Essential concepts
This section describes essential concepts necessary for understanding Clara Train.
Clara Train is built using a component-based architecture. This diagram shows the structure of the training graph and how the components are related.
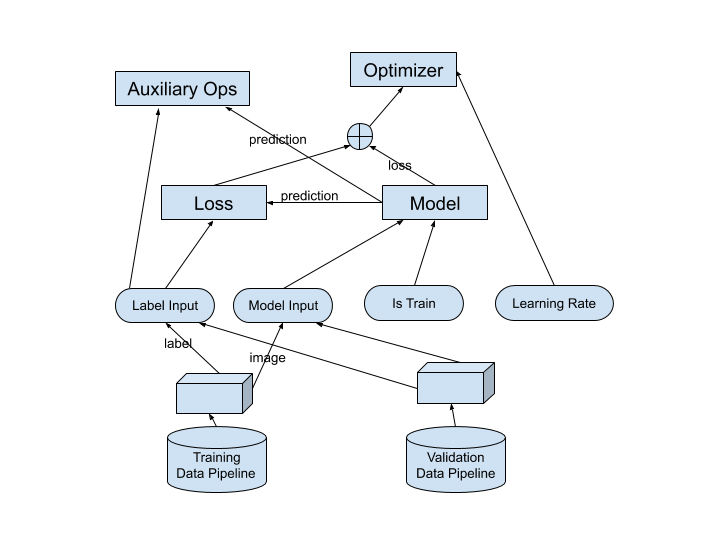
The components are built in the following order:
Training Data Pipeline
Validation Data Pipeline
Placeholders
Model (see ai4med.components.models)
Loss (see ai4med.components.losses)
Optimizer (see ai4med.components.optimizers)
Metrics (see ai4med.components.metrics)
Data pipelines are responsible for producing batched data items during training. Typically, two data pipelines are used: one for producing training data, another producing validation data.
A data pipeline contains a chain of transforms that are applied to the input image and label data to produce the data in the format required by the model.
For more details on directory setup for properly loading data, see the Image Pipeline section.
Data pipelines contain chains of transformations. A transform in the chain takes some data from TransformContext, performs some operations and puts it back in the context for the next transform in the chain.
For a list of available transforms, see the ai4med.components.transforms package section.
The blue ovals in the diagram above represent placeholders. The placeholders are the label input, model input, is train (whether training is taking place), and the learning rate.
Metric values are computed based on values of tensors. A training metric is a graph-building component that adds computational operations to the training graph, which produce tensors for metric computation.
Metrics can be used to dynamically measure the quality of the model during training on different aspects.