Creating an Application
In this section, we’ll address:
how to define an Application class
how to configure an Application
This section covers basics of applications running as a single fragment. For multi-fragment applications, refer to the distributed application documentation.
The following code snippet shows an example Application code skeleton:
We define the
Appclass that inherits from theApplicationbase class.We create an instance of the
Appclass inmain()using themake_application()function.The
run()method starts the application which will execute itscompose()method where the custom workflow will be defined.
#include <holoscan/holoscan.hpp>
class App : public holoscan::Application {
public:
void compose() override {
// Define Operators and workflow
// ...
}
};
int main() {
auto app = holoscan::make_application<App>();
app->run();
return 0;
}
We define the
Appclass that inherits from theApplicationbase class.We create an instance of the
Appclass in amain()function that is called from__main__.The
run()method starts the application which will execute itscompose()method where the custom workflow will be defined.
from holoscan.core import Application
class App(Application):
def compose(self):
# Define Operators and workflow
# ...
def main():
app = App()
app.run()
if __name__ == "__main__":
main()
It is recommended to call run() from within a separate main() function rather than calling it directly from __main__. This will ensure that the Application’s destructor is called before the Python process exits.
This is also illustrated in the hello_world example.
It is also possible to instead launch the application asynchronously (i.e. non-blocking for the thread launching the application), as shown below:
This can be done simply by replacing the call to run() with run_async() which returns a std::future. Calling future.get() will block until the application has finished running and throw an exception if a runtime error occurred during execution.
int main() {
auto app = holoscan::make_application<App>();
auto future = app->run_async();
future.get();
return 0;
}
This can be done simply by replacing the call to run() with run_async() which returns a Python concurrent.futures.Future. Calling future.result() will block until the application has finished running and raise an exception if a runtime error occurred during execution.
def main():
app = App()
future = app.run_async()
future.result()
if __name__ == "__main__":
main()
This is also illustrated in the ping_simple_run_async example.
An application can be configured at different levels:
providing the GXF extensions that need to be loaded (when using GXF operators)
configuring parameters for your application, including for:
the operators in the workflow
the scheduler of your application
configuring some runtime properties when deploying for production
The sections below will describe how to configure each of them, starting with a native support for YAML-based configuration for convenience.
YAML Configuration support
Holoscan supports loading arbitrary parameters from a YAML configuration file at runtime, making it convenient to configure each item listed above, or other custom parameters you wish to add on top of the existing API. For C++ applications, it also provides the ability to change the behavior of your application without needing to recompile it.
Usage of the YAML utility is optional. Configurations can be hardcoded in your program, or done using any parser of your choosing.
Here is an example YAML configuration:
string_param: "test"
float_param: 0.50
bool_param: true
dict_param:
key_1: value_1
key_2: value_2
Ingesting these parameters can be done using the two methods below:
The
config()method takes the path to the YAML configuration file. If the input path is relative, it will be relative to the current working directory.The
from_config()method returns anArgListobject for a given key in the YAML file. It holds a list ofArgobjects, each of which holds a name (key) and a value.If the
ArgListobject has only oneArg(when the key is pointing to a scalar item), it can be converted to the desired type using theas()method by passing the type as an argument.The key can be a dot-separated string to access nested fields.
The
config_keys()method returns an unordered set of the key names accessible viafrom_config().
// Pass configuration file
auto app = holoscan::make_application<App>();
app->config("path/to/app_config.yaml");
// Scalars
auto string_param = app->from_config("string_param").as<std::string>();
auto float_param = app->from_config("float_param").as<float>();
auto bool_param = app->from_config("bool_param").as<bool>();
// Dict
auto dict_param = app->from_config("dict_param");
auto dict_nested_param = app->from_config("dict_param.key_1").as<std::string>();
// Print
std::cout << "string_param: " << string_param << std::endl;
std::cout << "float_param: " << float_param << std::endl;
std::cout << "bool_param: " << bool_param << std::endl;
std::cout << "dict_param:\n" << dict_param.description() << std::endl;
std::cout << "dict_param['key1']: " << dict_nested_param << std::endl;
// // Output
// string_param: test
// float_param: 0.5
// bool_param: 1
// dict_param:
// name: arglist
// args:
// - name: key_1
// type: YAML::Node
// value: value_1
// - name: key_2
// type: YAML::Node
// value: value_2
// dict_param['key1']: value_1
The
config()method takes the path to the YAML configuration file. If the input path is relative, it will be relative to the current working directory.The
kwargs()method return a regular python dict for a given key in the YAML file.Advanced: this method wraps the
from_config()method similar to the C++ equivalent, which returns anArgListobject if the key is pointing to a map item, or anArgobject if the key is pointing to a scalar item. AnArgobject can be cast to the desired type (e.g.,str(app.from_config("string_param"))).
The
config_keys()method returns a set of the key names accessible viafrom_config().
# Pass configuration file
app = App()
app.config("path/to/app_config.yaml")
# Scalars
string_param = app.kwargs("string_param")["string_param"]
float_param = app.kwargs("float_param")["float_param"]
bool_param = app.kwargs("bool_param")["bool_param"]
# Dict
dict_param = app.kwargs("dict_param")
dict_nested_param = dict_param["key_1"]
# Print
print(f"string_param:{string_param}")
print(f"float_param:{float_param}")
print(f"bool_param:{bool_param}")
print(f"dict_param:{dict_param}")
print(f"dict_param['key_1']:{dict_nested_param}")
# # Output:
# string_param: test
# float_param: 0.5
# bool_param: True
# dict_param: {'key_1': 'value_1', 'key_2': 'value_2'}
# dict_param['key_1']: 'value_1'
from_config() cannot be used as inputs to the built-in operators at this time, it’s therefore recommended to use kwargs() in Python.
This is also illustrated in the video_replayer example.
With both from_config and kwargs, the returned ArgList/dictionary will include both the key and its associated item if that item value is a scalar. If the item is a map/dictionary itself, the input key is dropped, and the output will only hold the key/values from that item.
Loading GXF extensions
If you use operators that depend on GXF extensions for their implementations (known as GXF operators), the shared libraries (.so) of these extensions need to be dynamically loaded as plugins at runtime.
The SDK already automatically handles loading the required extensions for the built-in operators in both C++ and Python, as well as common extensions (listed here). To load additional extensions for your own operators, you can use one of the following approach:
extensions:
- libgxf_myextension1.so
- /path/to/libgxf_myextension2.so
auto app = holoscan::make_application<App>();
auto exts = {"libgxf_myextension1.so", "/path/to/libgxf_myextension2.so"};
for (auto& ext : exts) {
app->executor().extension_manager()->load_extension(ext);
}
from holoscan.gxf import load_extensions
from holoscan.core import Application
app = Application()
context = app.executor.context_uint64
exts = ["libgxf_myextension1.so", "/path/to/libgxf_myextension2.so"]
load_extensions(context, exts)
To be discoverable, paths to these shared libraries need to either be absolute, relative to your working directory, installed in the lib/gxf_extensions folder of the holoscan package, or listed under the HOLOSCAN_LIB_PATH or LD_LIBRARY_PATH environment variables.
Please see other examples in the system tests in the Holoscan SDK repository.
Configuring operators
Operators are defined in the compose() method of your application. They are not instantiated
(with the initialize method) until an application’s run() method is called.
Operators have three type of fields which can be configured: parameters, conditions, and resources.
Configuring operator parameters
Operators could have parameters defined in their setup method to better control their behavior (see details when creating your own operators). The snippet below would be the implementation of this method for a minimal operator named MyOp, that takes a string and a boolean as parameters; we’ll ignore any extra details for the sake of this example:
void setup(OperatorSpec& spec) override {
spec.param(string_param_, "string_param");
spec.param(bool_param_, "bool_param");
}
def setup(self, spec: OperatorSpec):
spec.param("string_param")
spec.param("bool_param")
# Optional in python. Could define `self.<param_name>` instead in `def __init__`
Given this YAML configuration:
myop_param:
string_param: "test"
bool_param: true
bool_param: false # we'll use this later
We can configure an instance of the MyOp operator in the application’s compose method like this:
void compose() override {
// Using YAML
auto my_op1 = make_operator<MyOp>("my_op1", from_config("myop_param"));
// Same as above
auto my_op2 = make_operator<MyOp>("my_op2",
Arg("string_param", std::string("test")), // can use Arg(key, value)...
Arg("bool_param") = true // ... or Arg(key) = value
);
}
def compose(self):
# Using YAML
my_op1 = MyOp(self, name="my_op1", **self.kwargs("myop_param"))
# Same as above
my_op2 = MyOp(self,
name="my_op2",
string_param="test",
bool_param=True,
)
This is also illustrated in the ping_custom_op example.
If multiple ArgList are provided with duplicate keys, the latest one overrides them:
void compose() override {
// Using YAML
auto my_op1 = make_operator<MyOp>("my_op1",
from_config("myop_param"),
from_config("bool_param")
);
// Same as above
auto my_op2 = make_operator<MyOp>("my_op2",
Arg("string_param", "test"),
Arg("bool_param") = true,
Arg("bool_param") = false
);
// -> my_op `bool_param_` will be set to `false`
}
def compose(self):
# Using YAML
my_op1 = MyOp(self, name="my_op1",
from_config("myop_param"),
from_config("bool_param"),
)
# Note: We're using from_config above since we can't merge automatically with kwargs
# as this would create duplicated keys. However, we recommend using kwargs in python
# to avoid limitations with wrapped operators, so the code below is preferred.
# Same as above
params = self.kwargs("myop_param").update(self.kwargs("bool_param"))
my_op2 = MyOp(self, name="my_op2", params)
# -> my_op `bool_param` will be set to `False`
Configuring operator conditions
By default, operators with no input ports will continuously run, while operators with input ports will run as long as they receive inputs (as they’re configured with the MessageAvailableCondition).
To change that behavior, one or more other conditions classes can be passed to the constructor of an operator to define when it should execute.
For example, we set three conditions on this operator my_op:
void compose() override {
// Limit to 10 iterations
auto c1 = make_condition<CountCondition>("my_count_condition", 10);
// Wait at least 200 milliseconds between each execution
auto c2 = make_condition<PeriodicCondition>("my_periodic_condition", "200ms");
// Stop when the condition calls `disable_tick()`
auto c3 = make_condition<BooleanCondition>("my_bool_condition");
// Pass directly to the operator constructor
auto my_op = make_operator<MyOp>("my_op", c1, c2, c3);
}
def compose(self):
# Limit to 10 iterations
c1 = CountCondition(self, 10, name="my_count_condition")
# Wait at least 200 milliseconds between each execution
c2 = PeriodicCondition(self, timedelta(milliseconds=200), name="my_periodic_condition")
# Stop when the condition calls `disable_tick()`
c3 = BooleanCondition(self, name="my_bool_condition")
# Pass directly to the operator constructor
my_op = MyOp(self, c1, c2, c3, name="my_op")
This is also illustrated in the conditions examples.
You’ll need to specify a unique name for the conditions if there are multiple conditions applied to an operator.
Configuring operator resources
Some resources can be passed to the operator’s constructor, typically an allocator passed as a regular parameter.
For example:
void compose() override {
// Allocating memory pool of specific size on the GPU
// ex: width * height * channels * channel size in bytes
auto block_size = 640 * 480 * 4 * 2;
auto p1 = make_resource<BlockMemoryPool>("my_pool1", 1, size, 1);
// Provide unbounded memory pool
auto p2 = make_condition<UnboundedAllocator>("my_pool2");
// Pass to operator as parameters (name defined in operator setup)
auto my_op = make_operator<MyOp>("my_op",
Arg("pool1", p1),
Arg("pool2", p2));
}
def compose(self):
# Allocating memory pool of specific size on the GPU
# ex: width * height * channels * channel size in bytes
block_size = 640 * 480 * 4 * 2;
p1 = BlockMemoryPool(self, name="my_pool1", storage_type=1, block_size=block_size, num_blocks=1)
# Provide unbounded memory pool
p2 = UnboundedAllocator(self, name="my_pool2")
# Pass to operator as parameters (name defined in operator setup)
auto my_op = MyOp(self, name="my_op", pool1=p1, pool2=p2)
Native resource creation
The resources bundled with the SDK are wrapping an underlying GXF component. However, it is also possible to define a “native” resource without any need to create and wrap an underlying GXF component. Such a resource can also be passed conditionally to an operator in the same way as the resources created in the previous section.
For example:
To create a native resource, implement a class that inherits from Resource
namespace holoscan {
class MyNativeResource : public holoscan::Resource {
public:
HOLOSCAN_RESOURCE_FORWARD_ARGS_SUPER(MyNativeResource, Resource)
MyNativeResource() = default;
// add any desired parameters in the setup method
// (a single string parameter is shown here for illustration)
void setup(ComponentSpec& spec) override {
spec.param(message_, "message", "Message string", "Message String", std::string("test message"));
}
// add any user-defined methods (these could be called from an Operator's compute method)
std::string message() { return message_.get(); }
private:
Parameter<std::string> message_;
};
} // namespace: holoscan
The setup method can be used to define any parameters needed by the resource.
This resource can be used with a C++ operator, just like any other resource. For example, an operator could have a parameter holding a shared pointer to MyNativeResource as below.
private:
class MyOperator : public holoscan::Operator {
public:
HOLOSCAN_OPERATOR_FORWARD_ARGS(MyOperator)
MyOperator() = default;
void setup(OperatorSpec& spec) override {
spec.param(message_resource_, "message_resource", "message resource",
"resource printing a message");
}
void compute(InputContext&, OutputContext& op_output, ExecutionContext&) override {
HOLOSCAN_LOG_TRACE("MyOp::compute()");
// get a resource based on its name (this assumes the app author named the resource "message_resource")
auto res = resource<MyNativeResource>("message_resource");
if (!res) {
throw std::runtime_error("resource named 'message_resource' not found!");
}
// call a method on the retrieved resource class
auto message = res->message();
};
private:
Parameter<std::shared_ptr<holoscan::MyNativeResource> message_resource_;
}
The compute method above demonstrates how the templated resource method can be used to retrieve a resource.
and the resource could be created and passed via a named argument in the usual way
// example code for within Application::compose (or Fragment::compose)
auto message_resource = make_resource<holoscan::MyNativeResource>(
"message_resource", holoscan::Arg("message", "hello world");
auto my_op = std::make_operator<holoscan::ops::MyOperator>(
"my_op", holoscan::Arg("message_resource", message_resource));
As with GXF-based resources, it is also possible to pass a native resource as a positional argument to the operator constructor.
For a concreate example of native resource use in a real application, see the volume_rendering_xr application on Holohub. This application uses a native XrSession resource type which corresponds to a single OpenXR session. This single “session” resource can then be shared by both the XrBeginFrameOp and XrEndFrameOp operators.
To create a native resource, implement a class that inherits from Resource.
class MyNativeResource(Resource):
def __init__(self, fragment, message="test message", *args, **kwargs):
self.message = message
super().__init__(fragment, *args, **kwargs)
# Could optionally define Parameter as in C++ via spec.param as below.
# Here, we chose instead to pass message as an argument to __init__ above.
# def setup(self, spec: ComponentSpec):
# spec.param("message", "test message")
# define a custom method
def message(self):
return self.message
The below shows how some custom operator could use such a resource in its compute method
class MyOperator(Operator):
def compute(self, op_input, op_output, context):
resource = self.resource("message_resource")
if resource is None:
raise ValueError("expected message resource not found")
assert isinstance(resource, MyNativeResource)
print(f"message ={resource.message()")
where this native resource could have been created and passed positionally to MyOperator as follows
# example code within Application.compose (or Fragment.compose)
message_resource = MyNativeResource(
fragment=self, message="hello world", name="message_resource")
# pass the native resource as a positional argument to MyOperator
my_op = MyOperator(fragment=self, message_resource)
There is a minimal example of native resource use in the examples/native folder.
Configuring the scheduler
The scheduler controls how the application schedules the execution of the operators that make up its workflow.
The default scheduler is a single-threaded GreedyScheduler. An application can be configured to use a different scheduler Scheduler (C++/Python) or change the parameters from the default scheduler, using the scheduler() function (C++/Python).
For example, if an application needs to run multiple operators in parallel, the MultiThreadScheduler or EventBasedScheduler can instead be used. The difference between the two is that the MultiThreadScheduler is based on actively polling operators to determine if they are ready to execute, while the EventBasedScheduler will instead wait for an event indicating that an operator is ready to execute.
The code snippet belows shows how to set and configure a non-default scheduler:
We create an instance of a holoscan::Scheduler derived class by using the
make_scheduler()function. Like operators, parameters can come from explicitArgs orArgList, or from a YAML configuration.The
scheduler()method assigns the scheduler to be used by the application.
auto app = holoscan::make_application<App>();
auto scheduler = app->make_scheduler<holoscan::EventBasedScheduler>(
"myscheduler",
Arg("worker_thread_number", 4),
Arg("stop_on_deadlock", true)
);
app->scheduler(scheduler);
app->run();
We create an instance of a
Schedulerclass in theschedulersmodule. Like operators, parameters can come from an explicitArgorArgList, or from a YAML configuration.The
scheduler()method assigns the scheduler to be used by the application.
app = App()
scheduler = holoscan.schedulers.EventBasedScheduler(
app,
name="myscheduler",
worker_thread_number=4,
stop_on_deadlock=True,
)
app.scheduler(scheduler)
app.run()
This is also illustrated in the multithread example.
Configuring runtime properties
As described below, applications can run simply by executing the C++ or Python application manually on a given node, or by packaging it in a HAP container. With the latter, runtime properties need to be configured: refer to the App Runner Configuration for details.
Operators are initialized according to the topological order of its fragment-graph. When an application runs, the operators are executed in the same topological order. Topological ordering of the graph ensures that all the data dependencies of an operator are satisfied before its instantiation and execution. Currently, we do not support specifying a different and explicit instantiation and execution order of the operators.
One-operator Workflow
The simplest form of a workflow would be a single operator.

Fig. 12 A one-operator workflow
The graph above shows an Operator (C++/Python) (named MyOp) that has neither inputs nor output ports.
Such an operator may accept input data from the outside (e.g., from a file) and produce output data (e.g., to a file) so that it acts as both the source and the sink operator.
Arguments to the operator (e.g., input/output file paths) can be passed as parameters as described in the section above.
We can add an operator to the workflow by calling add_operator (C++/Python) method in the compose() method.
The following code shows how to define a one-operator workflow in compose() method of the App class (assuming that the operator class MyOp is declared/defined in the same file).
class App : public holoscan::Application {
public:
void compose() override {
// Define Operators
auto my_op = make_operator<MyOp>("my_op");
// Define the workflow
add_operator(my_op);
}
};
class App(Application):
def compose(self):
# Define Operators
my_op = MyOp(self, name="my_op")
# Define the workflow
self.add_operator(my_op)
Linear Workflow
Here is an example workflow where the operators are connected linearly:

Fig. 13 A linear workflow
In this example, SourceOp produces a message and passes it to ProcessOp. ProcessOp produces another message and passes it to SinkOp.
We can connect two operators by calling the add_flow() method (C++/Python) in the compose() method.
The add_flow() method (C++/Python) takes the source operator, the destination operator, and the optional port name pairs.
The port name pair is used to connect the output port of the source operator to the input port of the destination operator.
The first element of the pair is the output port name of the upstream operator and the second element is the input port name of the downstream operator.
An empty port name (“”) can be used for specifying a port name if the operator has only one input/output port.
If there is only one output port in the upstream operator and only one input port in the downstream operator, the port pairs can be omitted.
The following code shows how to define a linear workflow in the compose() method of the App class (assuming that the operator classes SourceOp, ProcessOp, and SinkOp are declared/defined in the same file).
class App : public holoscan::Application {
public:
void compose() override {
// Define Operators
auto source = make_operator<SourceOp>("source");
auto process = make_operator<ProcessOp>("process");
auto sink = make_operator<SinkOp>("sink");
// Define the workflow
add_flow(source, process); // same as `add_flow(source, process, {{"output", "input"}});`
add_flow(process, sink); // same as `add_flow(process, sink, {{"", ""}});`
}
};
class App(Application):
def compose(self):
# Define Operators
source = SourceOp(self, name="source")
process = ProcessOp(self, name="process")
sink = SinkOp(self, name="sink")
# Define the workflow
self.add_flow(source, process) # same as `self.add_flow(source, process, {("output", "input")})`
self.add_flow(process, sink) # same as `self.add_flow(process, sink, {("", "")})`
Complex Workflow (Multiple Inputs and Outputs)
You can design a complex workflow like below where some operators have multi-inputs and/or multi-outputs:
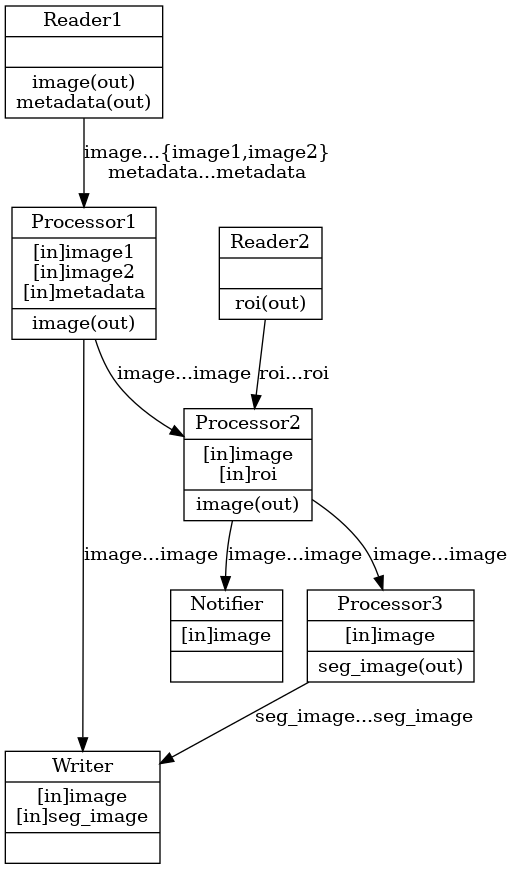
Fig. 14 A complex workflow (multiple inputs and outputs)
class App : public holoscan::Application {
public:
void compose() override {
// Define Operators
auto reader1 = make_operator<Reader1>("reader1");
auto reader2 = make_operator<Reader2>("reader2");
auto processor1 = make_operator<Processor1>("processor1");
auto processor2 = make_operator<Processor2>("processor2");
auto processor3 = make_operator<Processor3>("processor3");
auto writer = make_operator<Writer>("writer");
auto notifier = make_operator<Notifier>("notifier");
// Define the workflow
add_flow(reader1, processor1, {{"image", "image1"}, {"image", "image2"}, {"metadata", "metadata"}});
add_flow(reader1, processor1, {{"image", "image2"}});
add_flow(reader2, processor2, {{"roi", "roi"}});
add_flow(processor1, processor2, {{"image", "image"}});
add_flow(processor1, writer, {{"image", "image"}});
add_flow(processor2, notifier);
add_flow(processor2, processor3);
add_flow(processor3, writer, {{"seg_image", "seg_image"}});
}
};
class App(Application):
def compose(self):
# Define Operators
reader1 = Reader1Op(self, name="reader1")
reader2 = Reader2Op(self, name="reader2")
processor1 = Processor1Op(self, name="processor1")
processor2 = Processor2Op(self, name="processor2")
processor3 = Processor3Op(self, name="processor3")
notifier = NotifierOp(self, name="notifier")
writer = WriterOp(self, name="writer")
# Define the workflow
self.add_flow(reader1, processor1, {("image", "image1"), ("image", "image2"), ("metadata", "metadata")})
self.add_flow(reader2, processor2, {("roi", "roi")})
self.add_flow(processor1, processor2, {("image", "image")})
self.add_flow(processor1, writer, {("image", "image")})
self.add_flow(processor2, notifier)
self.add_flow(processor2, processor3)
self.add_flow(processor3, writer, {("seg_image", "seg_image")})
If there is a cycle in the graph with no implicit root operator, the root
operator is either the first operator in the first call to add_flow method (C++/Python), or the
operator in the first
call to add_operator method (C++/Python).
auto op1 = make_operator<...>("op1");
auto op2 = make_operator<...>("op2");
auto op3 = make_operator<...>("op3");
add_flow(op1, op2);
add_flow(op2, op3);
add_flow(op3, op1);
// There is no implicit root operator
// op1 is the root operator because op1 is the first operator in the first call to add_flow
If there is a cycle in the graph with an implicit root operator which has no input port, then the initialization and execution orders of the operators are still topologically sorted as far as possible until the cycle needs to be explicitly broken. An example is given below:

You can build your C++ application using CMake, by calling find_package(holoscan) in your CMakeLists.txt to load the SDK libraries. Your executable will need to link against:
holoscan::coreany operator defined outside your
main.cppwhich you wish to use in your app workflow, such as:SDK built-in operators under the
holoscan::opsnamespaceoperators created separately in your project with
add_libraryoperators imported externally using with
find_libraryorfind_package
Listing 1
# Your CMake project
cmake_minimum_required(VERSION 3.20)
project(my_project CXX)
# Finds the holoscan SDK
find_package(holoscan REQUIRED CONFIG PATHS "/opt/nvidia/holoscan")
# Create an executable for your application
add_executable(my_app main.cpp)
# Link your application against holoscan::core and any existing operators you'd like to use
target_link_libraries(my_app
PRIVATE
holoscan::core
holoscan::ops::<some_built_in_operator_target>
<some_other_operator_target>
<...>
)
This is also illustrated in all the examples:
in
CMakeLists.txtfor the SDK installation directory -/opt/nvidia/holoscan/examplesin
CMakeLists.min.txtfor the SDK source directory
Once your CMakeLists.txt is ready in <src_dir>, you can build in <build_dir> with the command line below. You can optionally pass Holoscan_ROOT if the SDK installation you’d like to use differs from the PATHS given to find_package(holoscan) above.
# Configure
cmake -S <src_dir> -B <build_dir> -D Holoscan_ROOT="/opt/nvidia/holoscan"
# Build
cmake --build <build_dir> -j
You can then run your application by running <build_dir>/my_app.
Python applications do not require building. Simply ensure that:
The
holoscanpython module is installed in yourdist-packagesor is listed under thePYTHONPATHenv variable so you can importholoscan.coreand any built-in operator you might need inholoscan.operators.Any external operators are available in modules in your
dist-packagesor contained inPYTHONPATH.
While python applications do not need to be built, they might depend on operators that wrap C++ operators. All python operators built-in in the SDK already ship with the python bindings pre-built. Follow this section if you are wrapping C++ operators yourself to use in your python application.
You can then run your application by running python3 my_app.py.
Given a CMake project, a pre-built executable, or a python application, you can also use the Holoscan CLI to package and run your Holoscan application in a OCI-compliant container image.
As of Holoscan v2.3 it is possible to send metadata alongside the data emitted from an operator’s output ports. This metadata can then be used and/or modified by any downstream operators. Currently this feature is only available for C++ applications, but will also be available to Python applications in a future release. The subsections below describe how this feature can be enabled and used.
Enabling application metadata
Currently the metadata feature is disabled by default and must be explicitly enabled as shown in the code block below
app = holoscan::make_application<MyApplication>();
// Enable metadata feature before calling app->run() or app->run_async()
app->is_metadata_enabled(true);
app->run();
Understanding Metadata Flow
Each operator in the workflow has an associated MetadataDictionary object. At the start of each operator’s compute() call this metadata dictionary will be empty (i.e. metadata does not persist from previous compute calls). When any call to receive data is made, any metadata also found in the input message will be merged into the operator’s local metadata dictionary. The operator’s compute method can then read, append to or remove metadata as explained in the next section. Whenever the operator emits data via a call to emit the current status of the operator’s metadata dictionary will be transmitted on that port alonside the data passed via the first argument to the emit call. Any downstream operators will then receive this metadata via their input ports.
Working With Metadata from Operator::compute
Within the operator’s compute() method, the metadata() method can be called to get a shared pointer to the MetadataDictionary of the operator. The metadata dictionary provides a similar API to a std::unordered_map (C++) where the keys are strings (std::string for C++) and the values can store any object type (via a C++ MetadataObject holding a std::any). Templated get() and set() method are provided as demonstrated below to allow directly setting values of a given type without having to explicitly work with the internal MetadataObject type.
// Receiving from a port updates operator metadata with any metadata found on the port
auto input_tensors = op_input.receive<TensorMap>("in");
// Get a reference to the shared metadata dictionary
auto& meta = metadata();
// Retrieve existing values.
// Use get<Type> to automatically cast the `std::any` contained within the `holsocan::Message`
auto name = meta->get<std::string>("patient_name");
auto age = meta->get<int>("age");
// Get also provides a two-argument version where a default value to be assigned is given by
// the second argument. The type of the default value should match the expected type of the value.
auto flag = meta->get("flag", false);
// Add a new value (if a key already exists, the value will be updated according to the
// operator's metadata_policy).
std::vector<float> spacing{1.0, 1.0, 3.0};
meta->set("pixel_spacing"s, spacing);
// Remove a value
meta->erase("patient_name")
// ... Some processing to produce output `data` could go here ...
// Current state of `meta` will automatically be emitted along with `data` in the call below
op_output.emit(data, "output1");
// Can clear all items
meta->clear();
// Any emit call after this point would not transmit a metadata object
op_output.emit(data, "output2");
See the MetadataDictionary API docs for all available methods. Most of these like begin() and end() iterators and the find() method match the corresponding methods of std::unordered_map.
Metadata Update Policies
The operator class also has a metadata_policy() method that can be used to set a MetadataPolicy() to use when handling duplicate metadata keys across multiple input ports of the operator. The available options are:
“update” (
MetadataPolicy::kUpdate): replace any existing key from a priorreceivecall with one present in a subsequentreceivecall.“reject” (
MetadataPolicy::kReject): Reject the new key/value pair when a key already exists due to a priorreceivecall.“raise” (
MetadataPolicy::kRaise): Throw astd::runtime_errorif a duplicate key is encountered. This is the default policy.
The metadata policy would typically be set during compose() as in the following example:
// Example for setting metadata policy from Application::compose()
my_op = make_operator<MyOperator>("my_op");
my_op->metadata_policy(holoscan::MetadataPolicy::kRaise);
The policy only applies to the operator on which it was set.
Use of Metadata in Distributed Applications
Sending metadata between two fragments of a distributed application is supported, but there are a couple of aspects to be aware of.
Sending metadata over the network requires serialization and deserialization of the metadata keys and values. The value types supported for this are the same as for data emitted over output ports (see the table in the section on object serialization). The only exception is that
TensorandTensorMap()values cannot be sent as metadata values between fragments. Any custom codecs registered for the SDK will automatically also be available for serialization of metadata values.There is a practical size limit of several kilobytes in the amount of metadata that can be transmitted between fragments. This is because metadata is currently sent along with other entity header information in the UCX header, which has fixed size limit (the metadata is stored along with other header information within the size limit defined by the
HOLOSCAN_UCX_SERIALIZATION_BUFFER_SIZEenvironment variable).
The above restrictions only apply to metadata sent between fragments. Within a fragment there is no size limit on metadata (aside from system memory limits) and no serialization or deserialization step is needed.
Current limitations
The current metadata API is only fully supported for native holoscan Operators and is not currently supported by operators that wrap a GXF codelet (i.e. inheriting from
GXFOperatoror created viaGXFCodeletOp). Aside fromGXFCodeletOp, the built-in operators provided under theholoscan::opsnamespace are all native operators, so the feature will work with these. Currently none of these built-in opereators add their own metadata, but any metadata received on input ports will automatically be passed on to their output ports (as long asapp->is_metadata_enabled(true)was set to enable the metadata feature).