Optimize for Tokens/GPU Throughput#
Learn how to use the NeMo Microservices Customizer to create a LoRA (Low-Rank Adaptation) customization job optimized for higher tokens/GPU throughput and lower runtime. In this tutorial, we’ll use LoRA to fine-tune a model and leverage sequence packing feature to improve GPU utilization and decrease fine-tuning runtime.
Note
The time to complete this tutorial is approximately 30 minutes. In this tutorial, you run a customization job. Job duration increases with the number of model parameters and the dataset size.
Prerequisites#
Platform Prerequisites#
New to using NeMo microservices?
NeMo microservices use an entity management system to organize all resources—including datasets, models, and job artifacts—into namespaces and projects. Without setting up these organizational entities first, you cannot use the microservices.
If you’re new to the platform, complete these foundational tutorials first:
Get Started Tutorials: Learn how to deploy, customize, and evaluate models using the platform end-to-end
Set Up Organizational Entities: Learn how to create namespaces and projects to organize your work
If you’re already familiar with namespaces, projects, and how to upload datasets to the platform, you can proceed directly with this tutorial.
Learn more: Entity Concepts
NeMo Customizer Prerequisites#
Microservice Setup Requirements and Environment Variables
Before starting, make sure you have:
Access to NeMo Customizer
The
huggingface_hubPython package installed(Optional) Weights & Biases account and API key for enhanced visualization
Set up environment variables:
# Set up environment variables
export CUSTOMIZER_BASE_URL="<your-customizer-service-url>"
export ENTITY_HOST="<your-entity-store-url>"
export DS_HOST="<your-datastore-url>"
export NAMESPACE="default"
export DATASET_NAME="test-dataset"
# Hugging Face environment variables (for dataset/model file management)
export HF_ENDPOINT="${DS_HOST}/v1/hf"
export HF_TOKEN="dummy-unused-value" # Or your actual HF token
# Optional monitoring
export WANDB_API_KEY="<your-wandb-api-key>"
Replace the placeholder values with your actual service URLs and credentials.
Tutorial-Specific Prerequisites#
SQuAD dataset uploaded to NeMo MS Datastore and registered in NeMo MS Entity Store. Refer to the LoRA model customization tutorial for details how to upload and register the dataset.
Create LoRA Customization Jobs#
Important
The config field must include a version, for example: meta/llama-3.2-1b-instruct@v1.0.0+A100. Omitting the version will result in an error like:
{ "detail": "Version is not specified in the config URN: meta/llama-3.2-1b-instruct" }
You can find the correct config URN (with version) by inspecting the output of the /customization/configs endpoint. Use the name and version fields to construct the URN as name@version.
For this tutorial, you must create two LoRA customization jobs: one with sequence_packing_enabled set to true and another with the same field set to false.
Tip
For enhanced visualization, it’s recommended to provide a WandB API key in the wandb-api-key HTTP header. Remove wandb-api-key from the request if the WANDB_API_KEY is not set.
Create the customization job with sequence packing enabled:
from nemo_microservices import NeMoMicroservices import os # Initialize the client client = NeMoMicroservices( base_url=os.environ['CUSTOMIZER_BASE_URL'] )
# Set up WandB API key for enhanced visualization extra_headers = {} if os.getenv('WANDB_API_KEY'): extra_headers['wandb-api-key'] = os.getenv('WANDB_API_KEY')
# Create a customization job with sequence packing enabled job_packed = client.customization.jobs.create( config="meta/llama-3.2-1b-instruct@v1.0.0+A100", dataset={ "namespace": "<namespace>", "name": "test-dataset" }, hyperparameters={ "sequence_packing_enabled": True, "training_type": "sft", "finetuning_type": "lora", "epochs": 10, "batch_size": 16, "learning_rate": 0.00001, "lora": { "adapter_dim": 16 } }, extra_headers=extra_headers ) print(f"Created job with sequence packing enabled:") print(f" Job ID: {job_packed.id}") print(f" Status: {job_packed.status}") print(f" Output model: {job_packed.output_model}") # Save the job ID for monitoring packed_job_id = job_packed.id
export WANDB_API_KEY=<YOUR_WANDB_API_KEY> curl --location \ "https://${CUSTOMIZER_BASE_URL}/v1/customization/jobs" \ --header "wandb-api-key: ${WANDB_API_KEY}" \ --header 'Accept: application/json' \ --header 'Content-Type: application/json' \ --data '{ "config": "meta/llama-3.2-1b-instruct@v1.0.0+A100", "dataset": { "namespace": "<namespace>", "name": "test-dataset" }, "hyperparameters": { "sequence_packing_enabled": true, "training_type": "sft", "finetuning_type": "lora", "epochs": 10, "batch_size": 16, "learning_rate": 0.00001, "lora": { "adapter_dim": 16 } } }' | jq
Note the
customization_id. It will be needed later.Create another customization job with sequence packing disabled:
from nemo_microservices import NeMoMicroservices import os # Initialize the client client = NeMoMicroservices( base_url=os.environ['CUSTOMIZER_BASE_URL'] )
# Set up WandB API key for enhanced visualization extra_headers = {} if os.getenv('WANDB_API_KEY'): extra_headers['wandb-api-key'] = os.getenv('WANDB_API_KEY')
# Create a customization job with sequence packing disabled job_unpacked = client.customization.jobs.create( config="meta/llama-3.2-1b-instruct@v1.0.0+A100", dataset={ "namespace": "<namespace>", "name": "test-dataset" }, hyperparameters={ "sequence_packing_enabled": False, "training_type": "sft", "finetuning_type": "lora", "epochs": 10, "batch_size": 16, "learning_rate": 0.00001, "lora": { "adapter_dim": 16 } }, extra_headers=extra_headers ) print(f"Created job with sequence packing disabled:") print(f" Job ID: {job_unpacked.id}") print(f" Status: {job_unpacked.status}") print(f" Output model: {job_unpacked.output_model}") # Save the job ID for monitoring unpacked_job_id = job_unpacked.id
export WANDB_API_KEY=<YOUR_WANDB_API_KEY> curl --location \ "https://${CUSTOMIZER_BASE_URL}/v1/customization/jobs" \ --header "wandb-api-key: ${WANDB_API_KEY}" \ --header 'Accept: application/json' \ --header 'Content-Type: application/json' \ --data '{ "config": "meta/llama-3.2-1b-instruct@v1.0.0+A100", "dataset": { "namespace": "<namespace>", "name": "test-dataset" }, "hyperparameters": { "sequence_packing_enabled": false, "training_type": "sft", "finetuning_type": "lora", "epochs": 10, "batch_size": 16, "learning_rate": 0.00001, "lora": { "adapter_dim": 16 } } }' | jq
Note the
customization_id. It will be needed later.
Monitor LoRA Customization Jobs#
Use the customization_id from each job to make a GET request for status details.
# Monitor both jobs
def monitor_jobs(packed_job_id, unpacked_job_id):
# Get status for sequence packing enabled job
packed_status = client.customization.jobs.status(packed_job_id)
print(f"Sequence Packing Enabled Job ({packed_job_id}):")
print(f" Status: {packed_status.status}")
print(f" Progress: {packed_status.status_details.percentage_done}%")
print(f" Epochs completed: {packed_status.status_details.epochs_completed}")
# Get status for sequence packing disabled job
unpacked_status = client.customization.jobs.status(unpacked_job_id)
print(f"\nSequence Packing Disabled Job ({unpacked_job_id}):")
print(f" Status: {unpacked_status.status}")
print(f" Progress: {unpacked_status.status_details.percentage_done}%")
print(f" Epochs completed: {unpacked_status.status_details.epochs_completed}")
# Compare training metrics if available
if (packed_status.status_details.metrics and
unpacked_status.status_details.metrics):
packed_metrics = packed_status.status_details.metrics.metrics
unpacked_metrics = unpacked_status.status_details.metrics.metrics
print(f"\nTraining Metrics Comparison:")
if packed_metrics.get("val_loss") and unpacked_metrics.get("val_loss"):
packed_val_loss = packed_metrics["val_loss"][-1] if packed_metrics["val_loss"] else None
unpacked_val_loss = unpacked_metrics["val_loss"][-1] if unpacked_metrics["val_loss"] else None
print(f" Packed Val Loss: {packed_val_loss}")
print(f" Unpacked Val Loss: {unpacked_val_loss}")
# Usage example (replace with your actual job IDs)
monitor_jobs("your-packed-job-id", "your-unpacked-job-id")
curl ${CUSTOMIZER_BASE_URL}/v1/customization/jobs/${customizationID}/status | jq
The response includes timestamped training and validation loss values. The expected validation loss for both jobs should be similar.
View Jobs in Weights & Biases#
To enable W&B integration, include your WandB API key when creating a customization job in the call header.
Then view your results at wandb.ai under the nvidia-nemo-customizer project.
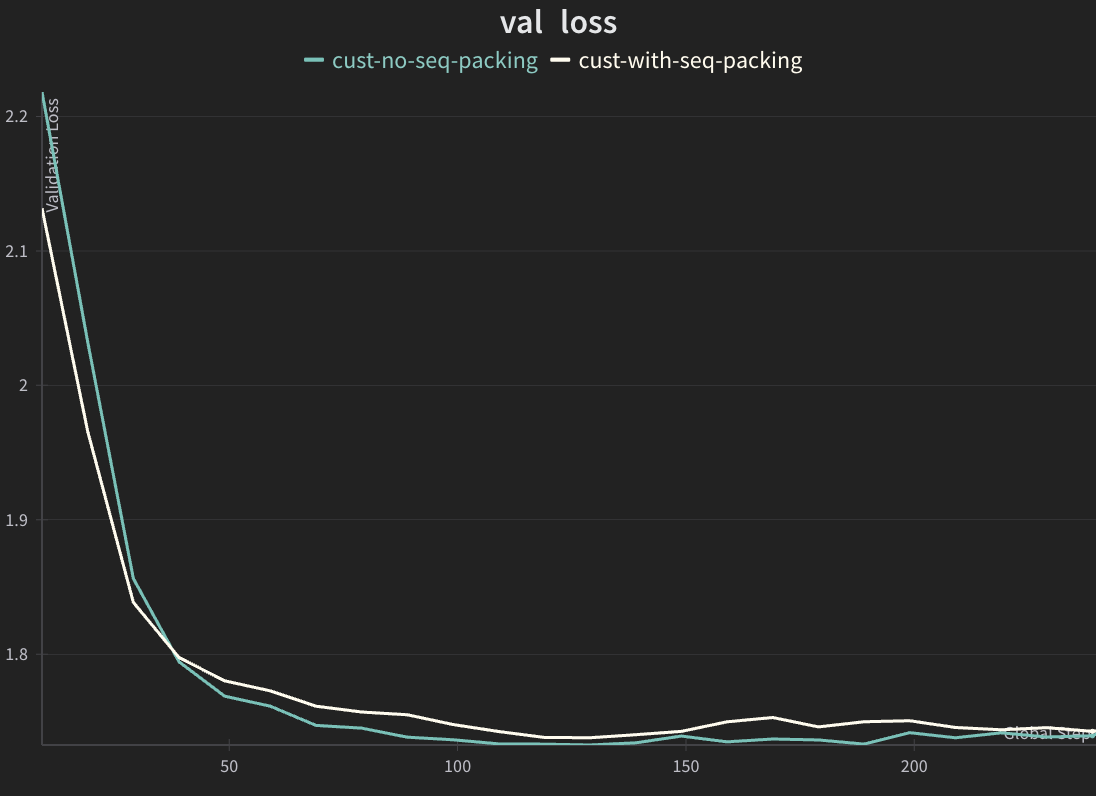
Validation Loss Curves#
The expected validation loss curves should match closely for both jobs.
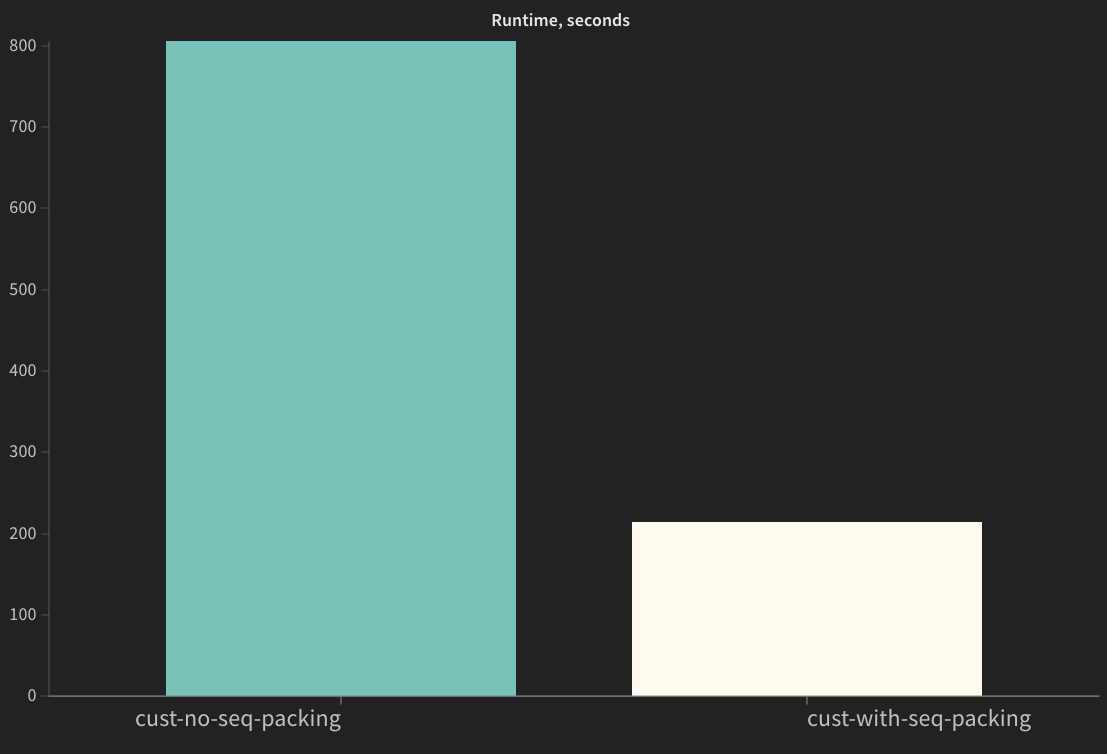
Sequence packed version should complete significantly faster.
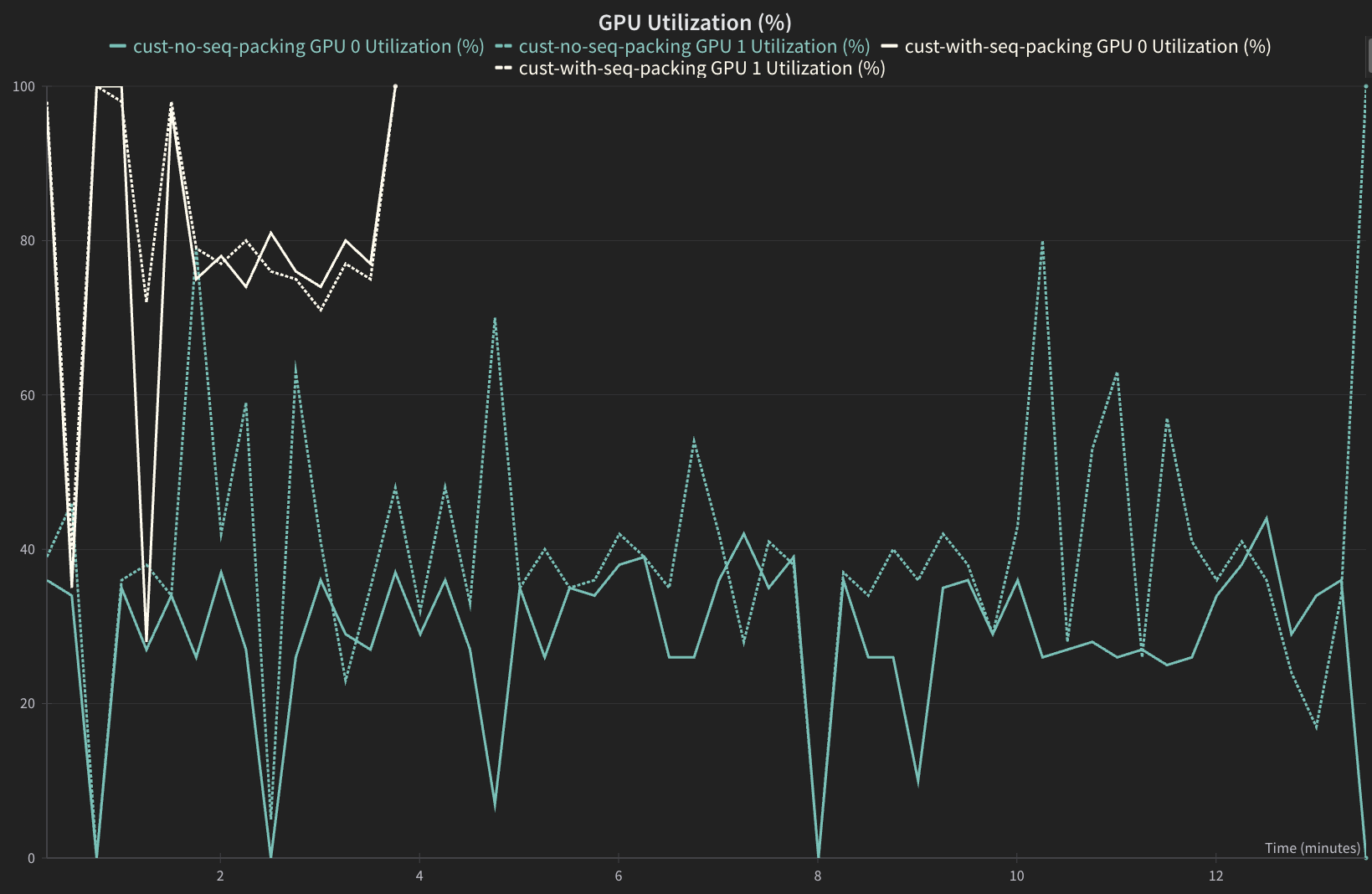
GPU Utilization#
Sequence packed version should have a higher GPU utilization.
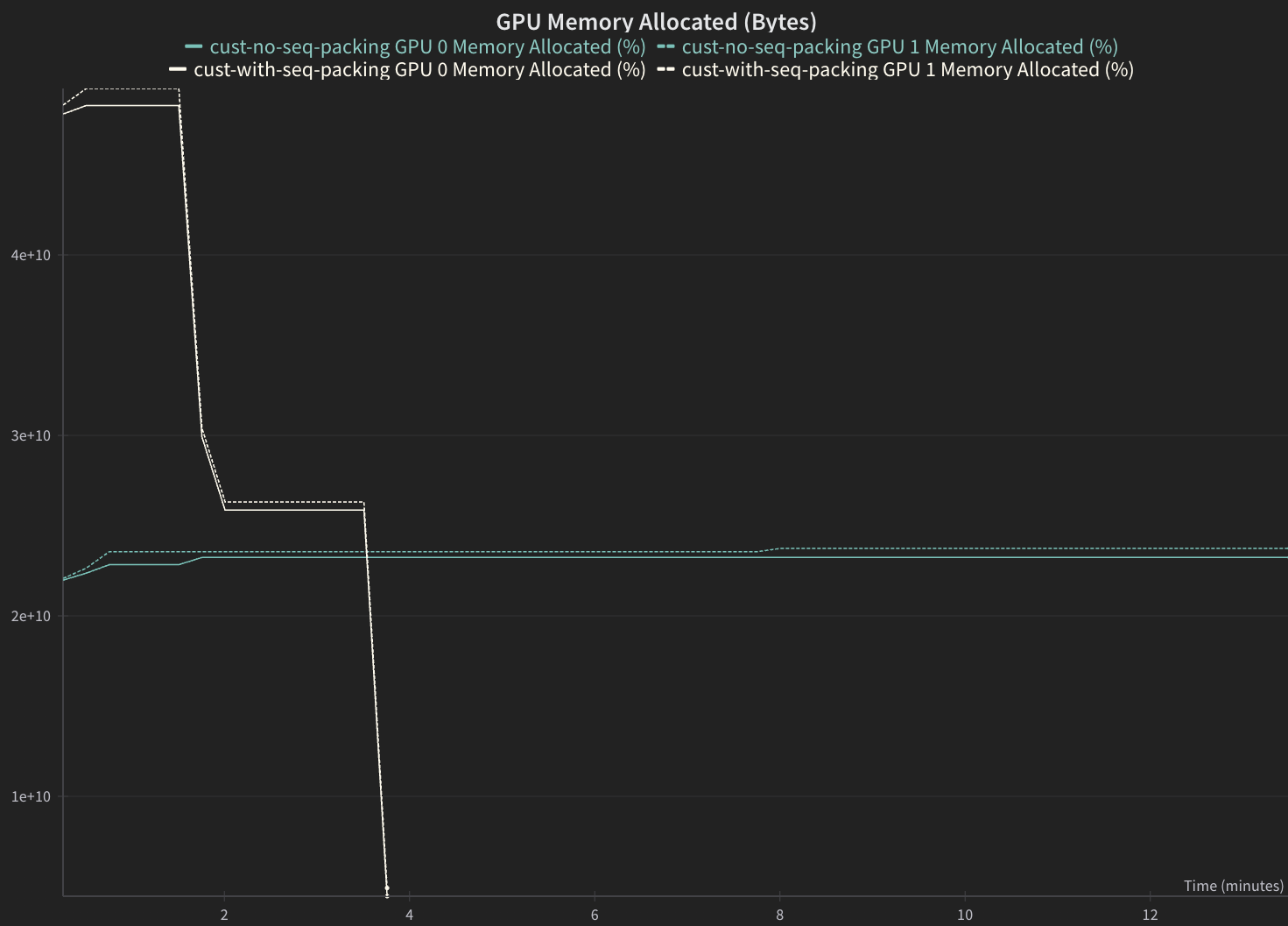
GPU Memory Allocation#
Sequence packed version should have a higher GPU Memory Allocation.
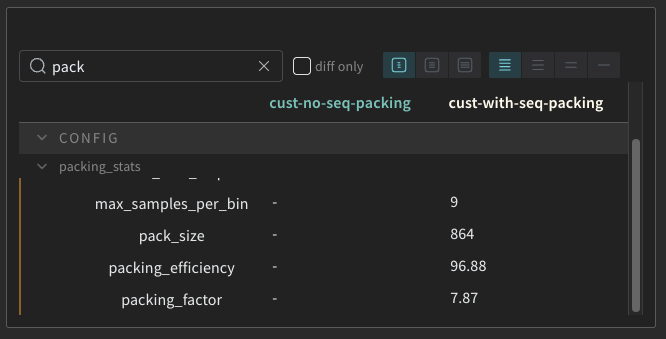
Sequence Packing Statistics#
Sequence packing statistics can be found under run config.
Note
The W&B integration is optional. When enabled, we’ll send training metrics to W&B using your API key. While we encrypt your API key and don’t log it internally, please review W&B’s terms of service before use.
Next Steps#
Learn how to check customization job metrics to monitor training progress and compare performance between your sequence-packed and regular jobs. You can also evaluate the output using NeMo Microservices Evaluator.