Integrating TAO Models into DeepStream
The deep learning and computer vision models that you’ve trained can be deployed on edge devices, such as a Jetson Xavier or Jetson Nano, a discrete GPU, or in the cloud with NVIDIA GPUs. TAO Toolkit has been designed to integrate with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with DeepStream SDK.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. This section will describe how to deploy your trained model to DeepStream SDK.
To deploy a model trained by TAO Toolkit to DeepStream we have two options:
Option 1: Integrate the
.etltmodel directly in the DeepStream app. The model file is generated by export.Option 2: Generate a device specific optimized TensorRT engine using
tao-converter. The generated TensorRT engine file can also be ingested by DeepStream.
Machine-specific optimizations are done as part of the engine creation process, so a distinct engine should be generated for each environment and hardware configuration. If the TensorRT or CUDA libraries of the inference environment are updated (including minor version updates), or if a new model is generated, new engines need to be generated. Running an engine that was generated with a different version of TensorRT and CUDA is not supported and will cause unknown behavior that affects inference speed, accuracy, and stability, or it may fail to run altogether.
Option 1 is very straightforward. The .etlt file and calibration cache are directly
used by DeepStream. DeepStream will automatically generate the TensorRT engine file and then run
inference. TensorRT engine generation can take some time depending on size of the model
and type of hardware. Engine generation can be done ahead of time with Option 2.
With option 2, the tao-converter is used to convert the .etlt file to TensorRT; this
file is then provided directly to DeepStream.
See the Exporting the Model section for more details on how to export a TAO model.
The following TAO models can be integrated into DeepStream 5.1:
Image Classification
Object Detection
Yolo V3
Yolo V4
DSSD
SSD
RetinaNet
DetectNet_v2
FasterRCNN
Instance Segmentation
Mask-RCNN
Semantic Segmentation
UNet
Character Recognition
MultiTask Classification
Of these models, the following do not support direct integration of the .etlt files
into DeepStream:
YOLOv3
YOLOv4
UNet
Character Recognition
You can deploy most trained models with DeepStream SDK. Follow the instructions below to integrate TAO models with Deepstream.
We recommend running TAO models with DeepStream 5.1.
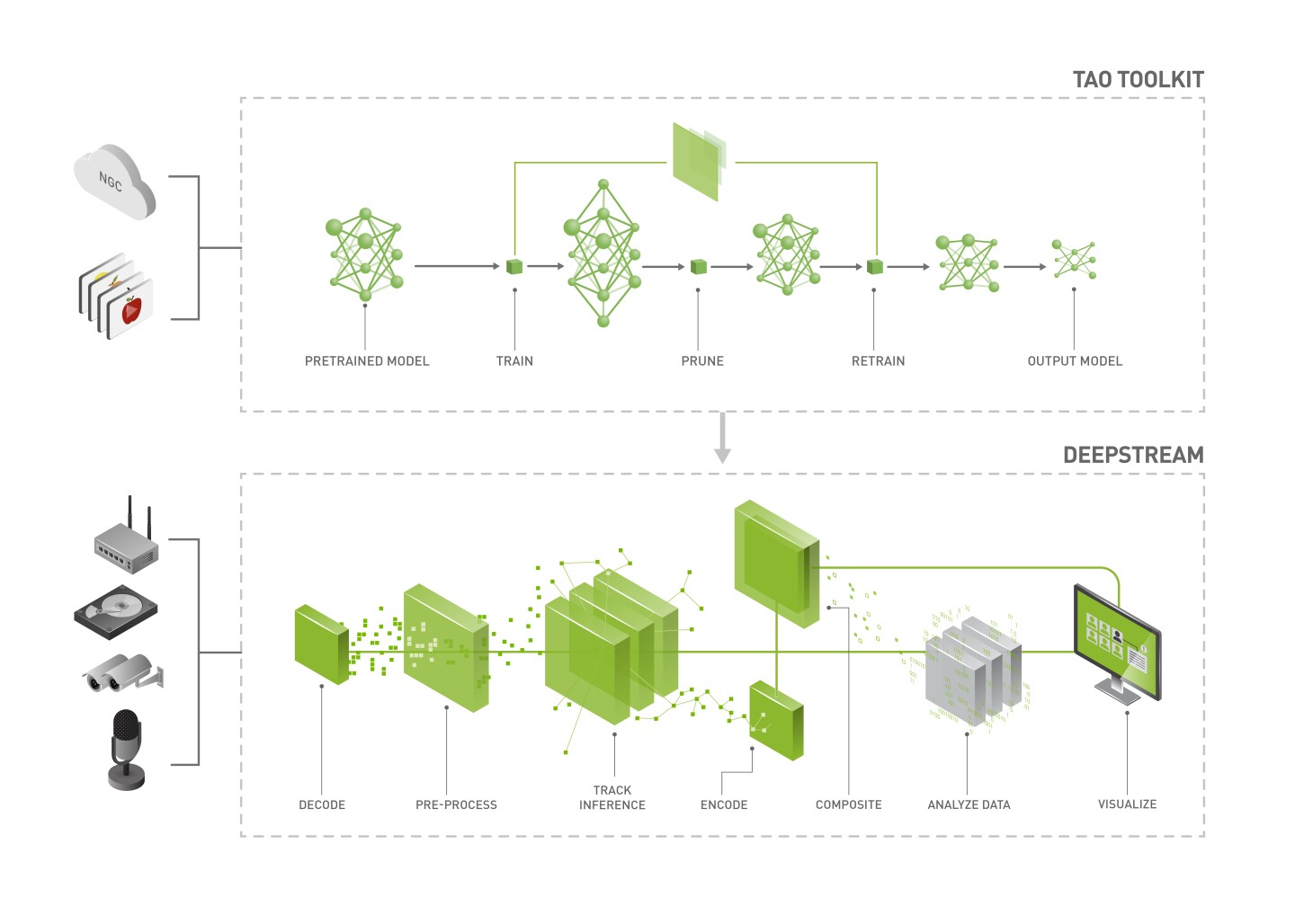
The following models have been integrated into DeepStream 5.1 with other models on the roadmap for future releases.
Model |
Model output format |
Prunable |
INT8 |
Compatible with DS5.0/5.0.1 |
Compatible with DS5.1 |
TRT-OSS required |
|---|---|---|---|---|---|---|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
Encrypted UFF |
Yes |
Yes |
No |
Yes |
No |
|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Encrypted ONNX |
Yes |
Yes |
Yes |
Yes (with TRT 7.1) |
Yes |
|
Encrypted ONNX |
Yes |
Yes |
Yes |
Yes (with TRT 7.1) |
Yes |
|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Encrypted UFF |
No |
Yes |
Yes |
Yes |
Yes |
|
Encrypted ONNX |
No |
Yes |
No |
Yes |
No |
|
Encrypted ONNX |
No |
Yes |
No |
Yes |
No |
Model Name |
Model arch |
Model output format |
Prunable |
INT8 |
Compatible with DS5.0/5.0.1 |
Compatible with DS5.1 |
TRT-OSS required |
|---|---|---|---|---|---|---|---|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
Image Classification |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
Image Classification |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
DetectNet_v2 |
Encrypted UFF |
Yes |
Yes |
Yes |
Yes |
No |
|
Character Recognition |
Encrypted ONNX |
No |
Yes |
No |
Yes |
No |
|
MaskRCNN |
Encrypted UFF |
No |
Yes |
Yes |
Yes |
Yes |
|
UNET |
Encrypted ONNX |
No |
Yes |
No |
Yes |
Yes |
Install Jetpack 4.5.1 for Jetson devices.
Note: For Jetson devices, use the following commands to manually increase the Jetson Power mode and maximize performance further by using the Jetson Clocks mode:
sudo nvpmodel -m 0 sudo /usr/bin/jetson_clocks
Install Deepstream.
The following files are required to run each TAO model with Deepstream:
ds_tlt.c: The application main filenvdsinfer_custombboxparser_tlt: A custom parser function on infernece end nodesModels: TAO models from NGC
Model configuration files: The Deepstream Inference configuration file
We have provided several reference applications on GitHub.
Reference app for YOLOv3/YOLOv4, FasterRCNN, SSD/DSSD, RetinaNet, MaskRCNN, UNet - DeepStream TAO reference app
Reference app for License plate detection and Recognition - DeepStream LPR app
Pre-trained models - License Plate Detection (LPDNet) and Recognition (LPRNet)
The following steps outline how to run the License Plate Detection and Recognition application: DeepStream LPR app
Download the Repository
git clone https://github.com/NVIDIA-AI-IOT/deepstream_lpr_app.git
Download the Models
cd deepstream_lpr_app
mkdir -p ./models/tlt_pretrained_models/trafficcamnet
cd ./models/tlt_pretrained_models/trafficcamnet
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/trafficcamnet/versions/pruned_v1.0/files/trafficnet_int8.txt
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/trafficcamnet/versions/pruned_v1.0/files/resnet18_trafficcamnet_pruned.etlt
cd -
mkdir -p ./models/LP/LPD
cd ./models/LP/LPD
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/lpdnet/versions/pruned_v1.0/files/usa_pruned.etlt
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/lpdnet/versions/pruned_v1.0/files/usa_lpd_cal.bin
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/lpdnet/versions/pruned_v1.0/files/usa_lpd_label.txt
cd -
mkdir -p ./models/LP/LPR
cd ./models/LP/LPR
wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/lprnet/versions/deployable_v1.0/files/us_lprnet_baseline18_deployable.etlt
touch labels_us.txt
cd -
Convert the Models to TRT Engine
See the TAO Converter section.
./tao-converter -k nvidia_tlt -p image_input,1x3x48x96,4x3x48x96,16x3x48x96 models/LP/LPR/us_lprnet_baseline18_deployable.etlt -t fp16 -e models/LP/LPR/lpr_us_onnx_b16.engine
Build and Run
make
cd deepstream-lpr-app
For US car plate recognition:
cp dict_us.txt dict.txt
Start to run the application:
./deepstream-lpr-app <1:US car plate model|2: Chinese car plate model> <1: output as h264 file| 2:fakesink 3:display output>
[0:ROI disable|1:ROI enable] [input mp4 file path and name] [input mp4 file path and name] ... [input mp4 file path and name] [output 264 file path and name]
For detailed instructions about running this application, refer to this GitHub repository.
Pre-trained models - PeopleNet, TrafficCamNet, DashCamNet, FaceDetectIR, Vehiclemakenet, Vehicletypenet, PeopleSegNet, PeopleSemSegNet
PeopleNet
Follow these instructions to run the PeopleNet model in DeepStream:
Download the model:
mkdir -p $HOME/peoplenet && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/peoplenet/versions/pruned_v2.1/files/resnet34_peoplenet_pruned.etlt \ -O $HOME/peoplenet/resnet34_peoplenet_pruned.etlt
Run the application:
xhost + docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:/opt/nvidia/deepstream/deepstream-5.1/samples/models/tlt_pretrained_models \ -w /opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models nvcr.io/nvidia/deepstream:5.1-21.02-samples \ deepstream-app -c deepstream_app_source1_peoplenet.txt
TrafficCamNet
Follow these instructions to run the TrafficCamNet model in DeepStream:
Download the model:
mkdir -p $HOME/trafficcamnet && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/trafficcamnet/versions/pruned_v1.0/files/resnet18_trafficcamnet_pruned.etlt \ -O $HOME/trafficcamnet/resnet18_trafficcamnet_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/trafficcamnet/versions/pruned_v1.0/files/trafficnet_int8.txt \ -O $HOME/trafficcamnet/trafficnet_int8.txt
Run the application:
xhost + docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:/opt/nvidia/deepstream/deepstream-5.1/samples/models/tlt_pretrained_models \ -w /opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models nvcr.io/nvidia/deepstream:5.1-21.02-samples \ deepstream-app -c deepstream_app_source1_trafficcamnet.txt
DashCamNet + Vehiclemakenet + Vehicletypenet
Follow these instructions to run the DashCamNet model as primary detector and Vehiclemakenet and Vehicletypenet as secondary classifier in DeepStream:
Download the model:
mkdir -p $HOME/dashcamnet && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/dashcamnet/versions/pruned_v1.0/files/resnet18_dashcamnet_pruned.etlt \ -O $HOME/dashcamnet/resnet18_dashcamnet_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/dashcamnet/versions/pruned_v1.0/files/dashcamnet_int8.txt \ -O $HOME/dashcamnet/dashcamnet_int8.txt mkdir -p $HOME/vehiclemakenet && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/vehiclemakenet/versions/pruned_v1.0/files/resnet18_vehiclemakenet_pruned.etlt \ -O $HOME/vehiclemakenet/resnet18_vehiclemakenet_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/vehiclemakenet/versions/pruned_v1.0/files/vehiclemakenet_int8.txt \ -O $HOME/vehiclemakenet/vehiclemakenet_int8.txt mkdir -p $HOME/vehicletypenet && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/vehicletypenet/versions/pruned_v1.0/files/resnet18_vehicletypenet_pruned.etlt \ -O $HOME/vehicletypenet/resnet18_vehicletypenet_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/vehicletypenet/versions/pruned_v1.0/files/vehicletypenet_int8.txt \ -O $HOME/vehicletypenet/vehicletypenet_int8.txt
Run the application:
xhost + docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:/opt/nvidia/deepstream/deepstream-5.1/samples/models/tlt_pretrained_models \ -w /opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models nvcr.io/nvidia/deepstream:5.1-21.02-samples \ deepstream-app -c deepstream_app_source1_dashcamnet_vehiclemakenet_vehicletypenet.txt
FaceDetectIR
Follow these instructions to run the FaceDetectIR model in DeepStream:
Download the model:
mkdir -p $HOME/facedetectir && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/facedetectir/versions/pruned_v1.0/files/resnet18_facedetectir_pruned.etlt \ -O $HOME/facedetectir/resnet18_facedetectir_pruned.etlt && \ wget https://api.ngc.nvidia.com/v2/models/nvidia/tao/facedetectir/versions/pruned_v1.0/files/facedetectir_int8.txt \ -O $HOME/facedetectir/facedetectir_int8.txt
Run the application:
xhost + docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:/opt/nvidia/deepstream/deepstream-5.1/samples/models/tlt_pretrained_models \ -w /opt/nvidia/deepstream/deepstream-5.1/samples/configs/tlt_pretrained_models nvcr.io/nvidia/deepstream:5.1-21.02-samples \ deepstream-app -c deepstream_app_source1_facedetectir.txt
PeopleSegNet
Follow these instructions to run the PeopleSegNet model in DeepStream:
Download the Repository:
git clone https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps.git
Download the model:
ngc registry model download-version "nvidia/tao/peoplesegnet:deployable_v2.0"
or
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/peoplesegnet/versions/deployable_v2.0/zip \ -O peoplesegnet_deployable_v2.0.zip
Build TRT OSS Plugin:
TRT-OSS instructions are provided in https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps/tree/master#1-build-trt-oss-plugin
Build the application:
export CUDA_VER=xy.z // xy.z is CUDA version, e.g. 10.2 make
Run the application:
SHOW_MASK=1 ./apps/ds-tlt -c configs/peopleSegNet_tlt/pgie_peopleSegNetv2_tlt_config.txt -i \ /opt/nvidia/deepstream/deepstream-5.1/samples/streams/sample_720p.h264 -d
PeopleSemSegNet
Follow these instructions to run the PeopleSemSegNet model in DeepStream:
Download tao-converter and the model:
mkdir $HOME/deepstream cd $HOME/deepstream wget https://developer.nvidia.com/cuda111-cudnn80-trt72 unzip cuda111-cudnn80-trt72 cp cuda11.1_cudnn8.0_trt7.2/tao-converter ./ chmod 0777 tao-converter ngc registry model download-version "nvidia/tao/peoplesemsegnet:deployable_v1.0"
Run the application:
xhost + docker run --gpus all -it --rm -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=$DISPLAY -v $HOME:$HOME -w $HOME/deepstream \ nvcr.io/nvidia/deepstream:5.1-21.02-devel ./tao-converter -k tlt_encode -p input_1,1x3x544x960,1x3x544x960,1x3x544x960 -t fp16 -e \ peoplesemsegnet_vdeployable_v1.0/unet_resnet18.etlt_b1_gpu0_fp16.engine peoplesemsegnet_vdeployable_v1.0/peoplesemsegnet.etlt ; \ git clone https://github.com/NVIDIA-AI-IOT/deepstream_tlt_apps.git ; cd deepstream_tlt_apps ; export CUDA_VER=11.1 ; export SHOW_MASK=1 ; make ; \ sed -i "s/..\/..\/models\/unet\/unet_resnet18.etlt_b1_gpu0_fp16.engine/..\/..\/..\/peoplesemsegnet_vdeployable_v1.0\/unet_resnet18.etlt_b1_gpu0_fp16.engine/g" \ configs/unet_tlt/pgie_unet_tlt_config.txt ; sed -i "s/infer-dims=3;608;960/infer-dims=3;544;960/g" configs/unet_tlt/pgie_unet_tlt_config.txt ; \ sed -i "s/unet_labels.txt/..\/..\/..\/peoplesemsegnet_vdeployable_v1.0\/labels.txt/g" configs/unet_tlt/pgie_unet_tlt_config.txt ; \ sed -i "s/num-detected-classes=3/num-detected-classes=2/g" configs/unet_tlt/pgie_unet_tlt_config.txt ; ./apps/ds-tlt -c configs/unet_tlt/pgie_unet_tlt_config.txt \ -i /opt/nvidia/deepstream/deepstream-5.1/samples/streams/sample_720p.h264 -d
General purpose CV model architecture - Classification, Object detection and Segmentation
A sample DeepStream app to run a classification, object detection, and semantic and instance segmentation network is provided in here.
TRT-OSS instructions are provided in the repo above. For more information about each individual model architecture, see the Deploying to DeepStream section under each model:
Object Detection
Instance Segmentation
Semantic Segmentation