth boxes in the dataset to help the network learn
bounding boxes. You can use the kmeans algorithm to generate the anchor shapes. The algorithm is
implemented in TAO Toolkit as the tao yolo_v3 kmeans command. You can use the output of the
algorithm as the anchor shape in the yolov3_config spec file.
tao yolo_v3 kmeans [-h] -l <label_folders>
-i <image_folders>
-x <network base input width>
-y <network base input height>
[-n <num_clusters>]
[--max_steps <kmeans max steps>]
[--min_x <ignore boxes with width less than this value>]
[--min_y <ignore boxes with height less than this value>]
Required Arguments
-l: The paths to the training label folders. Multiple folder paths should be separated with spaces.-i: The paths to corresponding training image folders. Folder counts and orders must match label folders.-x: The base network input width, which should be output_width in the augmentation config section of your spec file.-y: The base network input height, which should be output_height in the augmentation config section of your spec file.
Optional Arguments
-n: The number of shape clusters. This defines how many shape centers the command will output. The default is 9 (3 per group, with 3 groups)--max_steps: The maximum number of steps the kmeans algorithm should run. If the algorithm does not converge at this step, a suboptimal result will be returned. The default value is 10000.--min_x: Ignore ground-truth boxes with width less than this value in the reshaped image (images are first reshaped to the network base shape as -x, -y)--min_y: Ignore ground-truth boxes with height less than this value in the reshaped image (images are first reshaped to the network base shape as -x, -y)-h, --help: Show this help message and exit.
Train the YOLOv3 model using this command:
tao yolo_v3 train [-h] -e <experiment_spec>
-r <output_dir>
-k <key>
[--gpus <num_gpus>]
[--gpu_index <gpu_index>]
[--use_amp]
[--log_file <log_file_path>]
Required Arguments
-r, --results_dir: Path to the folder where the experiment output is written.-k, --key: Provide the encryption key to decrypt the model.-e, --experiment_spec_file: Experiment specification file to set up the evaluation experiment. This should be the same as the training specification file.
Optional Arguments
--gpus: The number of GPUs to be used for training in a multi-GPU scenario (the default value is 1).--gpu_index: The GPU indices used to run training. You can use GPU indicies to specify the GPU(s) to use for training when the machine has multiple GPUs installed.--use_amp: A flag to enable AMP training.--log_file: The path to the log file. The default path is “stdout”.-h, --help: Show this help message and exit.
Input Requirement
Input size: C * W * H (where C = 1 or 3, W >= 128, H >= 128, W, H are multiples of 32)
Image format: JPG, JPEG, PNG
Label format: KITTI detection
Sample Usage
Here’s an example of using the train command on a YOLOv3 model:
tao yolo_v3 train --gpus 2 -e /path/to/spec.txt -r /path/to/result -k $KEY
To run evaluation for a YOLOv3 model use this command:
tao yolo_v3 evaluate [-h] -e <experiment_spec_file>
-m <model_file>
-k <key>
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-e, --experiment_spec_file: Experiment spec file to set up the evaluation experiment. This should be the same as the training specification file.-m, --model: Path to the model file to use for evaluation. Model can be either .tlt model file or TensorRT engine.-k, --key: Provide the key to load the model (not needed if model is a TensorRT engine).
Optional Arguments
-h, --help: show this help message and exit.--gpu_index: The GPU index used to run the evaluation. We can specify the GPU index used to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.--log_file: Path to the log file. Defaults to stdout.
The inference tool for YOLOv3 networks may be used to visualize bboxes or generate frame-by-frame KITTI-format labels on a single image or a directory of images. An example of the command for this tool is shown here:
tao yolo_v3 inference [-h] -i <input directory>
-o <output annotated image directory>
-e <experiment spec file>
-m <model file>
-k <key>
[-l <output label directory>]
[-t <visualization threshold>]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-m, --model: Path to the trained model (TAO model) or TensorRT engine.-i, --in_image_dir: The directory of input images for inference.-o, --out_image_dir: The directory path to output annotated images.-k, --key: Key to load model (not needed if model is a TensorRT engine).-e, --config_path: Path to an experiment spec file for training.
Optional Arguments
-t, --draw_conf_thres: The threshold for drawing a bbox. The default value is 0.3.-h, --help: Show this help message and exit.-l, --out_label_dir: The directory to output KITTI labels.--gpu_index: The GPU index used to run inference. You can specify the index of the GPU to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.--log_file: The path to the log file. The default path is “stdout”.
Pruning removes parameters from the model to reduce the model size without compromising the
integrity of the model itself using the tao yolo_v3 prune command.
The tao yolo_v3 prune command includes these parameters:
tao yolo_v3 prune [-h] -m <pretrained_model>
-o <output_file>
-k <key>
[-n <normalizer>]
[-eq <equalization_criterion>]
[-pg <pruning_granularity>]
[-pth <pruning threshold>]
[-nf <min_num_filters>]
[-el [<excluded_list>]
Required Arguments
-m, --model: Path to pretrained YOLOv3 model.-o, --output_file: Path to output checkpoints.-k, --key: Key to load a .tlt model.
Optional Arguments
-h, --help: Show this help message and exit.-n, –normalizer:maxto normalize by dividing each norm by the maximum norm within a layer;L2to normalize by dividing by the L2 norm of the vector comprising all kernel norms. (default: max)-eq, --equalization_criterion: Criteria to equalize the stats of inputs to an element wise op layer, or depth-wise convolutional layer. This parameter is useful for resnets and mobilenets. Options arearithmetic_mean,:code:geometric_mean,union, andintersection. (default:union)-pg, -pruning_granularity: Number of filters to remove at a time (default:8)-pth: Threshold to compare normalized norm against (default:0.1)-nf, --min_num_filters: Minimum number of filters to keep per layer (default:16).-el, --excluded_layers: List of excluded_layers. Examples: -i item1 item2 (default: []).
After pruning, the model needs to be retrained. See Re-training the Pruned Model for more details.
Using the Prune Command
Here’s an example of using the tao yolo_v3 prune command:
tao yolo_v3 prune -m /workspace/output/weights/resnet_003.tlt \
-o /workspace/output/weights/resnet_003_pruned.tlt \
-eq union \
-pth 0.7 -k $KEY
Once the model has been pruned, there might be a slight decrease in accuracy because some previously
useful weights may be removed. To regain accuracy,
NVIDIA recommends that you retrain this pruned model over the same dataset. To do this, use
the tao yolo_v3 train command as documented in Training the model,
with an updated spec file that points to the newly pruned model as the pruned_model_path.
We recommend turning off the regularizer in the training_config for detectnet to recover
the accuracy when retraining a pruned model. To do this, set the regularizer type
to NO_REG as mentioned Training config. All the other parameters may be retained
in the spec file from the previous training.
Exporting the model decouples the training process from inference and allows conversion to TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware configuration and should be generated for each unique inference environment. The exported model may be used universally across training and deployment hardware.
The exported model format is referred to as .etlt. Like the .tlt model format,
.etlt is an encrypted model format, and it uses the same key as the .tlt model
that it is exported from. This key is required when deploying this model.
INT8 Mode Overview
TensorRT engines can be generated in INT8 mode to improve performance but require a calibration
cache at engine creation-time. The calibration cache is generated using a calibration tensor
file, if tao yolo_v3 export is run with the --data_type flag set to int8.
Pre-generating the calibration information and caching it removes the need for calibrating the
model on the inference machine. Moving the calibration cache is usually much more convenient than
moving the calibration tensorfile, since it is a much smaller file and can be moved with the
exported model. Using the calibration cache also speeds up engine creation as building the
cache can take several minutes to generate depending on the size of the Tensorfile and the model
itself.
The export tool can generate the INT8 calibration cache by ingesting training data using one of these options:
Option 1: Using the training data loader to load the training images for INT8 calibration. This option is now the recommended approach to support multiple image directories by leveraging the training dataset loader. This also ensures two important aspects of data during calibration:
Data pre-processing in the INT8 calibration step is the same as in the training process.
The data batches are sampled randomly across the entire training dataset, thereby improving the accuracy of the INT8 model.
Option 2: Pointing the tool to a directory of images that you want to use to calibrate the model. For this option, make sure to create a sub-sampled directory of random images that best represent your training dataset.
FP16/FP32 Model
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32-based inference, the export step is much simpler. All you need to do is provide
a .tlt model from the training/retraining step to be converted into .etlt format.
Exporting the Model
Here’s an example of the command line arguments of the tao yolo_v3 export command:
tao yolo_v3 export [-h]
-m <path to the .tlt model file generated by tao train>
-k <key>
[-o <path to output file>]
[--cal_data_file <path to tensor file>]
[--cal_image_dir <path to the directory images to calibrate the model]
[--cal_cache_file <path to output calibration file>]
[--data_type <Data type for the TensorRT backend during export>]
[--batches <Number of batches to calibrate over>]
[--max_batch_size <maximum trt batch size>]
[--max_workspace_size <maximum workspace size]
[--batch_size <batch size to TensorRT engine>]
[--experiment_spec <path to experiment spec file>]
[--engine_file <path to the TensorRT engine file>]
[--gen_ds_config]
[--verbose]
[--strict_type_constraints]
[--force_ptq]
[--gpu_index <gpu_index>]
[--log_file <log_file_path>]
Required Arguments
-m, --model: The path to the.tltmodel file to be exported.-k, --key: The key used to save the.tltmodel file.-e, --experiment_spec: The path to the spec file.
Optional Arguments
-h, --help: Show this help message and exit.-o, --output_file: The path to save the exported model to. The default path is./<input_file>.etlt.--data_type: The desired engine data type. The options arefp32,fp16,int8. The default value isfp32. A calibration cache will be generated in INT8 mode. If using INT8, the following INT8 arguments are required.--gen_ds_config: A Boolean flag indicating whether to generate the template DeepStream related configuration (“nvinfer_config.txt”) as well as a label file (“labels.txt”) in the same directory as theoutput_file. Note that the config file is NOT a complete configuration file and requires the user to update the sample config files in DeepStream with the parameters generated.-s, --strict_type_constraints: A Boolean flag indicating whether to apply the TensorRT strict type constraints when building the TensorRT engine.--gpu_index: The index of (discrete) GPUs used for exporting the model. You can specify the index of the GPU to run export if the machine has multiple GPUs installed. Note that export can only run on a single GPU.--log_file: The path to the log file. The default path is “stdout”.
INT8 Export Mode Required Arguments
--cal_data_file: tensorfile generated for calibrating the engine. This can also be an output file if used with--cal_image_dir.--cal_image_dir: Directory of images to use for calibration.
--cal_image_dir parameter for images and applies the necessary preprocessing
to generate a tensorfile at the path mentioned in the --cal_data_file
parameter, which is in turn used for calibration. The number of batches in the
tensorfile generated is obtained from the value set to the --batches parameter,
and the batch_size is obtained from the value set to the --batch_size
parameter. Be sure that the directory mentioned in --cal_image_dir has at least
batch_size * batches number of images in it. The valid image extensions are .jpg,
.jpeg, and .png. In this case, the input_dimensions of the calibration tensors
are derived from the input layer of the .tlt model.
INT8 Export Optional Arguments
--cal_cache_file: The path to save the calibration cache file to. The default value is./cal.bin.--batches: Number of batches to use for calibration and inference testing.The default value is 10.--batch_size: Batch size to use for calibration. The default value is 8.--max_batch_size: Maximum batch size of TensorRT engine. The default value is 16.--max_workspace_size: Maximum workspace size of TensorRT engine. The default value is: 1073741824 = 1<<30).--engine_file: Path to the serialized TensorRT engine file. Note that this file is hardware specific, and cannot be generalized across GPUs. Useful to quickly test your model accuracy using TensorRT on the host. As TensorRT engine file is hardware specific, you cannot use this engine file for deployment unless the deployment GPU is identical to training GPU.--force_ptq: A boolean flag to force post training quantization on the exported etlt model.
When exporting a model trained with QAT enabled, the tensor scale factors to calibrate
the activations are peeled out of the model and serialized to a TensorRT readable cache file
defined by the cal_cache_file argument. However, note that the current version of
QAT doesn’t natively support DLA int8 deployment in the Jetson. In order to deploy
this model on a Jetson with DLA int8, use the --force_ptq flag to use
TensorRT post training quantization to generate the calibration cache file.
Sample Usage
Here’s a sample command to export a YOLOv3 model in INT8 mode:
tao yolo_v3 export -m /workspace/yolov3_resnet18_epoch_100.tlt \
-o /workspace/yolov3_resnet18_epoch_100_int8.etlt \
-e /workspace/yolov3_retrain_resnet18_kitti.txt \
-k $KEY \
--cal_image_dir /workspace/data/training/image_2 \
--data_type int8 \
--batch_size 8 \
--batches 10 \
--cal_cache_file /export/cal.bin \
--cal_data_file /export/cal.tensorfile
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. This section will describe how to deploy your trained model to DeepStream SDK.
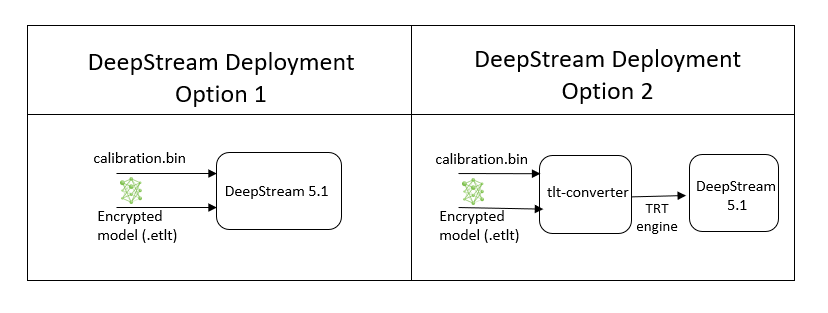
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the
.etltmodel directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device specific optimized TensorRT engine using
tao-converter. The generated TensorRT engine file can also be ingested by DeepStream.
Machine-specific optimizations are done as part of the engine creation process, so a distinct engine should be generated for each environment and hardware configuration. If the TensorRT or CUDA libraries of the inference environment are updated (including minor version updates), or if a new model is generated, new engines need to be generated. Running an engine that was generated with a different version of TensorRT and CUDA is not supported and will cause unknown behavior that affects inference speed, accuracy, and stability, or it may fail to run altogether.
Option 1 is very straightforward. The .etlt file and calibration cache are directly
used by DeepStream. DeepStream will automatically generate the TensorRT engine file and then run
inference. TensorRT engine generation can take some time depending on size of the model
and type of hardware. Engine generation can be done ahead of time with Option 2.
With option 2, the tao-converter is used to convert the .etlt file to TensorRT; this
file is then provided directly to DeepStream.
See the Exporting the Model section for more details on how to export a TAO model.
TensorRT Open Source Software (OSS)
For YOLOv3, we need the batchTilePlugin and batchedNMSPlugin plugins from the
TensorRT OSS build.
If the deployment platform is x86 with an NVIDIA GPU, follow the TensorRT OSS on x86 instructions. On the other hand, if your deployment is on the NVIDIA Jetson platform, follow the TensorRT OSS on Jetson (ARM64) instructions.
TensorRT OSS on x86
Building TensorRT OSS on x86:
Install Cmake (>=3.13).
NoteTensorRT OSS requires cmake version v3.13 or greater, so install cmake 3.13 if your cmake version is lower than 3.13c.
sudo apt remove --purge --auto-remove cmake wget https://github.com/Kitware/CMake/releases/download/v3.13.5/cmake-3.13.5.tar.gz tar xvf cmake-3.13.5.tar.gz cd cmake-3.13.5/ ./configure make -j$(nproc) sudo make install sudo ln -s /usr/local/bin/cmake /usr/bin/cmake
Get your GPU architecture. The
GPU_ARCHSvalue can be retrieved by thedeviceQueryCUDA sample:cd /usr/local/cuda/samples/1_Utilities/deviceQuery sudo make ./deviceQuery
If the
/usr/local/cuda/samplesdoesn’t exist in your system, you could downloaddeviceQuery.cppfrom this repo. Compile and rundeviceQuery:nvcc deviceQuery.cpp -o deviceQuery ./deviceQuery
This command will output something like this, which indicates that the
GPU_ARCHSis75based on the CUDA Capability major/minor version.Detected 2 CUDA Capable device(s) Device 0: "Tesla T4" CUDA Driver Version / Runtime Version 10.2 / 10.2 CUDA Capability Major/Minor version number: 7.5
Build TensorRT OSS:
git clone -b release/7.0 https://github.com/nvidia/TensorRT cd TensorRT/ git submodule update --init --recursive export TRT_SOURCE=`pwd` cd $TRT_SOURCE mkdir -p build && cd build
NoteMake sure your
GPU_ARCHSfrom step 2 is in TensorRT OSSCMakeLists.txt. IfGPU_ARCHSis not in TensorRT OSSCMakeLists.txt, add-DGPU_ARCHS=<VER>as below, where<VER>represents theGPU_ARCHSfrom step 2./usr/local/bin/cmake .. -DGPU_ARCHS=xy -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=`pwd`/out make nvinfer_plugin -j$(nproc)
After building ends successfully,
libnvinfer_plugin.so*will be generated under\`pwd\`/out/.Replace the original
libnvinfer_plugin.so*:sudo mv /usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so.7.x.y ${HOME}/libnvinfer_plugin.so.7.x.y.bak // backup original libnvinfer_plugin.so.x.y sudo cp $TRT_SOURCE/`pwd`/out/libnvinfer_plugin.so.7.m.n /usr/lib/x86_64-linux-gnu/libnvinfer_plugin.so.7.x.y sudo ldconfig
TensorRT OSS on Jetson (ARM64)
Install Cmake (>=3.13)
NoteTensorRT OSS requires cmake version v3.13 or greater, while the default version of cmake on Jetson/Ubuntu 18.04 is cmake 3.10.2.
Upgrade TensorRT OSS as follows:
sudo apt remove --purge --auto-remove cmake wget https://github.com/Kitware/CMake/releases/download/v3.13.5/cmake-3.13.5.tar.gz tar xvf cmake-3.13.5.tar.gz cd cmake-3.13.5/ ./configure make -j$(nproc) sudo make install sudo ln -s /usr/local/bin/cmake /usr/bin/cmake
Get the GPU architecture for your platform. The
GPU_ARCHSfor different Jetson platforms are given in the following table:Jetson Platform
GPU_ARCHS
Nano/Tx1
53
Tx2
62
AGX Xavier/Xavier NX
72
Build TensorRT OSS:
git clone -b release/7.0 https://github.com/nvidia/TensorRT cd TensorRT/ git submodule update --init --recursive export TRT_SOURCE=`pwd` cd $TRT_SOURCE mkdir -p build && cd build
NoteThe
-DGPU_ARCHS=72below is for Jetson Xavier or NX; for other Jetson platforms, change72to theGPU_ARCHSnumber shown in step 2./usr/local/bin/cmake .. -DGPU_ARCHS=72 -DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/ -DCMAKE_C_COMPILER=/usr/bin/gcc -DTRT_BIN_DIR=`pwd`/out make nvinfer_plugin -j$(nproc)
After building completes successfully,
libnvinfer_plugin.so*will be generated under‘pwd’/out/.Replace
"libnvinfer_plugin.so*"with the newly generated version:sudo mv /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.7.x.y ${HOME}/libnvinfer_plugin.so.7.x.y.bak // backup original libnvinfer_plugin.so.x.y sudo cp `pwd`/out/libnvinfer_plugin.so.7.m.n /usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.7.x.y sudo ldconfig
Generating an Engine Using tao-converter
The tao-converter tool is provided with the TAO Toolkit
to facilitate the deployment of TAO trained models on TensorRT and/or Deepstream.
This section elaborates on how to generate a TensorRT engine using tao-converter.
For deployment platforms with an x86-based CPU and discrete GPUs, the tao-converter
is distributed within the TAO docker. Therefore, we suggest using the docker to generate
the engine. However, this requires that the user adhere to the same minor version of
TensorRT as distributed with the docker. The TAO docker includes TensorRT version 7.2.
Instructions for x86
Copy
/opt/nvidia/tools/tao-converterto the target machine.Install TensorRT 7.0+ for the respective target machine.
For YOLOv3, you need to build TensorRT Open source software on the machine. Instructions to build TensorRT OSS on x86 can be found in TensorRT OSS on x86 section above or in this GitHub repo.
Run
tao-converterusing the sample command below and generate the engine.
Instructions for Jetson
For the Jetson platform, the tao-converter is available to download in the dev zone.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip
tao-converter-trt7.1.zipon the target machine.Install the open ssl package using this command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT 7.1 comes pre-installed with Jetpack. If you are using an older version of JetPack, upgrade to JetPack 4.4.
For YOLOv3, instructions to build TensorRT OSS on Jetson can be found in the TensorRT OSS on Jetson (ARM64) section above or in this GitHub repo.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model.
Using the tao-converter
tao-converter [-h] -k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
input_file
Required Arguments
input_file: The path to the.etltmodel exported usingtao yolo_v3 export.-k: The key used to encode the.tltmodel when doing the training.-d: A comma-separated list of input dimensions that should match the dimensions used fortao yolo_v3 export.-o: A comma-separated list of output blob names that should match the output configuration. used fortao yolo_v3 export. For YOLOv3, set this argument toBatchedNMS.-p: Optimization profiles for.etltmodels with dynamic shape. Use a comma-separated list of optimization profile shapes in the format<input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format:<n>x<c>x<h>x<w>. The input name for YOLOv3 isInput
Optional Arguments
-e: The path to save the engine to. The default path is./saved.engine.-t: The desired engine data type. The options arefp32,fp16, orint8. Selecting INT8 mode will generate a calibration cache.-w: The maximum workspace size for the TensorRT engine. The default value is1073741824(1<<30).-i: The input-dimension ordering. All other TAO commands use NCHW. The options arenchw,nhwc, andnc. The default value isnchw, so you can omit this argument for YOLOv3.-s: A Boolean value specifying wheter to apply TensorRT strict-type constraints when building the TensorRT engine.-u: Only needed if use DLA core. Specifying DLA core index when building the TensorRT engine on Jetson devices.
INT8 Mode Arguments
-c: The path to calibration cache file (only used in INT8 mode). The default value is./cal.bin.-b: The batch size used during the export step for INT8 calibration cache generation (default:8).-m: The maximum batch size for the TensorRT engine. The default value is16. If out-of-memory issues occur, decrease the batch size accordingly. This parameter is not required for.etltmodels generated with dynamic shape, which is only possible for new models introduced in TAO Toolkit 3.21.08.
Sample Output Log
Here is a sample log for exporting a YOLOv3 model.
tao-converter -k $KEY \
-d 3,384,1248 \
-o BatchedNMS \
-e /export/trt.fp16.engine \
-t fp16 \
-i nchw \
-m 8 \
/ws/yolov3_resnet18_epoch_100.etlt
Integrating the model to DeepStream
To integrate a model trained by TAO with DeepStream, you shoud generate a device-specific optimized
TensorRT engine using tao-converter. The generated TensorRT engine file can then be ingested
by DeepStream (Currently, YOLOv3 etlt files are not supported by DeepStream).
For YOLOv3, you will need to build the TensorRT open source plugins and custom bounding-box parser. The instructions to build TensorRT open source plugins are provided in the TensorRT OSS section above. The instructions to build custom bounding-box parser is provided below in prerequisite section and the required code can be found in this GitHub repo.
To integrate the models with DeepStream, you will need the following:
The DeepStream SDK (download from the DeepStream SDK Download Page). The installation instructions for DeepStream are provided in the DeepStream Development Guide.
An exported
.etltmodel file and optional calibration cache for INT8 precision.A
labels.txtfile containing the labels for classes in the order in which the networks produce outputs.A sample
config_infer_*.txtfile to configure the nvinfer element in DeepStream. The nvinfer element handles everything related to TensorRT optimization and engine creation in DeepStream.
DeepStream SDK ships with an end-to-end reference application which is fully configurable. Users
can configure input sources, the inference model, and output sinks. The app requires a primary
object-detection model, followed by an optional secondary classification model. The reference
application is installed as deepstream-app. The graphic below shows the architecture of the
reference application:
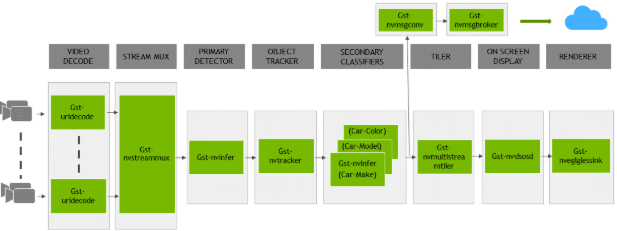
Typically, two or more configuration files are used with this app. In the install
directory, the config files are located in samples/configs/deepstream-app or
sample/configs/tlt_pretrained_models. The main config file configures all the high-level
parameters in the pipeline above. This will set the input source and resolution, number of
inferences, tracker, and output sinks. The other supporting config files are for each individual
inference engine. The inference-specific configuration files are used to specify the models,
inference resolution, batch size, number of classes, and other customizations. The main
configuration file will call all the supporting configuration files.
Here are some configuration files in samples/configs/deepstream-app for reference:
source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt: The main configuration file.config_infer_primary.txt: The supporting configuration file for the primary detector in the pipeline above.config_infer_secondary_*.txt: The supporting configuration file for the secondary classifier in the pipeline above.
The deepstream-app will only work with the main configuration file. This file will most
likely remain the same for all models and can be used directly from the DeepStream SDK with
little to no change. You will only have to modify or create config_infer_primary.txt and
config_infer_secondary_*.txt.
Integrating a YOLOv3 Model
To run a YOLOv3 model in DeepStream, you need a label file and a DeepStream configuration file. In addition, you need to compile the TensorRT 7+ Open source software and YOLOv3 bounding box parser for DeepStream.
A DeepStream sample with documentation on how to run inference using the trained YOLOv3 models from TAO Toolkit is provided on GitHub repo.
Prerequisite for YOLOv3 Model
YOLOv3 requires the batchTilePlugin, resizeNearestPlugin and batchedNMSPlugin. These plugins are available in the TensorRT open source repo, but not in TensorRT 7.0. Detailed instructions to build TensorRT OSS can be found in the TensorRT Open Source Software (OSS) section.
YOLOv3 requires custom bounding box parsers that are not built in to the DeepStream SDK. The source code to build custom bounding box parsers for YOLOv3 is available in GitHub repo. The following instructions can be used to build the bounding-box parser:
Install git-lfs (git >= 1.8.2)
curl -s https://packagecloud.io/install/repositories/github/git-lfs/ script.deb.sh | sudo bash sudo apt-get install git-lfs git lfs install
Download the source code with SSH or HTTPS:
git clone -b release/tlt3.0 https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps
Build the parser:
// or Path for DS installation export CUDA_VER=10.2 // CUDA version, e.g. 10.2 make
This generates libnvds_infercustomparser_tlt.so in the directory post_processor.
Label File
The label file is a text file containing the names of the classes that the YOLOv3 model is trained to detect. The order in which the classes are listed here must match the order in which the model predicts the output. During the training, TAO Toolkit YOLOv3 will specify all class names in lower case and sort them in alphabetical order. For example, if the dataset_config is:
dataset_config {
data_sources: {
label_directory_path: "/workspace/tao-experiments/data/training/label_2"
image_directory_path: "/workspace/tao-experiments/data/training/image_2"
}
target_class_mapping {
key: "car"
value: "car"
}
target_class_mapping {
key: "person"
value: "person"
}
target_class_mapping {
key: "bicycle"
value: "bicycle"
}
validation_data_sources: {
label_directory_path: "/workspace/tao-experiments/data/val/label"
image_directory_path: "/workspace/tao-experiments/data/val/image"
}
}
Then the corresponding yolov3_labels.txt file would be:
bicycle
car
person
DeepStream Configuration File
The detection model is typically used as a primary inference engine. It can also be used as a
secondary inference engine. To run this model in the sample deepstream-app, you must modify
the existing config_infer_primary.txt file to point to this model.
Integrate the TensorRT engine file with the DeepStream app
Generate the TensorRT engine using tao-converter. Detailed instructions are provided in the Generating an engine using tao-converter section above.
Once the engine file is generated successfully, modify the following parameters to use this engine with DeepStream:
model-engine-file=<PATH to generated TensorRT engine>
All other parameters are common between the two approaches. To use the custom bounding box parser
instead of the default parsers in DeepStream, modify the following parameters in the [property]
section of the primary infer configuration file:
parse-bbox-func-name=NvDsInferParseCustomBatchedNMSTLT
custom-lib-path=<PATH to libnvds_infercustomparser_tlt.so>
Add the label file generated above using the following:
labelfile-path=<YOLOv3 labels>
For all the options, see the configuration file below. To learn more about all the parameters, refer to the DeepStream Development Guide.
Here’s a sample config file, pgie_yolov3_config.txt:
[property]
gpu-id=0
net-scale-factor=1.0
offsets=103.939;116.779;123.68
model-color-format=1
labelfile-path=<Path to yolov3_labels.txt>
model-engine-file=<PATH to generated TensorRT engine>
tlt-model-key=<Key to decrypt model>
infer-dims=3;384;1248
maintain-aspect-ratio=1
uff-input-order=0
uff-input-blob-name=Input
batch-size=1
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=0
num-detected-classes=3
interval=0
gie-unique-id=1
is-classifier=0
#network-type=0
#no cluster
cluster-mode=3
output-blob-names=BatchedNMS
parse-bbox-func-name=NvDsInferParseCustomBatchedNMSTLT
custom-lib-path=<Path to libnvds_infercustomparser_tlt.so>
[class-attrs-all]
pre-cluster-threshold=0.3
roi-top-offset=0
roi-bottom-offset=0
detected-min-w=0
detected-min-h=0
detected-max-w=0
detected-max-h=0