cuMAC-CP#
CUDA RAN MAC Scheduler Control Plane (cuMAC-CP) is a process which provides an interface between 5G/6G L2 (MAC Scheduler Functions) and Aerial cuMAC library, with scheduler functions accelerated on GPU. It accepts L2/MAC scheduling request per cell, translates to cuMAC tasks and call cuMAC lib APIs to process on GPU. After processing is finished, it returns the scheduling results to L2/MAC by response message per cell.
Below is the cuMAC-CP architecture diagram.
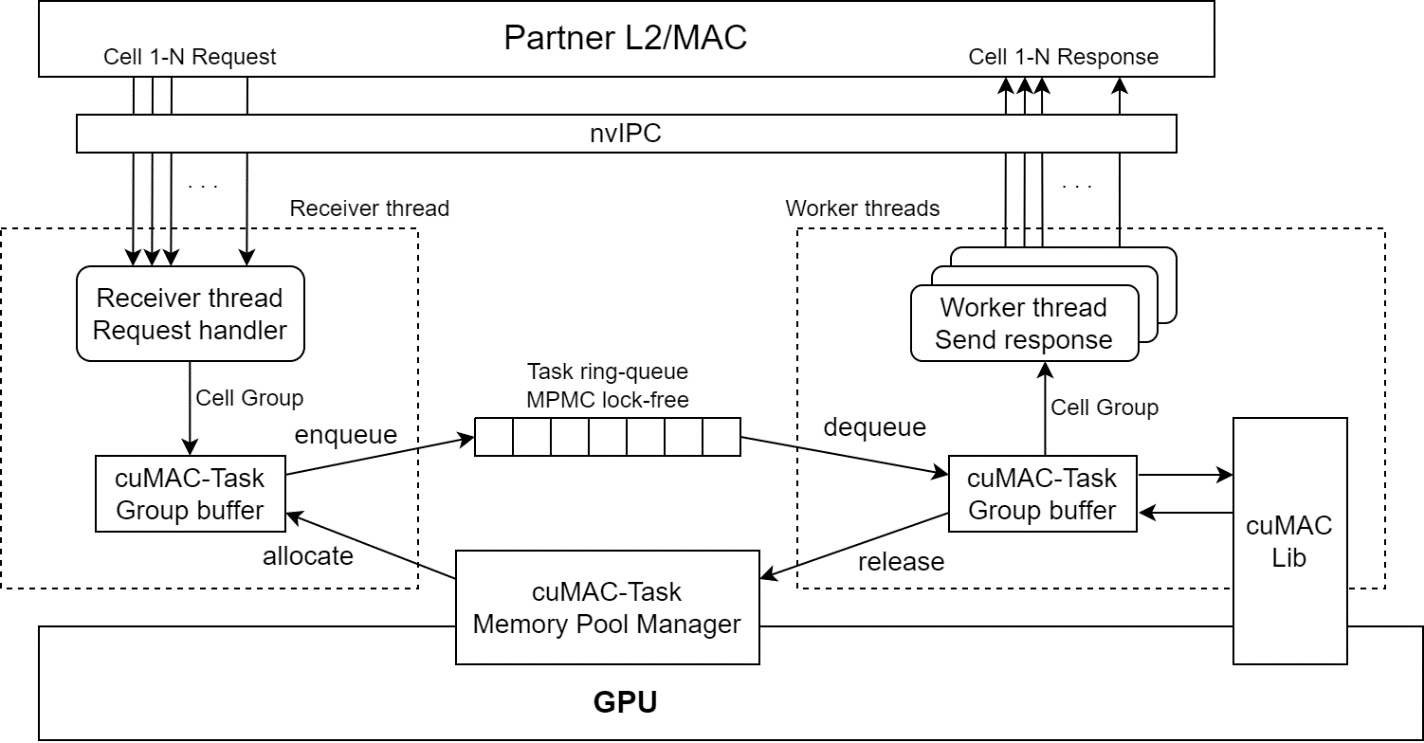
cuMAC-CP has 1 receiver thread and multiple worker threads which need to be bound to dedicated CPU cores. The thread model is as below. CPU core numbers are configurable by yaml file (24-2 release supports only 1 worker thread per core).
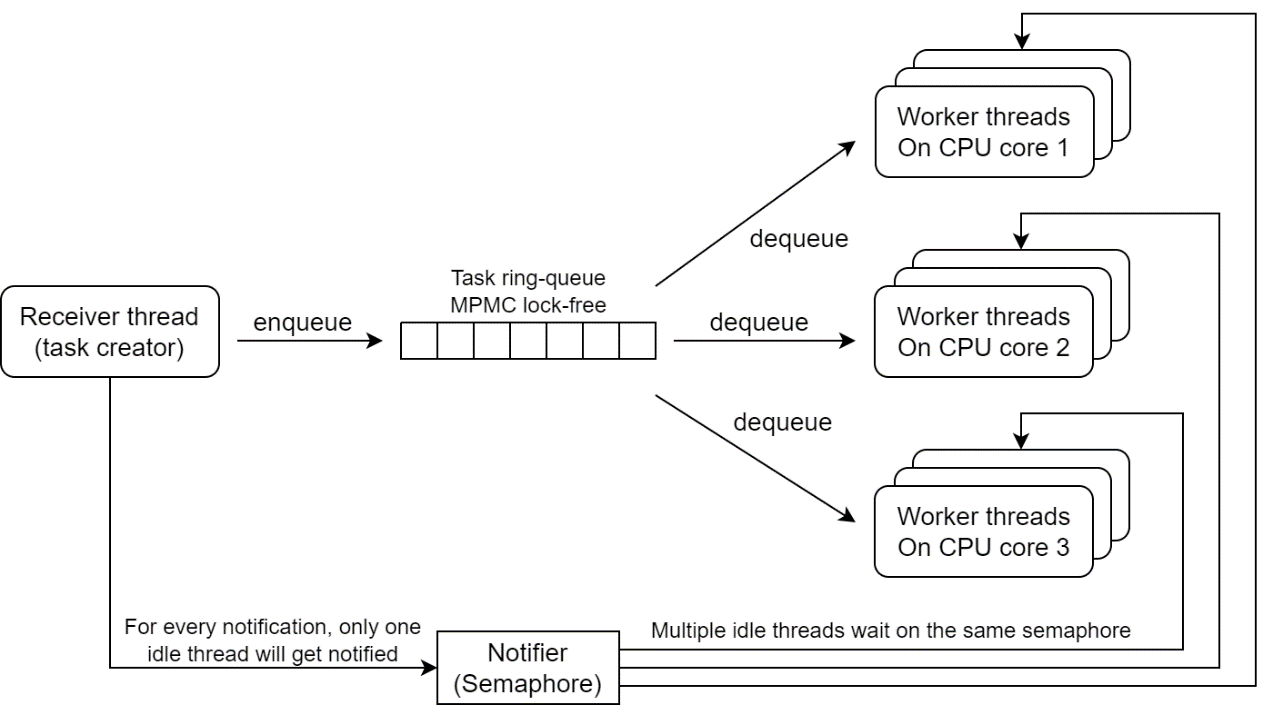
The receiver thread allocates a cumac_task object and necessary data
buffers for each slot. Once cuMAC-CP received schedule request messages
from L2/MAC for all cells, the receiver thread assemblies them into cell
group, populates the cumac_task object and pushes it into the lock-free
task queue, then increase the semaphore to notify the worker threads.
All worker threads wait on the same semaphore after initialization. Every time the semaphore is increased by the receiver thread, one worker thread will get the semaphore, dequeue cuMAC task and call cuMAC lib APIs to process it. After processing is finished, the worker thread creates per cell response messages and sends them to L2. Below is the program flow chart.
