Troubleshooting#
Platform Setup#
Local Developer#
SR-IOV Basic Troubleshooting Procedure#
Check if IOMMU is enabled in the kernel:
dmesg | grep -i iommu
Check for SR-IOV capability on PCIe devices:
lspci -vvv | grep -i "Single Root I/O Virtualization"
Monitor kernel logs for any errors related to resource allocation:
dmesg | grep -i "sriov|iommu|vf"
SR-IOV Extensive Troubleshooting Procedure#
Check for resource conflicts.
Run
dmesg | grep -i iommuto look for any IOMMU-related errors.Check
lspci -vvoutput for your network adapter to ensure that it is properly detected and configured.
Try manually enabling SR-IOV for the network interface:
echo 1 > /sys/class/net/<interface_name>/device/sriov_numvfs
Replace
<interface_name>with the correct network interface (for example,enp77s0f1np1).If this fails, check the kernel log (
dmesg) for more detailed error messages.Check system resources:
Ensure the machine has enough system memory and PCIe BAR space available for SR-IOV VFs:
Check system memory:
Use the
freecommand to view available memory:free -hLook at the “available” column to see how much memory is free for use.
Ensure at least a few GBs of free memory are available for SR-IOV VFs.
Check PCIe BAR space:
Use the
lspcicommand to view PCIe devices and their resource allocations:lspci -vvLook for the network adapter and check its “Region” entries.
Ensure there is enough unallocated space in the PCIe address ranges.
Verify IOMMU groups:
Check IOMMU groups:
find /sys/kernel/iommu_groups/ -type l
Ensure the network adapter is in its own IOMMU group for optimal SR-IOV performance.
Check SR-IOV capability:
lspci -vv | grep -i "Single Root I/O Virtualization"
Look for the SR-IOV capability in the output.
Check available VFs:
Check the maximum number of VFs supported:
cat /sys/class/net/<interface_name>/device/sriov_totalvfsReplace
<interface_name>with the correct network interface (for example,enp77s0f1np1).
Error “Ansible requires the locale encoding to be UTF-8; Detected ISO8859-1”#
This can be resolved by setting the LC_ALL environment variable to C.UTF-8 before running installation commands.
LC_ALL="C.UTF-8" <command>
Replace <command> with the actual command to be run.
Physical Function Name Is Not Visible#
If the physical function name is not visible when running the ip a command, it’s possible that the Mellanox driver module mlx5_core is not loaded.
To load it, use the following command:
sudo modprobe mlx5_core
CNS Installation Fails Due To Syntax Error#
If CNS installation fails with the following error:
The task includes an option with an undefined variable. The error was: 'dict object' has no attribute 'stdout_lines'. 'dict object' has no attribute 'stdout_lines'
The error appears to be in '/home/h4m/cns/cloud-native-stack/playbooks/cns-validation.yaml': line 484, column 7, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
- name: Report Stack Version
^ here
This issue would not impact the functionality so complete the setup by running the below command:
If you are using automation, run the following command to complete the remaining tasks:
ANSIBLE_LOG_PATH=./install_$(date +'%Y%m%d_%H%M%S').log ansible-playbook h4m_playbook.yaml --start-at-task="Verify the NVIDIA Network and GPU operator pods are running" -e action=install -e "NGC_API_KEY=<API-KEY>" -vv
where:
<API-KEY>is an NGC API Key
If you are following manual instructions, start from Verify the installation step to complete the remaining tasks.
Cannot Access Service Through External IP#
If a service is not reachable through its external IP, check whether the node has the label
node.kubernetes.io/exclude-from-external-load-balancers:kubectl describe node | grep exclude
node.kubernetes.io/exclude-from-external-load-balancers=
If the above label is present on the node, remove it:
kubectl label node <node-name> node.kubernetes.io/exclude-from-external-load-balancers-
Replace
<node-name>with the actual name of the node:kubectl get nodes --no-headers -o custom-columns=NAME:.metadata.name
Several Pods Are In Unknown Status After Reboot#
When rebooting without following the graceful reboot procedure, some pods may not be deployed properly. Follow the recovery procedure.
Not Enough GPU Resources#
When more pods request GPUs than are available, they cannot all be scheduled. In a local developer setup with a single GPU, only one pod using a GPU can be deployed by default. Activating GPU time-slicing allows multiple pods to share GPU resources, though this will impact performance. You can also configure GPU time-slicing in production if it fits your workload requirements.
Not Enough Huge Pages#
When running out of HugePages, you can increase the number by following the associated procedure.
Error “direct_mkey failed: -12” Registering Memory#
Below error can appear in Rivermax logs when using nvdsudpsink in DeepStream or Media Gateway:
[25-10-06 10:41:27.796223] Tid: 002684 error [create_direct_mkey:465] direct_mkey failed: -12
[25-10-06 10:41:27.796250] Tid: 002684 critical [allocate_memory:355] failed registering memory addr 0x302000000 size 314572800 ret 350
This is likely due to your hardware not using or not compatible with Resizable BAR required for large memory transfers. Check if your configuration supports Resizable BAR by using these commands on your developer machine:
nvidia-smi -q | grep -i bar -A 3
An output like that below, showing about 64 Gigabytes total BAR1 memory, indicates a proper configuration, allowing the entire VRAM capacity of your GPU to be addressed.
BAR1 Memory Usage
Total : 65536 MiB
Used : 567 MiB
Free : 64969 MiB
If the displayed values are in the range of kilobytes, check that resizable BAR is set in the BIOS for PCIe slots used for GPU and NIC.
Production Setup#
k9s Doesn’t Connect To My Cluster#
For k9s to work with OpenShift, create an alias on your jump node as follows
alias kubectl='oc'
User Not Authenticated#
For some reason, your credentials to the cluster were lost. Follow the procedure to login to the cluster again. If for some reason the OpenShift web console is not accessible, the following command line can be used
oc login --username=kubeadmin --password=<kubeadmin-password> --server=https://<cluster-ip>
Cluster Reboots Constantly#
If you entered the command oc debug exec reboot now, you effectively created a pod responsible for forcing reboot.
At each boot up, that container will reboot your cluster. You have a few minutes before it operates to identify it after
the cluster starts by listing all pods and killing it to prevent it from rebooting the cluster.
Getting Logs Fails Although Getting Pods Works#
If you can’t collect the logs although you can successfully list all pods, it may be caused by a TLS internal error. Approve pending certificates to solve the problem.
oc get csr -o name | xargs oc adm certificate approve
Common Issues#
Pod Does Not Launch#
When one pod doesn’t launch properly, details can be gathered by describing the pod and looking at logs for proper debugging. This could be done with command line or k9s.
List all pods on your cluster:
kubectl get pods
This will clearly show pods that are Pending or in CrashLoopBackOff. Identify the problematic pod and describe it:
kubectl describe pod <pod-name>
Look under Events at the bottom. Common messages when the pod is stuck in Pending include:
“0/3 nodes are available: 1 Insufficient cpu, 2 Insufficient nvidia.com/gpu”, which indicates the oversubscribed resources that are preventing the pod being scheduled for each node.
nodeSelectorornodeAffinityconflicts.
If no message is displayed, this can be due to the wrong scheduler being used when deploying the application. For Production Deployments
using Red Hat OpenShift, NUMA-aware scheduling is configured for maximum performance, and applications should be deployed with schedulerName: topo-aware-scheduler.
This is the default in Holoscan for Media Helm charts. However, NUMA-aware scheduling can be turned off in the Performance Profile,
and is not currently supported in Local Developer Deployments. In these cases, make sure
your helm install command values or the values specified in Helm Dashboard overwrite the default name with default-scheduler or an
empty string as shown below:
schedulerName: ""
Using the wrong scheduler can also cause runaway pod creation errors (ContainerStatusUnknown).
If the pod started at all, access the problematic pod’s logs to debug further:
kubectl logs <pod-name>
Pod Content Is Lost After Rebooting The Cluster#
To ensure persistent storage for a pod, configure persistent volumes in its Helm chart.
Pod Deploys On A Local Developer Setup But Not On A Production Setup with OpenShift#
Local developer setups differ from a production setup by several aspects. In particular, privileged access is restricted for security reasons with OpenShift. Traditional bare metal applications often utilize system services, file-system access or system calls that are not recommended in Kubernetes environments where resource management is centralized.
Reference Applications#
Common Issues#
Application Installation Fails Due To Resource Conflicts#
If an application installation fails with errors indicating that resources are already in use, such as:
Error: 1 error occurred:
* Service "helm-dashboard" is invalid: spec.ports[0].nodePort: Invalid value: 32033: provided port is already allocated
This occurs when an application is deployed with a different release name and using the same resource definition.
To resolve this issue, you can either use a different resource definition or uninstall the conflicting release. For example, in the above case, you can either specify a different nodePort in config.yaml or uninstall the existing helm-dashboard chart.
To uninstall the conflicting chart, follow these steps:
Check for existing Helm releases:
helm listUninstall conflicting Helm releases:
helm uninstall <chart-name>
Replace
<chart-name>with the actual name of the conflicting chart.Retry the installation:
ANSIBLE_LOG_PATH=./application_$(date +'%Y%m%d_%H%M%S').log ansible-playbook install.yaml --extra-vars "NGC_API_KEY=<API-KEY> CHROME_REMOTE_DESKTOP_CODE=<CRD-CODE>" -vv
Media Gateway#
Failed To Initialize Rivermax Error 32#
This error can appear when Rivermax license is not valid anymore. Check in application and Rivermax logs if any information about license expiration appears. To resolve, delete the existing Rivermax license secret:
kubectl delete secret rivermax-license
And recreate the license as shown here with a new valid license file.
Some GStreamer Libraries Are Missing#
DeepStream container images do not package libraries necessary for certain multimedia operations like audio data parsing, CPU decode, and CPU encode.
Run the following script inside the container to install additional packages that might be necessary to use all GStreamer features:
/opt/nvidia/deepstream/deepstream/user_additional_install.sh
How To Use Fractional Frame Rates#
To use non-integer frame rates like 29.97 frames per second, a rational should be used in the associated SDP:
24000/1001 for 23.98
30000/1001 for 29.97
60000/1001 for 59.94
How To Change NMOS Device Names#
The device name shown in the NMOS Controller UI can be adjusted by using the label property of the nvdsnmosbin element in the pipeline.
NMOS Controller#
NMOS Controller Does Not Show Any Devices#
The NMOS Controller is configured to contact the NMOS Registry directly from the browser through the high-speed network. The host on which the browser is running therefore needs to have access to the high-speed network. This is also important to then be able to connect NMOS senders and receivers with in-band control on the high-speed network. Accessing the NMOS Controller from a Chrome Remote Desktop session is a good way to achieve this.
NMOS Connection Fails#
Parameters of output and input to be connected can be checked in the NMOS Controller UI on the right pane. Clicking ID provides access to further NMOS information such as frame size and color sampling.
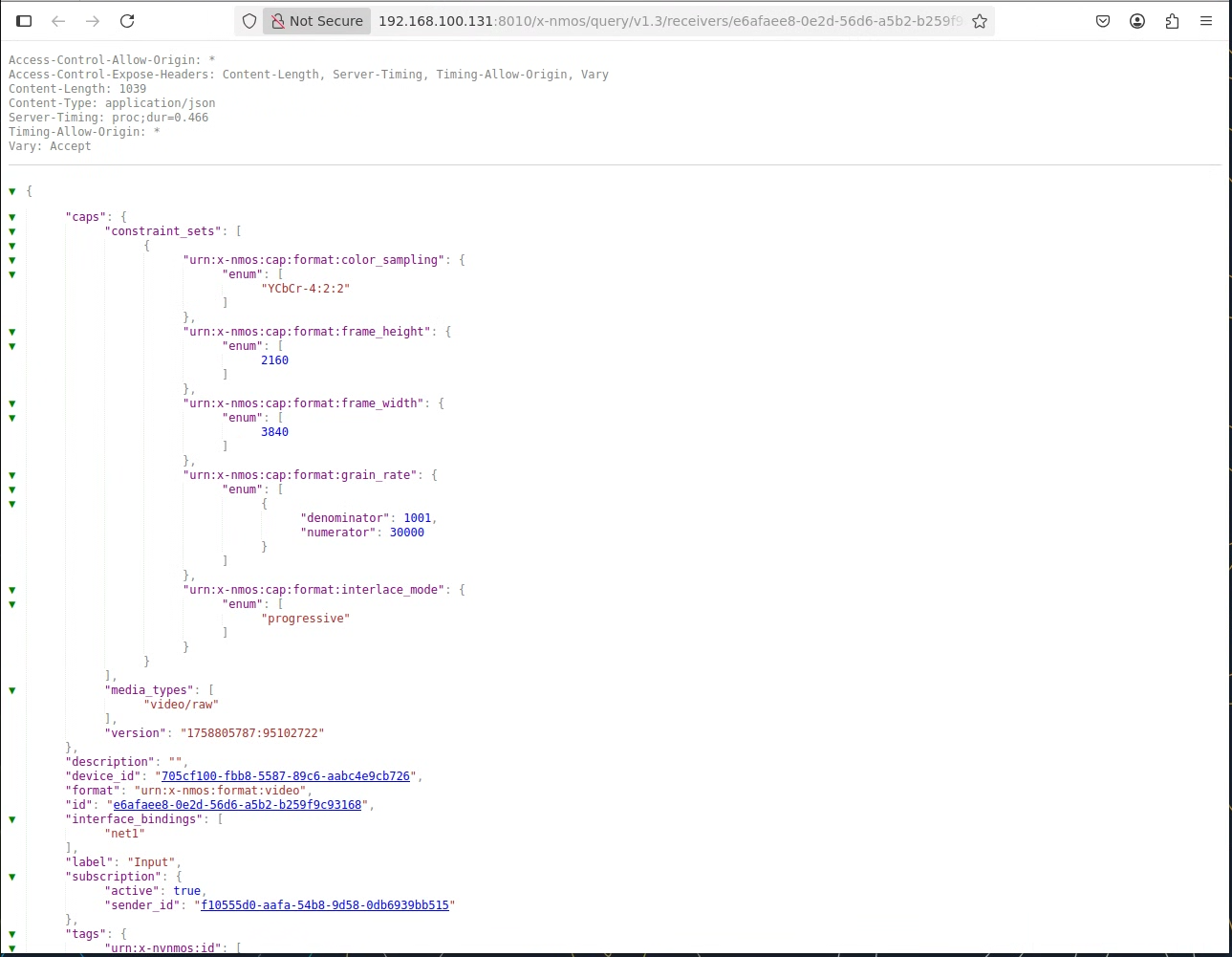
Clicking Active Parameters provides extended SDP information in use.
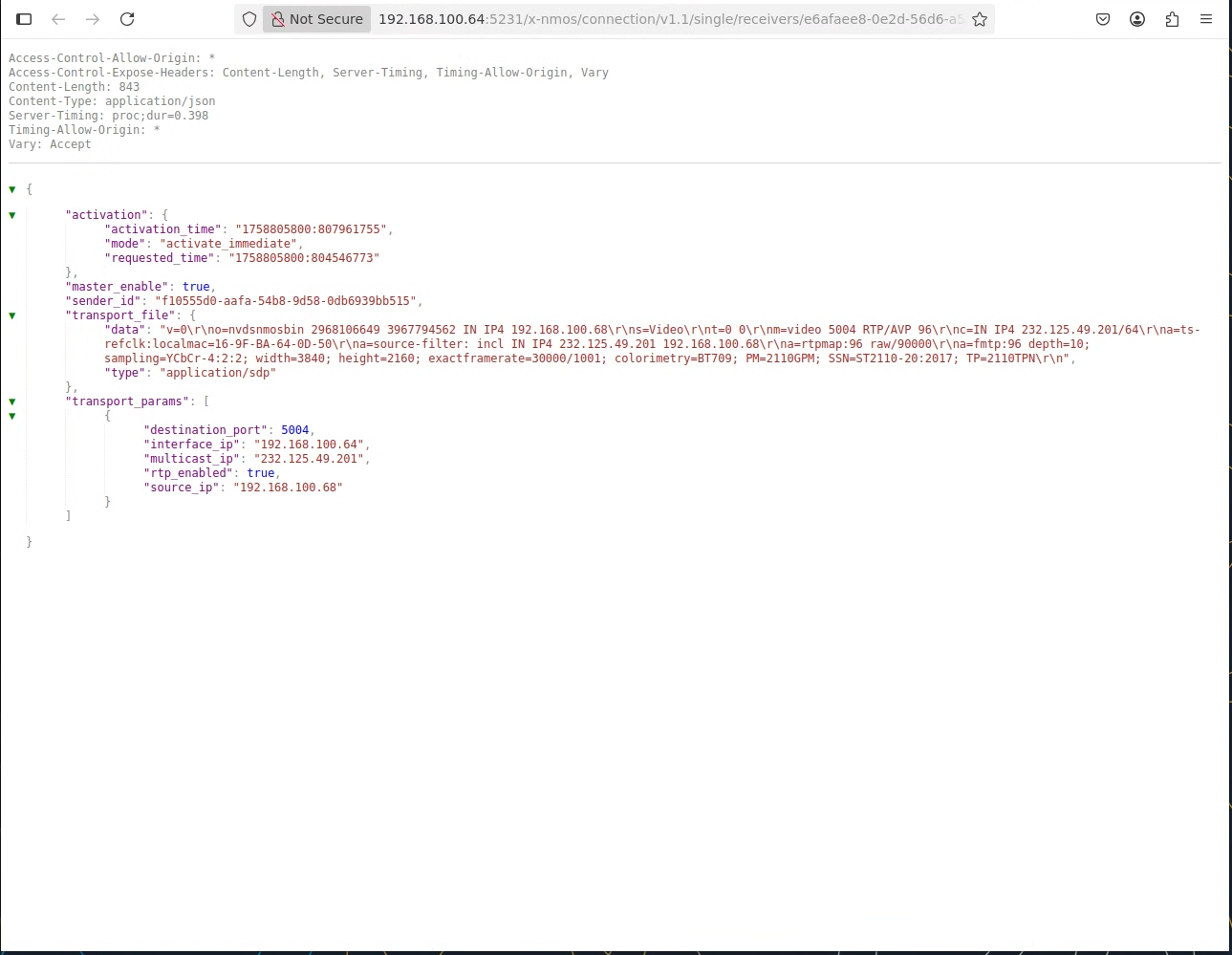
To debug a failing connection, display the logs of a given pod before NMOS connection using command line or k9s and proceed with connection. If logs of a pod are not under watch, the pod could be automatically restarting after failed connection, losing context and possible logs.
NMOS-Capable Pod Is Not Visible In NMOS Controller#
NMOS funcionality is highly dependent on the network configuration. NMOS Registry should be properly pinged from associated container if the high speed network interfaces are properly set on appropriate VLAN. Make sure your switch VLANs are properly configured and high speed network values in your pod Helm chart are properly set.
Chrome Remote Desktop#
Keyboard Is Set To US#
Chrome Remote Desktop image is using the US keyboard. Use the associated command to set it to your region.
setxkbmap fr
After Reboot Remote Connection Does Not Work And Needs To Be Reconfigured#
To ensure the remote connection works after reboot, a persistent volume should be set using the associated instructions. When the connection is first set up, a token will be stored on the persistent volume.
Platform Verification#
kubectl Command Not Found#
Install kubectl using the instructions from the Kubernetes documentation.
Permission Denied When Creating Secrets#
Verify RBAC permissions:
# Check permissions
kubectl auth can-i create secrets
kubectl auth can-i create pods
Test Fails With “Failed to start pods”#
Confirm the following:
Valid NGC API key configured
kubectl run test --image=nvcr.io/nvidia/holoscan-for-media/h4m-verification-tool-internals:<tag> --overrides='{"spec":{"imagePullSecrets":[{"name":"<ngc-secret-name>"}]}}' --rm -i --restart=Never --command -- echo "Image pulled successfully"
Replace
<ngc-secret-name>with the actual name of the NGC secret and<tag>with the version (for example,0.1.0).Appropriate nodes are present with worker role
kubectl get nodes -l node-role.kubernetes.io/worker -o name
Required resources are available and allocatable (check using the following)
kubectl describe nodes | awk '/^Name:/ {node=$2} /^Capacity:/ {print "\n" node; print; getline; while ($0 !~ /^Allocatable:/ && $0 !~ /^Conditions:/) {print; getline}} /^Allocatable:/ {print; getline; while ($0 !~ /^System Info:/ && $0 !~ /^Non-terminated Pods:/) {print; getline}}'
Try increasing the timeout using
export H4M_TEST_TIMEOUT=600and re-run the test.