NVIDIA DALI Documentation#
The NVIDIA Data Loading Library (DALI) is a GPU-accelerated library for data loading and pre-processing to accelerate deep learning applications. It provides a collection of highly optimized building blocks for loading and processing image, video and audio data. It can be used as a portable drop-in replacement for built in data loaders and data iterators in popular deep learning frameworks.
Deep learning applications require complex, multi-stage data processing pipelines that include loading, decoding, cropping, resizing, and many other augmentations. These data processing pipelines, which are currently executed on the CPU, have become a bottleneck, limiting the performance and scalability of training and inference.
DALI addresses the problem of the CPU bottleneck by offloading data preprocessing to the GPU. Additionally, DALI relies on its own execution engine, built to maximize the throughput of the input pipeline. Features such as prefetching, parallel execution, and batch processing are handled transparently for the user.
In addition, the deep learning frameworks have multiple data pre-processing implementations, resulting in challenges such as portability of training and inference workflows, and code maintainability. Data processing pipelines implemented using DALI are portable because they can easily be retargeted to TensorFlow, PyTorch, and PaddlePaddle.
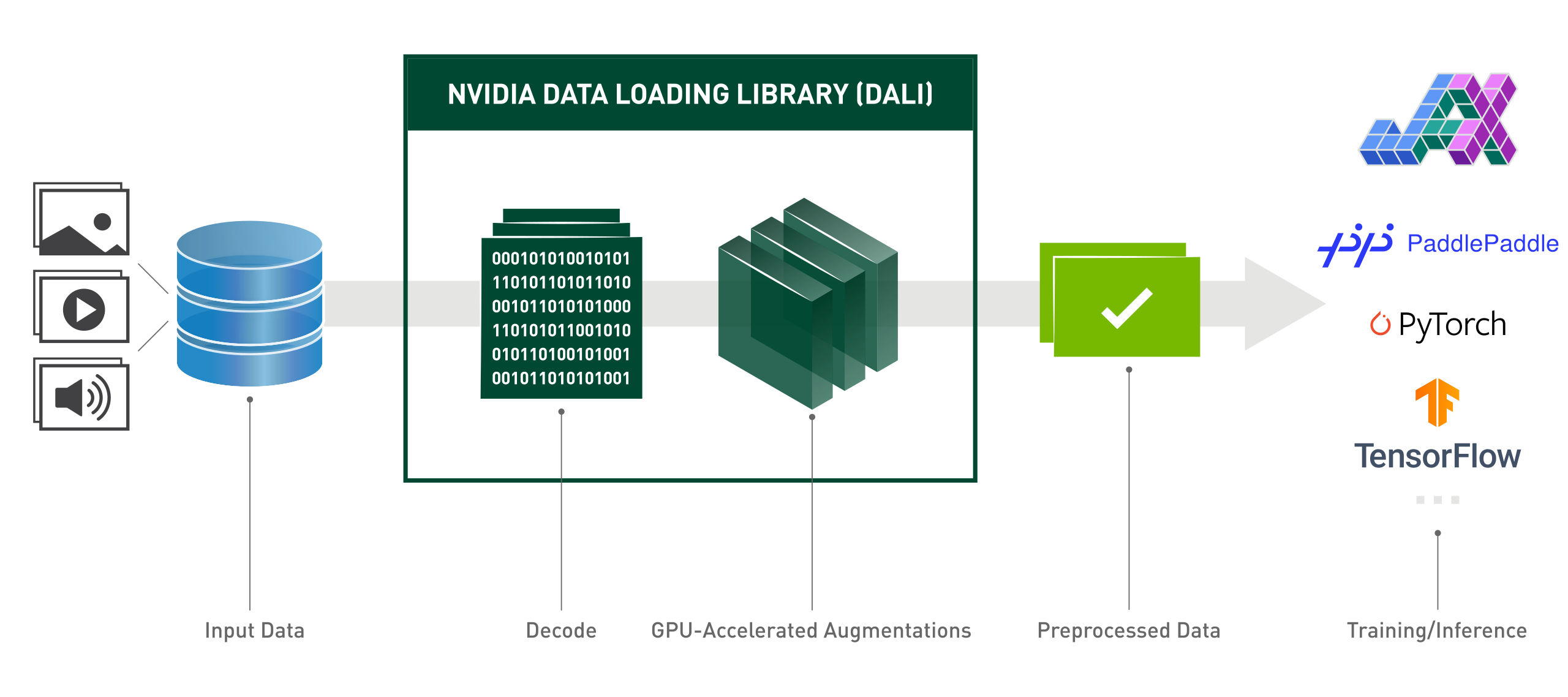
DALI in action:
from nvidia.dali.pipeline import pipeline_def
import nvidia.dali.types as types
import nvidia.dali.fn as fn
from nvidia.dali.plugin.pytorch import DALIGenericIterator
import os
# To run with different data, see documentation of nvidia.dali.fn.readers.file
# points to https://github.com/NVIDIA/DALI_extra
data_root_dir = os.environ['DALI_EXTRA_PATH']
images_dir = os.path.join(data_root_dir, 'db', 'single', 'jpeg')
def loss_func(pred, y):
pass
def model(x):
pass
def backward(loss, model):
pass
@pipeline_def(num_threads=4, device_id=0)
def get_dali_pipeline():
images, labels = fn.readers.file(
file_root=images_dir, random_shuffle=True, name="Reader")
# decode data on the GPU
images = fn.decoders.image_random_crop(
images, device="mixed", output_type=types.RGB)
# the rest of processing happens on the GPU as well
images = fn.resize(images, resize_x=256, resize_y=256)
images = fn.crop_mirror_normalize(
images,
crop_h=224,
crop_w=224,
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255],
mirror=fn.random.coin_flip())
return images, labels
train_data = DALIGenericIterator(
[get_dali_pipeline(batch_size=16)],
['data', 'label'],
reader_name='Reader'
)
for i, data in enumerate(train_data):
x, y = data[0]['data'], data[0]['label']
pred = model(x)
loss = loss_func(pred, y)
backward(loss, model)
import os
import nvidia.dali.types as types
import nvidia.dali.experimental.dynamic as ndd
import torch
# To run with different data, see documentation of ndd.readers.File
# points to https://github.com/NVIDIA/DALI_extra
data_root_dir = os.environ['DALI_EXTRA_PATH']
images_dir = os.path.join(data_root_dir, 'db', 'single', 'jpeg')
def loss_func(pred, y):
pass
def model(x):
pass
def backward(loss, model):
pass
reader = ndd.readers.File(file_root=images_dir, random_shuffle=True)
for images, labels in reader.next_epoch(batch_size=16):
images = ndd.decoders.image_random_crop(images, device="gpu", output_type=types.RGB)
# the rest of processing happens on the GPU as well
images = ndd.resize(images, resize_x=256, resize_y=256)
images = ndd.crop_mirror_normalize(
images,
crop_h=224,
crop_w=224,
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255],
mirror=ndd.random.coin_flip(),
)
x = torch.as_tensor(images)
y = torch.as_tensor(labels.gpu())
pred = model(x)
loss = loss_func(pred, y)
backward(loss, model)
Highlights#
Easy-to-use functional style Python API.
Multiple data formats support - LMDB, RecordIO, TFRecord, COCO, JPEG, JPEG 2000, WAV, FLAC, OGG, H.264, VP9 and HEVC.
Portable across popular deep learning frameworks: TensorFlow, PyTorch, PaddlePaddle, JAX.
Supports CPU and GPU execution.
Scalable across multiple GPUs.
Flexible graphs let developers create custom pipelines.
Extensible for user-specific needs with custom operators.
Accelerates image classification (ResNet-50), object detection (SSD) workloads as well as ASR models (Jasper, RNN-T).
Allows direct data path between storage and GPU memory with GPUDirect Storage.
Easy integration with NVIDIA Triton Inference Server with DALI TRITON Backend.
Open source.