Federated learning background and architecture
For details on using and operating the federated learning environment, see the Federated learning user guide.
For frequently asked questions, see the Federated learning FAQ.
Deep learning, the fastest growing field in AI, is empowering immense progress in scientific and real-life applications. It has been widely accepted that the more data used in the deep learning training, the better models can be achieved. However, those deep-learning algorithms are meeting difficult challenges when applied to the real-world, especially in the financial and health care areas. The data in these areas are typically subject to strong privacy regulations. It is often impossible to share data across different organizations. Annotated data is also hard to obtain and it represents an asset for individual institutions.
Hence, the question becomes: how can you obtain models as good as those that can be obtained training on large datasets without violating privacy and property constraints? One approach to solve this issue is to use federated learning. Different institutions contribute to the construction of a powerful model by doing collaborative training without sharing any data. A generic pre-trained model is fine-tuned for a specific application or a specific patient population. Different institutions share the trained model, not the actual data! With this approach, you can achieve the goal of training better models, while still protecting the data privacy.
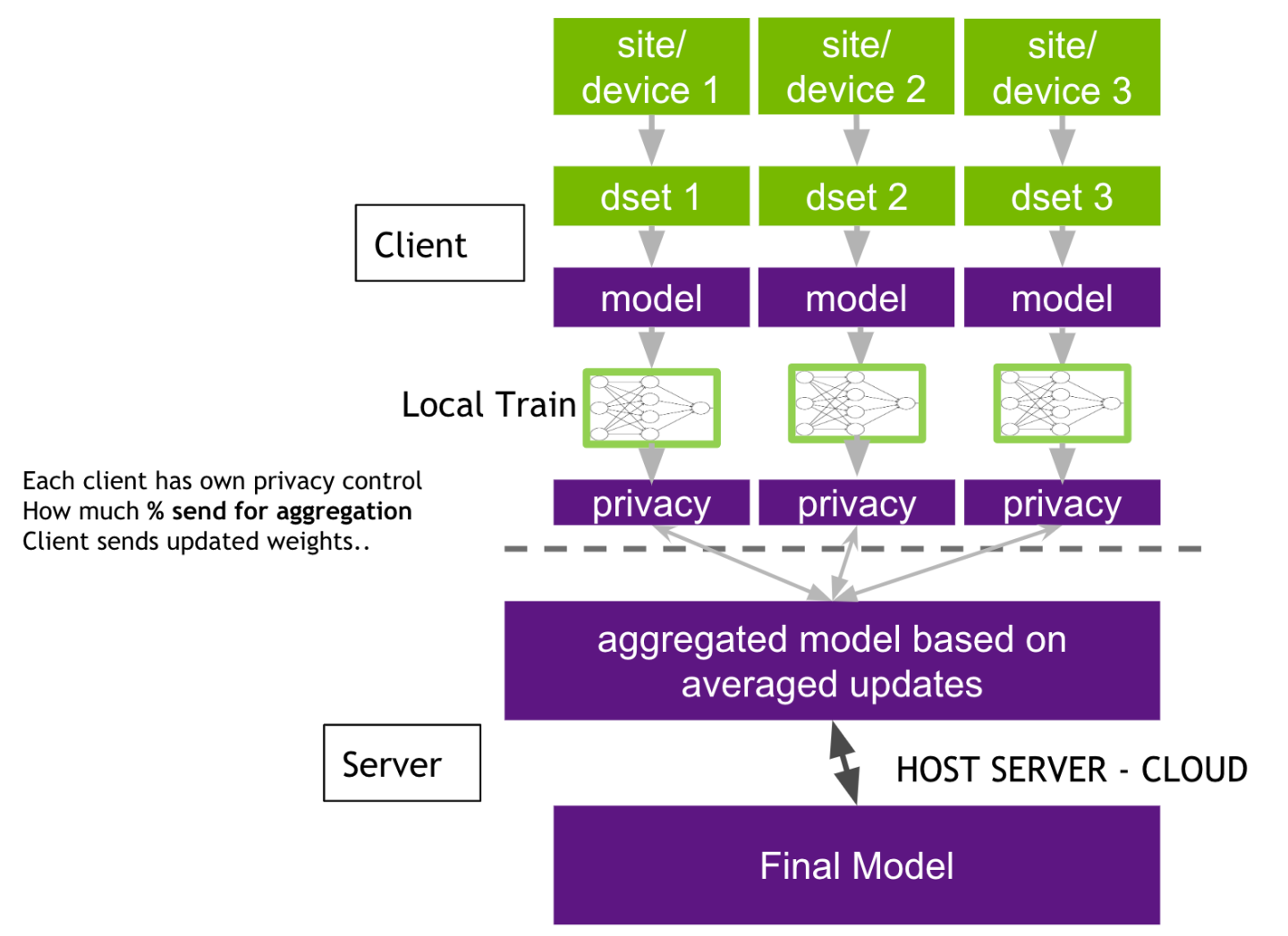
Federated learning is split into two parts: the server and the client. The server manages the overall model training progress and broadcasts the original model to all the participating clients. Model training happens locally on each client’s side. This way, the server does not need to access the training data. The data is protected with the private access on each client. All the clients are sharing the model updates instead of the data. Each client has its own privacy controls on what percentage of the model weights will be sent to the server for aggregation.
Once the server receives the latest round of models from the clients, the server can build its own algorithm on how to aggregate the model. It could be a simple average from all the clients, or based on some weights from the historical contributions from the clients.
The server has the overall control of how many rounds of federal learning training to conduct. The participating clients can be added or removed during any round of the training. Federated learning provides benefits for every participant: a stronger central model, and better local models.
Clara Train SDK provides sophisticated medical imaging specific deep learning transform modules through the Clara Train API. Clara Train supports the import/export of trained models from different training sources and allows for easy creation of training and evaluation workflows. Furthermore, Clara Train provides ready-to-use cutting-edge deep learning models with pre-processing pipelines addressing a wide range of real-life medical cases. The fully configurable deep learning model training and the open APIs provide the ability to easily integrate training with external models. With all these accomplishments in place, it is natural to extend Clara Train functionality to support federated learning across different institutions.
The approach we are taking is to use Clara Train on each client locally to perform training with the transforms made available by Clara Train API. On top of that, we will build a federated learning server to facilitate the overall model training. The server will manage the consolidated model from all the participating clients, control the training pace and how many rounds of overall training to conduct, and aggregate the training results by only sharing the training models from the clients, while the clients have control of how much of their weights to share with the server and how much protection to add on the data privacy.
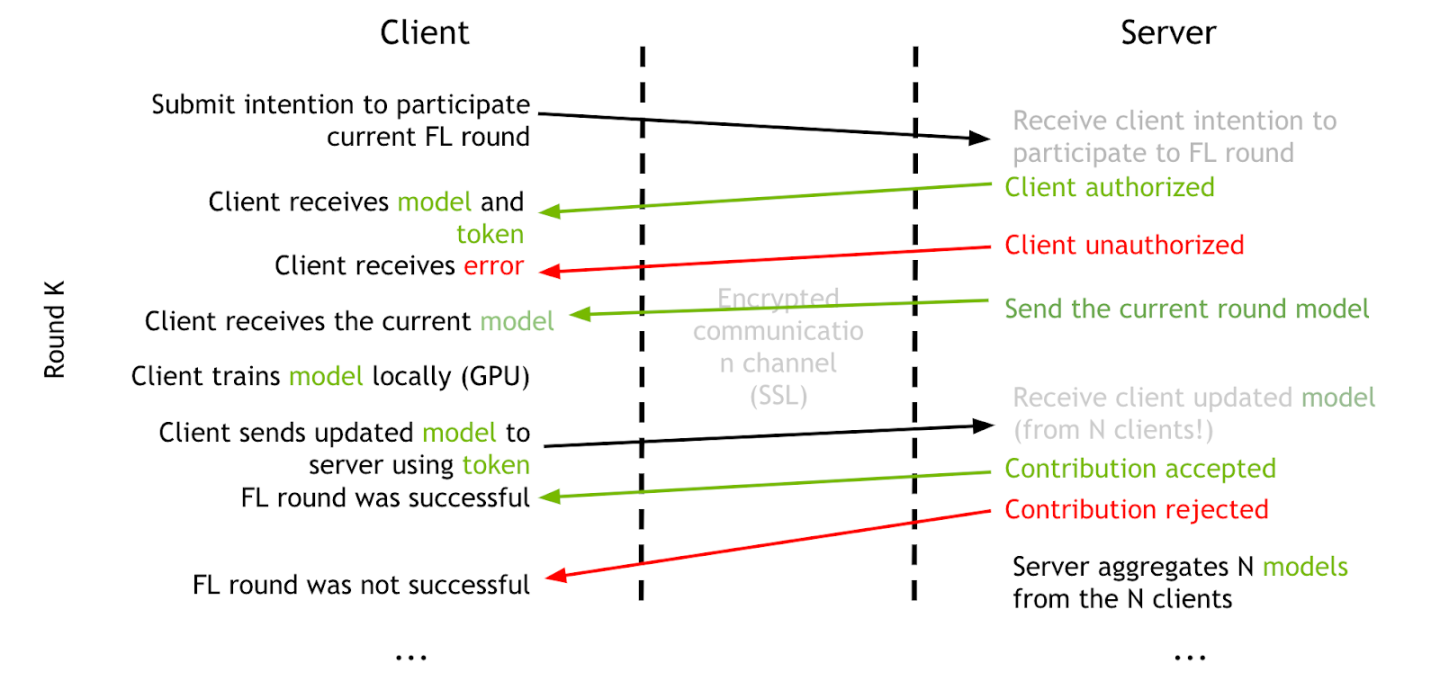
When running a federated learning model training, a server training service must first be started. The server session controls the minimum number of clients needed to start a round of FL training and the maximum number of clients that can join a round. If a client intends to join a FL session, it must first submit a login request to apply for FL training. The server will check the credentials of the FL client and perform the authentication process to validate the client. If the authentication is successful, the server sends a FL token back to the client for use in the following FL client-server communication. Otherwise, it sends an authentication rejection if the client can not be authenticated.
Then the client sends another request to get the current training model from the server to start the current round of model training. The client has its own control on how many epochs it will run during each round of FL training. Once the client finishes the current round of training, it sends the updated model to the server using the existing FL token. After the server receives all the updated models from all the participating clients, it performs the model aggregation based on the weights algorithms and gets the updated overall training model. This completes the current round of the FL training, and the FL training continues until it reaches the max rounds set on the server, num_rounds in the server configuration file.
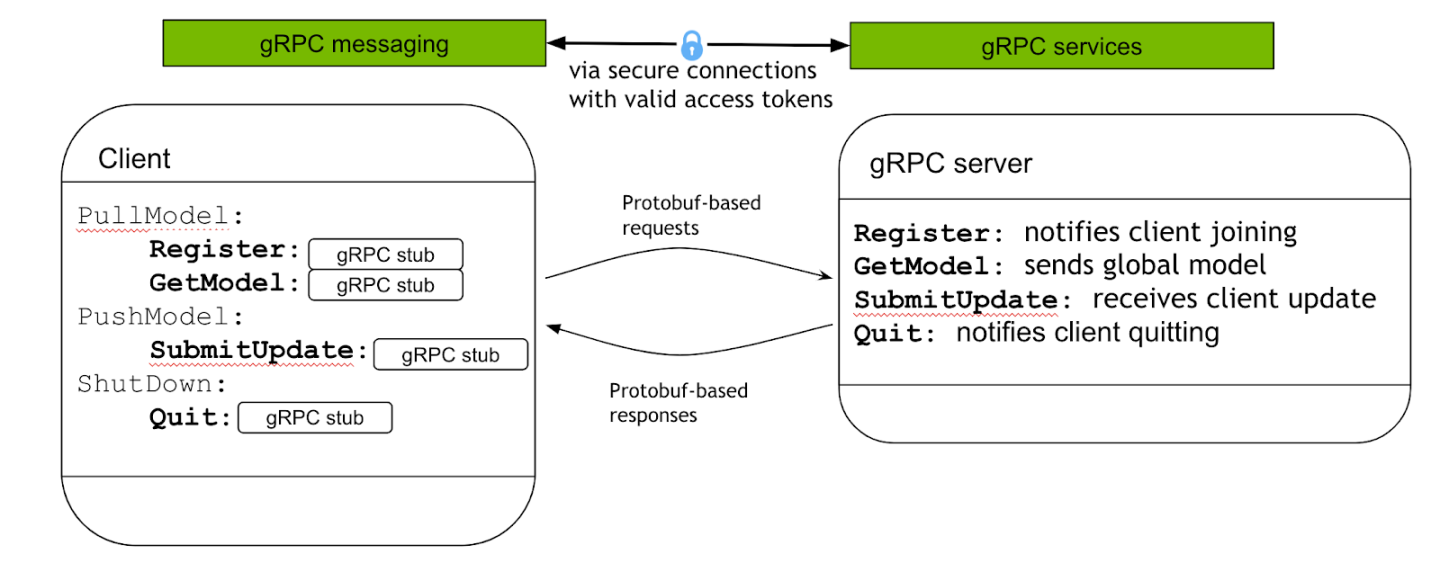
Federated learning uses the gPRC protocol between the server and clients during model training. There are 4 basic commands during the model training session:
Register: Client uses this command to notify intent to join a FL training. The server performs the client authentication then returns a FL token back to the client.
GetModel: Client uses this command to acquire the model of the current round from the server. The server checks the token, and sends back the global model to the client.
SubmitUpdate: Client uses this command to send the updated local model after the current round of FL training to the server for the aggregation.
Quit: The command to use when the client decides to quit from the current FL model training.
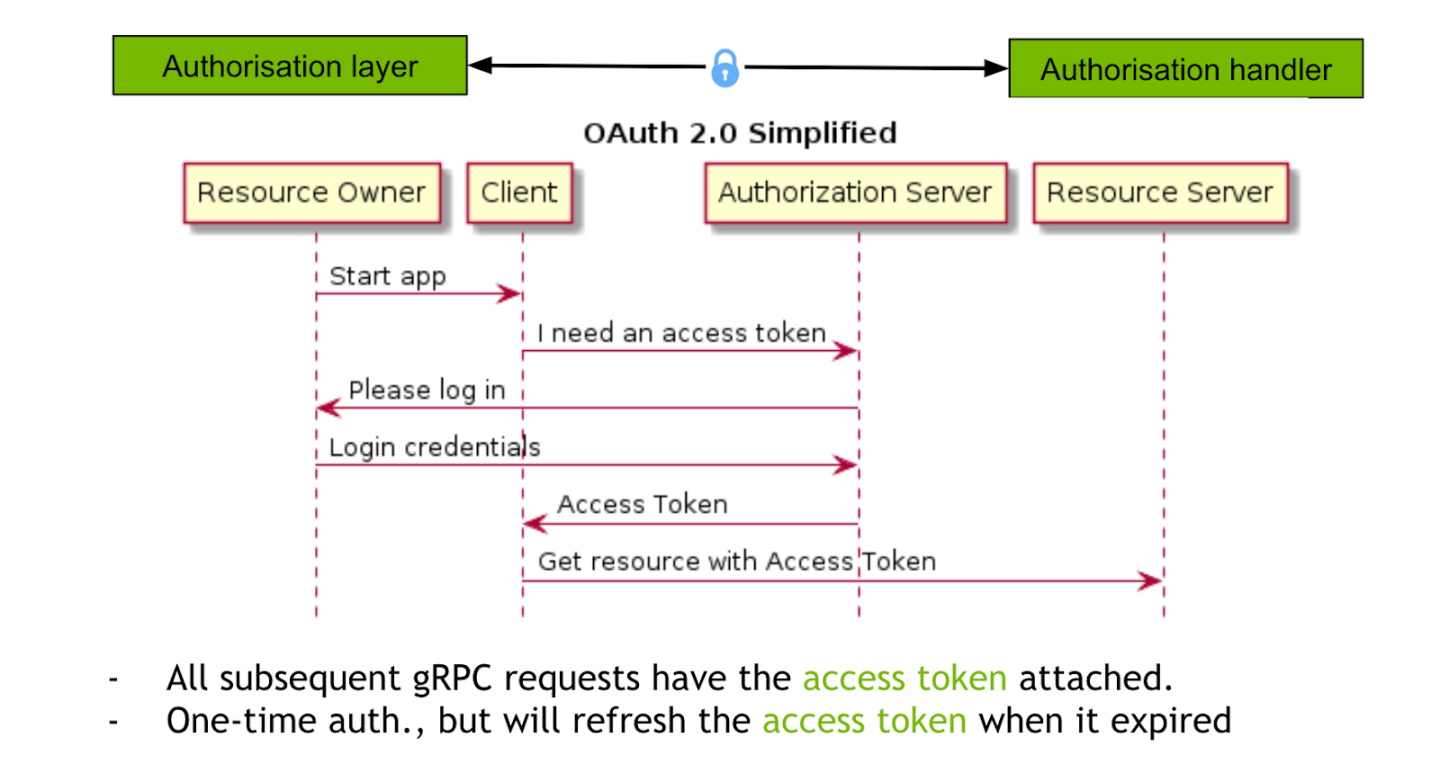
In order for the client to participate in the federated learning model training, the client needs to provide its credentials to be authenticated. There are many ways of client authentication for the client-server SOA implementation. For the federated learning deployment, we are not expecting the clients to frequently change their credentials. In this case, we choose to use the self-signed SSL certificates from the server authority to authenticate the client identities.
The client first sends a login request to the server for participating in federated learning training. After successful authentication, a FL token is returned to the client. The client uses the FL token for all the following communication requests. The token expiration is managed on the server side. Once the FL token is expired, the client needs to make a new login request and get a new FL token.
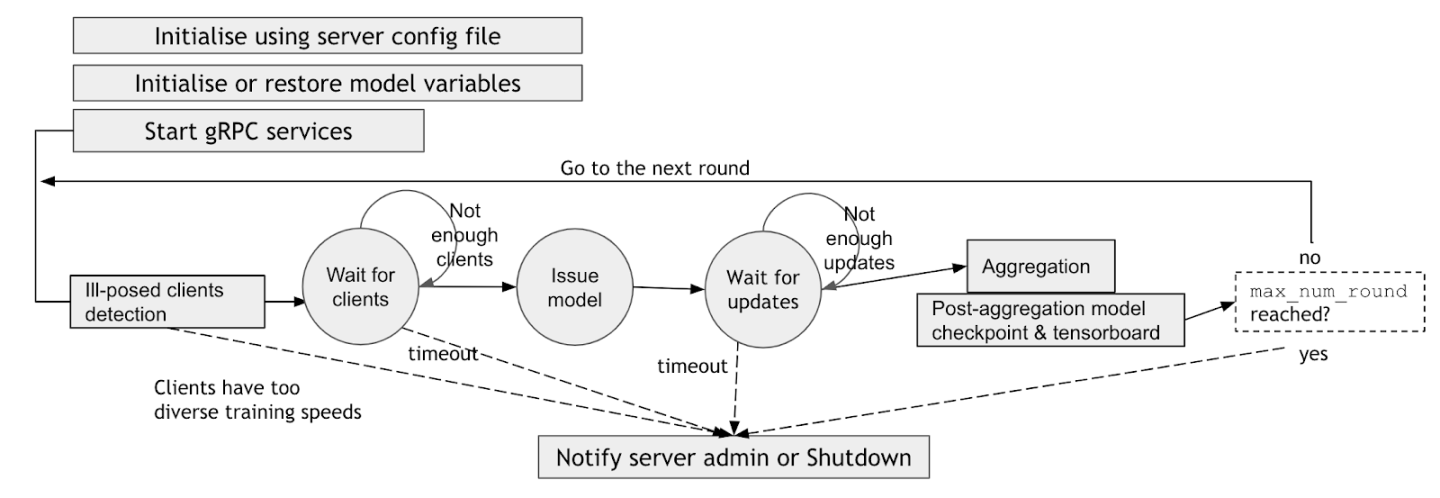
When starting a federated learning server-side service, the server side config files, including FL service name, gPRC communication ports, SSL certificate keys, minimum and maximum number of clients, etc, are used to initialize and restore the initial model and start the FL service. After the initialization, the server enters into a loop, waiting for clients’ joining request, then issuing the model to the clients, and waiting for the clients to send back the updated models. Once the server receives all the updated models from the clients, it performs the aggregation based on the weight aggregation algorithms, and updates the current overall model. This updated overall model is then used for the next round of model training, and this process is repeated until the server reaches the maximum rounds of the federated learning training.
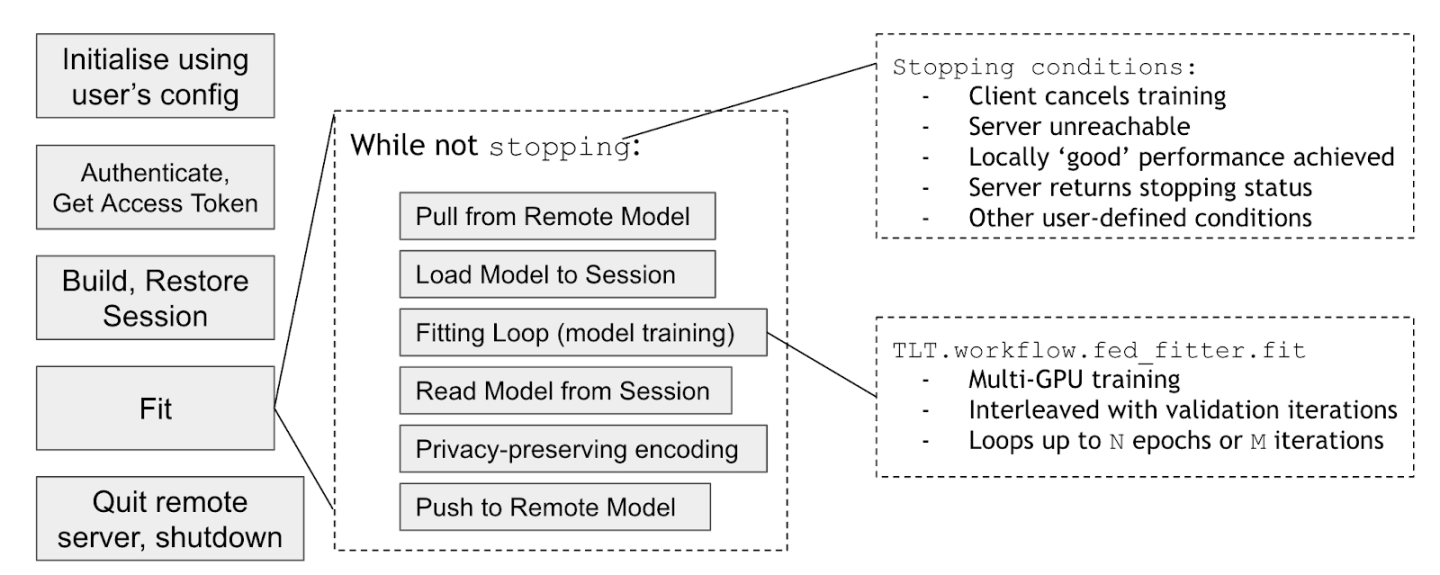
On the client side of federated learning model training, the client first uses the client configuration to initialize. Then, the client uses the client credential to make a login request to the server to get a FL training token. Once the token is obtained, the client requests the current model from the server. It uses the current global model to build and restore the TF session to start the local training using the local data for fitting the current model. During the local training, the client has control how many epochs to run for each round of FL training. It also has to control whether the local training is run on a single GPU or multiple GPUs.
Once the client finishes the current round of the local model training, the clients sends the updated local model to the server. The client can configure its own privacy preserving policies on how much of the weights to send back to the server for aggregation. After that, the client makes a request to the server asking for the new global model to start a new round of federated learning training.
During federated learning training, a bunch of different models are trained. These include the global server model, models generated by some handlers and each client’s local best model. Once training is done, we may like to validate these models on each client’s data. We call this process Cross site validation. This is an optional step after training.
Once training finishes, and if the client is participating in cross site validation, it sends it’s best local model to the server. It then asks the server for any models to validate. The server can have 3 possible responses 1) Send a model, 2) Ask the client to wait because models are not ready yet or 3) Tell client that no more models need to be validate. Based on the response, the client 1) validates model and sends the results 2) Wait for some time before asking again 3) Finish.
Through this process, each client validates models of all other clients, server global model and models generated by handler. The results can be fetched from the server.
The federated learning functions are packaged with the same Medical Model Archive (MMAR) structure as in Clara. In terms of the model training configurations, the FL model training uses the same Clara transform pipeline solution. The MMAR folder structure stays the same, and the Clara training commands and the training pipeline configurations stay the same.
There will be two additional server-client configurations to describe the federated learning behaviors. The server trainer controls how many rounds of FL training to conduct for the whole model training process, aggregates the overall models from the participating clients, and coordinates the global model training progress. The client trainer controls how many epochs the model training needs to run for each FL round, and the privacy protection policy to use when publishing the local training model back to the FL server for aggregation.
When starting a federated learning model training, you first start the FL training service from the server with the server_train.sh command. This service manages the FL training task identity and gPRC communication service location URLs. During the FL life cycle, the service listens for the clients to join, broadcasts the global model, and aggregates the updated models from the client.
From the client side, the client uses the client_train.sh command to start a FL client training task. It gets the FL token through a login request, gets the global model from the server, trains and updates the local model using protected data locally, and submits the model to the server for aggregation after each round of FL training.
One of the major motivations for federated learning is to safeguard data privacy. The federated learning model training typically involves multiple different organizations. Through the federated learning, each organization is enabled to train the model locally, sharing only the model, not the private data. However, the client-server communication is also critical to keep the data and model communication secure without being compromised.
In order to achieve federated learning security, use the FL token to establish trust between the client and server. The FL token is used throughout the FL training session life cycle. Clients need to verify the server identity and the server needs to verify and authenticate the clients. The client-server data exchanges are based on the HTTPS protocol for secure communication. The self-signed SSL certificates are used to build the client-server trust. Clara Train 3.1 introduced the provisioning process which handles the authentication automatically by creating the right certificates in the packages for the server and clients. Clara Train 3.1 also has authorization settings to allow for configuring granular restrictions for actions of users on sites based on specified groups.
Data protection
To mitigate the risk of recovering the training data from the trained model, which is also commonly known as reverse engineering or model inversion, we provide a configurable client-side privacy control based on the differential-privacy (DP) technique. During training, each client can have their own privacy policy.
The DP protection consists of two major components: selective parameter update and sparse vector technique (SVT):
For selective parameter update, the client only sends a partial of the model weights/updates, instead of the whole, to limit the amount of information shared. This is achieved by (1) only uploading the fraction of the model weights/updates whose absolute values are greater than a predefined threshold or percentile of the absolute update values; (2) further replacing the model weights by clipping its value to a fixed range.
Sparse vector technique operates on a random fraction of the weights/updates x by first adding a random noise to its absolute value abs(x)+Lap(s); then share the clipped noisy value clip(x+Lap(s), y) iff the thresholding condition is satisfied. Here abs(x) represents absolute value, Lap(x) denotes a random variable sampled from the Laplace distribution, y is a predefined threshold, clip(x,y) denotes clipping of x value to be in the range of [-y,y].
For details, please refer to [1]. The experimental results show that there is a tradeoff between model performance and privacy protection costs.
[1] W, Li. et, al “Privacy-preserving Federated Brain Tumour Segmentation”, arXiv preprint arXiv:1910.00962 (2019)
Starting from Clara Train 3.1, federated learning has been enhanced to enable easy server and client deployment through the use of an administration client. The Federated learning user guide details the steps to set up and operate a federated learning project.