Model Architectures#
PhysicsNeMo, built on PyTorch, offers flexibility for developers to create and train any model architecture. The following classes of fine-tuned and optimized model architecture blocks, such as transformer layers and GNN layers, serve as off the shelf building blocks for developers to configure and develop their proprietary custom models. Additionally, PhysicsNeMo provides a library of application-specific training recipes that utilize these model architectures for various use cases. They serve as reference implementations for end-to-end training pipelines using a specific architecture for a particular use case.
Graph Neural Networks#
NVIDIA PhysicsNeMo has extensive and versatile support for Graph Neural Networks (GNNs) across a wide range of physics simulations, from fluid dynamics and structural mechanics to large-scale weather forecasting. The framework leverages GNNs primarily for their ability to operate on unstructured or irregular meshes, a significant advantage over grid-based models like CNNs. It provides robust support for state-of-the-art GNN architectures like MeshGraphNet and GraphCast. These models are applied to a diverse set of problems, showcasing their strength in handling irregular meshes, particle-based systems, transient dynamics, and large-scale distributed computing.

Fig. 1 Graph partitioning and halo regions for handling massive graphs in PhysicsNeMo#
GNN Training recipes |
Architecture |
Key Features |
|---|---|---|
Time-dependent simulation on an irregular 2D mesh
|
MeshGraphNet |
Data structures: Loads time-series data from TFRecord files.
Scaling: Training scales on multiple GPUs/nodes (DDP).
|
Solves the shallow water equations on a sphere
|
GraphCast |
Data structures: On the fly data generation, on an icosahedral mesh.
Scaling: Distributed message passing.
|
Predicts surface forces on automotive geometries.
|
X-MeshGraphNet |
Multi-scale extension of MeshGraphNet by partitioning large graphs and incorporating halo regions.
Data structures: Constructs custom graphs directly from tessellated geometry using point clouds and k-nearest neighbors. Additionally, the model builds multi-scale graphs.
Scaling: scaling to meshes of size 100 million cells or more.
|
Simulates a deforming plate with varying geometries and boundary conditions.
|
Hybrid MeshGraphNet |
Data structures: Utilizes a heterogeneous graph with multiple edge types to handle complex boundary conditions.
Scaling: Training runs on multiple GPUs/nodes (DDP).
|
Models particle-based systems like fluids or granular materials.
|
MeshGraphNet |
Data structures: Handles point-cloud-like data where the connectivity between nodes (particles) can change over time.
Scaling: Training runs on multiple GPUs/nodes (DDP).
|
Global weather prediction for up to 10 days.
|
GraphCast |
Transient, auto-regressive approach
Data structures: Multi-scale icosahedral mesh.
Scaling: Multi-GPU (DDP)
Perf: Gradient checkpointing, concatenation trick, fused SiLU, multi-step rollout.
|
For a detailed tutorial on Mesh Graph Networks in PhysicsNeMo, refer to MeshGraphNet: A Practical User Tutorial.
Transformers#
NVIDIA PhysicsNeMo supports numerous transformer-based neural networks that are well adapted for physics-ML and scientific computing applications. One major such model is named Transolver, designed for simulating complex physics problems like external aerodynamics in CFD. This represents a cutting-edge approach that moves beyond traditional CNNs or GNNs and leverages PhysicsNeMo’s support for using sophisticated transformer layers to build powerful surrogate models.
Transformers are superior at modeling the long-range interactions that are crucial in many physics problems, particularly in fluid dynamics. By treating the input as an unordered set of points, these models can be more flexible with complex geometries than grid-based models like CNNs. When applied to problems with more regular meshes, transformers can often provide substantial accuracy and efficiency improvements by exploiting locality of the physics and applying attention within local neighborhoods. PhysicsNeMo offers several optimized training recipes for transformer architectures at scale.
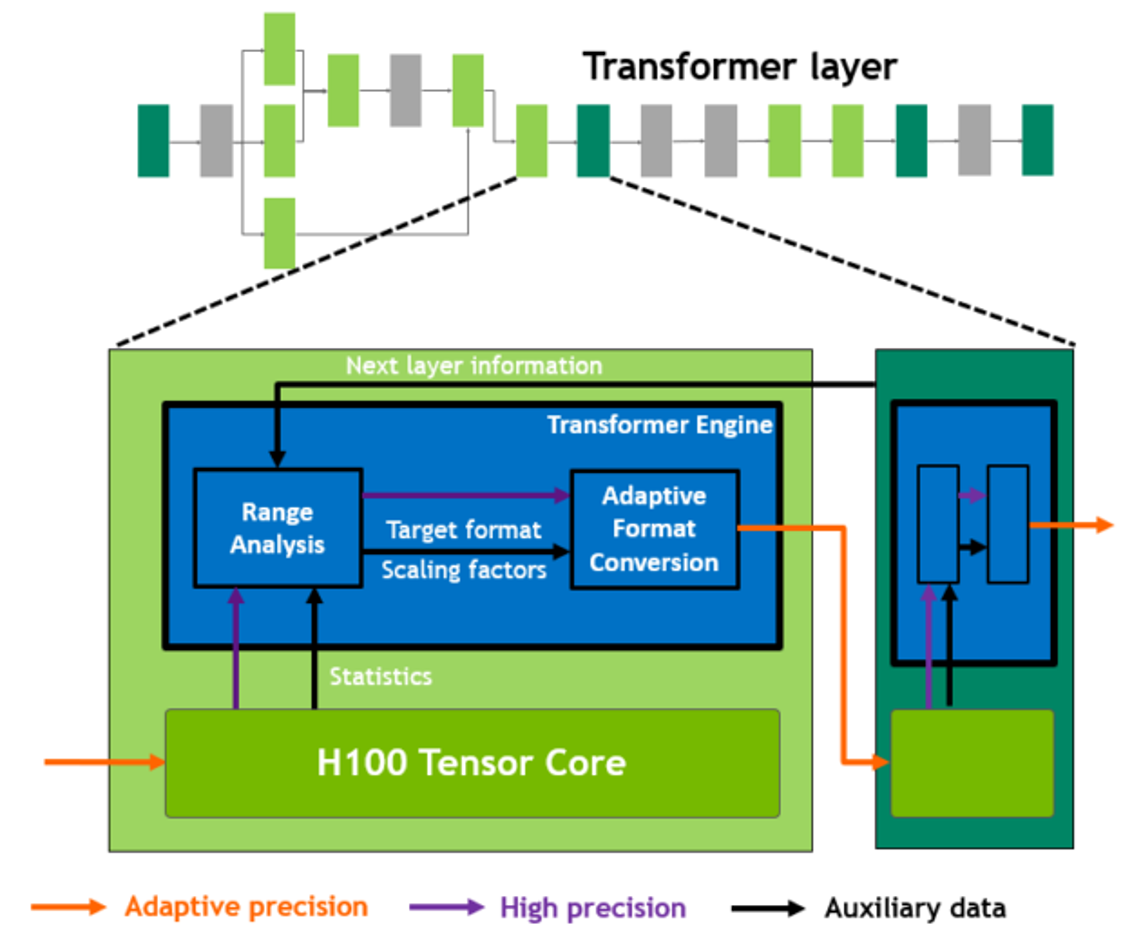
Fig. 2 Optimizing for Tensor cores using Transformer Engine in PhysicsNeMo#
In addition to the following recipes that use the transformer architecture, there are other recipes that use certain transformer layers like self-attention in weather forecasting (Graphcast), weather diagnostic models (AFNO), and many of the diffusion models (See below). The Diffusion Transformer backbone in particular is designed to be modular and extensible, including support for custom attention, tokenization, and de-tokenization backends defined by you.
Transformer Training Recipes |
Architecture |
Key Features |
|---|---|---|
Predict surface forces on automotive geometries
|
Transolver |
Data structures: Irregular Mesh - Applies PhysicsAttention to surface mesh data and on-the-fly signed distance field values
Scaling: Multi-GPU (DDP), Domain Parallel
Perf: With Transformer Engine, gives 25% speedup for large models.
Supports training and inference in fp8 on latest NVIDIA GPUs.
|
Transolver |
Data structures: 2D image data
Scaling: Multi-GPU (DDP)
|
|
Solving 2D Naiver-Stokes equation
|
DPOT |
Data structures: Uses spectral fourier attention to build a PDE Foundation Model.
Scaling: Single GPU, multi-gpu support coming.
|
Neural Operators#
Neural operators are a class of deep learning models designed to learn mappings between infinite-dimensional function spaces. In engineering and science, this means they learn to solve entire families of Partial Differential Equations (PDEs), making them powerful, mesh-independent tools for accelerating physical simulations. Most prominent neural operator architectures include Fourier Neural Operator (FNO), Deep Operator Network (DeepONet) and variants like Physics informed FNO (PINO). More recent innovations have led to DoMINO (Decomposable Multi-scale Iterative Neural Operator) that have shown remarkable generalizability for various domains. SciML developers can use all of these architectures out-of-the box, ready to scale for enterprise scale AI model development.
Neural Operator Training Recipes |
Architecture |
Key Features |
|---|---|---|
FNO |
Physics-informed extension of FNO using Spectral and Finite Difference gradients
Data structures: 2D structured grid
Scaling: Multi-GPU (DDP)
|
|
Predict surface and volume fields on automotive geometries
|
DoMINO |
First of its kind, multiscale neural operator
Data structures: point cloud sampled from the CAD model, builds local stencils that alleviate the need for a simulation mesh
Scaling: Multi-GPU (DDP), Domain Parallel
Perf: Tight integration with custom warp kernels enables point-cloud to point-cloud spatial projection, with over 10x better end-to-end performance than brute force methods in PyTorch.
|
SFNO |
Data structures: N-D Tensor on structured grid (Lat Long)
Scaling: Spatial model parallelism splits both the model and the data onto multiple GPUs
Perf: various optimization (automatic mixed precision, activation checkpointing) to fit into GPU memory
|
|
DeepONet (FNO for branch net and fully connected for trunk net) |
Physics-informed using Automatic Differentiation
Data structures: 2D structured tensors. The Fully-Connected component also allows random unstructured sampling
Scaling: Single GPU
|
Diffusion Models#
NVIDIA PhysicsNeMo provides broad support for state-of-the-art diffusion techniques across multiple scientific areas, including computational fluid dynamics (CFD), weather and climate, geophysics, and generative design. It offers ready-to-use diffusion model backbones that can be used directly or combined with the framework’s accompanying utilities—such as samplers, loss functions, and pre-conditioners—to build complete diffusion workflows without starting from scratch. Backbones include typical U-Net variants used in EDM/ADM diffusion papers, and a Diffusion Transformer backbone that allows for deeper customization through support of multiple attention, tokenization, and de-tokenization backends including custom Modules defined by you.
This combination of core architectures and supporting tools makes diffusion a practical and flexible approach for tackling ill-posed inverse problems, enabling applications such as super-resolution, downscaling, and direct geometry synthesis.
Fig. 3 EDM sampler available in PhysicsNeMo#
Diffusion Model Training Recipes |
Architecture |
Key Features |
|---|---|---|
Emulate a convection-allowing model at a few kilometers resolution
|
Diffusion UNet |
Sampler: EDM
Data Structures: N-D Tensor on structured grid (Lat Long)
Scale: Multi-GPU (DDP)
Perf: U-Net architecture optimized for compilation with fused operations, uses Apex Group Norm, bf16 AMP
|
Generate Km scale weather predictions from coarse simulation
|
Diffusion UNet |
Sampler: EDM
Data Structures: N-D Tensor on structured grid (Lat Long)
Scale: Multi-GPU (DDP), Can be scaled to very large domains (> 2000x2000 pixels) with multi-diffusion
Perf: architecture optimized for compilation with fused operations, uses Apex Group Norm, bf16 AMP. Training supports gradient accumulation and patch-wise gradient accumulation (for muli-diffusion settings)
|
Reconstructing subsurface velocity model from recorded seismic waveform
|
Diffusion UNet + Global Filter Network |
Sampler: EDM with physics-informed Diffusion Posterior Sampling (DPS)
Data Structures: 2D structured data (subsurface model) + unstructured set of N channels of 1D data (seismic observations)
Scale: Multi-GPU (DDP)
Perf: architectures partially optimized for compilation with fused ops, uses Apex GN and fused Adam optimizer
|
Showcases diffusion models to generate new, unique topologies that satisfy specific engineering constraints
|
Diffusion UNet + custom UNet encoder |
Sampler: Custom DDPM with Diffusion Posterior Sampling (DPS)
Data Structures: 2D data on structured grid.
Scaling: Single GPU
|
Voxel based models#
Voxel-based models are a class of deep learning models that predict the results of CAE simulations by treating the 3D physical domain as a regular grid of “3D pixels” or voxels. This approach transforms mesh-based physics problem into a 3D image processing task, which is ideal for leveraging the power of Convolutional Neural Networks (CNNs). This approach allows engineers to apply powerful and highly optimized computer vision architectures, like the U-Net, directly to complex physics problems. U-Net is the most prominent and effective architecture and it uses an encoder-decoder structure with skip connections to efficiently capture geometric features at multiple scales and reconstruct a detailed output field.
PhysicsNeMo provides a set of optimized U-Net backbones that can be used for developing custom proprietary models. Refer to the diffusion models section where U-Net is also used heavily and below are a list of other key U-Net based training recipes and their key features:
Voxel Based Model Training Recipes |
Architecture |
Key Features |
|---|---|---|
Thermal and airflow surrogate model for Datacenter design
|
3D UNet |
Physics-informed using Finite differences
Data structures: Structured 3D grids representing volume fields
Scale: Multi-GPU (DDP)
|
Predict surface forces on automotive geometries
|
FigConvUNet |
Data structures: point cloud sampled from the 3D CAD model or the simulation mesh.
Scaling: Multi-GPU (DDP)
Perf: Supports AMP (fp16/bf16)
|
Predict evolution of 3D Gray Scott system given the initial condition
|
Diffusion UNet + Global Filter Network |
RNN + UNet
Data structures: 4D data (time dimension and 3 dimensions representing volume fields on structured grids)
Scaling: Single GPU
|