Gst-nvinferserver#
The Gst-nvinferserver plugin performs inferencing on input data using NVIDIA® Triton Inference Server (previously called TensorRT Inference Server).
The plugin supports the following Triton server versions:
x86 platforms: Release 2.60.0, NGC Container 26.01 reference triton-inference-server/server
Jetson platforms: Release 2.56.0, NGC Container 25.08 reference triton-inference-server/server
The plugin accepts batched NV12/RGBA buffers from upstream. The NvDsBatchMeta structure must already be attached to the Gst Buffers.
The low-level library (libnvds_infer_server) operates on any of NV12 or RGBA buffers. The Gst-nvinferserver plugin passes the input batched buffers to the low-level library and waits for the results to be available. Meanwhile, it keeps queuing input buffers to the low-level library as they are received. Once the results are available from the low-level library, the plugin translates and attaches the results back in to Gst-buffer for downstream plugins.
The low-level library preprocesses the transformed frames (performs color conversion and scaling, normalization and mean subtraction) and produces final FP32/FP16/INT8/UINT8/INT16/UINT16/INT32/UINT32 RGB/BGR/GRAY planar/ packed data which is passed to the Triton for inferencing. The output type generated by the low-level library depends on the network type.
The pre-processing function is:
y = netscalefactor * (x - mean)
Where:
xis the input pixel value. It is an uint8 with range [0,255].meanis the corresponding mean value, read either from the mean file or as offsets[c], where c is the channel to which the input pixel belongs, and offsets is the array specified in the configuration file. It is a float.netscalefactoris the pixel scaling factor specified in the configuration file. It is a float.yis the corresponding output pixel value. It can be of typefloat / half / int8 / uint8 / int16 / uint16 / int32 / uint32.Take specific example for uint8 to int8 conversion. set
netscalefactor = 1.0andmean = [128, 128, 128]. Then the function looks like:y = (1.0) * (x - 128)
Gst-nvinferserver currently works on the following type of networks:
Multi-class object detection
Multi-label classification
Segmentation
The Gst-nvinferserver plugin can work in three process modes:
Primary mode: Operates on full frames.
Secondary mode: Operates on objects added in the metadata by upstream components.
When the plugin is operating as a secondary classifier in async mode along with the tracker, it tries to improve performance by avoiding re-inferencing on the same objects in every frame. It does this by caching the classification output in a map with the object’s unique ID as the key. The object is inferred upon only when it is first seen in a frame (based on its object ID) or when the size (bounding box area) of the object increases by 20% or more. This optimization is possible only when the tracker is added as an upstream element.
Preprocessed Tensor Input mode: Operates on tensors attached by upstream components.
When operating in preprocessed tensor input mode, the pre-processing inside Gst-nvinferserver is completely skipped. The plugin looks for
GstNvDsPreProcessBatchMetaattached to the input buffer and passes the tensor as is to the Tirton Inference Server without any modifications. This mode currently supports processing on full-frame and ROI. The GstNvDsPreProcessBatchMeta is attached by the Gst-nvdspreprocess plugin. This mode is enabled by adding the input_tensor_from_meta configuration message in the InferenceConfig message.
Detailed documentation of the Triton Inference Server is available at: triton-inference-server/server (x86) and triton-inference-server/server (Jetson)
The plugin supports Triton features along with multiple deep-learning frameworks such as TensorRT, TensorFlow (GraphDef / SavedModel), ONNX and PyTorch on Tesla platforms. On Jetson, it also supports TensorRT and TensorFlow (GraphDef / SavedModel). TensorFlow and ONNX can be configured with TensorRT acceleration. For details, see Framework-Specific Optimization.
The plugin requires a configurable model repository root directory path where all the models need to reside. All the plugin instances in a single process must share the same model root. For details, see Model Repository. Each model also needs a specific config.pbtxt file in its subdirectory. For details, see Model Configuration.
The plugin supports Triton ensemble mode to enable users to perform preprocessing or postprocessing with Triton custom backend.
The plugin also supports the interface for custom functions for parsing outputs of object detectors, classifiers, and initialization of non-image input layers in cases where there is more than one input layer.
Refer to sources/includes/nvdsinfer_custom_impl.h for the custom method implementations for custom models.
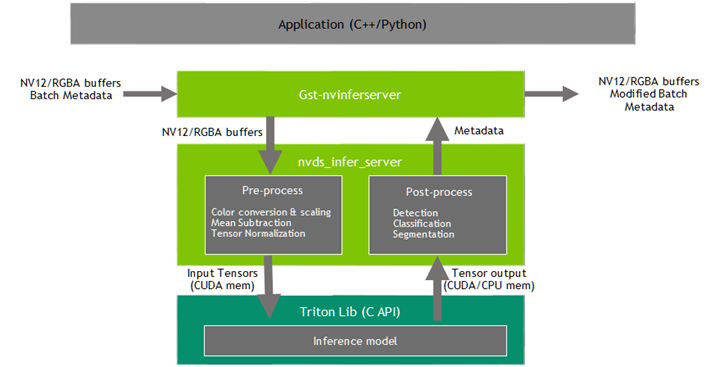
Downstream components receive a Gst Buffer with unmodified contents plus the metadata created from the inference output of the Gst-nvinferserver plugin. The plugin can be used for cascaded inferencing. That is, it can perform primary inferencing directly on input data, then perform secondary inferencing on the results of primary inferencing, and so on. This is similar with Gst-nvinfer, see more details in Gst-nvinfer.
Inputs and Outputs#
This section summarizes the inputs, outputs, and communication facilities of the Gst-nvinferserver plugin.
Inputs
Gst Buffer
NvDsBatchMeta (attaching NvDsFrameMeta)
Model repository directory path (model_repo.root)
gRPC endpoint URL (grpc.url)
Runtime model file with config.pbtxt file in model repository
Control parameters
Gst-nvinferserver gets control parameters from a configuration file. You can specify this by setting the property config-file-path. For details, see Gst-nvinferserver Configuration File Specifications. Other control parameters that can be set through GObject properties are:
Batch size
Process mode
Unique id
Inference on GIE id and operate on class ids [secondary mode only]
Inference interval
Raw output generated callback function
The parameters set through the GObject properties override the parameters in the Gst-nvinferserver configuration file.
Outputs
Gst Buffer
Depending on network type and configured parameters, one or more of:
NvDsObjectMeta
NvDsClassifierMeta
NvDsInferSegmentationMeta
NvDsInferTensorMeta
Gst-nvinferserver Configuration File Specifications#
The Gst-nvinferserver configuration file uses prototxt format described in https://developers.google.com/protocol-buffers.
The protobuf message structures of this configuration file are defined by nvdsinferserver_plugin.proto and nvdsinferserver_config.proto. All the basic data-type values are set to 0 or false from protobuf’s guide. Map, arrays and oneof are set to empty by default. See more details for each message definition.
The message PluginControl in
nvdsinferserver_plugin.protois the entry point for this config-file.The message InferenceConfig configures the low-level settings for
libnvds_infer_server.The message PluginControl::InputControl configures the input buffers, objects filtering policy for model inference.
The message PluginControl::OutputControl configures inference output policy for detections and raw tensor metadata.
The message BackendParams configures backend input/output layers and Triton settings in InferenceConfig.
The message PreProcessParams configures network preprocessing information in InferenceConfig.
The message InputTensorFromMeta enables the preprocessed tensor input mode and configures the input tensor information in InferenceConfig.
The message PostProcessParams configures the output tensor parsing methods such as detection, classification, semantic segmentation and others in InferenceConfig.
There are also other messages (e.g. CustomLib, ExtraControl) and enum types (e.g. MediaFormat, TensorOrder, …) defined in the proto file for miscellaneous settings for InferenceConfig and PluginControl.
Features#
The following table summarizes the features of the plugin.
Feature |
dGPU |
Jetson |
Release |
|---|---|---|---|
Gst-nvinferserver Running on Host |
No |
Yes |
DS 5.0 |
Running on Docker Image |
Yes |
Yes(DS 6.0) |
DS 5.0 |
DS Preprocessing: Network input format: RGB/BGR/Gray |
Yes |
Yes |
DS 5.0 |
DS Preprocessing: Network input data types FP32/FP16/UINT8/INT8/UINT16/INT16/UINT32/INT32 |
Yes |
Yes |
DS 5.0 |
DS Preprocessing: Network input tensor orders NCHW / NHWC |
Yes |
Yes |
DS 5.0 |
Mem: Cuda(GPU) buf-sharing for Input Tensors |
Yes |
Yes |
DS 5.0 |
Mem: Cuda Memory (GPU / CPU-pinned) for output tensors |
Yes |
Yes |
DS 5.0 |
Backend: TensorRT runtime (plan engine file) |
Yes |
Yes |
DS 5.0 |
Backend: Tensorflow Runtime CPU/GPU (graphdef/savedmodel) |
Yes |
Yes |
DS 5.0 |
Backend: Tensorflow Runtime with TF-TRT acceleration |
Yes |
Yes |
DS 5.0 |
Backend: ONNX Runtime |
Yes |
Yes(DS 6.0) |
DS 5.0 |
Backend: ONNX Runtime with ONNX-TRT acceleration |
Yes |
Yes(DS 6.0) |
DS 5.0 |
Backend: Pytorch Runtime |
Yes |
No |
DS 5.0 |
Postprocessing: DS Detection / Classification/ Segmentation |
Yes |
Yes |
DS 5.0 |
Postprocessing: DS Detection cluster method: NMS / GroupRectangle / DBSCan / None |
Yes |
Yes |
DS 5.0 |
Postprocessing: custom parsing (NvDsInferParseCustomTfSSD) |
Yes |
Yes |
DS 5.0 |
Postprocessing: Triton native classification |
Yes |
Yes |
DS 5.0 |
Triton Ensemble Mode (Triton preproc/postproc) with specified media-format (RGB/BGR/Gray) with Cuda GPU buffer as inputs |
Yes |
Yes |
DS 5.0 |
Postprocessing: Attach Triton raw tensor output in NvDsInferTensorMeta for downstream or application postprocessing |
Yes |
Yes |
DS 5.0 |
deepstream-app: pipeline works with PGIE / SGIE / nvtracker |
Yes |
Yes |
DS 5.0 |
Sample App: deepstream-segmentation-test / deepstream-infer-tensor-meta-test |
Yes |
Yes |
DS 5.0 |
Basic LSTM features on single batch and single stream (beta version, config file might be changed in future version) |
Yes |
Yes |
DS 5.0 |
gRPC: Triton Server running as independent process and plugin communicates through gRPC |
Yes |
Yes |
DS 6.0 |
Custom process interface |
Yes |
Yes |
DS 6.0 |
gRPC: CUDA buffer sharing with local Triton server for input tensors |
Yes |
Yes |
DS 6.2 |
Postprocessing: Clip object bounding boxes to fit within the ROI |
Yes |
Yes |
DS 6.3 |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs
(Primary/Secondary)
|
|---|---|---|---|---|
infer_config |
Low-level libnvds_infer_server inference configuration settings |
InferenceConfig |
infer_config { … } see details in InferenceConfig |
All Both |
input_control |
Control plugin input buffers, objects filtering policy for inference |
PluginControl ::InputControl |
input_control{ process_mode: PROCESS_MODE_FULL_FRAME } see details in InputControl |
All Both |
output_control |
Control plugin output metadata filtering policy after inference |
PluginControl ::OutputControl |
output_control { … } see details in OutputControl |
All Both |
process_mode |
Processing mode, selected from PluginControl::ProcessMode. In deepstream-app PGIE uses PROCESS_MODE_FULL_FRAME by default, SGIE use PROCESS_MODE_CLIP_OBJECTS by default |
enum PluginControl::ProcessMode |
process_mode: PROCESS_MODE_FULL_FRAME |
All Both |
operate_on_gie_id |
Unique ID of the GIE on whose metadata (bounding boxes) this GIE is to operate on |
int32, >=0, valid gie-id. -1, disable gie-id check, inference on all GIE Ids |
operate_on_gie_id: 1 |
All Secondary |
operate_on_class_ids |
Class IDs of the parent GIE on which this GIE is to operate on |
Comma delimited int32 array |
operate_on_class_ids: [1, 2] Operates on objects with class IDs 1, 2 generated by parent GIE |
All Secondary |
interval |
Specifies the number of consecutive, batches to be skipped for inference. default is 0 |
uint32 |
interval: 1 |
All Primary |
async_mode |
Enables inference on detected objects and asynchronous metadata attachments. Works only when tracker-ids are attached. Pushes buffer downstream without waiting for inference results. Attaches metadata after the inference |
bool |
async_mode: false |
Classifier Secondary |
object_control |
input object filter settings |
PluginControl::InputObjectControl |
object_control { bbox_filter { min_width: 64 min_height: 64 } } see details in InputObjectControl |
All Secondary |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs
(Primary/Secondary)
|
|---|---|---|---|---|
process_mode |
Processing mode, selected from PluginControl::ProcessMode. In deepstream-app PGIE uses PROCESS_MODE_FULL_FRAME by default, SGIE use PROCESS_MODE_CLIP_OBJECTS by default |
enum PluginControl::ProcessMode |
process_mode: PROCESS_MODE_FULL_FRAME |
All Both |
operate_on_gie_id |
Unique ID of the GIE on whose metadata (bounding boxes) this GIE is to operate on |
int32, >=0, valid gie-id. -1, disable gie-id check, inference on all GIE Ids |
operate_on_gie_id: 1 |
All Secondary |
operate_on_class_ids |
Class IDs of the parent GIE on which this GIE is to operate on |
Comma delimited int32 array |
operate_on_class_ids: [1, 2] Operates on objects with class IDs 1, 2 generated by parent GIE |
All Secondary |
interval |
Specifies the number of consecutive, batches to be skipped for inference. default is 0 |
uint32 |
interval: 1 |
All Primary |
async_mode |
Enables inference on detected objects and asynchronous metadata attachments. Works only when tracker-ids are attached. Pushes buffer downstream without waiting for inference results. Attaches metadata after the inference |
bool |
async_mode: false |
Classifier Secondary |
object_control |
input object filter settings |
PluginControl::InputObjectControl |
object_control { bbox_filter { min_width: 64 min_height: 64 } } see details in InputObjectControl |
All Secondary |
secondary_reinfer_interval |
Re-inference interval for objects, in frames |
uint32 |
secondary_reinfer_interval: 90 |
All Secondary |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs
(Primary/Secondary)
|
|---|---|---|---|---|
output_tensor_meta |
Enable attaching Inference output tensor metadata, tensor buffer pointer for host only |
bool |
output_tensor_meta: false |
All
Both
|
detect_control |
Specifies detection output filter policy |
PluginControl::OutputDetectionControl |
detect_control { default_filter { bbox_filter { min_width: 32 min_height: 32 } } } see details in OutputDetectionControl |
Detector
Both
|
classifier_type |
The classifier type to be added in the NvDsClassifierMeta in case of classification networks |
string |
classifier_type: multi_class_classification |
Classifier
Both
|
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs
(Primary/Secondary)
|
|---|---|---|---|---|
bbox_filter |
Bounding box filter |
PluginControl::BBoxFilter |
bbox_filter { min_width: 32 min_height: 32 } see details in BBoxFilter |
All Secondary |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
min_width |
Bounding box minimum width |
uint32 |
min_width: 64 |
All Both |
min_height |
Bounding box minimum height |
uint32 |
min_height: 64 |
All Both |
max_width |
Bounding box maximum width, default 0, max_width is ignored |
uint32 |
max_width: 640 |
All Both |
max_height |
Bounding box maximum height, default 0, max_height is ignored |
uint32 |
max_height: 640 |
All Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
default_filter |
default detection filter for output controls |
PluginControl::DetectClassFilter |
default_filter { bbox_filter { min_width: 32 min_height: 32 } } see details in DetectClassFilter |
All Both |
specific_class_filters |
specifies detection filters per class to replace default filter |
map<uint32, DetectClassFilter> |
specific_class_filters: [ { key: 1, value {…} }, { key: 2, value {…} } ] |
All Both |
filter_out_class_ids |
Filter out detected objects belonging to specified class-ids |
An array of comma-separated integers (class-ids) |
filter_out_class_ids: [1, 2] |
All Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
bbox_filter |
detection bounding box filter |
PluginControl::BBoxFilter |
bbox_filter { min_width: 64 min_height: 64 } |
Detection
Both
|
roi_top_offset |
Offset of the RoI from the top of the frame. Only objects within the RoI are output. |
uint32 |
roi_top_offset: 128 |
Detection
Both
|
roi_bottom_offset |
Offset of the RoI from the bottom of the frame. Only objects within the RoI are output. |
uint32 |
roi_bottom_offset: |
Detection
Both
|
border_color |
specify border color for detection bounding boxes |
PluginControl::Color |
border_color { r: 1.0 g: 0.0 b: 0.0 a: 1.0 } |
Detection
Both
|
bg_color |
specify background color for detection bounding boxes |
PluginControl::Color |
border_color { r: 0.0 g: 1.0 b: 0.0 a: 0.5 } |
Detection
Both
|
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
r |
Red color value |
float Range[0.0, 1.0] |
r: 0.5 |
All
Both
|
g |
Green color value |
float. Range[0.0, 1.0] |
g: 0.5 |
All
Both
|
b |
Blue color value |
float. Range[0.0, 1.0] |
b: 0.3 |
All
Both
|
a |
Alpha blending value |
float. Range[0.0, 1.0] |
a: 1.0 |
All
Both
|
Low Level libnvds_infer_server.so Configuration File Specifications#
The message InferenceConfig defines all the low-level structure fields in nvdsinferserver_config.proto. It has major settings for inference backend, network preprocessing and postprocessing.
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
unique_id |
Unique ID identifying metadata generated by this GIE |
uint32, ≥0 |
unique_id: 1 |
All/Both |
gpu_ids |
Device IDs of GPU to use for pre-processing/inference (single GPU support only) |
int32 array, ≥0 |
gpu_ids: [0] |
All/Both |
max_batch_size |
Max number of frames/objects to be inferred together in a batch |
uint32, ≥0 |
max_batch_size: 1 |
All/Both |
backend |
Inference backend settings |
BackendParams |
|
All/Both |
preprocessing |
One of preprocess or input_tensor_from_meta. Use preprocess if using frame or object processing mode and input_tensor_from_meta when using preprocessed tensor input mode |
preprocess or input_tensor_from_meta |
N/A. Refer preprocess and input_tensor_from_meta below |
All/Both |
preprocess |
Network preprocessing settings for color conversion, scale and normalization applicable when using frame or object processing mode |
PreProcessParams |
|
All/Both |
input_tensor_from_meta |
Configuration for the input tensor applicable when using preprocessed tensor as input |
InputTensorFromMeta |
|
Preprocessed tensor input mode |
postprocess |
Inference output tensor parsing methods such as detection, classification, semantic segmentation and others |
PostProcessParams |
|
All/Both |
custom_lib |
Specify custom lib path for custom parsing functions and preloads, optional |
CustomLib |
|
All/Both |
extra |
extra controls for inference config. |
ExtraControl |
|
All/Both |
lstm |
LSTM control parameters, limited on batch-size 1 and single stream |
LstmParams [optional] |
|
All/Both |
clip_object_outside_roi |
Clip the object bounding boxes to fit within the specified ROI boundary. |
bool |
clip_object_outside_roi: false |
Detector/Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
inputs |
Backend input layer settings, optional |
InputLayer arrays |
see details in InputLayer |
All/Both |
outputs |
Backend output layer settings, optional |
OutputLayer arrays |
see details in OutputLayer |
All/Both |
triton |
Backend of Triton Inference Server settings |
TritonParams |
see details in TritonParams |
All/Both |
output_mem_type |
Triton native output tensor memory type |
MemoryType (select from [MEMORY_TYPE_DEFAULT, MEMORY_TYPE_CPU, MEMORY_TYPE_GPU]) |
output_mem_type: MEMORY_TYPE_CPU |
All/Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
name |
input tensor name |
string |
name: “input_0” |
All Both |
dims |
input tensor shape, optional. Only required if backend cannot figure out fixed input shapes |
int32 array, > 0 |
dims: [299, 299, 3] |
All Both |
data_type |
enum TensorDataType with types:
usually can be deduced from Triton model config.pbtxt |
TensorDataType |
data_type: TENSOR_DT_FP32 |
All Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
name |
output tensor name |
string |
name: “detection_boxes” |
All
Both
|
max_buffer_bytes |
output tensor reserved buffer bytes |
uint64 |
max_buffer_bytes: 2048 |
All
Both
|
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
model_name |
Triton inference model name |
string |
model_name: “ssd_inception_graphdef” |
All
Both
|
version |
Triton model version number. -1, latest version number. >0, reserved for specific version number in future version |
int64 |
version: -1 |
All
Both
|
model_repo |
Triton model repository settings. Note, all model_repo settings must be same in single process |
TritonParams::TritonModelRepo |
model_repo { root: “../triton_model_repo” log_level: 2 } Refer the details in TritonModelRepo |
All
Both
|
grpc |
Triton gRPC server settings. |
TritonParams::TritonGrpcParams |
grpc { url: “localhost:8001” enable_cuda_buffer_sharing: false } Refer the details in TritonGrpcParams |
All
Both
|
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
root |
Triton inference model repository directory path |
string |
root: “../triton_model_repo” |
All/Both |
log_level |
Triton log output levels |
uint32; 0, ERROR; 1, WARNING; 2, INFO; >=3, VERBOSE Level |
log_level: 1 |
All/Both |
strict_model_config |
Enable Triton strict model configuration, see details in Triton Generated Model Configuration. Suggest setting value true |
bool |
strict_model_config: true |
All/Both |
tf_gpu_memory_fraction |
TensorFlow GPU memory fraction per process. Valid for Tensorflow models only. Default 0 means no GPU memory limitation. Suggest tuning to a proper value (e.g. in range of [0.2, 0.6]) in case Tensorflow uses up whole GPU memory |
float, Range (0, 1.0] |
tf_gpu_memory_fraction: 0.6 |
All/Both |
tf_disable_soft_placement |
Disable TensorFlow soft placement of operators. It’s enabled by default. |
bool |
tf_disable_soft_placement: false |
All/Both |
min_compute_capacity |
Specify minimal GPU compute capacity. The default value is 6.0 on x86 and 5.0 on Jetson. |
float |
min_compute_capacity: 6.0 |
All/Both |
backend_dir |
Specify Triton backend directory which store Tensorflow/Onnx/Pytorch and custom backends. The Default value is /opt/tritonserver/backends on X86 and opt/nvidia/deepstream/deepstream-x.x/lib/triton_backends on Jetson. |
string |
backend_dir: /opt/tritonserver/backends/ |
All/Both |
cuda_device_memory |
Specify a list of CudaDeviceMem blocks with pre-allocated memory pool. Use Triton’s default value if list is empty. |
message list |
cuda_device_memory [ { device: 0 memory_pool_byte_size: 2000000000 } ] |
All/Both |
CudaDeviceMem::device |
Specify device ID |
uint32; >= 0 |
device: 0 |
All/Both |
CudaDeviceMem::memory_pool_byte_size |
Indicate pre-allocated memory pool byte size on according device for Triton runtime |
uint64; >= 0 |
memory_pool_byte_size: 8000000000 |
All/Both |
pinned_memory_pool_byte_size |
Indicate pre-allocated Pinned memory on host for Triton runtime. Use Triton’s default value (around 256MB) if not set. |
uint64; >= 0 |
pinned_memory_pool_byte_size: 128000000 |
All/Both |
backend_configs |
A list of BackendConfig blocks for Tritonserver backend config settings |
message list |
backend_configs [ { backend: tensorflow setting: “allow-soft-placement” value: “true” } ] |
All/Both |
BackendConfig::backend |
Specify backend name |
string |
backend: tensorflow |
All/Both |
BackendConfig::setting |
Specify backend setting name |
string |
setting: “allow-soft-placement” |
All/Both |
BackendConfig::value |
Specify backend setting values |
string |
value: “true” |
All/Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
url |
Triton server name and port |
string |
url: “localhost:8001” |
All/Both |
enable_cuda_buffer_sharing |
Enable sharing of CUDA buffers with local Triton server for input tensors. If enabled, the input CUDA buffers are shared with the Triton server to improve performance. This feature should be enabled only when the Triton server is on the same machine. Applicable for x86 dGPU platform, not supported on Jetson devices. By default disabled i.e. CUDA buffers are copied to system memory while creating the inference request. |
Bool |
enable_cuda_buffer_sharing: true |
All/Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
network_format |
enum MediaFormat with formats: MEDIA_FORMAT_NONE, IMAGE_FORMAT_RGB, IMAGE_FORMAT_BGR, IMAGE_FORMAT_GRAY. use IMAGE_FORMAT_RGB by default. |
MediaFormat |
network_format: IMAGE_FORMAT_RGB |
All/Both |
tensor_order |
enum TensorOrder with order types: TENSOR_ORDER_NONE, TENSOR_ORDER_LINEAR(this includes NCHW, CHW, DCHW, … orders), TENSOR_ORDER_NHWC. It can deduce the value from backend layers info if set to TENSOR_ORDER_NONE |
TensorOrder |
tensor_order: TENSOR_ORDER_NONE |
All/Both |
tensor_name |
Specify the tensor name for the preprocessing buffer. This is in the case when multiple input tensors in a single network. |
string; Optional |
tensor_name: “input_0” |
All/Both |
frame_scaling_hw |
Compute hardware to use for scaling frames / object crops to network resolution |
enum FrameScalingHW FRAME_SCALING_HW_DEFAULT: Platform default – GPU (dGPU), VIC (Jetson) FRAME_SCALING_HW_GPU FRAME_SCALING_HW_VIC (Jetson only) |
frame_scaling_hw: FRAME_SCALING_HW_GPU |
All/Both |
frame_scaling_filter |
The filter to use for scaling frames / object crops to network resolution |
int32, refer to enum NvBufSurfTransform_Inter in nvbufsurftransform.h for valid values |
frame_scaling_filter: 1 |
All/Both |
maintain_aspect_ratio |
Indicates whether to maintain aspect ratio while scaling input. |
int32; 0 or 1 |
maintain_aspect_ratio: 0 |
All/Both |
symmetric_padding |
Indicates whether to pad image symmetrically while scaling input. DeepStream pads the images asymmetrically by default. |
int32; 0 or 1 |
symmetric_padding: 0 |
All/Both |
normalize |
Network input tensor normalization settings for scale-factors, offsets and mean-subtraction |
PreProcessParams::ScaleNormalize |
|
All/Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
scale_factor |
Pixel normalization factor |
float |
scale_factor: 0.0078 |
All
Both
|
channel_offsets |
Array of mean values of color components to be subtracted from each pixel. Array length must equal the number of color components in the frame. The plugin multiplies mean values by scale_factor. |
float array, Optional |
channel_offsets: [77.5, 21.2, 11.8] |
All
Both
|
mean_file |
Pathname of mean data file (PPM format) |
string; Optional |
mean_file: “./model_meanfile.ppm” |
All
Both
|
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs
(Primary/Secondary)
|
|---|---|---|---|---|
is_first_dim_batch |
Boolean indicating whether the preprocessed input tensor has first dimension as batch. Set true for batched input, false otherwise. |
Boolean |
is_first_dim_batch: true |
All Preprocessed tensor input mode |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
labelfile_path |
Pathname of a text file containing the labels for the model |
string |
labelfile_path: “=/home/ubuntu/model_labels.txt” |
All Both |
oneof process_type |
Indicates one of the postprocessing type detection; classification; segmentation; other; |
None |
N/A |
All Both |
detection |
Specify detection parameters for the network. It must be oneof process_type |
DetectionParams |
detection { num_detected_classes: 4 simple_cluster { threshold: 0.2 } } see details in DetectionParams |
Detector Both |
classification |
Specify classification parameters for the network It is oneof process_type |
ClassificationParams |
classification { threshold: 0.6 } see details in ClassificationParams |
Classifier Both |
segmentation |
Specify semantic segmentation parameters for the network It is oneof process_type |
SegmentationParams |
segmentation { threshold: 0.2 num_segmentation_classes: 2 } |
Segmentation Both |
other |
Specify other network parameters. This is for user-defined networks and usually coexists with output_control.output_tensor_meta: true. Tensor output data would be attached into GstBuffer. Data can be parsed in application. User can increase extra.output_buffer_pool_size if need to hold metadata longer. It is oneof process_type |
OtherNetworkParams |
other {} see details in OtherNetworkParams |
Others Both |
triton_classification |
Specify Triton classification parameters for the network It is oneof process_type |
TritonClassifyParams |
Triton_classification { topk: 1 } see details in TritonClassifyParams |
Classifier Both |
Name |
Description |
Type and Range |
Example Notes |
Network Types /
Applicable to GIEs (Primary/Secondary)
|
|---|---|---|---|---|
num_detected_classes |
Define number of classes detected by the network |
int32, > 0 |
num_detected_classes:4 |
Detector Both |
per_class_params |
Map of specific detection parameters per class. Key-value follows <class_id: per_class_params> order. |
map<int32, PerClassParams>; Optional |
per_class_params [ { key: 1, value { pre_threshold : 0.4} }, { key: 2, value { pre_threshold : 0.5} } ] see details for PerClassParams |
Detector Both |
custom_parse_bbox_func |
Name of the custom bounding box parsing function. If not specified, Gst-nvinferserver uses the internal function for the resnet model provided by the SDK. If specified, also need to set custom_lib to load custom library. |
string; |
custom_parse_bbox_func: “NvDsInferParseCustomTfSSD” |
Detector Both |
oneof clustering_policy |
Indicates one of the clustering policies from nms; dbscan; group_rectangle; simple_cluster; |
None |
N/A |
Detector Both |
nms |
Indicates clustering bounding boxes by Non-Maximum-Suppression method detected objects. It is oneof clustering_policy |
Nms |
nms { confidence_threshold: 0.3 iou_threshold: 0.4 } see details in Nms |
Detector Both |
dbscan |
Indicates clustering bounding boxes by DBSCAN method for detected objects. It is oneof clustering_policy |
DbScan |
dbscan { pre_threshold: 0.3 eps: 0.7 min_boxes: 3 } see details in DbScan |
Detector Both |
group_rectangle |
Indicates clustering bounding boxes by groupRectangles() function for grouping detected objects It is oneof clustering_policy |
GroupRectangle |
group_rectangle { confidence_threshold: 0.2 group_threshold: 2 eps: 0.2 } |
Detector Both |
simple_cluster |
Indicates simple clustering method by outlier boxes through threshold |
SimpleCluster |
simple_cluster { threshold: 0.2 } |
Detector Both |
Gst-nvinferserver message DetectionParams-PerClassParams definition details# Name
Description
Type and Range
Example Notes
pre_threshold
Define confidence threshold per class
float
pre_threshold:0.3
Detector
Both
Gst-nvinferserver message DetectionParams-Nms definition details# Name
Description
Type and Range
Example Notes
Network Types/Applicable to GIEs (Primary/Secondary)
confidence_threshold
Detection score lesser than this threshold would be rejected
float
confidence_threshold:0.5
Detector/Both
iou_threshold
Maximum IOU score between two proposals after which the proposal with the lower confidence will be rejected.
float
iou_threshold: 0.3
Detector/Both
topk
Specify top k detection results to keep after nms
int32, >= 0
topk: 2; value 0, means keep all.
Detector/Both
Gst-nvinferserver message DetectionParams-DbScan definition details# Name
Description
Type and Range
Example Notes
pre_threshold
Detection score lesser than this threshold would be rejected before DBSCAN clustering
float
pre_threshold:0.2
Detector
Both
eps
DBSCAN epsilon to control merging of overlapping boxes.
float
eps: 0.7
Detector
Both
min_boxes
Minimum boxes in DBSCAN cluster to be considered an object
int32, > 0
min_boxes: 3;
Detector
Both
min_score
Minimum score in DBSCAN cluster for it to be considered as an object
float
min_score: 0.7
Default value is 0
Detector
Both
Gst-nvinferserver message DetectionParams-GroupRectangle definition details# Name
Description
Type and Range
Example Notes
confidence_threshold
Detection score lesser than this threshold would be rejected
float
confidence_threshold:0.2
Detector
Both
group_threshold
Threshold value for rectangle merging for OpenCV grouprectangles() function
int32; >= 0
group_threshold: 1
Detector
Both
eps
Epsilon to control merging of overlapping boxes
float
eps: 0.2
Detector
Both
Gst-nvinferserver message DetectionParams-SimpleCluster definition details# Name
Description
Type and Range
Example Notes
threshold
Detection score lesser than this threshold would be rejected
float
confidence_threshold:0.6
Detector
Both
Gst-nvinferserver message ClassificationParams definition details# Name
Description
Type and Range
Example Notes
threshold
Classification score lesser than this threshold would be rejected
float
threshold: 0.5
Classifier
Both
custom_parse_classifier_func
Name of the custom classifier output parsing function. If not specified, Gst-nvinfer uses the internal parsing function with NCHW tensor order for softmax layers. User can reshape other output tensor order to NCHW in Triton config.pbtxt to run internal parsing. If specified, also need to set custom_lib to load custom library.
string
parse-classifier-func-name: “parse_bbox_softmax”
Classifier
Both
Gst-nvinferserver message SegmentationParams definition details# Name
Description
Type and Range
Example Notes
threshold
Segmentation score lesser than this threshold would be rejected
float
threshold: 0.5
Segmentation
Both
num_segmentation_classes
Number of output classes for the segmentation network
int32, >0
num_segmentation_classes: 2
Segmentation
Both
custom_parse_segmentation_func
Name of the custom segmentation output parsing function. If not specified, Gst-nvinferserver uses the internal function for the UNet model provided by the SDK. If specified, users also need to set custom_lib to load custom library.
string
custom_parse_segmentation_func: “NvDsInferParseCustomPeopleSemSegNet”
Segmentation
Both
Gst-nvinferserver message OtherNetworkParams definition details# Name
Description
Type and Range
Example Notes
type_name
Specify a user-defined network name
string; | Optional
type_name: “face”
Others
Both
Gst-nvinferserver message TritonClassifyParams definition details# Name
Description
Type and Range
Example Notes
topk
Specify top k elements need to keep from Triton’s native classification
uint32; >=0
topk : 1 Value 0 or empty would keep the top 1 result.
Classifier
Both
threshold
Classification score lesser than this threshold would be rejected
float
threshold: 0.5
Classifier
Both
Gst-nvinferserver message CustomLib definition details# Name
Description
Type and Range
Example Notes
path
Pathname that points to a custom library for preload
string
path: “/home/ubuntu/lib_custom_impl.so”
All
Both
Gst-nvinferserver message ExtraControl definition details# Name
Description
Type and Range
Example Notes
copy_input_to_host_buffers
Enable to copy input. If enabled, input tensor would be attached as NvDsInferTensorMeta into GstBuffer with output tensors together tensor data to host buffers.
bool
copy_input_to_host_buffers: false
All
Both
output_buffer_pool_size
Specify the buffer pool size for each output tensor. When infer_config.postprocess.other is specified or output_control.output_tensor_meta is enabled, the output tensor would be attached as NvDsInferTensorMeta into GstBuffer
int32; Range [2, 10]
output_buffer_pool_size: 4
All
Both
custom_process_funcion
custom function to create a specific user-defined processor IInferCustomProcessor. The function symbol is loaded by infer_config.custom_lib
String
path: “libnvdsinfer_custom_impl_fasterRCNN.so”
All
Both
Note
LstmParams structures may be changed in future versions
Gst-nvinferserver message LstmParams definition details# Name
Description
Type and Range
Example Notes
Network Types/Applicable to GIEs (Primary/Secondary)
loops
Specify LSTM loops between input and output tensors.
LstmLoop [repeated]
loops [ { input: “init_state” output: “out_state” } ] See details in LstmParams::LstmLoop
All/Both
Note
Input and output tensors must have same datatype/dimensions, FP16 is not supported
LstmParams::LstmLoop structures might be changed in future versions
Name |
Description |
Type and Range |
Example Notes |
Network Types/Applicable to GIEs (Primary/Secondary) |
|---|---|---|---|---|
input |
Specify input tensor name of the current loop. |
string |
Input: “init_state” |
All/Both |
output |
Specify input tensor name of the current loop. Tensor data will feedback to the input tensor |
string |
onput: “output_state” |
All/Both |
init_const |
Specify the constant values for the input in first frame |
InitConst | value: float |
Init_const { value: 0 } |
All/Both |
Gst Properties#
The values set through Gst properties override the values of properties in the configuration file. The application does this for certain properties that it needs to set programmatically. If user set property though plugin, these values would replace the original value in config files. The following table describes the Gst-nvinferserver plugin’s Gst properties.
Property |
Meaning |
Type and Range |
Example Notes |
|---|---|---|---|
config-file-path |
Absolute pathname of configuration file for the Gst-nvinferserver element |
String |
config-file-path=config_infer_primary.txt |
process-mode |
Infer Processing Mode (0):None, (1)FullFrame, (2)ClipObject. If set, it could replace input_control.process_mode |
Integer, 0, 1 or 2 |
process-mode=1 |
unique-id |
Unique ID identifying metadata generated by this GIE. If set, it could replace infer_config.unique_id |
Integer, 0 to 4,294,967,295 |
unique-id=1 |
infer-on-gie-id |
See input_control.operate_on_gie_id in the configuration file table |
Integer, 0 to 4,294,967,295 |
infer-on-gie-id=1 |
operate-on-class-ids |
See input_control.operate_on_class_ids in the configuration file table |
An array of colon- separated integers (class-ids) |
operate-on-class-ids=1:2:4 |
batch-size |
Number of frames/objects to be inferred together in a batch. If set, it could replace infer_config.max_batch_size |
Integer, 1 – 4,294,967,295 |
batch-size=4 |
Interval |
Number of consecutive batches to be skipped for inference If set, it could replace input_control.interval |
Integer, 0 to 32 |
interval=0 |
raw-output-generated-callback |
Pointer to the raw output generated callback function |
Pointer |
Cannot be set through gst-launch |
raw-output-generated-userdata |
Pointer to user data to be supplied with raw-output-generated-callback |
Pointer |
Cannot be set through gst-launch |
DeepStream Triton samples#
DeepStream Triton samples are located in the folder samples/configs/deepstream-app-triton. In terms of Triton model specification, all related models and Triton config files(config.pbtxt) must be gathered into same root directory which
is samples/triton_model_repo. Follow the instructions in samples/configs/deepstream-app-triton/README to run the samples.
DeepStream Triton gRPC support#
In addition to native Triton server, gst-nvinferserver supports the Triton Inference Server running as independent process. Communication to the server happens through gRPC.
Config files to run the application in gRPC mode are located at samples/config/deepstream-app-triton-grpc. Follow the instructions in samples/configs/deepstream-app-triton-grpc/README to run the samples.
Triton Ensemble Models#
The Gst-nvinferserver plugin can support Triton ensemble models for further custom preprocessing, backend and postprocessing through Triton custom-backends.
Triton ensemble model represents a pipeline of one or more models and the connection of input and output tensors between those models, such as “data preprocessing -> inference -> data postprocessing”. See more details
triton-inference-server/server.
To manage memory efficiency and keep clean interface, The Gst-nvinferserver Plugin’s default preprocessing cannot be disabled. Color conversion, datatype conversion, input scaling and object cropping are continue working in nvds_infer_server natively. For example, in the case native normalization is not needed, update scale_factor to 1.0:
infer_config { preprocess { network_format: IMAGE_FORMAT_RGB tensor_order: TENSOR_ORDER_LINEAR normalize { scale_factor: 1.0 } } }
The low level nvds_infer_server library could deliver specified media-format (RGB/BGR/Gray) in any kind of tensor orders and datatypes as a CUDA GPU buffer input to Triton backend. User’s custom-backend must support GPU memory on this input. Triton custom-backend sample identity can work with Gst-nvinferserver plugin.
Note
Custom backend API must have same Triton codebase version (25.08 for Jetson, 26.01 for x86). Read more details from Triton server releases: x86 release and Jetson release.
To learn details how to implement Triton custom-backend, refer to Triton custom-backend.
For Triton model’s output, TRTSERVER_MEMORY_GPU and TRTSERVER_MEMORY_CPU buffer allocation are supported in nvds_infer_server according to Triton output request. This also works for ensemble model’s final output tensors.
Finally, inference data can be parsed by default for detection, classification, or semantic segmentation. Alternatively, user can implement custom-backend for postprocessing, then deliver the final output to Gst-nvinferserver plugin to do further processing. Besides that, User can also optionally attach raw tensor output data into metadata for downstream or application to parse.
Custom Process interface IInferCustomProcessor for Extra Input, LSTM Loop, Output Tensor Postprocess#
Gst-nvinferserver plugin supports extra(multiple) input tensors custom preprocessing, input / output tensor custom loop processing (LSTM-based) with multiple streams, output tensor data custom parsing and attaching into NvDsBatchMeta. This custom function is loaded though gst-nvinferserver’s config file:
infer_config {
backend {
triton {
model_name: "yolov3-10_onnx"
# option 1: for CAPI inference
# model_repo { root: "./model_repo" }
# option 2: for gRPC inference
# grpc { url: "localhost:8001" }
}
# specify output tensor memory type, MEMORY_TYPE_CPU/MEMORY_TYPE_GPU
output_mem_type: MEMORY_TYPE_CPU
}
preprocess { ... } # specify scale and normalization
# postprocess{ other{} } # skip generic postprocess
# specify custom processing library
custom_lib {
path: "/path/to/libnvdsinferserver_custom_process.so"
}
extra {
# specify custom processing function entrypoint from custom_lib
custom_process_funcion: "CreateInferServerCustomProcess"
}
}
The interface IInferCustomProcessor is defined in sources/includes/nvdsinferserver/infer_custom_process.h.
class IInferCustomProcessor {
virtual void supportInputMemType(InferMemType& type); // return supported memory type for `extraInputs`
virtual bool requireInferLoop() const; // indicate whether LSTM loop is needed. return 'false' if not needed.
// custom implementation for extra input tensors processing, `primaryInputs` is processed by preprocess{} from config file.
// param `options` is helpful to carry extra information such as stream_ids, `NvBufSurface`, `NvDsBatchMeta`, `GstBuffer`
virtual NvDsInferStatus extraInputProcess(const vector<IBatchBuffer*>& primaryInputs, vector<IBatchBuffer*>& extraInputs, const IOptions* options) = 0;
// param `outputs` is a array of all batched output tensors. param `inOptions` is same as extraInputProcess
virtual NvDsInferStatus inferenceDone(const IBatchArray* outputs, const IOptions* inOptions) = 0;
virtual void notifyError(NvDsInferStatus status) = 0;
};
Users need derive from IInferCustomProcessor to implement their own extra preprocessing through extraInputProcess and fully postprocessing through inferenceDone. the param structured in IOptions carry all information from GstBuffer and NvDsBatchMeta. Users can query them through IOptions for each frame and batch.
see more examples in /opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp
Take a example for a simple postprocessing to add output tensors.
#include <inttypes.h>
#include <unistd.h>
#include <cassert>
#include <unordered_map>
#include "infer_custom_process.h"
#include "nvbufsurface.h"
#include "nvdsmeta.h"
typedef struct _GstBuffer GstBuffer;
using namespace nvdsinferserver;
#define INFER_ASSERT assert
class NvInferServerCustomProcess : public IInferCustomProcessor {
// memtype for ``extraInputs``, set ``kGpuCuda`` for performance
void supportInputMemType(InferMemType& type) override { type = InferMemType::kGpuCuda; }
// for LSTM loop. return false if not required.
bool requireInferLoop() const override { return false; }
// skip extraInputProcess if there is no extra input tensors
NvDsInferStatus extraInputProcess(const std::vector<IBatchBuffer*>& primaryInputs, std::vector<IBatchBuffer*>& extraInputs, const IOptions* options) override {
return NVDSINFER_SUCCESS;
}
// output tensor postprocessing function.
NvDsInferStatus inferenceDone(const IBatchArray* outputs, const IOptions* inOptions) override
{
GstBuffer* gstBuf = nullptr;
std::vector<uint64_t> streamIds;
NvDsBatchMeta* batchMeta = nullptr;
std::vector<NvDsFrameMeta*> frameMetaList;
NvBufSurface* bufSurf = nullptr;
std::vector<NvBufSurfaceParams*> surfParamsList;
int64_t unique_id = 0;
INFER_ASSERT (inOptions->getValueArray(OPTION_NVDS_SREAM_IDS, streamIds) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getObj(OPTION_NVDS_BUF_SURFACE, bufSurf) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getObj(OPTION_NVDS_BATCH_META, batchMeta) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getInt(OPTION_NVDS_UNIQUE_ID, unique_id) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getValueArray(OPTION_NVDS_BUF_SURFACE_PARAMS_LIST, surfParamsList) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getValueArray(OPTION_NVDS_FRAME_META_LIST, frameMetaList) == NVDSINFER_SUCCESS);
uint64_t nsTimestamp = UINT64_MAX; // nano-seconds
if (inOptions->hasValue(OPTION_TIMESTAMP)) {
INFER_ASSERT(inOptions->getUInt(OPTION_TIMESTAMP, nsTimestamp) == NVDSINFER_SUCCESS);
}
std::unordered_map<std::string, SharedIBatchBuffer> tensors;
for (uint32_t i = 0; i < outputs->getSize(); ++i) {
SharedIBatchBuffer outTensor = outputs->getSafeBuf(i);
INFER_ASSERT(outTensor);
auto desc = outTensor->getBufDesc();
tensors.emplace(desc.name, outTensor);
}
// parsing output tensors
float* boxesPtr = (float*)tensors["output_bbox"]->getBufPtr(0);
auto& bboxDesc = tensors["output_bbox"]->getBufDesc();
float* scoresPtr = (float*)tensors["output_score"]->getBufPtr(0);
float* numPtr = (float*)tensors["output_bbox_num"]->getBufPtr(0);
int32_t batchSize = bboxDesc.dims.d[0]; // e.g. tensor shape [Batch, num, 4]
std::vector<std::vector<NvDsInferObjectDetectionInfo>> batchedObjs(batchSize);
// parsing data into batchedObjs
...
// attach to NvDsBatchMeta
for (int iB = 0; iB < batchSize; ++iB) {
const auto& objs = batchedObjs[iB];
for (const auto& obj : objs) {
NvDsObjectMeta* objMeta = nvds_acquire_obj_meta_from_pool(batchMeta);
objMeta->unique_component_id = unique_id;
objMeta->confidence = obj.detectionConfidence;
objMeta->class_id = obj.classId;
objMeta->rect_params.left = obj.left;
objMeta->rect_params.top = obj.top;
objMeta->rect_params.width = obj.width;
objMeta->rect_params.height = obj.height;
// other settings
...
// add NvDsObjectMeta obj into NvDsFrameMeta frame.
nvds_add_obj_meta_to_frame(frameMetaList[iB], objMeta, NULL);
}
}
}
};
extern "C" {
IInferCustomProcessor* CreateInferServerCustomProcess(const char* config, uint32_t configLen)
{
return new NvInferServerCustomProcess();
} }
For extra input tensors preprocess: If the model requires multiple tensor inputs more than the primary image input, Users can derive from this interface IInferCustomProcessor and implement extraInputProcess() to process extra inputs tensors. This function is for extra input process only. the parameter IOptions* options would carry all the information from GstBuffer, NvDsBatchMeta, NvDsFrameMeta, NvDsObjectMeta and so on. User can leverage all of the information from options to fill the extra input tensors. All of the input tensor memory is allocated by nvdsinferserver low-level lib.
For output tensor postprocess(parsing and metadata attaching): If user want to do custom parsing on output tensors into user metadata and attach them into GstBuffer, NvDsBatchMeta, NvDsFrameMeta or NvDsObjectMeta. User can implement ‘inferenceDone(outputs, inOptions)’ to parse all output tensors in outputs, and get above GstBuffer, NvDsBatchMeta and other DeepStream information from inOptions. Then attach the parsed user metadata into NvDs metadata. This function supports multiple-streams parsing and attaching. See examples in
/opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp: NvInferServerCustomProcess::inferenceDone()how to parse and attach output metadata.Note
If user need specific memory type(e.g. CPU) for output tensors in inferenceDone(). Update config file.
infer_config { backend { output_mem_type: MEMORY_TYPE_CPU } }For multi-stream custom loop process: If the model is LSTM based, and next frame’s inputs are generated by previous frame’s output data. User can derive interface IInferCustomProcessor, then implement extraInputProcess() and inferenceDone() for loop process. extraInputProcess() could initialize first input tensor states. Then ‘inferenceDone()’ can get the output data and do post processing and store the result into the context. When next ‘extraInputProcess()’ is coming, it can check the stored results and feedback into tensor states. When user override
bool requireInferLoop() const { return true; }. The nvdsinferver low-level lib shall keep the extraInputProcess and inferenceDone running in sequence along with its nvds_stream_ids which could be get fromoptions->getValueArray(OPTION_NVDS_SREAM_IDS, streamIds). see examples and details in/opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp. Inside this example, see functionNvInferServerCustomProcess::feedbackStreamInputhow to feedback output into next input loop.
Tensor Metadata Output for Downstream Plugins#
The Gst-nvinferserver plugin can attach raw output tensor data generated by the inference backend as metadata. It is added as an NvDsInferTensorMeta in the frame_user_meta_list member of NvDsFrameMeta for primary (full frame) mode, or in the obj_user_meta_list member of NvDsObjectMeta for secondary (object) mode. It uses same metadata structure with Gst-nvinferserver plugin.
Note
Gst-nvinferserver plugin does not attach device buffer pointer NvDsInferTensorMeta::attach out_buf_ptrs_dev at this moment.
To read or parse inference raw tensor data of output layers#
Enable the following fields in the configuration file for the Gst-nvinferserver plugin:
output_control { output_tensor_meta : true }If native postprocessing need be disabled, update:
infer_config { postprocess { other {} } }When operating as primary GIE,
NvDsInferTensorMetais attached to each frame’s (each NvDsFrameMeta object’s)frame_user_meta_list. When operating as secondary GIE, NvDsInferTensorMeta is attached to each NvDsObjectMeta object’sobj_user_meta_list.Metadata attached by Gst-nvinferserver can be accessed in a GStreamer pad probe attached downstream from the Gst-nvinferserver instance.
The
NvDsInferTensorMetaobject’s metadata type is set to NVDSINFER_TENSOR_OUTPUT_META. To get this metadata you must iterate over the NvDsUserMeta user metadata objects in the list referenced byframe_user_meta_listor obj_user_meta_list.
For more information about Gst-infer tensor metadata usage, see the source code in
sources/apps/sample_apps/deepstream_infer_tensor_meta-test.cpp, provided in the DeepStream SDK samples.
Segmentation Metadata#
The Gst-nvinferserver plugin attaches the output of the semantic segmentation model as user metadata in an instance of NvDsInferSegmentationMeta with meta_type set to NVDSINFER_SEGMENTATION_META. The user metadata is added to the frame_user_meta_list member of NvDsFrameMeta for primary (full frame) mode, or the obj_user_meta_list member of NvDsObjectMeta for secondary (object) mode. For guidance on how to access user metadata, see User/Custom Metadata Addition Inside NvDsMatchMeta and Tensor Metadata, above.