Evaluation Concepts#
NVIDIA NeMo Evaluator is a cloud-native microservice for evaluating large language models (LLMs), RAG pipelines, and AI agents at enterprise scale as part of the NeMo ecosystem. The service provides automated workflows for academic benchmarks (including LM Harness, BigCode, BFCL, Safety Harness, and Simple Evals), LLM-as-a-judge scoring, and specialized metrics for RAG and agent systems.
What is NeMo Evaluator?#
NeMo Evaluator enables real-time evaluations of your LLM applications through APIs, guiding developers and researchers in refining and optimizing LLMs for enhanced performance and real-world applicability. The NeMo Evaluator APIs can be seamlessly automated within development pipelines, enabling faster iterations without the need for live data. It is cost effective and suitable for pre-deployment checks and regression testing.
The development of Large Language Models (LLMs) has become pivotal in shaping intelligent applications across various domains. Enterprises today have a large number of LLMs to choose from and need a rigorous and systematic evaluation framework to choose the LLM that best suits their use case.
Evaluation Capabilities#
NVIDIA NeMo Evaluator supports evaluation of:
LLMs: Assess model performance using academic benchmarks, custom metrics, and LLM-as-a-Judge approaches
Retriever Pipelines: Measure document retrieval quality with metrics like Recall@K and NDCG@K
RAG Pipelines: Evaluate complete Retrieval Augmented Generation workflows including faithfulness, answer relevancy, and context precision
AI Agents: Test multi-step reasoning, tool use accuracy, topic adherence, and goal completion
For detailed information on evaluation types, refer to Evaluation Flows.
Architecture and Key Components#
NeMo Evaluator operates as a microservice within the NeMo platform and orchestrates evaluation workflows using several components:
Core Dependencies#
NeMo Data Store: Stores evaluation datasets, results, and artifacts
NeMo Entity Store: Manages evaluation targets, configs, and dataset metadata
PostgreSQL: Stores evaluation job metadata and status information
Optional Dependencies#
Milvus: Recommended for production Retriever and RAG pipeline evaluations (provides vector storage and similarity search). A local file-based fallback is available for development.
NIM (NVIDIA Inference Microservices): Provides model inference endpoints for evaluations
Workflow Orchestration#
When you submit an evaluation job, NeMo Evaluator:
Validates the target (model/pipeline/dataset to evaluate) and config (evaluation settings)
Retrieves datasets from NeMo Data Store or external sources
Executes the evaluation flow with specified metrics
Stores results and job artifacts back to NeMo Data Store
Updates job status and metadata
For deployment information, refer to NeMo Evaluator Deployment Guide.
Key Evaluation Concepts#
Understanding the following concepts is essential to using NeMo Evaluator effectively. The evaluation workflow centers around three core entities: Targets (what to evaluate), Configs (how to evaluate), and Jobs (the execution of an evaluation).
Why Separate Targets, Configs, and Jobs?#
This three-entity model provides:
Reusability: Evaluate one model with multiple evaluation strategies, or apply one evaluation config across many models
Flexibility: Mix and match targets and configs without recreating infrastructure
Tracking: Build model scorecards and track performance over time with consistent evaluation settings
Collaboration: Share evaluation configs across teams for standardized assessment practices
Evaluation Targets#
An evaluation target represents the subject of your evaluation—what you want to test or measure. Targets are reusable entities that can be evaluated multiple times with different configurations.
What is a Target?#
A target is a JSON object that defines:
Target Type: The category of the evaluation subject (
model,retriever,rag,cached_outputs,rows, ordataset)Endpoint Configuration: Connection details for models or pipelines
Authentication: API keys or credentials needed to access the target
Metadata: Namespace, name, and custom fields for organization
Target Types#
The following table summarizes the available target types:
Target Type |
Purpose |
Use Case |
|---|---|---|
|
Live model inference endpoints (NIM, OpenAI-compatible APIs) |
Real-time evaluation of LLMs |
|
Pre-generated model responses stored in NeMo Data Store |
Offline evaluation without re-running inference |
|
Embedding models for document retrieval with optional reranking |
Evaluate search and retrieval quality |
|
Complete RAG pipeline (embedding models + LLM endpoints) |
End-to-end RAG evaluation |
|
Inline JSON data |
Quick metric-only evaluations |
|
Reference to dataset in NeMo Data Store |
Metric-only evaluations on existing data |
For detailed target specifications and examples, refer to Create and Manage Evaluation Targets.
Target Reusability#
Targets are created once and stored in NeMo Entity Store. You can reference the same target across multiple evaluation jobs, making it easy to:
Compare different evaluation approaches on the same model
Build model scorecards with consistent targets
Track performance over time
Refer to Create and Manage Evaluation Targets for detailed information on creating and managing targets.
Evaluation Configs#
An evaluation config defines the methodology, metrics, and parameters for an evaluation. Configs are independent from targets, allowing you to test different evaluation strategies on the same target.
What is a Config?#
A config is a JSON object that specifies:
Evaluation Type: The flow or benchmark to run (such as
mmlu,gsm8k,custom,rag,retrieval)Tasks and Groups: Hierarchical structure of evaluation tasks
Metrics: Specific measurements to compute
Datasets: Data sources for the evaluation
Parameters: Runtime settings and behavior controls
Config Components#
Type (
type: string):Identifies the evaluation flow
Examples:
"lm-harness","custom","rag","retrieval","agentic"Pre-defined types use standard benchmarks
"custom"allows flexible, user-defined evaluations
Params (
params: object):Global parameters that apply to all tasks
Common parameters:
parallelism: Number of concurrent requests (default varies by evaluation type)request_timeout: Timeout for API calls (seconds)max_retries: Retry attempts for failed requestslimit_samples: Restrict dataset size for testingmax_new_tokens: Token limit for generationtemperature: Sampling temperature for LLMs
Flow-specific parameters in
extrafield
Tasks (
tasks: dict):Named evaluation tasks with individual configurations
Each task includes:
Task type (for academic benchmarks)
Dataset reference or inline data
Metrics to compute
Task-specific parameters
Example: Multiple MMLU subject evaluations as separate tasks
Groups (
groups: dict):Hierarchical organization of tasks
Aggregate metrics across related tasks
Example: Group all math-related tasks to compute an aggregate score
Metrics (
metrics: dict):Defined at task or group level
Metric types include:
Standard:
accuracy,f1_score,bleu,rougeSemantic:
semantic_similarity,faithfulnessRAG-specific:
answer_relevancy,context_precision,recall@kCustom:
llm_judgewith configurable prompts
Each metric can have parameters (judge models, thresholds, templates)
For a complete list of available metrics, refer to Evaluation Flows
Datasets (
dataset: object):Reference to evaluation data
Can be:
Standard benchmarks (
files_url: "file://mmlu/")Custom datasets in NeMo Data Store (
files_url: "hf://datasets/namespace/dataset-name")Inline dataset definitions
Format specification (JSONL, CSV, BEIR, RAGAS, etc.)
Config Reusability#
Like targets, configs are stored in NeMo Entity Store and reusable across jobs. You can:
Apply the same evaluation methodology to different models
Version configs as your evaluation requirements evolve
Share configs across teams for consistent evaluation standards
Refer to References for configuration schemas and examples.
Evaluation Jobs#
An evaluation job is the execution instance that combines a target and a config to perform an evaluation. Jobs orchestrate the end-to-end evaluation workflow from data loading to result storage.
What is a Job?#
A job is created by submitting a request that references:
Target (
target: string): Reference to a target bynamespace/nameConfig (
config: string): Reference to a config bynamespace/nameNamespace (
namespace: string): Organizational grouping for the job
When submitted, NeMo Evaluator assigns a unique job ID (for example, eval-1234ABCD5678EFGH) and begins orchestration.
Job Lifecycle#
When you submit an evaluation job, it progresses through the following phases:
Validation: Retrieves target and config from NeMo Entity Store, validates compatibility, and runs prechecks
Compilation: Submits the evaluation as a job orchestrated by the Jobs Microservice.
Execution: Loads datasets, performs inference (if needed), computes metrics, and tracks progress
Completion: Uploads results to NeMo Data Store and updates final job status
For detailed information on job execution and troubleshooting, refer to Run and Manage Evaluation Jobs.
Job Status#
Jobs progress through several states:
CREATED: Job created but not yet scheduledPENDING: Job accepted, waiting to startRUNNING: Actively executing evaluation tasksCOMPLETED: Successfully finished all tasksFAILED: Encountered an error during executionCANCELLING: Job is being cancelledCANCELLED: Manually stopped by user
Job Monitoring#
While a job runs, you can:
Query job status and progress percentage
View task-level status for multi-task evaluations
Access real-time logs (v2 API)
Track samples processed count
Job Results#
After completion, retrieve:
Metrics: Aggregated scores for each task and metric
Detailed Results: Per-sample outputs and scores
Logs: Execution logs for debugging
Metadata: Job configuration, timing, and resource usage
Target and Config Compatibility#
Not all target types work with all config types. For example:
Academic benchmark configs require model or cached_outputs targets
RAG configs require rag targets
Retrieval configs require retriever targets
Custom configs work with model, cached_outputs, rows, or dataset targets
Refer to Job Target and Configuration Matrix for compatibility details.
Refer to Run and Manage Evaluation Jobs for job submission and management.
NeMo Evaluator Use Cases#
The following table shows common use cases and their corresponding documentation:
Evaluation Focus |
Use Cases |
NeMo Evaluator Documentation |
|---|---|---|
Models |
|
|
Evaluations |
|
|
Data |
|
Integration with NeMo Microservices#
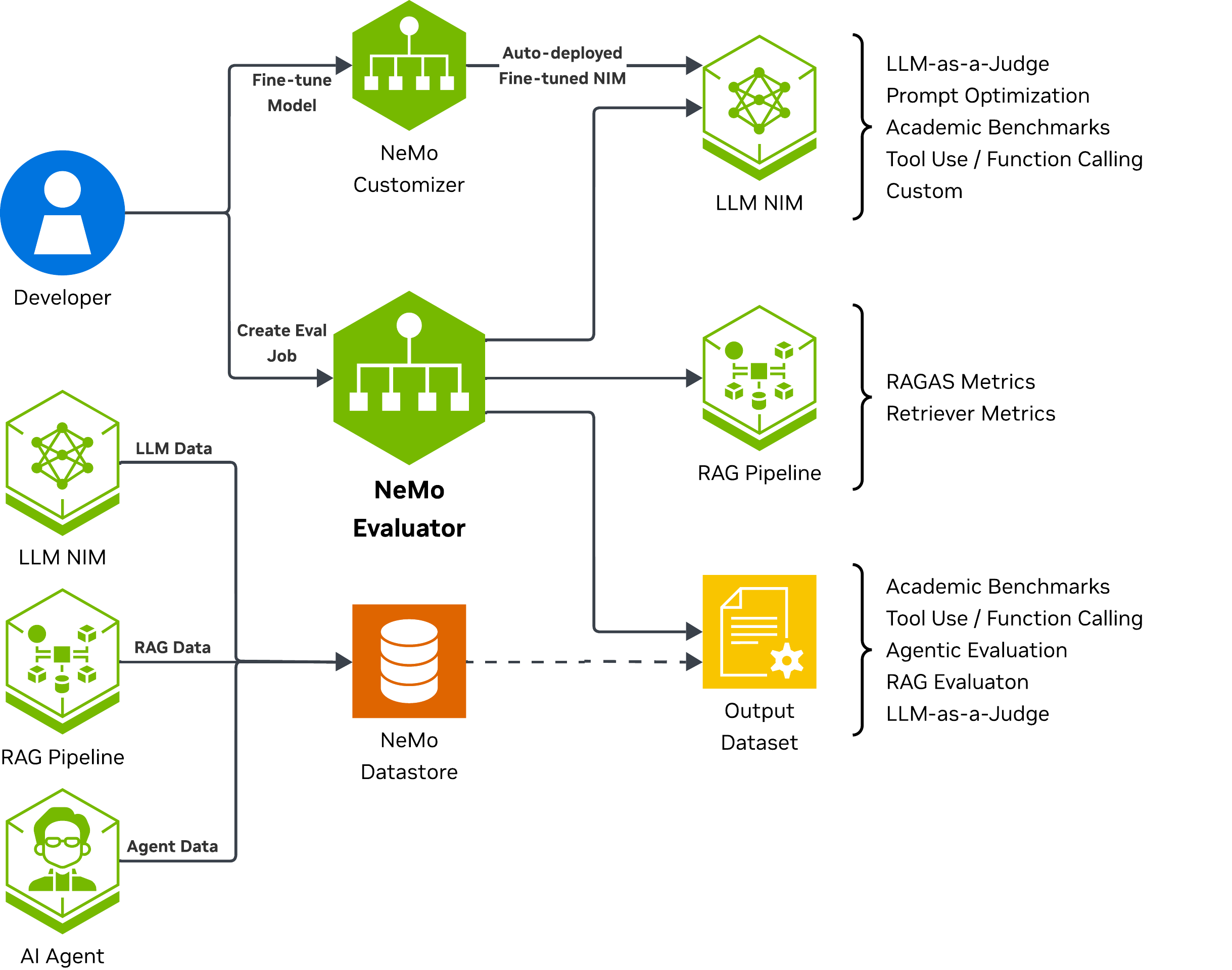
NeMo Evaluator integrates with other NeMo platform services to provide a complete evaluation solution:
NeMo Data Store: Stores datasets, evaluation results, and job artifacts
NeMo Entity Store: Manages metadata for datasets, models, targets, and configs
NIM: Provides model inference endpoints for LLM evaluations
NeMo Customizer: Can trigger evaluations before and after customization workflows
NeMo Guardrails: Evaluations can include guardrailed endpoints for safety assessments
The following diagram shows NeMo Evaluator’s interaction with other NeMo Microservices:
For information on the complete NeMo platform, refer to Overview of NeMo Microservices.