

Promoting local and shared files
When it comes to working with files, the first question often is how? How to easily and quickly move or copy existing file datasets into AIS clusters?
There are, in fact, several distinct ways to handle existing datasets. But if those are files, we do recommend to maybe take a look at promote.
Introduced in v3.0 to exclusively handle local files and directories, promote over time has become the preferred method. Any file source is supported, local or remote, shared or not.
Here’s a quick and commented CLI illustration:
But if we want to, for instance:
- promote recursively to an s3 bucket - with nested subdirectories but without renaming the destination base, and
- delete sources upon (promoting) success, and
- overwrite destination objects (if exist), and finally
- prevent auto-detecting file share
then we can do something like this:
--not-file-sharetranslates as follows: each target to act autonomously, skipping auto-detection and promoting the entire file source as “seen” by this target.
Historically, AIS promote is reminiscent of what’s usually called server-side copy - a time-honored technique to engage sources and destinations directly, thus avoiding network roundtrips and client-side bottlenecks.
AIS, of course, takes it to a different level by distributing the work between clustered nodes that act independently and in parallel:
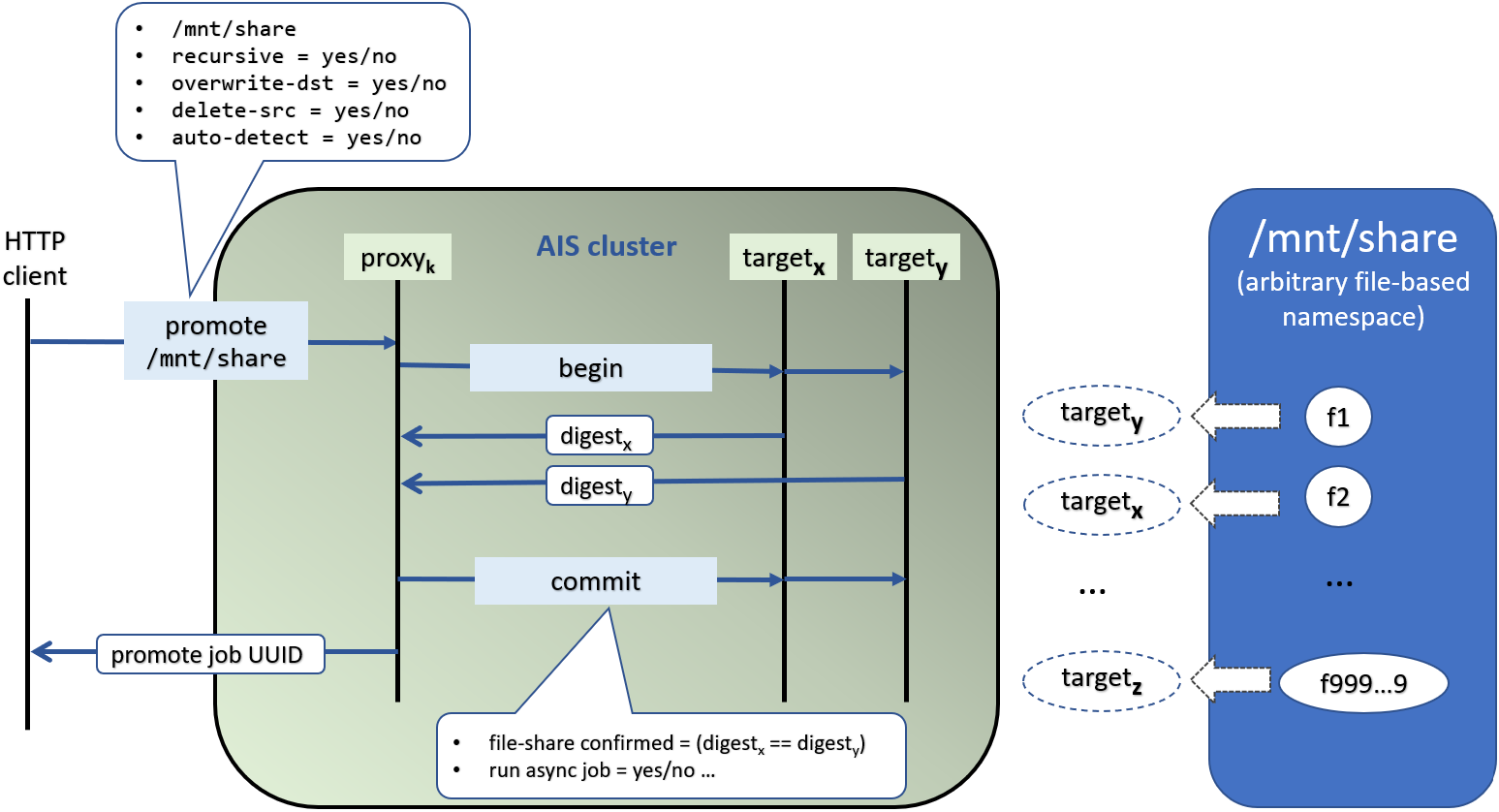
Here we have a client promoting NFS or SMB share called mnt/share.
The client can use CLI (as shown above), HTTP, or directly call native API via api.Promote. Either way:
-
Given correct HTTP address, the request finds the designated AIS cluster (shown as a green/gray bubble) and the AIS gateway (aka “proxy”) with that address.
-
AIS proxy then initiates a 2-phase transaction where the begin phase performs a range of validations to make sure that storage targets are ready to execute.
-
In particular, unless auto-detection is disabled, each target computes a digest of all sorted filenames under
mnt/share. For example,target-xwould computedigest-x,target-y-digest-y, and so on. -
This concludes the begin phase, after which the cluster, and each target individually, start committing - i.e, reading files from
mnt/shareand writing them locally as objects.
Further details are indicated on the line diagram above. The one nuance that’s maybe worth reiterating is that each target handles those, and only those, files that map to itself, location-wise.