High-Speed Fabric Management#
NVLink and NVLink Switch#
NVIDIA NVLink is a high-speed interconnect that allows multiple GPUs to communicate directly. In the past, the NVLink connections were limited to GPUs within a single node. With the addition of the NVLink Switch technology multi-node NVLink is now possible. This now allows multiple systems to interconnect over NVLink, using NVLink Switches, to form a large GPU and memory fabric within an NVLink Domain.
The NVIDIA GB200 NVL72 rack enables a 72 GPU NVLink Domain by default.This NVL72 NVLink Domain is set up as a single NVLink Partition. In other words, all GPUs in the NVL72 Domain have the potential to communicate with each other by default. In certain scenarios, a cluster administrator may need to create multiple NVLink Partitions within the NVL72 system. These are called User Partitions and they enable the ability to have multiple NVLink Partitions instead of one large Default Partition. This can provide a higher degree of multi-tenancy and isolation between workloads.
In most cases the Default Partition can be utilized, unless there are strong security requirements for certain workloads. IMEX and Slurm provide ways to dynamically split the NVLink Default Partition at job runtime and those will be discussed in more detail at the Slurm <provide link> section of this document.
It is worth noting that the connection between racks utilizes Infiniband but the connection within a rack will utilize NVLink.
NVLink definitions
Terms |
Description |
|---|---|
NVLink |
High speed link to enable GPU to GPU communication |
NVLink Partition |
A subset of GPUs within a hardware isolation boundary |
NVLink Domain |
A set of nodes that can communicate over NVLink |
Default Partition |
Allows all GPUs in an NVLink Domain to communicate |
User Partition |
An NVLink partition that is created and managed by an admin |
For more information about NVLink Partitioning, see: GB200 NVL Partition Guide.
NVLink Management Software (NMX)#
NVIDIA NVLink Management Software (NMX) is an integrated platform for managing and monitoring NVLink Switches, Domains, and Partitions.
It includes the following main components:
NMX-Telemetry (NMX-T)
NMX-Manager (NMX-M)
NMX-Controller (NNMX-C)
To manage NVLink Partitions gRCP, API calls are sent to the NMX Controller or by utilizing the NVOS CLI on the NVSwitch.
The base case is highlighted below, where we utilize the NVOS CLI on NVSWITCH-1. In this case, NVSWITCH-1 is theleader switch that runs NMX-C and NMX-T.
You can see the processes of the leader switch with the NVOS CLI and running nv show cluster app:
admin@a07-p1-nvsw-01-eth1.ipminet2.cluster:~$ nv show cluster app
Name ID Version Capabilities Components Version Status Reason Additional Information Summary
-------------- ------------- ---------------------- --------------------------------------------------- ---------------------------------------------------------------- ------ ------ ------------------------------ -------
nmx-controller nmx-c-nvos 1.0.0_2025-04-11_15-23 sm, gfm, fib, gw-api sm:2025.03.6, gfm:R570.133.15, fib-fe:1.0.1 ok CONTROL_PLANE_STATE_CONFIGURED
nmx-telemetry nmx-telemetry 1.0.4 nvl telemetry, gnmi aggregation, syslog aggregation nvl-telemetry:1.20.4, gnmi-aggregator:1.4.1, nmx-connector:1.4.1 ok
You can further check NVLink partition configuration:
admin@NVSWITCH-1:~$ nv show sdn partition
ID Name Num of GPUs Health Resiliency mode Multicast groups limit Partition type Summary
----- ----------------- ----------- ------- ------------------ ---------------------- -------------- -------
32766 Default Partition 72 healthy adaptive_bandwidth 1024 gpuuid_based
Additionally, here is a way to see available commands for creating or modifying partitions:
admin@NVSWITCH-1:~$ nv list-commands | grep partition
nv show sdn partition
nv show sdn partition <partition-id>
nv show sdn partition <partition-id> location
nv show sdn partition <partition-id> uuid
nv action boot-next system image (partition1|partition2)
nv action update sdn partition <partition-id> [reroute]
nv action update sdn partition <partition-id> location <location-id> [no-reroute]
nv action update sdn partition <partition-id> uuid <uuid> [no-reroute]
nv action create sdn partition <partition-id> [name <value>] [resiliency-mode (full_bandwidth|adaptive_bandwidth|user_action)] [mcast-limit (0-1024)] [location <location-id>] [uuid (0-18446744073709551615)]
nv action delete sdn partition <partition-id>
nv action restore sdn partition <partition-id> location <location-id> [no-reroute]
nv action restore sdn partition <partition-id> uuid <uuid> [no-reroute]
More details on managing NVLink Switches can be found within the NVOS and NMX docs on the NVLink Networking docs page.
NMX-M provides for centralized monitoring of NVSwitches providing a REST API endpoint and Prometheus scrape endpoint per rack. BCM also integrates into NMX-M and will collect a subset of metrics.
[a03-p1-head-01]% partition
[a03-p1-head-01->partition[base]]% nmxmsettings
[a03-p1-head-01->partition[base]->nmxmsettings]% show
Parameter Value
-------------------------------- ------------------------------------------------
Revision
Server 7.241.0.145
User name rw-user
Password ********
Port 443
Verify SSL no
CA certificate
Certificate
Private key
Prometheus metric forwarders <0 in submode>
An example of updating the Server and Password fields in nmxmsettings.
[a03-p1-head-01->partition[base]->nmxmsettings]% set Server 7.241.0.144
[a03-p1-head-01->partition*[base*]->nmxmsettings*]% set Password ********
[a03-p1-head-01->partition*[base*]->nmxmsettings*]% commit
BCM exposes the counts from NMX-M’s KPI endpoint as metrics
curl -sk https://localhost:8081/exporter | grep -Ev '# HELP|# TYPE' | grep -E '^nmxm' | cut -d '{' -f1 | sort -u
nmxm_chassis_count
nmxm_compute_allocation_count
nmxm_compute_health_count
nmxm_compute_nodes_count
nmxm_domain_health_count
nmxm_gpu_health_count
nmxm_gpus_count
nmxm_ports_count
nmxm_switch_health_count
nmxm_switch_nodes_count
for i in $(curl -sk https://localhost:8081/exporter | grep -Ev '# HELP|# TYPE' | grep -E '^nmxm' | cut -d '{' -f1 | sort -u); do curl -sk https://localhost:8081/exporter | grep -Ev '# HELP|# TYPE' | grep $i; done
nmxm_chassis_count{base_type="Partition",name="base"} 7
nmxm_compute_allocation_count{base_type="Partition",name="base",parameter="full"} 126
nmxm_compute_allocation_count{base_type="Partition",name="base",parameter="all"} 126
nmxm_compute_allocation_count{base_type="Partition",name="base",parameter="partial"} 0
nmxm_compute_allocation_count{base_type="Partition",name="base",parameter="free"} 54
nmxm_compute_health_count{base_type="Partition",name="base",parameter="unhealthy"} 1
nmxm_compute_health_count{base_type="Partition",name="base",parameter="unknown"} 0
nmxm_compute_health_count{base_type="Partition",name="base",parameter="healthy"} 122
nmxm_compute_health_count{base_type="Partition",name="base",parameter="degraded"} 0
nmxm_compute_nodes_count{base_type="Partition",name="base"} 123
nmxm_domain_health_count{base_type="Partition",name="base",parameter="unknown"} 0
nmxm_domain_health_count{base_type="Partition",name="base",parameter="unhealthy"} 0
nmxm_domain_health_count{base_type="Partition",name="base",parameter="healthy"} 7
nmxm_domain_health_count{base_type="Partition",name="base",parameter="degraded"} 0
nmxm_gpu_health_count{base_type="Partition",name="base",parameter="degraded"} 0
nmxm_gpu_health_count{base_type="Partition",name="base",parameter="unknown"} 0
nmxm_gpu_health_count{base_type="Partition",name="base",parameter="healthy"} 491
nmxm_gpu_health_count{base_type="Partition",name="base",parameter="nonvlink"} 1
nmxm_gpu_health_count{base_type="Partition",name="base",parameter="degraded_bw"} 0
nmxm_gpus_count{base_type="Partition",name="base"} 492
nmxm_ports_count{base_type="Partition",name="base"} 15552
nmxm_switch_health_count{base_type="Partition",name="base",parameter="missing_nvlink"} 54
nmxm_switch_health_count{base_type="Partition",name="base",parameter="unknown"} 0
nmxm_switch_health_count{base_type="Partition",name="base",parameter="healthy"} 72
nmxm_switch_health_count{base_type="Partition",name="base",parameter="unhealthy"} 0
nmxm_switch_nodes_count{base_type="Partition",name="base"} 63
These count metrics are categorized by the label parameter.
The following figure shows an example dashboard, using the Single Stat panel consuming these KPI metrics:

InfiniBand Fabrics#
The high-speed InfiniBand fabrics are managed with NVIDIA Unified Fabric Manager (UFM). UFM is a powerful platform for managing scale-out computing environments. UFM enables data center operators to efficiently monitor and operate the entire fabric, boost application performance, and maximize fabric resource utilization.
While other tools are device-oriented and involve manual processes, UFM automated and application-centric approach bridges the gap between servers, applications, and fabric elements, thus enabling administrators to manage and optimize from the smallest to the largest and most performance-demanding clusters.
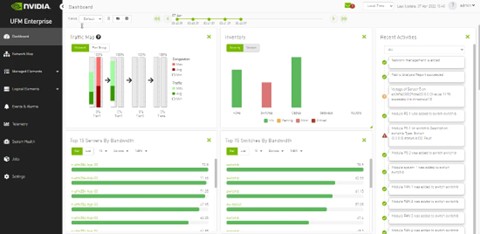
UFM Dashboard#
The following figure shows the dashboard window that summarizes the fabric’s status, including events, alarms, errors, traffic and statistics.
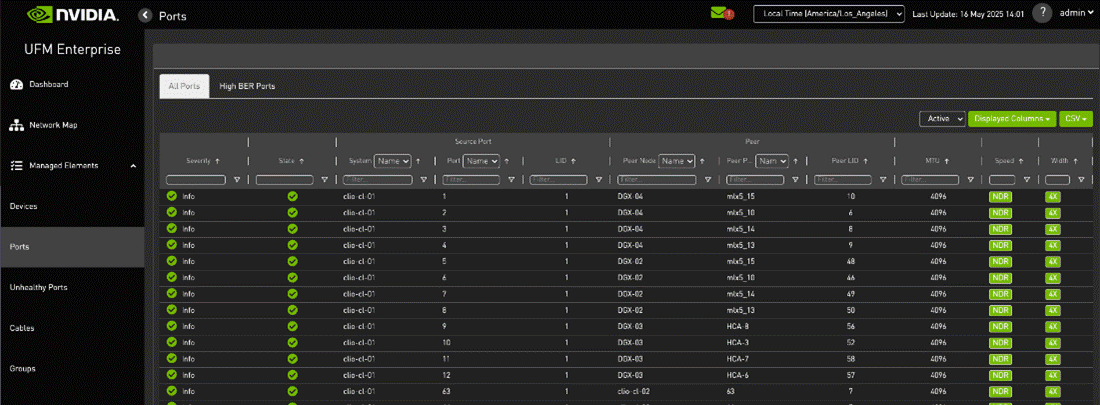
UFM InfiniBand Fabric Ports View#
The Ports view provides a list of all ports in the InfiniBand fabric and their speed, width, and status.
Verifying that UFM is Running#
To verify that UFM is running, use the following service ufmha status command:
ufm001# service ufmha status
ufmha status
========================================
Local Host
Server ufm001
Kernel 3.10.0-1127.19.1.el7.x86_64
IP Address 10.166.130.31
HA Interface bond0
DRBD Partition /dev/sda6
Heartbeat Master
Mysql Running
UFM Server Running
DRBD State Primary
DRBD Device State UpToDate
========================================
Remote Host
Server ufm002
Kernel 3.10.0-1127.19.1.el7.x86_64
IP Address 10.166.130.32
HA Interface bond0
DRBD Partition /dev/sda6
Heartbeat Slave
Mysql Stopped
UFM Server Stopped
DRBD State Secondary
DRBD Device State UpToDate
========================================
Virtual IP 10.166.130.58/24
Broadcast IP 10.166.130.255
========================================
For more information about UFM, see: http://nvidia.com/en-us/networking/infiniband/ufm/.