Gst-nvtracker#
The Gst-nvtracker plugin allows the DS pipeline to use a low-level tracker library to track the detected objects over time persistently with unique IDs. It supports any low-level library that implements NvDsTracker API, including the reference implementations provided by the NvMultiObjectTracker library: IOU, NvSORT, NvDCF, MaskTracker and NvDeepSORT trackers. As part of this API, the plugin queries the low-level library for capabilities and requirements concerning the input format, memory type, and additional feature support. Based on these queries, the plugin then converts the input frame buffers into the format requested by the low-level tracker library. For example, NvDCF, MaskTracker, and NvDeepSORT trackers use NV12 or RGBA, while IOU and NvSORT requires no video frame buffers at all.
Based on the queries, the Gst-nvtracker plugin constructs the input data to the low-level tracker library, which consists of video frames and detected objects across multiple streams that are fed to the low-level library in a single data structure (i.e, a frame batch) through a single API call. This API design allows all the input data from multiple streams in the low-level tracker library processed in a batched processing mode (similar to the batch mode in cuFFT™, cuBLAS™, etc.) for potentially more efficient execution especially when accelerated on GPU. There for, it is required that the low-level tracker supports batch processing when using NvMOT_Process API.
The Gst-nvtracker plugin supports retrieval of the user-defined miscellaneous data from the low-level tracker library through NvMOT_RetrieveMiscData API, which includes useful object tracking information other than the default data for the current frame targets; for example, past-frame object data, targets in shadow tracking mode, full trajectory of terminated targets and re-identification features. More details on the types of miscellaneous data and what they means can be found in Miscellaneous Data Output section. The users are allowed to define other types of miscellaneous data in NvMOTTrackerMiscData.
More details on all these tracker APIs is discussed in NvDsTracker API for Low-Level Tracker Library section.
The plugin accepts NV12- or RGBA-formatted frame data from the upstream component and scales (and/or converts) the input buffer to a buffer in the tracker plugin based on the format required by the low-level library, with the frame resolution specified by tracker-width and tracker-height in the configuration file’s [tracker] section. The path to the low-level tracker library is to be specified via ll-lib-file configuration option in the same section. The low-level library to be used may also require its own configuration file, which can be specified via ll-config-file option. If ll-config-file is not specified, the low-level tracker library may proceed with its default parameter values.
The reference low-level tracker implementations provided by the NvMultiObjectTracker library support various types of multi-object tracking algorithms:
IOU Tracker: The Intersection-Over-Union (IOU) tracker uses the IOU values among the detector’s bounding boxes between the two consecutive frames to perform the association between them or assign a new target ID if no match found. This tracker includes a logic to handle false positives and false negatives from the object detector; however, this can be considered as the bare-minimum object tracker, which may serve as a baseline only.
NvSORT: The NvSORT tracker is the NVIDIA®-enhanced Simple Online and Realtime Tracking (SORT) algorithm. Instead of a simple bipartite matching algorithm, NvSORT uses a cascaded data association based on bounding box (bbox) proximity for associating bboxes over consecutive frames and applies a Kalman filter to update the target states. It is computationally efficient since it does not involve any pixel data processing.
NvDeepSORT: The NvDeepSORT tracker is the NVIDIA®-enhanced Online and Realtime Tracking with a Deep Association Metric (DeepSORT) algorithm, which uses the deep cosine metric learning with a Re-ID neural network for data association of multiple objects over frames. This implementation allows users to use any Re-ID network as long as it is supported by NVIDIA’s TensorRT™ framework. NvDeepSORT also uses a cascaded data association instead of a simple bipartite matching. The implementation is also optimized for efficient processing on GPU.
NvDCF: The NvDCF tracker is an online multi-object tracker that employs a discriminative correlation filter for visual object tracking, which allows independent object tracking even when detection results are not available. It uses the combination of the correlation filter responses and bounding box proximity for data association.
MaskTracker: MaskTracker simultaneously performs multi-object tracking and segmentation using advanced vision foundation models such as Segment Anything Model 2 (SAM2). It maintains high-quality segmentation and robust tracking, while automatically adding and removing targets as needed. MaskTracker can generate bounding boxes around segmentation masks, match them with detections, and fuse this information to improve bounding box accuracy. Additionally, it supports accelerated inference of the entire SAM2 network with TensorRT™.
More details on each algorithm and its implementation details can be found in NvMultiObjectTracker : A Reference Low-Level Tracker Library section.
Note
The source code of the Gst-nvtracker plugin is provided as a part of DeepStream SDK package under sources/gst-plugins/gst-nvtracker/ when installed on a system This is to allow users to make direct changes in the plugin whenever needed for their custom applications and also to show the users as to how the low-level libraries are managed and how the metadata is handled in the plugin.
Inputs and Outputs#
This section summarizes the inputs, outputs, and communication facilities of the Gst-nvtracker plugin.
Input
Gst Buffer
A frame batch from available source streams
NvDsBatchMetaIncludes the detected object info from primary inference module
More details about NvDsBatchMeta can be found in the link.
The color formats supported for the input video frame by the NvTracker plugin are NV12 and RGBA. A separate batch of video frames are created from the input video frames based on the color format and the resolution that is required to the low-level tracker library.
Output
Gst Buffer
Same as the input. Unmodified.
NvDsBatchMetaUpdated with additional data from tracker low-level library
There’s no separate data structure for the output. Instead, the tracker plugin just adds/updates the data in the existing NvDsBatchMeta (and its NvDsObjectMeta) with the output data from the tracker low-level library, including tracked object coordinates, tracker confidence, and object IDs. There are some other miscellaneous data that can be attached as user-meta, which is covered in Miscellaneous Data Output section.
Note
If the tracker algorithm does not generate confidence value, then tracker confidence value will be set to the default value (i.e., 1.0) for tracked objects. For IOU, NvSORT and NvDeepSORT trackers, tracker_confidence is set to 1.0 as these algorithms do not generate confidence values for tracked objects. NvDCF tracker, on the other hand, generates confidence for the tracked objects due to its visual tracking capability, and its value is set in tracker_confidence field in NvDsObjectMeta structure.
Note that there are separate parameters in NvDsObjectMeta for detector’s confidence and tracker’s confidence, which are confidence and tracker_confidence, respectively. MaskTracker also fills the segmentation mask information in mask_params field. More details can be found in New metadata fields
The operate-on-class-ids property allows filtering objects based on their class IDs. When class IDs are specified, only objects with matching class IDs will have tracker metadata. Metadata for other objects will be copied directly to downstream without tracking. If class IDs are not specified or are empty, all classes are tracked by default.
Sub-batching#
The Gst-nvtracker plugin works in the batch processing mode by default. In this mode, the input frame batch is passed to and processed by a single instance of low-level tracker library. The advantage of batch processing mode is to allow GPUs to work on bigger amount of data at once, potentially increasing the GPU occupancy during execution and reducing the CUDA kernel launch overhead. Depending on the use cases, however, a potential issue is that there is a possibility that GPU could be idling (also referred to as GPU bubble) in some compute stages in the tracker unless the end-to-end operation within the module is carried out solely on the GPU. This is indeed the case if some of the compute modules in the tracker runs on CPU. If there are other components in the DeepStream pipeline that uses GPU (e.g., GPU-based inference in PGIE and SGIE), such CPU blocks in tracker can be hidden behind them, not affecting the overall throughput of the pipeline.
The newly-introduced Sub-batching feature allows the plugin to split the input frame batch into multiple sub-batches (for example, a four-stream pipeline can use two sub-batches in the tracker plugin, each of which takes care of two streams). Each sub-batch is assigned to a separate instance of low-level tracker library, where the input to the corresponding sub-batch is processed separately. Each instance of low-level tracker libraries runs on a dedicated thread running independently, allowing parallel processing of sub-batches and minimizing the GPU idling due to CPU compute blocks, which eventually results in higher resource utilization.
Because sub-batching assigns separate low-level tracker library instances to different sub-batches, it allows the user to configure each individual sub-batch differently with different low-level tracker library configuration files. This can be utilized in multiple ways like setting varied compute backends across sub-batches, using varied tracking algorithms across sub-batches or modifying any other configuration that is supported in low-level tracker configuration file. Each VPI™ backend low-level tracker library supports at most 128 streams, so when running more than 128 streams, users need to configure the sub-batching to run multiple instances of the low-level tracker library. More detailed example use-cases are discussed in Setup and Usage of Sub-batching section.
Features#
The following table summarizes the features of the plugin.
Feature |
Description |
Release |
|---|---|---|
Configurable tracker width/height |
Frames are internally scaled in NvTracker plugin to the specified resolution for tracking and passed to the low-level lib |
DS 2.0 |
Multi-stream CPU/GPU tracker |
Supports tracking on batched buffers consisting of frames from multiple sources |
DS 2.0 |
NV12 Input |
DS 2.0 |
|
RGBA Input |
DS 3.0 |
|
Configurable GPU device |
User can select GPU for internal scaling/color format conversions and tracking |
DS 2.0 |
Dynamic addition/deletion of sources at runtime |
Supports tracking on new sources added at runtime and cleanup of resources when sources are removed |
DS 3.0 |
Support for user’s choice of low-level library |
Dynamically loads user selected low-level library |
DS 4.0 |
Support for batch processing exclusively |
Supports sending frames from multiple input streams to the low-level library |
DS 4.0 |
Multiple buffer formats as input to low-level library |
Converts input buffer to formats requested by the low-level library, for up to 4 formats per frame |
DS 4.0 |
Enabling tracking-id display |
Supports enabling or disabling display of tracking-id |
DS 5.0 |
Tracking ID reset based on event |
Based on the pipeline event (i.e., GST_NVEVENT_STREAM_EOS and GST_NVEVENT_STREAM_RESET), the tracking IDs on a particular stream can be reset to start from 0 or new IDs. |
DS 6.0 |
Tracker Miscellaneous data output |
Supports outputting user defined miscellaneous data (including object Re-ID features, the past-frame data, a list of terminated tracks, etc. ) if the low-level library supports the capability |
DS 6.3 |
Support for NVIDIA’s VPI™ based Crop-scaler and DCF-Tracker algorithms in NvDCF tracker |
DS 6.4 |
|
PVA-backend for NvDCF via VPI™’s unified API |
Allow PVA-based execution of a significant part of NvDCF on Jetson to achieve lower GPU utilization |
DS 6.4 |
Sub-batching |
Supports splitting of a batch of frames in sub-batches which are internally processed in parallel resulting in higher resource utilization. This feature also enables specification of a different config file for each sub-batch. |
DS 6.4 |
Single-View 3D Tracking |
Allow 3D world coordinate system based object tracking when camera/model info (3x4 projection matrix and 3D human model info) is provided for better handling of partial occlusion |
DS 6.4 |
MaskTracker (Developer Preview) |
A new algorithm for multi-object tracking and segmentation using SAM2 as visual tracking engine |
DS 8.0 |
Gst Properties#
The following table describes the Gst properties of the Gst-nvtracker plugin.
Property |
Meaning |
Type and Range |
Example Notes |
|---|---|---|---|
tracker-width |
Frame width at which the tracker is to operate, in pixels. |
Integer, 0 to 4,294,967,295 |
tracker-width=640 |
tracker-height |
Frame height at which the tracker is to operate, in pixels. |
Integer, 0 to 4,294,967,295 |
tracker-height=384 |
ll-lib-file |
Pathname of the low-level tracker library to be loaded by Gst-nvtracker. |
String |
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so |
ll-config-file |
Configuration file for the low-level library if needed. A list of configuration files can be specified when the property sub-batches is configured. |
Path to configuration file OR A list of paths to configuration files delimited by semicolon |
ll-config-file=config_tracker_NvDCF_perf.yml ll-config-file=config_tracker_NvDCF_perf1.yml; config_tracker_NvDCF_perf2.yml |
gpu-id |
ID of the GPU on which device/unified memory is to be allocated, and with which buffer copy/scaling is to be done. (dGPU only.) |
Integer, 0 to 4,294,967,295 |
gpu-id=0 |
tracking-surface-type |
Set surface stream type for tracking. (default value is 0) |
Integer, ≥0 |
tracking-surface-type=0 |
display-tracking-id |
Enables tracking ID display on OSD. |
Boolean |
display-tracking-id=1 |
compute-hw |
Compute engine to use for scaling. 0 - Default 1 - GPU 2 - VIC (Jetson only) |
Integer, 0 to 2 |
compute-hw=1 |
tracking-id-reset-mode |
Allow force-reset of tracking ID based on pipeline event. Once tracking ID reset is enabled and such event happens, the lower 32-bit of the tracking ID will be reset to 0 0: Not reset tracking ID when stream reset or EOS event happens 1: Terminate all existing trackers and assign new IDs for a stream when the stream reset happens (i.e., GST_NVEVENT_STREAM_RESET) 2: Let tracking ID start from 0 after receiving EOS event (i.e., GST_NVEVENT_STREAM_EOS) (Note: Only the lower 32-bit of tracking ID to start from 0) 3: Enable both option 1 and 2 |
Integer, 0 to 3 |
tracking-id-reset-mode=0 |
input-tensor-meta |
Use the tensor-meta from Gst-nvdspreprocess if available for tensor-meta-gie-id |
Boolean |
input-tensor-meta=1 |
tensor-meta-gie-id |
Tensor Meta GIE ID to be used, property valid only if input-tensor-meta is TRUE |
Unsigned Integer, ≥0 |
tensor-meta-gie-id=5 |
sub-batches |
Configures splitting of a batch of frames in sub-batches. There are two ways to configure sub-batches. First option allows static mapping of each source id to individual sub-batch. Second option lets the user configure the sub-batch sizes. Mapping of individual streams to sub-batch happens dynamically at runtime. |
Option 1 : Semicolon delimited integer array where each number corresponds to source id. Must include all values from 0 to (batch-size -1) where batch-size is configured in Option 2 : Colon delimited integer array where each number corresponds to size of a sub-batch (i.e. max number of stream a sub-batch can accommodate) |
Option 1 : sub-batches=0,1;2,3 In this example, a batch size of 4 is split into two sub-batches where the first sub-batch consists of source ids 0 & 1 and second sub-batch consists of source ids 2 & 3 Option 2 : sub-batches=2:1 The above example indicates that there are two sub-batches, first one can accommodate 2 streams and second one can accommodate 1. |
sub-batch-err-recovery-trial-cnt (Alpha feature) |
Configure the number of times the plugin can try to recover when the low level tracker in a sub-batch returns with a fatal error. To recover from the error, the plugin reinitializes the low level tracker library. |
Integer,≥-1 where, -1 corresponds to infinite trials |
sub-batch-err-recovery-trial-cnt=3 |
user-meta-pool-size |
The size of tracker miscellaneous data buffer pool |
Unsigned Integer, >0 |
user-meta-pool-size=32 |
operate-on-class-ids |
Filtering objects based on class ID. When class IDs are specified, only objects with matching class IDs will have tracker metadata. Metadata for other objects will be copied directly to downstream without tracking. If class IDs are not specified or are empty, all classes are tracked by default. |
Semicolon-separated list of class IDs (String) |
operate-on-class-ids=1;2 |
NvDsTracker API for Low-Level Tracker Library#
A low-level tracker library can be implemented using the API defined in sources/includes/nvdstracker.h. Parts of the API refer to sources/includes/nvbufsurface.h. The names of API functions and data structures are prefixed with NvMOT, which stands for NVIDIA Multi-Object Tracker. Below is the general flow of the API from a low-level library’s perspective:
The first required function is:
NvMOTStatus NvMOT_Query ( uint16_t customConfigFilePathSize, char* pCustomConfigFilePath, NvMOTQuery *pQuery );
The plugin uses this function to query the low-level library’s capabilities and requirements before it starts any processing sessions (i.e., contexts) with the library. Queried properties include the input frame’s color format (e.g., RGBA or NV12) and memory type (e.g., NVIDIA® CUDA® device or CPU-mapped NVMM).
The plugin performs this query once during initialization stage, and its results are applied to all contexts established with the low-level library. If a low-level library configuration file is specified, it is provided in the query for the library to consult. The query reply structure,
NvMOTQuery, contains the following fields:NvMOTCompute computeConfig: Report compute targets supported by the library. The plugin currently only echoes the reported value when initiating a context.uint8_t numTransforms: The number of color formats required by the low-level library. The valid range for this field is0toNVMOT_MAX_TRANSFORMS. Set this to0if the library does not require any visual data.Note
0does not mean that untransformed data will be passed to the library.NvBufSurfaceColorFormat colorFormats[NVMOT_MAX_TRANSFORMS]: The list of color formats required by the low-level library. Only the firstnumTransformsentries are valid.NvBufSurfaceMemType memType: Memory type for the transform buffers. The plugin allocates buffers of this type to store color- and scale-converted frames, and the buffers are passed to the low-level library for each frame. The support is currently limited to the following types:dGPU:
NVBUF_MEM_CUDA_PINNED NVBUF_MEM_CUDA_UNIFIED
Jetson:
NVBUF_MEM_SURFACE_ARRAYbool supportBatchProcessing: True if the low-level library supports the batch processing across multiple streams; otherwise false.bool supportPastFrame: True if the low-level library supports outputting the past-frame data; otherwise false.
After the query, and before any frames arrive, the plugin must initialize a context with the low-level library by calling:
NvMOTStatus NvMOT_Init ( NvMOTConfig *pConfigIn, NvMOTContextHandle *pContextHandle, NvMOTConfigResponse *pConfigResponse );
The context handle is opaque outside the low-level library. In the batch processing mode, the plugin requests a single context for all input streams. In per-stream processing mode, on the other hand, the plugin makes this call for each input stream so that each stream has its own context. This call includes a configuration request for the context. The low-level library has an opportunity to:
Review the configuration and create a context only if the request is accepted. If any part of the configuration request is rejected, no context is created, and the return status must be set to
NvMOTStatus_Error. ThepConfigResponsefield can optionally contain status for specific configuration items.Pre-allocate resources based on the configuration.
Note
In the
NvMOTMiscConfigstructure, thelogMsgfield is currently unsupported and uninitialized.The
customConfigFilePathpointer is only valid during the call.
Once a context is initialized, the plugin sends frame data along with detected object bounding boxes to the low-level library whenever it receives such data from upstream. It always presents the data as a batch of frames, although the batch can contain only a single frame in per-stream processing contexts. Note that depending on the frame arrival timings to the tracker plugin, the composition of frame batches could either be a full batch (that contains a frame from every stream) or a partial batch (that contains a frame from only a subset of the streams). In either case, each batch is guaranteed to contain at most one frame from each stream.
The function call for this processing is:
NvMOTStatus NvMOT_Process ( NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackedObjBatch *pTrackedObjectsBatch );, where:
pParamsis a pointer to the input batch of frames to process. The structure contains a list of one or more frames, with at most one frame from each stream. Thus, no two frame entries have the samestreamID. Each entry of frame data contains a list of one or more buffers in the color formats required by the low-level library, as well as a list of object attribute data for the frame. Most libraries require at most one-color format.
pTrackedObjectsBatchis a pointer to the output batch of object attribute data. It is pre-populated with a value fornumFilled, which is the same as the number of frames included in the input parameters.If a frame has no output object attribute data, it is still counted in
numFilledand is represented with an empty list entry (NvMOTTrackedObjList). An empty list entry has the correctstreamIDset and numFilled set to0.Note
The output object attribute data
NvMOTTrackedObjcontains a pointer to the detector object (provided in the input) that is associated with a tracked object, which is stored inassociatedObjectIn. You must set this to the associated input object only for the frame where the input object is passed in. For a pipeline with PGIEinterval=1, for example:
Frame 0:
NvMOTObjToTrackXis passed in. The tracker assigns it ID 1, and the output object’sassociatedObjectInpoints toX.Frame 1: Inference is skipped, so there is no input object from detector to be associated with. The tracker finds Object 1, and the output object’s
associatedObjectInpoints toNULL.Frame 2:
NvMOTObjToTrackYis passed in. The tracker identifies it as Object 1. The output Object 1 hasassociatedObjectInpointing toY.
Depending on the capability of the low-level tracker, there could be some user-defined miscellaneous data to report to tracker plugin.
batch_user_meta_listinNvDsBatchMetaas a user-meta:NvMOTStatus NvMOT_RetrieveMiscData ( NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackerMiscData *pTrackerMiscData );
where:
pParamsis a pointer to the input batch of frames to process. This structure is needed to check the list of stream ID in the batch.
pTrackerMiscDatais a pointer to the output miscellaneous data for the current batch to be filled by the low-level tracker. The data structureNvMOTTrackerMiscDatais defined innvdstracker.h.
In case that a video stream source is removed on the fly, the plugin calls the following function so that the low-level tracker library can remove it as well. Note that this API is optional and valid only when the batch processing mode is enabled, meaning that it will be executed only when the low-level tracker library has an actual implementation for the API. If called, the low-level tracker library can release any per-stream resource that it may be allocated:
void NvMOT_RemoveStreams ( NvMOTContextHandle contextHandle, NvMOTStreamId streamIdMask );
When all processing is complete, the plugin calls this function to clean up the context and deallocate its resources:
void NvMOT_DeInit (NvMOTContextHandle contextHandle);
NvMultiObjectTracker : A Reference Low-Level Tracker Library#
Multi-object tracking (MOT) is a key building block for a large number of intelligent video analytics (IVA) applications that requires spatio-temporal analysis of objects of interest to draw further insights about the objects’ behaviors in long term. Given a set of detected objects from the Primary GIE (PGIE) module on a single or multiple streams and with the APIs defined to work with the tracker plugin, the low-level tracker library is expected to carry out actual multi-object tracking operations to keep persistent IDs to the same objects over time.
DeepStream SDK provides a single reference low-level tracker library, called NvMultiObjectTracker, that implements all four low-level tracking algorithms (i.e., IOU, NvSORT, NvDeepSORT, and NvDCF) in a unified architecture. It supports multi-stream, multi-object tracking in the batch processing mode for efficient processing on CPU and GPU (and PVA for Jetson). The following sections will cover the unified tracker architecture and the details of each reference tracker implementation.
Unified Tracker Architecture for Composable Multi-Object Tracker#
In NvMultiObjectTracker low-level tracker library, different types of multi-object trackers share common modules when it comes to basic functionalities (e.g., data association, target management, state estimation, etc.), while differing in other core functionalities (e.g., visual tracking for NvDCF and deep association metric for NvDeepSORT). The NvMultiObjectTracker library employs a unified architecture to allow the composition of a multi-object tracker through configuration by enabling only the modules required for a particular object tracker. The IOU tracker, for example, requires a minimum set of modules that consist of data association and target management modules. On top of that, NvSORT adds a state estimator for more accurate motion estimation & prediction, and NvDeepSORT further introduces a deep Re-ID network to integrate appearance information into data association. Instead of the deep neural network-based Re-ID features in NvDeepSORT, NvDCF employs a Discriminative Correlation Filter (DCF)-based visual tracking module that uses conventional feature descriptors for more efficient tracking. However, NvDCF can still allow the use of Re-ID module for target re-association for longer-term robustness. MaskTracker utilizes SAM2 as visual tracking module and generates bounding boxes around segmentation masks for data association with detections.
The table below summarizes what modules are used to compose each object tracker, showing what modules are shared across different object trackers and how each object tracker differs in module composition:
Tracker Type |
State Estimator |
Target Management |
Visual Tracker |
Target Re-Association |
Data Association Metric |
|||
|---|---|---|---|---|---|---|---|---|
Spatio- temporal |
Re-ID |
Proximity & Size |
Visual Similarity |
Re-ID |
||||
IOU |
O |
O |
||||||
NvSORT |
O |
O |
O |
|||||
NvDeepSORT |
O |
O |
O |
O |
||||
NvDCF |
O |
O |
O |
O |
O |
O |
O |
|
MaskTracker |
O |
O |
O (SAM2) |
O (SAM2) |
||||
In the following sections, we will first discuss the general work flow of the NvMultiObjectTracker library and its core modules, and then each type of object trackers in more details with explanations on the config params in each module.
Workflow and Core Modules in The NvMultiObjectTracker Library#
The input to a low-level tracker library consists of (1) a batch of video frames from a single or multiple streams and (2) a list of detector objects for each video frame. If the detection interval (i.e., interval in Primary GIE section) is set larger than 0, the input data to the low-level tracker would have the detector object data only when the inferencing for object detection is performed for a video frame batch (i.e., the inferenced frame batch). For the frame batches where the inference is skipped (i.e., the uninferenced frame batch), the input data would include only the video frames.
Note
A detector object refers to an object that is detected by the detector in PGIE module, which is provided to the multi-object tracker module as an input.
A target refers to an object that is being tracked by the object tracker.
An inferenced frame is a video frame where an inference is carried out for object detection. Since the inference interval can be configured in setting for PGIE and can be larger than zero, the
frameNumof two consecutive inferenced frames may not be contiguous.
For carrying out multi-object tracking operations with the given input data, below are the essential functionalities to be performed. Multithreading is deployed to optimize their performance on CPU.
Data association between the detector objects from a new video frame and the existing targets for the same video stream
Target management based on the data association results, including the target state update and the creation and termination of targets
Depending on the tracker types, there could be some addition processing before data association. For example, NvDeepSORT extracts Re-ID features from all the detector objects and computes the similarity, while NvDCF performs the visual tracker based localization so the targets’ predicted locations in a new frame can be used for data association. More details will be covered in each tracker’s section.
Data Association#
For data association, various types of similarity metrics are used to calculate the matching score between the detector objects and the existing targets, including:
Location similarity (i.e., proximity)
Bounding box size similarity
Re-ID feature similarity (specific to NvDeepSORT tracker)
Visual appearance similarity (specific to NvDCF tracker)
For the proximity between detector objects and targets, IOU is a typical metric that is widely used, but it also depends on the size similarity between them. The similarity of the box size between two objects can be used explicitly, which is calculated as the ratio of the size of the smaller box over the larger one.
The total association score for a pair of detector object and target is the weighted sum of all the metrics:
\[totalScore=w_1*IOU+w_2*sizeSimilarity+w_3*reidSimilarity+w_4*visualSimilarity\]
where \(w_i\) is the weight for each metric set in config file. Users can also set a minimum threshold for each similarity and the total score.
During the matching, a detector object is associated with a target that belongs to the same class by default to minimize the false matching. However, this can be disabled by setting checkClassMatch: 0, allowing objects can be associated regardless of their object class IDs. This can be useful when employing a detector like YOLO, which can detect many classes of objects, where there could be false classification on the same object over time.
Regarding the matching algorithm, users can set associationMatcherType as 0 to employ an efficient greedy algorithm for optimal bipartite matching with similarity metrics defined above, or 1 for a newly introduced method named cascaded data association for higher accuracy.
The cascaded data association consists of multi-stage matching, assigning different priorities and similarity metrics based on detection and target confidence. Detector objects are split into two sets, confirmed (confidence between [tentativeDetectorConfidence, 1.0]) and tentative (confidence between [minDetectorConfidence, tentativeDetectorConfidence]). Then three stage matching are performed sequentially:
Confirmed detections and validated (both active and inactive) targets
Tentative detections and active targets left
Confirmed detections left and tentative targets
The first stage uses the joint-similarity metrics defined above, while the later two stages only considers the IOU similarity, because proximity can be a more reliable metric than visual similarity or Re-ID when the detection confidence is low due to, say, partial occlusions or noise. Each stage takes different sets of bboxes as candidates and uses the efficient greedy algorithm for matching. The matched pairs are produced from each stage and combined together.
The output of the data association module consists of three sets of objects/targets:
The unmatched detector objects
The matched pairs of the detector objects and the existing targets
The unmatched targets
The unmatched detector objects are among the objects detected by a PGIE detector, yet not associated with any of the existing targets. An unmatched detector object is considered as a newly observed object that needs to be tracked, unless they are determined to be duplicates to any of the existing target. If the maximum IOU score of a new detector object to any of the existing targets is lower than minIouDiff4NewTarget, a new target tracker would be created to track the object since it is not a duplicate to an existing target.
The behavior of minIouDiff4NewTarget depends on the checkClassMatch setting in the DataAssociator configuration. When checkClassMatch: 1, minIouDiff4NewTarget is checked only against same-class targets, allowing different-class objects with high IOU overlap to both be added as new targets. Otherwise, the IOU is checked against all existing targets regardless of class.
Target Management and Error Handling#
Although a new object is detected by the detector (i.e., a detector object), there is a possibility that this may be a false positive. To suppress such noise in detection, the NvMultiObjectTracker tracker library employs a technique called Late Activation, where a newly detected object is examined for a period of time and activated for long-term tracking only if it survives such a period. To be more specific, whenever a new object is detected, a new tracker is created to track the object, but the target is initially put into the Tentative mode, which is a probationary period, whose length is defined by probationAge under TargetManagement section of the config file. During this probationary period, the tracker output will not be reported to the downstream, since the target is not validated yet; however, those unreported tracker output data (i.e., the past-frame data) are stored within the low-level tracker for later report.
The same target may be detected for the next frame; however, there could be false negative by the detector (i.e., missed detection), resulting in a unsuccessful data association to the target. The NvMultiObjectTracker library employs another technique called Shadow Tracking, where a target is still being tracked in the background for a period of time even when the target is not associated with a detector object. Whenever a target is not associated with a detector object for a given time frame, an internal variable of the target called shadowTrackingAge is incremented. Once the target is associated with a detector object, then shadowTrackingAge will be reset to zero.
If the target is in the Tentative mode and the shadowTrackingAge reaches earlyTerminationAge specified in the config file, the target will be terminated prematurely (which is referred to as Early Termination). If the target is not terminated during the Tentative mode and successfully associated with a detector object, the target is activated and put into the Active mode, starting to report the tracker outputs to the downstream. If the past-frame data is enabled, the tracked data during the Tentative mode will be reported as well, since they were not reported yet. Once a target is activated (i.e., in Active mode), if the target is not associated for a given time frame (or the tracker confidence gets lower than a threshold), it will be put into the Inactive mode, and its shadowTrackingAge will be incremented, yet still be tracked in the background. However, the target will be terminated if the shadowTrackingAge exceeds maxShadowTrackingAge.
The state transitions of a target tracker are summarized in the following diagram:
The NvMultiObjectTracker library can generate a unique ID to some extent. If enabled by setting useUniqueID: 1, each video stream will be assigned a 32-bit long random number during the initialization stage. All the targets created from the same video stream will have the same upper 32-bit of the uint64_t-type target ID set by the per-stream random number. In the meantime, the lower 32-bit of the target ID starts from 0. The randomly generated upper 32-bit number allows the target IDs from a particular video stream to increment from a random position in the possible ID space. If disabled (i.e., useUniqueID: 0, which is the default value), both the upper and lower 32-bit will start from 0, resulting in the target ID to be incremented from 0 for every run.
Note that the incrementation of the lower 32-bit of the target ID is done across the whole video streams in the same NvMultiObjectTracker library instantiation. Thus, even if the unique ID generation is disabled, the tracker IDs will be unique for the same pipeline run. If the unique ID generation is disabled, and if there are three objects for Stream 1 and two objects for Stream 2, for example, the target IDs will be assigned from 0 to 4 (instead of 0 to 2 for Stream 1 and 0 to 1 for Stream 2) as long as the two streams are being processed by the same library instantiation.
preserveStreamUpdateOrder controls whether to use single or multiple threads to update targets. If it is enabled, new IDs are generated sequentially following input stream ID order in each batch using a single thread, i.e. the objects for Stream 1 and 2 will have IDs from 0 to 2 and 3 to 4 respectively. By default, this option is disabled so target management is done with multi-threads to enable better performance but the ID order is not preserved. If the user needs consistent IDs over multiple runs for the same video source, please set preserveStreamUpdateOrder: 1 and batched-push-timeout=-1 in deepstream-app config.
The NvMultiObjectTracker library pre-allocates all the GPU memories during initialization based on:
The number of streams to be processed
The maximum number of objects to be tracked per stream (denoted as
maxTargetsPerStream)
Thus, the CPU/GPU memory usage by the NvMultiObjectTracker library is almost linearly proportional to the total number of objects being tracked, which is (number of video streams) × (maxTargetsPerStream), except the scratch memory space used by dependent libraries (such as cuFFT™, TensorRT™, etc.). Thanks to the pre-allocation of all the necessary memory, the NvMultiObjectTracker library is not expected to have memory growth during long-term run even when the number of objects increases over time.
Once the number of objects being tracked reaches the configured maximum value (i.e., maxTargetsPerStream), any new objects will be discarded until some of the existing targets are terminated. Note that the number of objects being tracked includes the targets that are being tracked in the shadow tracking mode. Therefore, NVIDIA recommends that users set maxTargetsPerStream large enough to accommodate the maximum number of objects of interest that may appear in a frame, as well as the objects that may have been tracked from the past frames in the shadow tracking mode.
The minDetectorConfidence property under BaseConfig section in a low-level tracker config file sets the confidence level below which the detector objects are filtered out.
State Estimation#
The NvMultiObjectTracker library employs two types of state estimators, both of which are based on Kalman Filter (KF): Simple-bbox KF, Regular-bbox KF, and Simple-location KF. The Simple-bbox KF has 6 states defined, which are {x, y, w, h, dx, dy}, where x and y indicate the coordinates of the top-left corner of a target bbox, while w and h the width and the height of the bbox, respectively. dx and dy denote the velocity of x and y states. The Regular-bbox KF, on the other hand, have 8 states defined, which are {x, y, w, h, dx, dy, dw, dh}, where dw and dh are the velocity of w and h states and the rest is the same as the Simple-bbox KF. The Simple-location KF has 4 states only, which are {x, y, dx, dy}. Unlike the the two KFs that estimate the bbox attributes, note that the Simple-location KF is meant to estimate the object location in either 2D camera image plane or 3D world ground plane.
All the Kalman Filter types employ a constant velocity model for generic use. The measurement vector for the Simple-bbox and Regular-bbox KF is defined as {x, y, w, h}, which represents the bbox attributes, while that for the Simple-location KF is defined as {x, y}. There is an option to use bbox aspect ratio a and its velocity da instead of w and dw when useAspectRatio is enabled, which is specially used by NvDeepSORT. In case the state estimator is used for a generic use case (like in the NvDCF tracker), the process noise variance for {x, y}, {w, h}, and {dx, dy, dw, dh} can be configured by processNoiseVar4Loc, processNoiseVar4Size, and processNoiseVar4Vel, respectively.
When a visual tracker module is enabled (like in the NvDCF tracker), there could be two different measurements from the state estimator’s point of view: (1) the bbox (or location) from the detector at PGIE and (2) the bbox (or location) from the tracker’s localization. This is because the NvDCF tracker module is capable of localizing targets using its own learned filter. The measurement noise variance for these two different types of measurements can be configured by measurementNoiseVar4Detector and measurementNoiseVar4Tracker. These parameters are expected to be tuned or optimized based on the detector’s and the tracker’s characteristics for better measurement fusion.
The usage of the state estimator in the NvDeepSORT tracker slightly differs from that for the aforementioned generic use case in that it is basically a Regular KF, yet with a couple of differences as per the original paper and the implementation (Check the references in NvDeepSORT Tracker section):
Use of the aspect ratio
aand the heighth(instead ofwandh) to estimate the bbox sizeThe process and measurement noises that are proportional to the bounding box height (instead of constant values)
To allow these differences, the state estimator module in the NvMultiObjectTracker library has a set of additional config parameters:
useAspectRatioto enable the use ofa(instead ofw)noiseWeightVar4LocandnoiseWeightVar4Velas the proportion coefficients for the measurement and velocity noise, respectively
Note that if these two parameters are set, the fixed process noise and measurement noise parameters for the generic use cases will be ignored.
Model Inference#
NvMultiObjectTracker supports different kinds of neural network models to improve the tracking accuracy, which are supported by a unified inference module using NVIDIA TensorRT™ backend for acceleration. Currently, below types of models are supported:
Re-identification: Given each target’s cropped image, extract a unique feature vector that is robust to spatial-temporal variance and occlusion. This is used in NvDeepSORT and target re-association, and the parameters are defined in
ReIDsection in the tracker config.Pose Estimation: Given each target’s cropped image, estimate the 2D and 3D key-points. These key-points are used in single (SV3DT) and multi-view 3D tracking (MV3DT) to estimate the 3D height and target foot location in the world coordinate system, and the parameters are defined in
PoseEstimatorsection in the tracker config.Target Segmentation: Given the whole frame image, prompt and past frame memory, segmentation models like SAM2 generate a segmentation mask for each target. The segmentation mask is used in MaskTracker to match targets with detections and fuse this information to improve bounding box accuracy, where the parameters are defined in
config_tracker_module_Segmenter.ymlas a separate config.
Note
Both NVIDIA TAO toolkit or third-party ONNX models are supported. Users can also setup their own models.
The setup instructions for all different types of models can be found in
/opt/nvidia/deepstream/deepstream/sources/tracker_ReID/README.Sample applications to use the latest models are also provided on GitHub:
To perform inference, the input image is first resized to the network input dimension inferDims and converted to the required colorFormat, which is either RGB or BGR. Then each pixel value is pre-processed by y = netScaleFactor*(x-offsets) where x is the initial pixel value with range [0,255], y is the corresponding output float value. This preprocessing is the same as the one used in Gst-nvinfer and Gst-nvinferserver plugins. The input is also transposed to the network’s inputOrder, which is either NCHW or NHWC. useVPICropScaler: 1 can be used to enable the VPI crop scaler, which is a hardware-accelerated crop scaler that performs above operations on GPU or PVA.
The TensorRT™ inference engine configuration is controlled through several key parameters: batchSize specifies the number of inputs processed simultaneously for optimal GPU utilization, while networkMode determines the inference precision (0=FP32, 1=FP16, 2=INT8). Model files are specified via onnxFile for ONNX format models, tltEncodedModel for TAO Toolkit encoded models, or modelEngineFile for pre-built TensorRT engines. For INT8 quantization, calibrationTableFile provides the calibration data required to maintain accuracy while achieving maximum performance. The workspaceSize parameter allocates GPU memory for TensorRT optimization and inference operations.
Target Re-Identification#
Re-identification (Re-ID) uses TensorRT™-accelerated deep neural networks to extract unique feature vectors from detected objects that are robust to spatial-temporal variance and occlusion. It has two use-cases in NvMultiObjectTracker: (1) In NvDeepSORT, the Re-ID similarity is used for data association of objects over consecutive frames.; (2) In target re-association (which will be described in more detail in the following section), the Re-ID features of targets are extracted and kept, so that they can be used for re-association with the same target if they are seemingly lost. reidType selects the mode for each aforementioned use-case.
In the Re-ID module, the detector objects are cropped and resized into the configured input size of the Re-ID network. The parameter keepAspc controls whether the object’s aspect ratio is preserved after cropping. Then NVIDIA TensorRT™ creates an engine from the network, which processes the input in batches and outputs a fixed-dimensional vector for each detector object as the Re-ID feature. The cosine similarity function requires each feature’s L2 norm normalized to 1. Check Re-ID Feature Output on how to retrieve these features in the tracker plugin and downstream modules. For each target, a gallery of its Re-ID features in most recent frames are kept internally. The size of the feature gallery can be set by reidHistorySize.
Note
config_tracker_NvDeepSORT.yml and config_tracker_NvDCF_accuracy.yml configs use ReIdentificationNet by default, which is a ResNet-50 Re-ID network in NVIDIA TAO toolkit on NGC. Users need to follow instructions in Setup Sample Re-ID Models to setup, or check Customize Re-ID Model for more information on adding a custom Re-ID model for object tracking with different architectures and datasets.
The Re-ID similarity between a detector object and a target is the cosine similarity between the detector object’s Re-ID feature and its nearest neighbor in the target’s feature gallery, whose value is in range [0.0, 1.0]. Specifically, each Re-ID feature in the target’s gallery takes the dot product with the detector object’s Re-ID feature. The maximum of all the dot products is the similarity score, i.e.
\[score_{ij}=\max_{k}(feature\_det_{i}\cdot feature\_track_{jk})\]
where:
\(\cdot\) denotes the dot product.
\(feature\_det_{i}\) denotes the i-th detector object’s feature.
\(feature\_track_{jk}\) denotes the k-th Re-ID feature in the j-th target’s feature gallery. \(k\) =[1,
reidHistorySize].
The Re-ID has a spatial-temporal constraint. If an object moves out of frame or gets occluded beyond maxShadowTrackingAge, it will be assigned a new ID even if it returns into the frame.
The extracted Re-ID features (i.e., embeddings) can be exported to the metadata, which is explained in a separate section in Re-ID Feature Output.
Target Re-Association#
The target re-association algorithm enhances the long-term robustness of multi-object tracking by jointly using the Re-ID and spatio-temporal (i.e., motion) features. It addresses one of the major tracking failure cases that occurs in the situation where objects undergo partial- or full-occlusions in a gradual or abrupt manner. During this course of action, the detector at PGIE module may capture only some part of the objects (due to partial visibility), resulting in ill-sized, ill-centered boxes on the target. Later, the target cannot be associated with the object appearing again due to the size and location prediction errors, potentially causing tracking failures and ID switches. Such a re-association problem can typically be handled as a post-processing; however, for real-time analytics applications, this is often expected to be handled seamlessly as a part of the real-time multi-object tracking.
The target re-association takes advantage of the Late Activation and Shadow Tracking in target management module. It tries to associate the newly-appeared targets with previously lost targets based on motion and Re-ID similarity in a seamless, real-time manner by the following steps:
Tracklet Prediction: Whenever an existing target is not associated with a detector object for a prolonged period (same as probationAge), it is considered that the target is lost. While the visual tracker module keeps track of the target in the shadow tracking mode, a length of the predicted tracklet (configured by trajectoryProjectionLength) is generated using some of the recently matched tracklet points (whose length is set by prepLength4TrajectoryProjection) and stored into an internal database until it is matched again with a detector object or re-associated with another target.
Re-ID Feature Extraction: Before a target is lost, the Re-ID network extracts its Re-ID feature with the frame interval of reidExtractionInterval and stores them in the feature gallery. These features will be used to identify target re-appearance in the tracklet matching stage.
Target ID Acquisition: When a new target is instantiated, its validity is examined for a few frames (i.e., probationAge) and a target ID is assigned only if validated (i.e., Late Activation), after which the target state report starts. During the target ID acquisition, the new target is examined if it matches with one of the predicted tracklets from the existing targets in the internal database where the aforementioned predicted tracklets are stored. If matched, it would mean that the new target is actually the re-appearance of a disappeared target in the past. Then, the new target is re-associated with the existing target and its tracklet is fused into that as well. Otherwise, a new target ID is assigned.
Tracklet Matching: During the tracklet matching process in the previous step, the valid candidate tracklets are queried from the database based on the feasible time window configured by maxTrackletMatchingTimeSearchRange. For the new target and each candidate, both the motion and Re-ID similarity are taken into account for tracklet matching. The motion similarity is the average IOU along the tracklet with various criteria including the minimum average IOU score (i.e., minTrackletMatchingScore), maximum angular difference in motion (i.e., maxAngle4TrackletMatching), minimum speed similarity (i.e., minSpeedSimilarity4TrackletMatching), and minimum bbox size similarity (i.e., minBboxSizeSimilarity4TrackletMatching) computed by a Dynamic Time Warping (DTW)-like algorithm. The Re-ID similarity is the cosine distance between the new target’s Re-ID feature and its nearest neighbor in the candidate’s feature gallery. The total similarity score is the weighted sum of both metrics:
\[totalScore=w_1*IOU+w_2*reidSimilarity\]
where \(w_i\) is the weight for each metric set in config file. Users can also set a minimum threshold for each similarity and the total score.
Tracklet Fusion: Once two tracklets are associated, they are fused together to generate one smooth tracklet based on the matching status with detector and the confidence at each point.
config_tracker_NvDCF_accuracy.yml provides an example to enable this feature. Since Re-ID is computationally expensive, users may choose to increase reidExtractionInterval to improve performance or set the parameters like below (i.e., disabling Re-ID feature extraction) to use motion-only target re-association without Re-ID.
TrajectoryManagement: useUniqueID: 0 # Use 64-bit long Unique ID when assignining tracker ID. Default is [true] enableReAssoc: 1 # Enable Re-Assoc minMatchingScore4Overall: 0 # min matching score for overall minTrackletMatchingScore: 0.5644 # min tracklet similarity score for re-assoc matchingScoreWeight4TrackletSimilarity: 1.0 # weight for tracklet similarity score minTrajectoryLength4Projection: 36 # min trajectory length required to make projected trajectory prepLength4TrajectoryProjection: 50 # the length of the trajectory during which the state estimator is updated to make projections trajectoryProjectionLength: 94 # the length of the projected trajectory maxAngle4TrackletMatching: 106 # max angle difference for tracklet matching [degree] minSpeedSimilarity4TrackletMatching: 0.0967 # min speed similarity for tracklet matching minBboxSizeSimilarity4TrackletMatching: 0.5577 # min bbox size similarity for tracklet matching maxTrackletMatchingTimeSearchRange: 20 # the search space in time for max tracklet similarity trajectoryProjectionProcessNoiseScale: 0.0100 # trajectory projector's process noise scale w.r.t. state estimator trajectoryProjectionMeasurementNoiseScale: 100 # trajectory projector's measurement noise scale w.r.t. state estimator trackletSpacialSearchRegionScale: 0.2598 # the search region scale for peer tracklet ReID: reidType: 0 # The type of reid among { DUMMY=0, NvDEEPSORT=1, Reid based reassoc=2, both NvDEEPSORT and reid based reassoc=3}Note
Target re-association can be effective only when the state estimator is enabled, otherwise the tracklet prediction will not be made properly. The parameters provided above is tuned for PeopleNet v2.6.2, and it may not work as expected for other types of detectors.
Bounding-box Unclipping#
Another small experimental feature is the bounding box unclipping. If a target is fully visible within the field-of-view (FOV) of the camera but starts going out of the FOV, the target would be partially visible and the bounding box (i.e., bbox) may capture only a part of the target (i.e., clipped by the FOV) until it fully exits the scene. If it is expected that the size of the bbox doesn’t change much around the border of the video frame, the full bbox can be estimated beyond the FOV limit using the bbox size estimated when the target was fully visible. This feature can be enabled by setting enableBboxUnClipping: 1 under TargetManagement module in the low-level config file.
Single-View 3D Tracking#
Note
To allow users to easily try out and experience SV3DT, a sample usecase for SV3DT with pose estimator has been hosted on GitHub. So, users can just clone and run it with the sample data provided.
As mentioned earlier, partial occlusion is one of the most challenging problems that object trackers have to deal with and often lead to tracking failures. If the object detectors capture only the visible part of the object (which is often the case), the partial occlusion would cause the detection bboxes to have abrupt or gradual changes in attributes in terms of bbox location, size, aspect ratio, confidence, and most importantly the visual appearance within the bbox. Considering the object trackers rely on the bbox attributes as spatio-temporal measure and the visual appearance (e.g., ReID embedding) extracted within the bbox as visual similarity measure, such changes in bbox attributes is a major source of tracking failures, resulting in more frequent ID switches.
To tackle these challenging problems, DeepStream SDK introduced a new feature called the Single-View 3D Tracking (SV3DT) that allows the object tracking to be carried out in a 3D world coordinate system (instead of the 2D camera image plane) when (1) a 3x4 projection matrix and (2) a 3D model info are provided for a video stream in a camera info file like below.
# camInfo-01.yml # The 3x4 camera projection matrix (in row-major): # 996.229 -202.405 -9.121 -1.185 # 105.309 478.174 890.944 1.743 # -0.170 -0.859 0.481 -1085.484 projectionMatrix_3x4: - 996.229 - -202.405 - -9.121 - -1.185 - 105.309 - 478.174 - 890.944 - 1.743 - -0.170 - -0.859 - 0.481 - -1085.484 # The human model. modelInfo: height: 250.0 radius: 30.0 # "radius" represents the actual radius of the 3D cylinder, or half of a cuboid's bottom edge
There are two options (projectionMatrix_3x4 and projectionMatrix_3x4_w2p) in which users can provide corresponding 3x4 camera projection matrices to support different usecase. Please refer to The 3x4 Camera Projection Matrix section for more details.
Note that there are a few assumptions that this algorithm requires:
A human is modeled as a cylinder or cuboid with height and radius in the 3D world coordinate system. The cuboid’s bottom surface is assumed to be a square with edge length equal to twice the radius. The default height and radius are provided in 3D model info, which is the same for all the people. Additionally, a pose estimation model can be provided to estimate the 3D height of different people on the fly for better 3D accuracy.
A 3x4 projection matrix (that transforms a 3D world coordinate point to a 2D camera image coordinate point) is provided for a video stream or a camera.
Video streams are captured from cameras that are mounted higher than the human height. This ensures that when a human is partially-occluded, the upper body is still visible.
Introduced in DS 9.0, SV3DT extends beyond human tracking to support tracking of different object types that can be modeled as a cylinder or cuboid (e.g., forklifts, robots). For multi-class tracking, users need to provide a modelInfo array with different height and radius for each class ID in the camera info file. The following example demonstrates multi-class tracking using projectionMatrix_3x4_w2p with meter-scale dimensions:
# camInfo-multiclass.yml # 3x4 projection matrix that transforms world coordinates directly to pixel coordinates projectionMatrix_3x4_w2p: - 24.299825409521425 - 36.02205402112838 - -12.114767515284589 - 2498.5031157805533 - 5.145843154396475 - -8.901630718558632 - -39.76642074370861 - -131.8205299390187 - -0.009918105242078522 - 0.017157014258762076 - -0.012619549232871473 - 1.0 # Multi-class model info with different dimensions for each class ID modelInfo: - classID: 0 # person height: 1.7 radius: 0.3 - classID: 5 # forklift height: 2.2 radius: 0.9
SV3DT algorithm can be used with an optional 2D pose estimator, which estimates human key-points on the 2D image plane. If the pose estimator is enabled, the algorithm uses upper body key-points as 2D anchor to achieve a higher 3D accuracy. Otherwise, the algorithm uses 2D detection bounding boxes, especially the top edge as 2D anchor, which we will touch upon shortly.
2D Key-Points as Anchors: If the 2D pose estimator is enabled, SV3DT can estimate each person’s different 3D height and refine it over frames. It will use the head and feet (or head and waist) key-points as 2D anchors. It assumes the 3D line between these two key-points is perpendicular to the ground plane. By minimizing the projection error, it jointly solves the 3D distance between them and the world coordinate on the ground plane. The minPoseConfidence parameter controls which key points are reliable enough for height estimation. SV3DT mainly uses three sets of key points: head, waist, and feet. If both head and feet key points have confidence exceeding minPoseConfidence, they are used for height estimation. Otherwise, if both head and waist key points have confidence exceeding minPoseConfidence, they are used instead. If neither combination meets the confidence threshold, key points are not used for height estimation. Once a reliable key point pair is selected, the 3D height is estimated assuming body proportions are the same for all people. Then the 3D human model is updated for each target with different 3D height. The radius is also adjusted proportionally to the 3D height. More information about the 2D pose estimator can be found in Pose Estimation section.
Detection Boxes as Anchors: When 2D pose estimator is disabled, for each person, SV3DT algorithm tries to fit the 3D human model to the detection bbox in such a way that the bounding box of the projected 3D human model from the world coordinate system to the camera image plane matches with the detection bbox.
In the cases where a person is partially occluded, the head and waist key-points, or the top edge of the detection bbox is used as an anchor to align the bbox of the projected 3D human model. Once aligned, we can recover the full-body bbox using the projected 3D human model, as if the person is not occluded. Therefore, if SV3DT is enabled, the input detection bboxes are always first recovered to the full-body bboxes based on the provided 3D model info especially when the input detection bboxes capture only the visible part of the person due to partial occlusions. This greatly enhances the multi-object tracking accuracy and robustness, since the bbox attributes are not altered during the course of partial occlusions.
An animated image below shows how 3D human models can be fitted into the input detection bboxes when the persons are partially occluded. The thin, gray bboxes on the persons indicate the input detection bboxes, which capture only the visible part of the objects. The figure demonstrates that the SV3DT algorithm is still able to estimate the accurate foot location of each person. The person trajectories are drawn based on the estimated foot locations, allowing robust spatio-temporal behavior analytics of persons in the scene despite varying degree of occlusions. Some of the persons in this example are barely seen only on the head and shoulders, but they are being successfully tracked as if not occluded at all.
As a derived metric, the ratio between the bbox for the visible part and the bbox for the projected 3D human model can be considered as an approximated visibility of the object, which could be a useful information.
Users can still get access to the corresponding detection bboxes by checking out detector_bbox_info in NvDsObjectMeta.
To enable SV3DT feature, we introduced a new section in tracker config files, ObjectModelProjection, like below:
ObjectModelProjection: cameraModelFilepath: # In order of the source streams - 'camInfo-01.yml' - 'camInfo_02.yml' ...
Every camera view is different, so the 3x4 projection matrix is supposed to be unique to each camera. Therefore, the camera info file (e.g., camInfo-01.yml) is to be provided for each stream, which include the 3x4 projection matrix and the model info that are shown at the beginning of the section.
Once a 3D human model corresponding to an input detection bbox is estimated and located in the world coordinate system, the foot location (i.e., the center of the base of the human model) of a person on the world ground plane is what we want to keep estimating because it is a physical state that better follows the motion dynamics modeling than the motion of the object on 2D camera image plane. To perform the state estimation of the foot location of the objects on a 3D world ground plane, users need to set the state estimator type as stateEstimatorType: 3 like below:
StateEstimator: stateEstimatorType: 3 # the type of state estimator among { DUMMY_ESTIMATOR=0, SIMPLE_BBOX_KF=1, REGULAR_BBOX_KF=2, SIMPLE_LOCATION_KF=3 } # [Dynamics Modeling] processNoiseVar4Loc: 6810.866 # Process noise variance for location processNoiseVar4Vel: 1348.487 # Process noise variance for velocity measurementNoiseVar4Detector: 100.000 # Measurement noise variance for detector's detection measurementNoiseVar4Tracker: 293.323 # Measurement noise variance for tracker's localization
Meta Data for 3D Tracking#
The additional miscellaneous data that is generated when SV3DT is enabled include (1) visibility, (2) foot location in both world plane and 2D image, (3) convex hull (human cylinders projected on 2D image), and (4) 3D bounding box information. These data can be saved in text files and/or outputted to object meta for downstream usage. To do that, users would need to set outputVisibility: 1, outputFootLocation: 1, outputConvexHull: 1 in ObjectModelProjection section respectively. Note that 3D bounding box information is controlled by the same setting as foot location (outputFootLocation: 1). The sample use cases includes saving in terminated track dump for low level tracker, attaching in KITTI track dump for deepstream-app, and converting them in schema through Gst-nvmsgconv.
NvDsObj3DBbox User Meta: When SV3DT is enabled, each tracked object’s 3D bounding box information is stored in the NvDsObj3DBbox user meta structure. This structure contains comprehensive 3D spatial information about the tracked object including centroid coordinates, dimensions, rotation angles, and velocity in world coordinates. The NvDsObj3DBbox is retrieved and added in updateObjectProjectionMeta() in nvtracker_proc.cpp. The complete structure definition can be found in nvds_tracker_meta.h.
NvDs3DTracking Schema: The NvDs3DTracking structure is used in the DeepStream schema for event messages and contains key 3D tracking metadata including foot locations in both world and image coordinates, visibility information, convex hull data, and 3D bounding box information. The complete structure definition can be found in nvdsmeta_schema.h.
A figure below shows how the 3D human models can be fitted to the input detection bboxes. Note the current DeepStream OSD only supports 3D cuboid visualization as in right figure. The left figure uses the convex hull of the projected 3D cylinder model on 2D camera image plane. Users can refer to Miscellaneous Data Output section on how to retrieve the convex hull and create their own script to plot the convex hull.
The 3x4 Camera Projection Matrix#
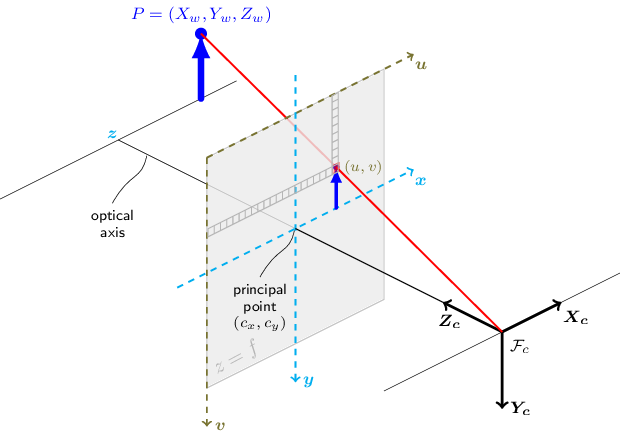
The 3x4 Camera Projection Matrix is also called as simply the camera matrix, which is a 3x4 matrix that converts a 3D world point to a 2D point on camera image plane based on a pinhole camera model like shown in the figure below:
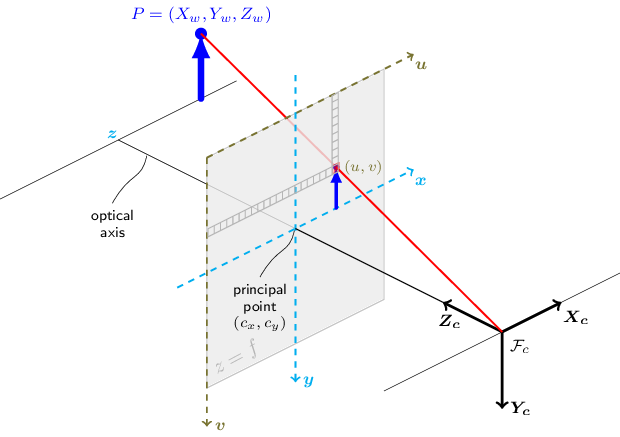
Pinhole Camera Model. Source: OpenCV Doc and License#
{kind=link}
More detailed and general information about the camera matrix can be found in various sources that deal with the computer vision geometries and camera calibration, including OpenCV’s documentation on Camera Calibration.
For projectionMatrix_3x4 in a camera model file (e.g., camInfo-01.yml), the principal point (i.e., (Cx, Cy)) in the camera matrix is assumed to be at (0, 0) as image coordinates. But, the optical center (i.e., (Cx, Cy)) is located at the image center (i.e., (img_width/2, img_height/2)). Thus, to move the origin to the left-top of the camera image (i.e., the pixel coordinates), SV3DT internally adds (img_width/2, img_height/2) after the transformation using the camera matrix provided in projectionMatrix_3x4.
In case that the 3x4 camera projection matrix already accounts for such translation of the principal point, users can provide the camera matrix in projectionMatrix_3x4_w2p instead. This assumes that the 3x4 camera projection matrix transforms a 3D world point directly into an actual pixel point whose origin is at the left-top corner of the image, so it does not require any further translation of the principal point.
Pose Estimation#
Pose estimation is a technique that estimates the key-points of a target, such as human or vehicle. It is used in SV3DT to estimate the 3D height in real world. Currently, SV3DT supports NVIDIA’s BodyPose3DNet with TensorRT acceleration. BodyPose3DNet is a 3D human pose estimation network based on HRNet architecture that predicts 34 keypoints in 3D space for a person in an image, including joints from head to toe such as pelvis, shoulders, elbows, wrists, hips, knees, and ankles. The model outputs both 2D and 3D keypoint coordinates, enabling accurate human pose tracking and analysis for applications like action understanding, surveillance, and human-robot interaction. It can be downloaded and used with command:
mkdir -p /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
wget --content-disposition 'https://api.ngc.nvidia.com/v2/models/org/nvidia/team/tao/bodypose3dnet/deployable_accuracy_v1.0/files?redirect=true&path=bodypose3dnet_accuracy.etlt' -P /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
Add PoseEstimator section in the tracker config like below to enable the network. Note the direct output of this network consists of both 2D and 3D key-points, but the 3D key-points are in each target’s local coordinate system. Currently, SV3DT only uses the 2D key-points to estimate the 3D height and target foot location in the world coordinate system.
Pose Estimator Parameters
PoseEstimator:
poseEstimatorType: 1 # Type of pose estimator used
useVPICropScaler: 1 # Use VPI backend for cropping and scaling
batchSize: 1 # Batch size for pose estimation
workspaceSize: 1000 # Workspace size in MB for the pose estimator engine
inferDims: [3, 256, 192] # Input dimensions for the pose estimator network (C, H, W)
networkMode: 1 # Inference precision mode (fp32=0, fp16=1, int8=2)
inputOrder: 0 # Input order for the network (NCHW=0, NHWC=1)
colorFormat: 0 # Input color format (RGB=0, BGR=1)
offsets: [123.6750, 116.2800, 103.5300] # Channel-wise mean subtraction values
netScaleFactor: 0.00392156 # Scaling factor for input normalization
onnxFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/bodypose3dnet_accuracy.onnx" # Path to the ONNX model file
modelEngineFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/bodypose3dnet_accuracy.onnx_b1_gpu0_fp16.engine" # Path to the engine file
poseInferenceInterval: -1 # Pose inference frame interval. -1 means only for the first frame of each target and use it to determine the target height.
operateOnClassIds: [] # Class IDs on which pose inference operates (e.g. [0]). If empty, operates on all classes.
Configuration Parameters#
The following table summarizes the configuration parameters for the common modules in the NvMultiObjectTracker low-level tracker library.
Module |
Property |
Meaning |
Type and Range |
Default value |
Support Dynamic Updates |
|---|---|---|---|---|---|
Base Config |
minDetectorConfidence |
Minimum detector confidence for a valid object |
Float, -inf to inf |
minDetectorConfidence: 0.0 |
True |
Control |
tracker-reset |
soft reset the tracker removing all tracks and track history |
Boolean |
tracker-reset:0 |
True |
Target Management |
preserveStreamUpdateOrder |
Whether to ensure target ID update order the same as input stream ID order |
Boolean |
preserveStreamUpdateOrder: 0 |
False |
maxTargetsPerStream |
Max number of targets to track per stream |
Integer, 0 to 65535 |
maxTargetsPerStream: 30 |
False |
|
minIouDiff4NewTarget |
Min IOU to existing targets for discarding new target |
Float, 0 to 1 |
minIouDiff4NewTarget: 0.5 |
True |
|
enableBboxUnClipping |
Enable bounding-box unclipping |
Boolean |
enableBboxUnClipping: 0 |
True |
|
probationAge |
Length of probationary period in #of frames |
Integer, ≥0 |
probationAge: 5 |
True |
|
maxShadowTrackingAge |
Maximum length of shadow tracking |
Integer, ≥0 |
maxShadowTrackingAge: 38 |
True |
|
earlyTerminationAge |
Early termination age |
Integer, ≥0 |
earlyTerminationAge: 2 |
True |
|
outputTerminatedTracks |
Output total frame history for terminated tracks to the tracker plugin for downstream usage |
Boolean |
outputTerminatedTracks: 0 |
False |
|
outputShadowTracks |
Output shadow track state information to the tracker plugin for downstream usage |
Boolean |
outputShadowTracks: 0 |
False |
|
terminatedTrackFilename |
File name prefix to save terminated tracks |
String |
terminatedTrackFilename: “” |
False |
|
Trajectory Management |
useUniqueID |
Enable unique ID generation scheme |
Boolean |
useUniqueID: 0 |
False |
enableReAssoc |
Enable motion-based target re-association |
Boolean |
enableReAssoc: 0 |
False |
|
minMatchingScore4Overall |
Min total score for re-association |
Float, 0.0 to 1.0 |
minMatchingScore4Overall: 0.4 |
True |
|
minTrackletMatchingScore |
Min tracklet similarity score for matching in terms of average IOU between tracklets |
Float, 0.0 to 1.0 |
minTrackletMatchingScore: 0.4 |
False |
|
minMatchingScore4ReidSimilarity |
Min ReID score for re-association |
Float, 0.0 to 1.0 |
minMatchingScore4ReidSimilarity: 0.8 |
True |
|
matchingScoreWeight4TrackletSimilarity |
Weight for tracklet similarity term in re-assoc cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4TrackletSimilarity: 1.0 |
True |
|
matchingScoreWeight4ReidSimilarity |
Weight for ReID similarity term in re-assoc cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4ReidSimilarity: 0.0 |
True |
|
minTrajectoryLength4Projection |
Min tracklet length of a target (i.e., age) to perform trajectory projection [frames] |
Integer, >=0 |
minTrajectoryLength4Projection: 20 |
True |
|
prepLength4TrajectoryProjection |
Length of the trajectory during which the state estimator is updated to make projections [frames] |
Integer, >=0 |
prepLength4TrajectoryProjection: 10 |
True |
|
trajectoryProjectionLength |
Length of the projected trajectory [frames] |
Integer, >=0 |
trajectoryProjectionLength: 90 |
True |
|
maxAngle4TrackletMatching |
Max angle difference for tracklet matching [degree] |
Integer, [0, 180] |
maxAngle4TrackletMatching: 40 |
True |
|
minSpeedSimilarity4TrackletMatching |
Min speed similarity for tracklet matching |
Float, 0.0 to 1.0 |
minSpeedSimilarity4TrackletMatching: 0.3 |
True |
|
minBboxSizeSimilarity4TrackletMatching |
Min bbox size similarity for tracklet matching |
Float, 0.0 to 1.0 |
minBboxSizeSimilarity4TrackletMatching: 0.6 |
True |
|
maxTrackletMatchingTimeSearchRange |
Search space in time for max tracklet similarity |
Integer, >=0 |
maxTrackletMatchingTimeSearchRange: 20 |
True |
|
trajectoryProjectionProcessNoiseScale |
Trajectory state estimator’s process noise scale |
Float, 0.0 to inf |
trajectoryProjectionProcessNoiseScale: 1.0 |
True |
|
trajectoryProjectionMeasurement NoiseScale |
Trajectory state estimator’s measurement noise scale |
Float, 0.0 to inf |
trajectoryProjectionMeasurement NoiseScale: 1.0 |
True |
|
trackletSpacialSearchRegionScale |
Re-association peer tracklet search region scale |
Float, 0.0 to inf |
trackletSpacialSearchRegionScale: 0.0 |
True |
|
reidExtractionInterval |
Frame interval to extract ReID features per target for re-association; -1 means only extracting the beginning frame per target |
Integer, ≥-1 |
reidExtractionInterval: 0 |
True |
|
Data Associator |
associationMatcherType |
Type of matching algorithm { GREEDY=0, CASCADED=1 } |
Integer, [0, 1] |
associationMatcherType: 0 |
False |
checkClassMatch |
Enable associating only the same-class objects |
Boolean |
False |
||
minMatchingScore4Overall |
Min total score for valid matching |
Float, 0.0 to 1.0 |
minMatchingScore4Overall: 0.0 |
True |
|
minMatchingScore4SizeSimilarity |
Min bbox size similarity score for valid matching |
Float, 0.0 to 1.0 |
minMatchingScore4SizeSimilarity: 0.0 |
True |
|
minMatchingScore4Iou |
Min IOU score for valid matching |
Float, 0.0 to 1.0 |
minMatchingScore4Iou: 0.0 |
True |
|
matchingScoreWeight4SizeSimilarity |
Weight for size similarity term in matching cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4SizeSimilarity: 0.0 |
True |
|
matchingScoreWeight4Iou |
Weight for IOU term in matching cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4Iou: 1.0 |
True |
|
tentativeDetectorConfidence |
If a detection’s confidence is lower than this but higher than minDetectorConfidence, then it’s considered as a tentative detection |
Float, 0.0 to 1.0 |
tentativeDetectorConfidence: 0.5 |
True |
|
minMatchingScore4TentativeIou |
Min iou threshold to match targets and tentative detection |
Float, 0.0 to 1.0 |
minMatchingScore4TentativeIou: 0.0 |
True |
|
State Estimator |
stateEstimatorType |
Type of state estimator among { DUMMY=0, SIMPLE=1, REGULAR=2, SIMPLE_LOC=3 } |
Integer, [0,3] |
stateEstimatorType: 0 |
False |
processNoiseVar4Loc |
Process noise variance for bbox center |
Float, 0.0 to inf |
processNoiseVar4Loc: 2.0 |
False |
|
processNoiseVar4Size |
Process noise variance for bbox size |
Float, 0.0 to inf |
processNoiseVar4Size: 1.0 |
False |
|
processNoiseVar4Vel |
Process noise variance for velocity |
Float, 0.0 to inf |
processNoiseVar4Vel: 0.1 |
False |
|
measurementNoiseVar4Detector |
Measurement noise variance for detector’s detection |
Float, 0.0 to inf |
measurementNoiseVar4Detector: 4.0 |
False |
|
measurementNoiseVar4Tracker |
Measurement noise variance for tracker’s localization |
Float, 0.0 to inf |
measurementNoiseVar4Tracker: 16.0 |
False |
|
noiseWeightVar4Loc |
Noise covariance weight for bbox location; if set, location noise will be proportional to box height |
Float, >0.0 considered as set |
noiseWeightVar4Loc: -0.1 |
False |
|
noiseWeightVar4Vel |
Noise covariance weight for bbox velocity; if set, location noise will be proportional to box height |
Float, >0.0 considered as set |
noiseWeightVar4Vel: -0.1 |
False |
|
useAspectRatio |
Use aspect ratio in Kalman Filter’s states |
Boolean |
useAspectRatio: 0 |
False |
|
Object Re-ID |
[All the parameters in “Model Inference” module] |
This network’s input is each target’s cropped image. It uses “Model Inference” parameters to define the network input format and TensorRT inference properties. |
[Refer to “Model Inference” module |
[Refer to “Model Inference” module] |
False |
reidType |
The type of Re-ID network among { DUMMY=0, NvDEEPSORT=1, Reid based reassoc=2, both NvDEEPSORT and reid based reassoc=3 } |
Integer, [0, 3] |
reidType: 0 |
False |
|
reidFeatureSize |
Size of Re-ID feature |
Integer, >0 |
reidFeatureSize: 128 |
False |
|
reidHistorySize |
Size of feature gallery, i.e. max number of Re-ID features kept for one tracker |
Integer, >0 |
reidHistorySize: 100 |
False |
|
addFeatureNormalization |
If Re-ID network’s output Re-ID feature vector is not l2 normalized, explicitly performs l2 normalization |
Boolean |
addFeatureNormalization: 0 |
False |
|
keepAspc |
Whether to keep aspcect ratio when resizing input objects to Re-ID network |
Boolean |
keepAspc: 1 |
False |
|
outputReidTensor |
Output Re-ID features to user meta for downstream usage |
Boolean |
outputReidTensor: 0 |
False |
|
Object Model Projection |
cameraModelFilepath |
A list of file paths to camera info files. A valid camera info file should be provided to each video stream |
String |
cameraModelFilepath: “” |
False |
waistHeightRatio |
The ratio of human upper body with regarding to the whole body. This value is assumed to be the same for all the people. |
Float, (0, 1) |
waistHeightRatio: 0.5 |
||
outputVisibility |
Output object visibility to object meta and file dump |
Boolean |
outputVisibility: 0 |
False |
|
outputFootLocation |
Output object (especially for human) foot location to object meta and file dump |
Boolean |
outputFootLocation: 0 |
False |
|
outputConvexHull |
Output projected object convex hull (especially cylinder for human) to object meta and file dump |
Boolean |
outputConvexHull: 1 |
False |
|
maxConvexHullSize |
Maximum number of points to consist an object convex hull |
Integer, >0 |
maxConvexHullSize: 15 |
False |
|
minPoseConfidence |
Minimum pose keypoints confidence to be used in human height estimation |
Float, 0.0 to 1.0 |
minPoseConfidence: 0.5 |
False |
|
Pose Estimation |
[All the parameters in “Model Inference” module] |
This network’s input is each target’s cropped image. It uses “Model Inference” parameters to define the network input format and TensorRT inference properties. |
[Refer to “Model Inference” module] |
[Refer to “Model Inference” module] |
|
poseEstimatorType |
The type of pose estimation network among { DUMMY=0, enable pose estimation=1 } |
Integer, [0, 1] |
poseEstimatorType: 0 |
False |
|
poseInferenceInterval |
Pose inference frame interval. -1 means only for the first frame of each target and use it to determine the target height. 0 means for every frame. Positive integers mean inference with a strided frame interval. Target height will be updated after each inference. |
Integer, >=-1 |
poseInferenceInterval: -1 |
False |
|
operateOnClassIds |
Class IDs on which pose estimation operates. When class IDs are specified (e.g., [0,1]), only image patches for those classes are sent to pose inference. If not specified or empty, operates on all classes. |
List of integers, >=0 |
operateOnClassIds: [] |
False |
|
Model Inference |
batchSize |
Batch size of network |
Integer, >0 |
batchSize: 1 |
False |
workspaceSize |
Workspace size to be used by TensorRT engine, in MB |
Integer, >0 |
workspaceSize: 20 |
False |
|
inferDims |
Network input dimension CHW or HWC based on inputOrder |
Integer, >0 |
inferDims: [128, 64, 3] |
False |
|
inputOrder |
Network input order {NCHW=0, NHWC=1} |
Integer, [0, 1] |
inputOrder: 1 |
False |
|
colorFormat |
Network input color format among {RGB=0, BGR=1 } |
Integer, [0, 1] |
colorFormat: 0 |
False |
|
networkMode |
Network inference precision mode among {FP32=0, FP16=1, INT8=2 } |
Integer, [0, 1, 2] |
networkMode: 0 |
False |
|
offsets |
Array of values to be subtracted from each input channel, with length equal to number of channels |
Comma delimited float array |
offsets: [0.0, 0.0, 0.0] |
False |
|
netScaleFactor |
Scaling factor for network input after subtracting offsets |
Float, >0 |
netScaleFactor: 1.0 |
False |
|
tltEncodedModel |
Absolute path of the TAO toolkit encoded model |
String |
tltEncodedModel: “” |
False |
|
tltModelKey |
Key for the TAO toolkit encoded model |
String |
tltModelKey: “” |
False |
|
onnxFile |
Absolute path of the ONNX model file |
String |
onnxFile: “” |
False |
|
modelEngineFile |
Absolute path to TensorRT engine file |
String |
modelEngineFile:”” |
False |
|
calibrationTableFile |
Absolute path to calibration table, required by INT8 only |
String |
calibrationTableFile:”” |
False |
|
useVPICropScaler |
Use NVIDIA’s VPI™ Crop Scaler algorithm instead of built in implementation |
Boolean |
useVPICropScaler: 0 |
False |
Dynamic Runtime Configuration#
The NvMultiObjectTracker now supports updates to the tracker’s configuration during runtime, allowing the user to update settings without disrupting the current processing pipeline. The intent of this feature is to enable users to update parameters of the NvMultiObjectTracker and the low-level tracker without incurring the overhead of reinstating the tracker itself. This results in minimal runtime penalties for updating config parameters, but with the limitation of only supporting parameters that do not allocate or change memory requirements. If a user attempts to dynamically modify an unsupported parameter, the tracker will respond with a warning and ignore the user input. A new parameter section named “control” has been defined. The control section is only available through the dynamic config control and cannot be set during initialization. The supported dynamic config parameters are denoted in the above table outlining all configuration parameters.
Note
All config parameters are not supported, however may be updated over time. This table may become out-of-sync with a specific Deepstream version, so please verify with logs that invalid configs are not silently ignored from the sender’s perspective. Due to the realtime nature of the processing and updating of the various parameters, the REST API will return a success if the message is received and processed correctly, not upon the specific parameters being changed. Only the local log of the running process will report bad parameter messages.
The dynamic config is enabled through three mechanisms: - the REST API supported through the Deepstream REST Server - Gstreamer events supported through the NvMultiObject tracker - A C++ API enabled through an optional interface for all low-level tracker implementation The APIs are hierarchal, meaning higher-level APIs utilize lower-level APIs to ensure consistency in behavior. This allows users to command config updates from any level of the application they are currently working with (REST for off-node, Gstreamer for within App, and C++ for custom tracker plugins). The following sections outline the details and behaviors of each API.
Note
Reconfiguring any stream in a batch will result in all streams of that batch being re-configured. Currently the tracker state for all streams within the same batch is shared. If a user would like to re-configure only one/few streams from a batch, they will need to move that single stream/group of streams to a different sub-batch. The sub-batches configuration needs to be specified when initializing the tracker. Within a sub-batch, the re-configuration will be applied to all the streams in that sub-batch.
REST API Support#
The REST API is facilitated though the DeepStream With REST API Server functionality. Due to the large number of config parameters related to the NvMultiOjbectTracker, the REST API only supports a path to a config file. This config file may then set any of the above supported config parameters. The REST API does require the NvMultiOjbectTracker to access disk to parse this file, with the tradeoff of greatly simplifying updating many complex parameters.
An example REST command would be as follows:
curl -XPOST 'http://localhost:9000/api/v1/nvtracker/config-path' -d '{
"stream":
{
"stream_id":"0",
"config_path":"trackerReset.yaml"
}
}'
Gstreamer Event Support#
The NvMultiObjectTracker also supports native gstreamer events and implements the GST_NVEVENT_NVTRACKER_CONFIG_UPDATE event to trigger a config update. This is the underlying update mechanism of the REST API, so follows the same control limitations and behavior as the REST API. After receiving an event, the config file at the path provided is parsed, converted to a string, and provided to the lowest-level C++ API.
Creation of a Gstreamer Config update can be facilitated through the helper function gst_nvevent_nvtracker_config_update:
C++ API Support#
A public C++ API provides the lowest-level implementations to directly pass config updates to the nvtracker. Unlike the higher level options that only accept the path to a new config file defining the configs to update, updateDynamicConfig is implemented in the NvMultiObject tracker to allow C++ implementations to directly feed stringified configs to the low-level tracker. No file on disk is required; instead, the contents of a valid YAML file is provided as a string and directly provided to the low-level tracker for update.
The updateDynamicConfig is facilitated through an optional low-level tracker interface function NvMOT_UpdateParams. Any low-level tracker implementation can implement this function and will work seamlessly with the NvMultiObjectTracker’s pipeline for higher level update calls to reach the low-level implementation.
Low-Level Tracker Comparisons and Tradeoffs#
DeepStream SDK provides four reference low-level tracker libraries which have different resource requirements and performance characteristics, in terms of accuracy, robustness, and efficiency, allowing the users to choose the best tracker based on their use cases and requirements. See the following table for comparison.
Tracker Type |
GPU Compute |
CPU Compute |
Pros |
Cons |
Best Use Cases |
|---|---|---|---|---|---|
IOU |
No |
Very Low |
|
|
|
NvSORT |
No |
Very Low |
|
|
|
NvDeepSORT |
High |
Low |
|
|
|
NvDCF |
Medium |
Low |
|
|
|
MaskTracker |
High |
Medium |
|
|
|
IOU Tracker#
The NvMultiObjectTracker library provides an object tracker that has only the essential and minimum set of functionalities for multi-object tracking, which is called the IOU tracker. IOU tracker performs only the following functionalities:
Greedy data association between the detector objects from a new video frame and the existing targets in the previous video frame
Target management based on the data association results including the target state update and the creation and termination of targets
The error handling mechanisms like Late Activation and Shadow Tracking are integral part of the target management module of the NvMultiObjectTracker library; thus, such features are inherently enabled in the IOU tracker.
IOU tracker can be used as a performance baseline as it consumes the minimum amount of computational resources. A sample configuration file config_tracker_IOU.yml is provided in DeepStream SDK package.
NvSORT Tracker#
NvSORT tracker increases the tracking accuracy while maintaining the high performance on top of IOU tracker with the following improvements:
State estimation with Kalman filter to better estimate and predict the states of the targets in the current frame.
Cascaded data association to associate targets and detector objects in multiple stages based on their proximity and confidence, which is more accurate than the simple matching in original SORT tracker.
As it fully relies on the bbox attributes for data association, the NvSORT’s tracking accuracy is solely attributed to the detection accuracy. With a medium or high accuracy detector, NvSORT produces high quality tracking results with minimal computational resources. A sample configuration file config_tracker_NvSORT.yml is provided in DeepStream SDK package.
NvDeepSORT Tracker#
NvDeepSORT tracker utilizes deep learning based object appearance information for accurate object matching in different frames and locations, resulting in enhanced robustness over occlusions and reduced ID switches. It applies a pre-trained re-identification (Re-ID) neural network to extract a feature vector for each object, compares the similarity between different objects using the extracted feature vector with a cosine distance metric, and combines it with a state estimator to perform the data association over frames. Before running NvDeepSORT, Re-ID model needs to be set up following Setup Sample Re-ID Models and Customize Re-ID Model.
Data Association#
For the data association in the NvDeepSORT tracker, there are two metrics are used:
Proximity
Re-ID based similarity
For the proximity score, the Mahalanobis distance between the i-th detector object and the j-th target is calculated using the target’s predicted location and its associated uncertainty:
\[dist_{ij}=(D_i-Y_j)^TS_j^{-1}(D_i-Y_j)\]
where:
\(D_i\) denotes the i-th detector object in
{x, y, a, h}format.\(Y_j\) denotes the predicted states
{x', y', a', h'}from state estimator for the j-th tracker.\(S_j\) denotes the predicted covariance from state estimator for the j-th tracker.
In the original DeepSORT implementation, the maximum threshold of Mahalanobis distance for a valid pair of detector object and target is set 9.4877, representing 95% confidence computed from the inverse Chi-square distribution. Note in NvDeepSORT, the value is configured by thresholdMahalanobis in tracker config to achieve higher accuracy for a particular detector model, such as the PeopleNet v2.6.2, so it may be different from the value in the original implementation.
After filtering out invalid pairs, the Re-ID similarity score is computed as the maximum cosine similarity between a detector object and a target. Then the cascaded data association algorithm is used for high accuracy multi-stage matching.
Configuration Parameters#
A sample config file config_tracker_NvDeepSORT.yml is provided in DeepStream SDK package. The following table summarizes the configuration parameters for NvDeepSORT.
Module |
Property |
Meaning |
Type and Range |
Default value |
|---|---|---|---|---|
Data Associator |
thresholdMahalanobis |
Max Mahalanobis distance based on Chi-square probabilities |
Float, >0 considered as set |
thresholdMahalanobis: -1.0 |
minMatchingScore4ReidSimilarity |
Min Re-ID threshold to match targets and tentative detection |
Float, 0.0 to 1.0 |
minMatchingScore4ReidSimilarity: 0.0 |
|
matchingScoreWeight4ReIDSimilarity |
Weight for Re-ID similarity term in matching cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4ReIDSimilarity: 0.0 |
Implementation Details and Reference#
The difference between NvDeepSORT and the original implementation includes:
For data association, the original implementation sorts the targets in an ascending order based on the tracking age and runs the matching algorithm for each age sequentially, while NvDeepSORT applies the cascaded data association algorithm with higher performance and accuracy.
NvDeepSORT implementation in the NvMultiObjectTracker library adopts the same target management policy as the NvDCF tracker, which is advanced to the original DeepSORT.
The cosine distance metric for two features is \(score_{ij}=1-feature\_det_{i}\cdot feature\_track_{jk}\), with smaller values representing more similarity. By contrast, NvDeepSORT directly uses dot product for computational efficiency, so larger values means higher similarity.
Reference: Wojke, Nicolai, Alex Bewley, and Dietrich Paulus. “Simple online and real-time tracking with a deep association metric.” 2017 IEEE international conference on image processing (ICIP). IEEE, 2017. Check Paper and The original implementation on Github.
NvDCF Tracker#
NvDCF tracker employs a visual tracker that is based on the discriminative correlation filter (DCF) for learning a target-specific correlation filter and for localizing the same target in the next frames using the learned correlation filter. Such correlation filter learning and localization are usually carried out on per-object basis in a typical MOT implementation, creating a potentially large number of small CUDA kernel launches when processed on GPU. This inherently poses challenges in maximizing GPU utilization, especially when a large number of objects from multiple video streams are expected to be tracked on a single GPU.
To address such performance issues, the GPU-accelerated operations for the NvDCF tracker are designed to be executed in the batch processing mode to maximize the GPU utilization despite the nature of small CUDA kernels in per-object tracking model. The batch processing mode is applied in the entire tracking operations, including the bbox cropping and scaling, visual feature extraction, correlation filter learning, and localization. This can be viewed as a similar model to the batched cuFFT or batched cuBLAS calls, but it differs in that the batched MOT execution model spans many operations in a higher level. The batch processing capability is extended from multi-object batching to the batching of multiple streams for even greater efficiency and scalability.
Thanks to its visual tracking capability, the NvDCF tracker can localize and keep track of the targets even when the detector in PGIE misses them (i.e., false negatives) for potentially an extended period of time caused by partial or full occlusions, resulting in more robust tracking. The enhanced robustness characteristics allow users to use a higher maxShadowTrackingAge value for longer-term object tracking and also allows PGIE’s interval to be higher only at the cost of slight degradation in accuracy.
Unlike NvSORT and NvDeepSORT where the Kalman filter takes the detection bboxes as the only input, the Kalman filter in the NvDCF tracker also takes the localization results from the visual tracking module as an input as well. Once a target is being tracked, the visual tracker keeps trying to localize the same target in the next frames using the learned correlation filter, while there could be matched detector bboxes. The Kalman filter in NvDCF tracker fuses both the DCF-based localization results and the detection bboxes for better target state estimation and prediction.
Visual Tracking#
For each tracked target, NvDCF tracker defines a search region around its predicted location in the next frame large enough for the same target to be detected in the search region. The location of a target on a new video frame is predicted by using the state estimator module. The searchRegionPaddingScale property determines the size of the search region as a multiple of the diagonal of the target’s bounding box. The size of the search region would be determined as:
\[ \begin{align}\begin{aligned}SearchRegion_{width}=w+searchRegionPaddingScale*\sqrt{w*h}\\SearchRegion_{height}=h+searchRegionPaddingScale*\sqrt{w*h}\end{aligned}\end{align} \]
, where \(w\) and \(h\) are the width and height of the target’s bounding box, respectively.
Once the search region is defined for each target at its predicted location, the image patches from each of the search regions are cropped and scaled to a predefined feature image size, from which the visual features are extracted. The featureImgSizeLevel property defines the size of the feature image, and its range is from 1 to 5. Each level between 1 and 5 corresponds to 12x12, 18x18, 24x24, 30x30, and 36x36, respectively, for each feature channel. A lower value of featureImgSizeLevel causes NvDCF to use a smaller feature size, increasing GPU performance potentially yet at the cost of accuracy and robustness. Consider the relationship between featureImgSizeLevel and searchRegionPaddingScale when configuring the parameters. If searchRegionPaddingScale is increased while featureImgSizeLevel is fixed, the number of pixels corresponding to the target itself in the feature images will be effectively decreased.
For each cropped image patch, the visual appearance features such as ColorNames and/or Histogram-of-Oriented-Gradient (HOG) are extracted. The type of visual features to be used can be configured by setting useColorNames and/or useHog. The HOG features consist of 18 channels based on the number of bins for different orientations, while The ColorNames features have 10 channels. If both features are used (by setting useColorNames: 1 and useHog: 1), the total number of channels would then be 28. Therefore, if one uses both HOG and ColorNames with featureImgSizeLevel: 5, the dimension of visual features that represents a target would be 28x48x48. The more channels of visual features are used, the higher the accuracy would be, but would increase the computational complexity and reduce the performance. The NvDCF tracker uses NVIDIA’s VPI™ library for extracting those visual features.
The correlation filters are generated with an attention window (using a Hanning window) applied at the center of the target bbox. Users are allowed to move the center of the attention window in the vertical direction. For example, featureFocusOffsetFactor_y: -0.2 would result in the center of the attention window to be at y=-0.2 in the feature map, where the relative range of the height is [-0.5, 0.5]. Consider that typical surveillance or CCTV cameras are mounted at a moderately high position to monitor a wide area of the environment, say, a retail store or a traffic intersection. From those vantage points, more occlusions can occur at the lower part of the body of persons or vehicles by other persons or vehicles. Moving the attention window up a bit may improve the accuracy and robustness for those use cases.
Once a correlation filter is generated for a target, typical DCF-based trackers usually employ an exponential moving average for temporal consistency when the optimal correlation filter is created and updated over consecutive frames. The learning rate for this moving average can be configured by filterLr and filterChannelWeightsLr for the correlation filters and their channel weights, respectively. The standard deviation for Gaussian for the desired response used when creating an optimal DCF filter can also be configured by gaussianSigma.
Compute Backends
Visual tracker module in NvDCF supports multiple compute backends: CUDA/GPU and PVA (Programmable Vision Accelerator). So, the users are allowed to use different compute backends depending on the particular use cases.
PVA is an accelerator in Tegra SOC in NVIDIA’s Jetson devices, which is specialized for image processing and computer vision algorithms with extremely low power consumption. When running DeepStream-based pipeline with tracker on Jetson, it is recommended to use the PVA-backend for DCF operations in NvDCF for better power efficiency. Since the GPU-based processing for DCF operations is offloaded onto PVA, therefore, more GPU resources are made available to the users for any downstream or custom processing that requires GPU-based processing.
To employ PVA-backend, the visual tracker module leverages the APIs provided by NVIDIA’s VPI™, which can be enabled by setting visualTrackerType: 2 and vpiBackend4DcfTracker: 2 # {CUDA=1, PVA=2} on Jetson platforms. VPI also has CUDA-backend mode, which can configured by setting vpiBackend4DcfTracker: 1 on any supported HW platforms (Jetson or dGPU platforms).
The PVA-backend implementation of DCF operations by VPI™ currently has the following limitations:
The maximum number of objects that can be supported by a single instance of tracker library is 512. This translates to the following restrictions in DeepStream configuration:
When sub-batching is not enabled, the total number of objects being tracked across all the streams (i.e., the number of streams in a batch *
maxTargetsPerStream) should be less than or equal to 512When sub-batching is enabled, the total number of objects being tracked across all the streams in a sub-batch (i.e., the number of streams in a sub-batch *
maxTargetsPerStream) should be less than or equal to 512If there are N sub-batches, the total number of objects that can be tracked in the pipeline is effectively
N*512.
Supports only one combination of the these three configurations :
useColorNames: 1anduseHog: 1andfeatureImgSizeLevel: 3
Another limitation of the DCF APIs provided by VPI™ is that, the max number of streams supported by a single library instance is 33. Hence, to run a DS application with higher batch size (>33) using visualTrackerType: 2, it is recommended to use Sub-batching feature in the tracker plugin such that each sub-batch is of size less than or equal to 33 streams.
Data Association#
The association of target IDs across frames for robust tracking typically entails visual appearance-based similarity matching, for which the visual appearance features are extracted at each candidate location. Usually, this is a computationally expensive process and often plays as a performance bottleneck in object tracking. Unlike existing approaches that extract visual features from all the candidate locations and perform feature matching among all the candidate objects, the NvDCF tracker takes advantage of the correlation response (that is already obtained during target localization stage) as the tracking confidence map of each tracker over a search region and simply looks up the confidence values at each candidate location (i.e., the location of each detector object) to get the visual similarity without any explicit computation. By comparing those confidences between trackers, we can identify which tracker has a higher visual similarity to a particular detector object and use it as a part of the matching score for data association. Therefore, the visual similarity matching in the data association process can be carried out very efficiently through a simple look-up table (LUT) operation on existing correlation responses.
In the animated figure below, the left side shows the target within its search region, while the right side shows the correlation response map (where the deep red color indicates higher confidence and deep blue indicates lower confidence). In the confidence map, the yellow cross (i.e., +) around the center indicates the peak location of the correlation response, while the purple x indicate the center of nearby detector bboxes. The correlation response values at those purple x locations indicate the confidence score on how likely the same target exists at that location in terms of the visual similarity.

If there are multiple detector bboxes (i.e., purple x) around the target like the one in the figure below, the data association module will take care of the matching based on the visual similarity score and the configured weight and minimum value, which are matchingScoreWeight4VisualSimilarity and minMatchingScore4VisualSimilarity, respectively.

Configuration Parameters#
A few sample configuration files for the NvDCF tracker are provided as a part of DeepStream SDK package, which is named as:
config_tracker_NvDCF_max_perf.ymlconfig_tracker_NvDCF_perf.ymlconfig_tracker_NvDCF_accuracy.yml
The first max_perf config file is to configure the NvDCF tracker to consume the least amount of resources, while the second perf config file is for the use case where a decent balance between performance and accuracy is required. The last accuracy config file is to maximize the accuracy and robustness by enabling most of the features to their full capability, especially the target re-association.
The following table summarizes the configuration parameters used in the config files for the NvDCF low-level tracker (except the common modules and parameters already mentioned in an earlier section).
Module |
Property |
Meaning |
Type and Range |
Default value |
Support Dynamic Updates |
|---|---|---|---|---|---|
Visual Tracker |
visualTrackerType |
Type of visual tracker among { DUMMY=0, NvDCF=1, NvDCF_VPI=2 } NvDCF_VPI is an Alpha feature. |
Int, [0, 1, 2] |
visualTrackerType: 0 |
False |
useColorNames |
Use ColorNames feature |
Boolean |
useColorNames: 1 |
False |
|
useHog |
Use Histogram-of-Oriented-Gradient (HOG) feature |
Boolean |
useHog: 0 |
False |
|
featureImgSizeLevel |
Size of a feature image |
Integer, 1 to 5 |
featureImgSizeLevel: 2 |
False |
|
featureFocusOffsetFactor_y |
The offset for the center of hanning window relative to the feature height |
Float, -0.5 to 0.5 |
featureFocusOffsetFactor_y: 0.0 |
True |
|
useHighPrecisionFeature |
Whether to use 16 bit high precision feature; otherwise use 8 bit |
Boolean |
useHighPrecisionFeature: 0 |
False |
|
filterLr |
Learning rate for DCF filter in exponential moving average |
Float, 0.0 to 1.0 |
filterLr: 0.075 |
True |
|
filterChannelWeightsLr |
Learning rate for weights for different feature channels in DCF |
Float, 0.0 to 1.0 |
filterChannelWeightsLr: 0.1 |
True |
|
gaussianSigma |
Standard deviation for Gaussian for desired response |
Float, >0.0 |
gaussianSigma: 0.75 |
True |
|
vpiBackend4DcfTracker |
Compute backend among {CUDA=1, PVA=2} Valid when visualTrackerType: 2 |
Int, [1,2] |
vpiBackend4DcfTracker: 1 |
False |
|
Target Management |
searchRegionPaddingScale |
Search region size |
Integer, 1 to 3 |
searchRegionPaddingScale: 1 |
True |
minTrackerConfidence |
Minimum detector confidence for a valid target |
Float, 0.0 to 1.0 |
minTrackerConfidence: 0.6 |
True |
|
Data Assoicator |
minMatchingScore4 VisualSimilarity |
Min visual similarity score for valid matching |
Float, 0.0 to 1.0 |
minMatchingScore4 VisualSimilarity: 0.0 |
True |
matchingScoreWeight4 VisualSimilarity |
Weight for visual similarity term in matching cost function |
Float, 0.0 to 1.0 |
matchingScoreWeight4 VisualSimilarity: 0.0 |
True |
See also the Troubleshooting in gst-nvtracker Setup and Parameter Tuning section for solutions to common problems in tracker behavior and tuning.
MaskTracker (Developer Preview)#
Note
To allow users to easily try out and experience MaskTracker, A sample application and scripts to convert the SAM2 model to ONNX are provided on GitHub.
Recently, vision foundation models for video segmentation, such as Segment Anything Model 2 (SAM2) from Meta Inc., have gained significant attention. These models, built on transformer architectures and trained with large-scale datasets, provide highly accurate object segmentation and tracking even in difficult scenarios like occlusion, rapid movement, and changes in appearance. Unlike traditional Re-ID models that are typically limited to specific object types such as people or vehicles, these models achieves high tracking accuracy across a wide range of object classes. In the DeepStream SDK, MaskTracker is a new multi-object tracker that leverages these advanced models for precise segmentation and visual tracking. MaskTracker can operate on single-frame detections, as in the original SAM2, or use periodic detections for continuous tracking.
The segmentation mask for each target is saved in the mask_params field of NvDsObjectMeta in DeepStream meta data. As defined in nvll_osd_struct.h, this structure stores the segmentation mask as a float array with dimensions matching the target’s bounding box (rounded to integer values). Set display-mask=1 in DeepStream OSD config to visualize the masks.
MaskTracker is composed of the following modules:
Target Segmentation: This core module accelerates SAM2 inference using TensorRT to generate segmentation masks and bounding boxes for each target in every frame. It also extracts target features to store in a memory bank and refines the memory bank when a target is matched with a detection.
Data Association: This module matches targets with detections based on the similarity of their locations (IOU) and bounding box sizes, where the target bounding boxes are estimated directly from the segmentation masks.
State Estimation: Detection and mask bounding boxes for each target are fused using a Kalman filter to improve accuracy. For scenes with frequent occlusion or diverse motion, process noise should be set high and measurement noise low, as detection and mask bounding boxes are typically reliable.
Target Management: MaskTracker uses a standard target management module similar to other trackers, but determines each target’s tracking confidence based on SAM2’s mask confidence. Targets with low confidence or those not matched with a detection are placed in shadow tracking mode.
Target Segmentation#
The target segmentation module performs accelerated inference of SAM2 with TensorRT™, generating segmentation masks and bounding boxes for each target. It can be configured to operate in two modes: Segmentation with Visual Tracking and Segmentation-Only mode, which are described below. Due to resource constraints, Jetson platforms only support Segmentation-Only mode.
Model Introduction
SAM2 is composed of the following neural networks, all of which can be converted to ONNX format and accelerated with TensorRT using FP16 precision:
Image Encoder: A transformer-based encoder network that extracts visual features from each frame. This network processes the frame once and shares the extracted features across all targets in that frame.
Memory Attention: This module generates conditional features for each target by combining the current frame’s image encoder features with spatial memory features and object pointers from previous frames, which are stored in the memory bank.
Mask Decoder (including prompt encoder): This component takes bounding box prompts (if provided) and conditional features from memory attention to generate segmentation masks and object pointers. The object pointers capture high-level semantic information to uniquely identify each target.
Memory Encoder: This module downsamples and fuses the segmentation mask with the image encoder features to create spatial memory features for the current frame, which are then stored in the memory bank for future reference.
MaskTracker also includes additional modules implemented in C++ and CUDA, which complement the neural network components described above:
Memory Bank: For each target, the memory bank maintains a queue of spatial memory features and object pointers, storing information from both the initial and most recent frames. The number of initial frames retained can be configured using
numConditionalMem, while the remaining slots are filled with the latest frames, updated in a first-in, first-out manner. The parametermaskMemoryUpdateIntervalcontrols how frequently the memory bank is updated; setting this to a non-zero value increases the interval between updates, allowing for a longer history of past frames. The memory bank also includes parameters to filter out low-quality features. For example,minMemoryUpdateConfidenceensures that only segmentation masks with sufficient confidence are used to update the memory bank. When a target is matched with a detection, the detection is used as a prompt for the mask decoder to update the memory bank, but only if the detection confidence exceedsminPromptUpdateConfidenceand its IOU with other targets is belowminIouDiff4MemoryUpdate, indicating it is not heavily occluded.Post Processing: This step generates precise bounding boxes around the segmentation masks. To avoid errors from inaccurate segmentation, the parameter
minIouPrevFrame4ProgBboxis used to check the IOU between the bounding box in the previous frame and the current one, helping to filter out unreliable results.
Segmention with Visual Tracking Mode
In this mode, all SAM2 networks are enabled to visually track and segment targets across frames. Visual features from previous frames are stored and leveraged to help localize targets in new frames. This approach provides the highest accuracy for object segmentation and tracking, especially in challenging scenarios such as occlusion, rapid movement, and significant changes in appearance. For each frame, the process typically involves two main steps: localization and update. This is the default configuration used in DeepStream MaskTracker.
Localization: This step is performed in the new frame before data association. Each existing target uses SAM2 to localize its mask and bounding box in the new frame. The image encoder and memory attention modules are run to obtain conditional features, which are then passed to the mask decoder without any bounding box prompts to estimate the segmentation mask. A bounding box is generated from the segmentation mask and used to associate the target with a detection if possible.
Update: After data association, each target is updated following target management rules, or terminated if not observed for a long period. Then each target’s memory bank is updated. If detections are available for the current frame and a target is matched with a detection, the detection is provided as a prompt to the mask decoder along with the conditional features to generate an updated segmentation mask and object pointer. If no detections are present, the output masks from the localization step is used. Unmatched detections are initialized as new targets, and their memory bank is empty for the first frame, so mask decoder generates the mask and object pointer only based on the prompt and current frame feature. The memory encoder is then run to update the memory bank with the new masks and object pointers.
Segmentation-Only Mode
In this mode, the image encoder and mask decoder process each frame independently, using the target’s bounding box as a prompt to generate segmentation masks. This approach achieves higher performance by not storing or leveraging features from previous frames. As a result, object tracking is handled by external trackers such as NvSORT or NvDCF. This mode can be seamlessly integrated with other trackers without impacting their tracking accuracy. To enable this mode, configure the relevant settings in config_tracker_module_Segmenter.yml as shown below.
config_tracker_module_Segmenter_Seg_Only.yml
outputLabelNum: 1 # Number of output labels for segmentation
hiddenDim: 256 # Hidden dimension size
encoderFeatureDim: 64 # Encoder feature dimension
inferDims: [3, 1024, 1024] # Segmentation network input dimension CHW or HWC based on inputOrder
# [Input Preprocessing]
inputOrder: 0 # Input order among { NCHW=0, NHWC=1 }
colorFormat: 0 # Segmentation network input color format among {RGB=0, BGR=1 }
offsets: [123.6750, 116.2800, 103.5300] # Array of values to be subtracted from each input channel, with length equal to number of channels
netScaleFactor: 0.0174 # Scaling factor for segmentation network input after subtracting offsets
useVPICropScaler: 1 # Use VPI for image cropping and rescaling
ImageEncoder:
batchSize: 1 # Batch size of image encoder network
workspaceSize: 5000 # Workspace size to be used by image encoder engine, in MB
networkMode: 1 # Image encoder network inference precision mode among {fp32=0, fp16=1, int8=2 }
onnxFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/image_encoder.onnx" # ONNX model path for image encoder
modelEngineFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/image_encoder.onnx_b1_gpu0_fp16.engine" # Engine file path for image encoder
MaskDecoder:
batchSize: 20 # Batch size of mask decoder network, max value is 20
workspaceSize: 5000 # Workspace size to be used by mask decoder engine, in MB
networkMode: 1 # Mask decoder network inference precision mode among {fp32=0, fp16=1, int8=2 }
onnxFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/mask_decoder.onnx" # ONNX model path for mask decoder
modelEngineFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/mask_decoder.onnx_b20_gpu0_fp16.engine" # Engine file path for mask decoder, max batch size is b20
Setup Segmentation Model#
To use MaskTracker with SAM2 models, users need to convert the SAM2 model checkpoints to ONNX format and then to TensorRT engines. The following steps outline the complete setup process.
First, clone the deepstream_tools repository provided by NVIDIA, which contains scripts to export SAM2 models to ONNX format. Then run the export script below to download SAM2 model checkpoints and convert them to ONNX files:
git clone https://github.com/NVIDIA-AI-IOT/deepstream_tools.git
cd deepstream_tools/sam2-onnx-tensorrt
bash run.sh
This script will:
Install SAM2 dependencies
Download the SAM2 model checkpoints from Meta’s repository
Export four key networks to ONNX format.
Save the ONNX files in the
/opt/nvidia/deepstream/deepstream/samples/models/Tracker/directory.
Update the DeepStream config file to use config_tracker_MaskTracker.yml. When running DeepStream applications with MaskTracker for the first time, TensorRT will automatically generate optimized engine files from the ONNX models. This process may take several minutes depending on the hardware platform.
Configuration Parameters#
A sample configuration for MaskTracker is included in the DeepStream SDK package. This setup uses two files: config_tracker_MaskTracker.yml, which should be specified as the ll-config-file in DeepStream applications, and an additional file, config_tracker_module_Segmenter.yml, which provides the segmentation module settings required by MaskTracker.
The following table summarizes the configuration parameters defined in config_tracker_module_Segmenter.yml. The four key networks utilizing the unified Model Inference module, are configured as ImageEncoder, MaskDecoder, MemoryAttention, and MemoryEncoder, and each network is configured with the corresponding ONNX file and engine file. Input pre-processing parameters are used to convert input frame for ImageEncoder.
Module |
Property |
Meaning |
Type and Range |
Default value |
|---|---|---|---|---|
Segmentation Network Dimension |
outputLabelNum |
Number of output masks for segmentation. Only 1 is supported now |
Integer |
outputLabelNum: 1 |
hiddenDim |
Hidden dimension size used in MaskTracker |
Integer |
hiddenDim: 256 |
|
encoderFeatureDim |
Encoder feature dimension in MaskTracker |
Integer |
encoderFeatureDim: 64 |
|
inferDims |
Segmentation network input dimension |
Array of 3 integers |
inferDims: [3, 1024, 1024] |
|
Frame Input Preprocessing |
inputOrder |
Input order (NCHW=0, NHWC=1) |
Integer (0 or 1) |
inputOrder: 0 |
colorFormat |
Input color format (RGB=0, BGR=1) |
Integer (0 or 1) |
colorFormat: 0 |
|
offsets |
Array of values to subtract from each input channel |
Array of 3 floats |
offsets: [123.6750, 116.2800, 103.5300] |
|
netScaleFactor |
Scaling factor for input after subtracting offsets |
Float |
netScaleFactor: 0.0174 |
|
useVPICropScaler |
Use VPI for image cropping and rescaling |
Integer (0 or 1) |
useVPICropScaler: 1 |
|
Memory Management |
updateMemBankPrompt |
Whether to update memory bank using detection bounding box as prompt |
Integer (0 or 1) |
updateMemBankPrompt: 0 |
minIouDiff4MemoryUpdate |
IOU threshold between the current target and other targets for memory update |
Float |
minIouDiff4MemoryUpdate: 0.8 |
|
minMemoryUpdateConfidence |
Minimum confidence for memory update |
Float |
minMemoryUpdateConfidence: 0.5 |
|
maskMemoryUpdateInterval |
Interval for mask memory update |
Integer |
maskMemoryUpdateInterval: 0 |
|
minIouPrevFrame4ProgBbox |
Minimum IOU with previous frame for progressive bbox |
Float |
minIouPrevFrame4ProgBbox: 0.0 |
|
minPromptUpdateConfidence |
Minimum confidence for prompt update |
Float |
minPromptUpdateConfidence: 0.8 |
|
numConditionalMem |
Number of conditional memory entries |
Integer |
numConditionalMem: 1 |
|
TensorRT Inference for Each Network |
batchSize |
Batch size of network |
Integer |
batchSize: 1 |
workspaceSize |
Workspace size for network engine (MB) |
Integer |
workspaceSize: 5000 |
|
networkMode |
Network inference precision mode (fp32=0, fp16=1, int8=2) |
Integer (0, 1, or 2) |
networkMode: 1 |
|
onnxFile |
ONNX model path for network |
String |
onnxFile:”” |
|
modelEngineFile |
Engine file path for network |
String |
modelEngineFile:”” |
Miscellaneous Data Output#
Miscellaneous data provides a mechanism to return additional data to the user outside of the Gst Buffer or NvDsBatchMeta. The miscellaneous data buffer will only be populated when options are enabled for specific feature. Currently the supported types of miscellaneous data are:
Terminated Track List
Shadow Tracking Target Data
Past-frame Target Data
Each type of data has a unique output variable within the miscellaneous data; however, they do share a common data structure, using the unified NvDsTargetMiscDataBatch data structure. A buffer pool is used for its memory management, whose size can be set with user-meta-pool-size. When the latency for downstream plugins to release the buffers is too long, the buffer pool may be empty so tracker will skip reporting the miscellaneous data for next batch. A warning gstnvtracker: Unable to acquire a user meta buffer will be shown, and users can increase the pool size from default 32 to larger values like 64. Specifics for each type of miscellaneous data is defined below in the following sections.
Terminated Track List#
Whenever a target is terminated, the full target trajectory data can be exported to the metadata as part of the miscellaneous data, which is populated in NvDsTargetMiscDataBatch data structure. This data not only informs of the termination event of a target, but also can be useful for a downstream module that performs trajectory-based analysis for each object.
The terminated track list can be saved in a file in either deepstream-app or within the low-level tracker library:
(Option 1) Saving output in
deepstream-app:Add
outputTerminatedTracks: 1in tracker configTargetManagementsectionAdd
terminated-track-output-dir=<dir name>indeepstream-appconfig’s application group propertiescreate the folder
<dir name>Run
deepstream-appto save the terminated track history into text files in<dir name>Data format is defined below.
frame number |
object unique id |
class id |
blank |
blank |
bbox left |
bbox top |
bbox right |
bbox bottom |
blank |
blank |
blank |
blank |
blank |
blank |
blank |
confidence |
tracker state |
visibility |
unsigned int |
long unsigned int |
unsigned int |
int |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
int |
float |
A file will be created for each frame in each stream. Sample data is like:
0 7 2 0 0.0 1535.194092 94.266541 1603.132812 301.653625 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.000000 2 1.000000 1 7 2 0 0.0 1535.938232 94.234810 1603.121338 301.769501 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.982758 2 1.000000 ...
(Option 2) Saving output directly from low level tracker:
Add
outputTerminatedTracks: 1in tracker configTargetManagementsectionAdd
terminatedTrackFilename: <file name prefix>in tracker configTargetManagementsection. For example, setterminatedTrackFilename: track_dumpand the saved file names will betrack_dump_0.txt,track_dump_1.txt, etc.Run
deepstream-appto save the terminated track information directly from the low-level tracker libraryData format is defined below. The foot location, and convex hull data are only useful if SV3DT output is enabled.
frame number(starting from 1) |
object unique id |
bbox left |
bbox top |
bbox right |
bbox bottom |
confidence |
Foot World Position X |
Foot World Position Y |
blank |
class id |
tracker state |
visibility |
Foot Image Position X |
Foot Image Position Y |
ConvexHull Points (optional) |
unsigned int |
long unsigned int |
int |
int |
int |
int |
float |
float |
float |
int |
unsigned int |
int |
float |
float |
float |
int separated by vertical bar |
A file will be created for each stream. Sample data is like:
# SV3DT output disabled 31,48,558,104,31,74,0.949,-1.000,-1.000,-1,0,0.994,-1,-1 32,48,558,104,31,74,0.951,-1.000,-1.000,-1,0,0.995,-1,-1 ... # SV3DT output enabled 31,48,558,104,31,74,0.949,1254.535,2962.867,-1,0,0.994,581,176,-15|-34|-14|-35|-13|-35|-10|-36|-6|-36|-3|-36|0|-36|1|-36|2|-35|16|35|15|35|13|36|9|37|6|37|3|37|0|37|0|36 32,48,558,104,31,74,0.951,1255.602,2968.294,-1,0,0.995,581,176,-14|-34|-14|-35|-13|-35|-10|-35|-6|-36|-3|-36|0|-36|1|-36|2|-35|15|35|15|35|13|36|9|37|6|37|3|37|0|37|0|36 ...
Shadow Tracking Target Data#
As mentioned earlier, even when a target is not being associated with any of the detection bboxes, the target is still being tracked in a Shadow Tracking mode. When tracked in the Shadow Tracking mode, the target data is not being reported to the downstream because the target data may not be reliable.
However, the users are allowed to still report these shadow tracking target data as a part of the miscellaneous data, when outputShadowTracks: 1 is set under TargetManagement section in a tracker config file.
The shadow tracking data can be dumped in to a file when enabled in deepstream-app like below:
Add
shadow-track-output-dir=<dir name>indeepstream-appconfig’s application group propertiescreate the folder
<dir name>Run
deepstream-appto save the Shadow Track history into text files in<dir name>Data format is defined below.
frame number |
object unique id |
class id |
blank |
blank |
bbox left |
bbox top |
bbox right |
bbox bottom |
blank |
blank |
blank |
blank |
blank |
blank |
blank |
confidence |
tracker state |
visibility |
unsigned int |
long unsigned int |
unsigned int |
int |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
int |
float |
A file will be created for each frame in each stream. Sample data is like:
1 11 2 0 0.0 296.346130 262.343445 333.428864 376.817291 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.407002 2 1.000000 1 22 2 0 0.0 1663.921875 857.167725 1752.483521 1049.053223 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.912138 2 1.000000 ...
Important
Both the terminated track data and the shadow tracking object data are not retained in the low-level tracker library when subsequent frames arrive. Thus, if users want to use these data, they should retrieve these miscellaneous data using the NvMOT_RetrieveMiscData() API at the end of every frame in the plugin. Otherwise, the data will be discarded within the tracker library.
Past-frame Target Data#
Past-frame target data is always reported in miscellaneous data, and is appended to the current frame objects in tracker KITTI dump when enabled.
To enable tracker KITTI dump:
Add
kitti-track-output-dir=<dir name>indeepstream-appconfig’s application group propertiescreate the folder
<dir name>Run
deepstream-appto save tracked objects files in<dir name>.Data format is defined below following the KITTI format. The foot location and visibility data will append to the end of each line if SV3DT output is enabled.
object Label |
object Unique Id |
blank |
blank |
blank |
bbox left |
bbox top |
bbox right |
bbox bottom |
blank |
blank |
blank |
blank |
blank |
blank |
blank |
confidence |
visibility (optional) |
Foot Image Position X (optional) |
Foot Image Position Y (optional) |
string |
long unsigned |
float |
int |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
float |
A file will be created for each frame in each stream. Sample data is like:
# SV3DT output disabled person 0 0.0 0 0.0 1302.667236 135.852036 1340.975830 241.724579 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.917301 person 1 0.0 0 0.0 878.249023 195.080475 913.410950 320.695618 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.899029 ... # SV3DT output enabled person 0 0.0 0 0.0 1302.667236 135.852036 1340.975830 241.724579 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.917301 0.966531 1314.492554 239.495193 person 1 0.0 0 0.0 878.249023 195.080475 913.410950 320.695618 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.899029 0.930824 899.187500 316.670013 ...
Setup and Usage of Re-ID Model#
This section describes how to download and setup Re-ID models in different formats, perform INT8 calibration for performance optimization and output Re-ID features to downstream modules.
Setup Sample Re-ID Models#
The supported Re-ID model formats are NVIDIA TAO and ONNX. Multiple ready-to-use sample models are listed below. Scripts and README file for users to setup the model are provided in sources/tracker_ReID.
Note
UFF is no longer supported by TensorRT, so please migrate to TAO or ONNX models.
NVIDIA TAO ReIdentificationNet#
NVIDIA pre-trained ReIdentificationNet is a high accuracy ResNet-50 model with feature length 256. Users can download either the ETLT (Encrypted ONNX by TAO Toolkit) or ONNX with below command. For different versions of the model, please refer to its model card.
mkdir /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
wget 'https://api.ngc.nvidia.com/v2/models/nvidia/tao/reidentificationnet/versions/deployable_v1.0/files/resnet50_market1501.etlt' -P /opt/nvidia/deepstream/deepstream/samples/models/Tracker/ # v1.0 ETLT model
# Optionally, use below command for v1.2 ONNX model
wget 'https://api.ngc.nvidia.com/v2/models/org/nvidia/team/tao/reidentificationnet/deployable_v1.2/files/resnet50_market1501_aicity156.onnx' -P /opt/nvidia/deepstream/deepstream/samples/models/Tracker/ # v1.2 ONNX model
Note the raw output from this network is not L2 normalized, so addFeatureNormalization: 1 is set to add L2 normalization as a post processing. The default tracker config file supports the ETLT model by default. To use the ONNX model, remove existing tltEncodedModel and modelEngineFile parameters and add new onnxFile and modelEngineFile parameters in tracker config file ReID session as below.
ReID:
...
# Remove below two lines from the original config
# tltEncodedModel: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/resnet50_market1501.etlt" # NVIDIA TAO model path
# modelEngineFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/resnet50_market1501.etlt_b100_gpu0_fp16.engine" # Engine file path
# Add below two lines
onnxFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/resnet50_market1501_aicity156.onnx" # ONNX model path
modelEngineFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/resnet50_market1501_aicity156.onnx_b100_gpu0_fp16.engine" # Engine file path matching the new ONNX model
Customize Re-ID Model#
Users can also train a custom Re-ID model in ONNX format, whose output is a single vector for each object. Then the Re-ID similarity score will be computed based on the cosine metric and used to perform the data association in the same way as the official model. The steps are:
Train a Re-ID network using deep learning frameworks such as PyTorch or TensorFlow.
Make sure the network layers are supported by TensorRT and convert the model into ONNX. Mixed precision inference is still supported, and a calibration cache is required for INT8 mode.
Specify the following parameters in tracker config file based on the custom model’s properties. Then run DeepStream SDK with the new Re-ID model.
reidFeatureSizereidHistorySizeinferDimscolorFormatnetworkModeoffsetsnetScaleFactoraddFeatureNormalization
ONNX model must specify below parameters.
onnxFile
Re-ID Feature Output#
Objects’ Re-ID features can be accessed in the tracker plugin and downstream modules, which can be used for other tasks such as multi-target multi-camera tracking. Steps to retrieve those features using deepstream-app are:
Add
outputReidTensor: 1in tracker configReIDsection. Addreid-track-output-dir=<dir name>indeepstream-appconfig’s application group properties and create the folder<dir name>.Run
deepstream-appto save the Re-ID features in each frame into text files in<dir name>. In each text file, each line’s first integer is object id, and the remaining floats are its feature vector. Users can checkwrite_reid_track_output()indeepstream_app.cto understand how these features are retrieved.
This feature is supported whenever NvDeepSORT or Re-ID based re-association is used. To retrieve Re-ID features for every frame, make sure interval=0 in PGIE config and reidExtractionInterval: 0 if re-association is enabled. Otherwise, the Re-ID features will be extracted at intervals only when PGIE generates bounding boxes and reidExtractionInterval is met.
Setup and Usage of Sub-batching#
This section describes how to use the sub-batching feature with multiple low-level tracker config files. Two use cases are explained: the first one with varied tracker algorithms and the second one with varied compute backends.
Here, a deepstream-app pipeline is used as an example.
Use-case 1#
This use-case illustrates an application with a batch size of 4 (i.e., 4 streams). The batch is split into 3 sub-batches: the first sub-batch of size 2 and the next two sub-batches of size 1 each. The first sub-batch uses NvDCF tracker, the second sub-batch uses NvSORT tracker, and the third sub-batch uses IOU tracker, respectively.
To achieve this, modify the [tracker] section in source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display.txt configuration file that comes with DeepStream package as shown below :
[tracker]
enable=1
tracker-width=960
tracker-height=544
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so
ll-config-file=config_tracker_NvDCF_accuracy.yml;config_tracker_NvSORT.yml;config_tracker_IOU.yml
sub-batches=0,1;2;3
In this example, sub-batches can also be configured using option 2 i.e. sub-batches=2:1:1. Refer Gst Properties for details.
Use-case 2#
This use-case illustrates an application with a batch size of 4, where the batch is split into 2 sub-batches each of size 2: the first sub-batch uses NvDCF tracker with setting visualTrackerType: 1 (i.e., existing DCF module). The second sub-batch uses NvDCF tracker with visualTrackerType: 2 and vpiBackend4DcfTracker: 2 (i.e. NvDCF_VPI tracker with PVA backend). Please note that, since this use-case configures PVA backend, it will run only on Jetson platforms.
Steps are :
Create a copy of
config_tracker_NvDCF_accuracy.ymland name it asconfig_tracker_NvDCF_accuracy_PVA.ymlIn
config_tracker_NvDCF_accuracy_PVA.ymlmodify theVisualTracker:section as follows :VisualTracker: visualTrackerType: 2 # the type of visual tracker among { DUMMY=0, NvDCF=1, NvDCF_VPI=2 } vpiBackend4DcfTracker: 2 # the type of compute backend among {CUDA=1, PVA=2} ....
Then modify the
[tracker]section insource4_1080p_dec_infer-resnet_tracker_sgie_tiled_display.txtas follows :[tracker] enable=1 tracker-width=960 tracker-height=544 ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so ll-config-file=config_tracker_NvDCF_accuracy.yml;config_tracker_NvDCF_accuracy_PVA.yml sub-batches=0,1;2,3
In this example, sub-batches can also be configured using option 2 i.e. sub-batches=2:2. Refer Gst Properties for details.
Similarly, if an application using the same NvDCF configuration file has more than 128 streams (130 streams for example), tracker section can be set to ll-config-file=config_tracker_NvDCF_accuracy.yml;config_tracker_NvDCF_accuracy.yml, sub-batches=65:65.
For further details on implementation of sub-batches feature, please refer to a writeup at the end of nvtracker_proc.cpp in nvtracker plugin’s source code.
The most optimal sub-batches configuration for a pipeline depends on multiple factors like elements in the pipeline, configuration of each element, hardware configuration etc. Increasing the number of sub-batches parallelizes the processing of streams in a batch. But it also adds an overhead. Hence, the number of sub-batches to configure needs to be determined experimentally by comparing GPU/PVA utilization and performance across various sub-batches configurations. A thumb rule is to start with a single batch and keep splitting it into sub-batches until an optimal performance point is reached.
Setup and Visualization of Tracker Sample Pipelines#
This section describes how to setup a multi-object tracking pipeline with various NVIDIA® pre-trained detector models and DeepStream multi-object trackers, and provides ready-to-use detector and tracker config files optimized for high accuracy tracking. The optimal tracker configs for People tracking (e.g., config_tracker_NvSORT.yml, config_tracker_NvDeepSORT.yml, config_tracker_NvDCF_accuracy.yml, etc.) are already provided in DeepStream release package, so here we present optimized detector parameters only. Then the visualization of some sample outputs and internal states (such as correlation responses for a few selected targets) are presented to help users to better understand how NvDsTracker works, especially on the visual tracker module. In addition, we present detector config params and tracker config params for vehicle tracking use-case as well.
People Tracking#
NVIDIA® pre-trained PeopleNet detects person, bag, and face classes. The pre-trained model with ResNet-34 backbone is on NVIDIA NGC catalog. It can be used in PGIE module in conjunction with various low level trackers for people tracking.
Setup#
Here deepstream-app pipeline is used as an example, which can be naturally extended to other applications. Steps are:
Download the detector model files here, and place the files under
/opt/nvidia/deepstream/deepstream/samples/models/peoplenetCopy detector config file in below sections
config_infer_primary_PeopleNet.txtfor the specific low level tracker (for example PeopleNet + NvDCF) into work directory:cp config_infer_primary_PeopleNet.txt /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-appAssuming
deepstream-appconfig file is/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/deepstream_app_config.txt, set PGIE and tracker config files in it:
deepstream_app_config.txt
## Other groups
[primary-gie]
## Use PeopleNet as PGIE
config-file=config_infer_primary_PeopleNet.txt
## Other [primary-gie] configs
[tracker]
## Specify the low level tracker (for example NvSORT)
# ll-config-file=config_tracker_IOU.yml
ll-config-file=config_tracker_NvSORT.yml
# ll-config-file=config_tracker_NvDCF_perf.yml
# ll-config-file=config_tracker_NvDCF_accuracy.yml
# ll-config-file=config_tracker_NvDeepSORT.yml
## Other [tracker] configs
/opt/nvidia/deepstream is the default DeepStream installation directory. The paths will be different if the user sets up in different directory.
PeopleNet + NvSORT#
This pipeline performs high performance people tracking with reasonable accuracy. Such a deepstream-app pipeline is constructed with the following components:
Detector: PeopleNet v2.6.2 (w/ ResNet-34 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvSORT with
config_tracker_NvSORT.ymlconfiguration in DeepStream release
A set of recommended detector config params for PeopleNet v2.6.2 to be used with NvSORT tracker is:
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1555
nms-iou-threshold=0.3386
minBoxes=2
dbscan-min-score=1.9224
eps=0.3596
detected-min-w=20
detected-min-h=20
PeopleNet + NvDeepSORT#
This pipeline enables people Re-ID capability during tracking. Such a deepstream-app pipeline is constructed with the following components:
Detector: PeopleNet v2.6.2 (w/ ResNet-34 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvDeepSORT with
config_tracker_NvDeepSORT.ymlconfiguration in DeepStream release
A set of recommended detector config params for PeopleNet v2.6.2 to be used with NvDeepSORT tracker is:
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1653
nms-iou-threshold=0.5242
minBoxes=2
dbscan-min-score=1.7550
eps=0.1702
detected-min-w=20
detected-min-h=20
PeopleNet + NvDCF#
This pipeline performs more accurate people tracking. For the output visualization, a deepstream-app pipeline is first constructed with the following components:
Detector: PeopleNet v2.6.2 (w/ ResNet-34 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvDCF with
config_tracker_NvDCF_accuracy.ymlconfiguration in DeepStream release
For better visualization, the following changes were also made:
featureImgSizeLevel: 5is set underVisualTrackersection inconfig_tracker_NvDCF_accuracy.ymltracker-height=960andtracker-width=544under[tracker]section in the deepstream-app config file
A set of recommended detector config params for PeopleNet v2.6.2 to be used with NvDCF_accuracy tracker is:
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1429
nms-iou-threshold=0.4688
minBoxes=3
dbscan-min-score=0.7726
eps=0.2538
detected-min-w=20
detected-min-h=20
The resulting output video of the aforementioned pipeline with (PeopleNet + Hybrid clustering + NvDCF) is shown below, but please note that only ‘Person’-class objects are detected and shown in the video:
While the video above shows the per-stream output, each animated figure below shows (1) the cropped & scaled image patch used for each target on the left side and (2) the corresponding correlation response map for the target on the right side. As mentioned earlier, the yellow + mark shows the peak location of the correlation response map generated by using the learned correlation filter, while the puple x marks show the the center of nearby detector objects.
Person 1 (w/ Blue hat + gray backpack) 
|
Person 6 (w/ Red jacket + gray backpack) 
|
Person 4 (w/ Green jacket) 
|
Person 5 (w/ Cyan jacket) 
|
The figures above show how the correlation responses progress over time for the cases of no occlusion, partial occlusion, and full occlusions happening. It can be seen that even when a target undergoes a full occlusion for a prolonged period, the NvDCF tracker is able to keep track of the targets in many cases.
If featureImgSizeLevel: 3 is used instead for better performance, the resolution of the image patch used for each target would get lower like shown in the figure below.
Person 1 (w/ Blue hat + gray backpack) 
|
Person 6 (w/ Red jacket + gray backpack) 
|
Vehicle Tracking#
To perform tracking of vehicle and other types of targets (such as pedestrians, bicycles and road signs), a NVIDIA® pre-trained detector model is available in NGC:
TrafficCamNet: A newer model based on ResNet-18 backbone with higher detection accuracy on NVIDIA NGC.
The following samples demonstrate using TrafficCamNet and various trackers with different detection intervals for performance and accuracy tradeoff.
Setup#
Here deepstream-app pipeline is used as an example, which can be naturally extended to other applications. Steps to setup a pipeline are:
For TrafficCamNet, download the detector model files here, and place the files under
/opt/nvidia/deepstream/deepstream/samples/models/trafficcamnetCopy detector and tracker config files in below sections for the specific tracker type (for example TrafficCamNet + NvDCF) into work directory:
cp config_infer_primary_TrafficCamNet.txt /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-appAssuming
deepstream-appconfig file is/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/deepstream_app_config.txt, set detector and tracker config files in it like the following:
deepstream_app_config.txt
## Other groups
[primary-gie]
## Use TrafficCamNet as PGIE
config-file=config_infer_primary_TrafficCamNet.txt
## Other [primary-gie] configs
[tracker]
## Specify the low level tracker (for example NvDCF_accuracy)
# ll-config-file=config_tracker_IOU.yml
# ll-config-file=config_tracker_NvSORT.yml
# ll-config-file=config_tracker_NvDCF_perf.yml
ll-config-file=config_tracker_NvDCF_accuracy.yml
# ll-config-file=config_tracker_NvDeepSORT.yml
## Other [tracker] configs
/opt/nvidia/deepstream is the default DeepStream installation directory. The paths will be different if the user sets up in different directory.
TrafficCamNet + NvSORT#
This pipeline performs high performance vehicle tracking with reasonable accuracy. Such a deepstream-app pipeline is constructed with the following components:
Detector: TrafficCamNet v1.0.3 (w/ ResNet-18 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvSORT with configuration as below
The detector and tracker config files:
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.txt
labelfile-path=../../models/trafficcamnet/labels.txt
onnx-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.2327
nms-iou-threshold=0.1760
minBoxes=2
dbscan-min-score=0.7062
eps=0.4807
detected-min-w=20
detected-min-h=20
config_tracker_NvSORT.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0415
TargetManagement:
enableBboxUnClipping: 0
maxTargetsPerStream: 300
minIouDiff4NewTarget: 0.6974
minTrackerConfidence: 0.8049
probationAge: 5
maxShadowTrackingAge: 42
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
minMatchingScore4Overall: 0.2042
minMatchingScore4SizeSimilarity: 0.2607
minMatchingScore4Iou: 0.3708
matchingScoreWeight4SizeSimilarity: 0.2639
matchingScoreWeight4Iou: 0.4384
tentativeDetectorConfidence: 0.1054
minMatchingScore4TentativeIou: 0.4953
usePrediction4Assoc: 1
StateEstimator:
stateEstimatorType: 2
noiseWeightVar4Loc: 0.0853
noiseWeightVar4Vel: 0.0061
useAspectRatio: 1
TrafficCamNet + NvDeepSORT#
This pipeline enables vehicle Re-ID capability during tracking. Such a deepstream-app pipeline is constructed with the following components:
Detector: TrafficCamNet v1.0.3 (w/ ResNet-18 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvDeepSORT with configuration as below. No vehicle Re-ID models are included in DeepStream so far, so the user needs to follow Customize Re-ID Model to setup a vehicle Re-ID model and change ReID section in tracker config.
The detector and tracker config files:
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.txt
labelfile-path=../../models/trafficcamnet/labels.txt
onnx-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.1654
nms-iou-threshold=0.7614
minBoxes=3
dbscan-min-score=2.4240
eps=0.3615
detected-min-w=20
detected-min-h=20
config_tracker_NvDeepSORT.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0451
TargetManagement:
preserveStreamUpdateOrder: 0
maxTargetsPerStream: 150
minIouDiff4NewTarget: 0.0602
minTrackerConfidence: 0.7312
probationAge: 9
maxShadowTrackingAge: 59
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
thresholdMahalanobis: 34.3052
minMatchingScore4Overall: 0.0231
minMatchingScore4SizeSimilarity: 0.3104
minMatchingScore4Iou: 0.3280
minMatchingScore4ReidSimilarity: 0.6805
matchingScoreWeight4SizeSimilarity: 0.7103
matchingScoreWeight4Iou: 0.5429
matchingScoreWeight4ReidSimilarity: 0.6408
tentativeDetectorConfidence: 0.0483
minMatchingScore4TentativeIou: 0.5093
StateEstimator:
stateEstimatorType: 2
noiseWeightVar4Loc: 0.0739
noiseWeightVar4Vel: 0.0097
useAspectRatio: 1
ReID: # need customization
reidType: 1
batchSize: 100
workspaceSize: 1000
reidFeatureSize: 128
reidHistorySize: 100
inferDims: [128, 64, 3]
networkMode: 0
inputOrder: 1
colorFormat: 0
offsets: [0.0, 0.0, 0.0]
netScaleFactor: 1.0000
keepAspc: 1
# custom Re-ID model path
TrafficCamNet + NvDCF#
This pipeline performs more accurate vehicle tracking. For the output visualization, a deepstream-app pipeline is first constructed with the following components:
Detector: TrafficCamNet v1.0.3 (w/ ResNet-18 as backbone)
Post-processing algorithm for object detection: Hybrid clustering (i.e., DBSCAN + NMS)
Tracker: NvDCF with configuration as below. No vehicle Re-ID models are included in DeepStream so far, so the user needs to follow Customize Re-ID Model to setup a vehicle Re-ID model and change ReID section in tracker config.
The detector and tracker config files:
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/trafficcamnet.txt
labelfile-path=../../models/trafficcamnet/labels.txt
tlt-encoded-model=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.etlt
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
uff-input-blob-name=input_1
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
output-blob-names=output_cov/Sigmoid;output_bbox/BiasAdd
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.3034
nms-iou-threshold=0.5002
minBoxes=3
dbscan-min-score=1.2998
eps=0.1508
detected-min-w=20
detected-min-h=20
config_tracker_NvDCF_accuracy.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0382
TargetManagement:
enableBboxUnClipping: 0
preserveStreamUpdateOrder: 0
maxTargetsPerStream: 150
minIouDiff4NewTarget: 0.1356
minTrackerConfidence: 0.2136
probationAge: 1
maxShadowTrackingAge: 49
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
enableReAssoc: 1
minMatchingScore4Overall: 0.0324
minTrackletMatchingScore: 0.2979
minMatchingScore4ReidSimilarity: 0.4329
matchingScoreWeight4TrackletSimilarity: 0.5117
matchingScoreWeight4ReidSimilarity: 0.8356
minTrajectoryLength4Projection: 14
prepLength4TrajectoryProjection: 50
trajectoryProjectionLength: 116
maxAngle4TrackletMatching: 180
minSpeedSimilarity4TrackletMatching: 0
minBboxSizeSimilarity4TrackletMatching: 0.2154
maxTrackletMatchingTimeSearchRange: 16
trajectoryProjectionProcessNoiseScale: 0.0100
trajectoryProjectionMeasurementNoiseScale: 100
trackletSpacialSearchRegionScale: 0.0742
reidExtractionInterval: 2
enableVanishingTrackletReconstruction: 0
minInclusionRatio4DuplicateTrackletRemoval: 0.5705
minIou4DuplicateTrackletRemoval: 0.5260
minMatchRatio4ValidTrackletDetermination: 0.4385
minVisibility4VanishingTrackletReconstruction: 0.3485
visibilityThreshold4VanishingTrackletDetection: 0.5817
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
minMatchingScore4Overall: 0.1103
minMatchingScore4SizeSimilarity: 0.0392
minMatchingScore4Iou: 0.0980
minMatchingScore4VisualSimilarity: 0.3234
matchingScoreWeight4VisualSimilarity: 0.4223
matchingScoreWeight4SizeSimilarity: 0.8416
matchingScoreWeight4Iou: 0.6517
tentativeDetectorConfidence: 0.0198
minMatchingScore4TentativeIou: 0.1844
StateEstimator:
stateEstimatorType: 1
processNoiseVar4Loc: 374.6508
processNoiseVar4Size: 3364.1350
processNoiseVar4Vel: 3.6082
measurementNoiseVar4Detector: 164.4517
measurementNoiseVar4Tracker: 3439.5683
VisualTracker:
visualTrackerType: 1
useColorNames: 1
useHog: 1
featureImgSizeLevel: 4
featureFocusOffsetFactor_y: 0.0652
filterLr: 0.0993
filterChannelWeightsLr: 0.0549
gaussianSigma: 0.9047
ReID: # need customization
reidType: 2
batchSize: 100
workspaceSize: 1000
reidFeatureSize: 128
reidHistorySize: 148
inferDims: [128, 64, 3]
networkMode: 0
inputOrder: 1
colorFormat: 0
offsets: [0.0, 0.0, 0.0]
netScaleFactor: 1.0000
keepAspc: 1
# onnxFile: customize_onnx_path
Below is a side-by-side comparison of TrafficCamNet with different trackers on a challenging scene with lots of occlusions. From the top-left corner in the clockwise direction are detection only, NvSORT, NvDeepSORT, and NvDCF results. NvDCF has the highest tracking accuracy and robustness to occlusion.
Tracker Accuracy Tuning#
Tracker sample pipelines demonstrated in above section include lots of detector and tracker parameters optimized for people tracking. When users deploy such pipelines for other scenarios, such as traffic, animals, etc., a pain point is how to find the optimal parameters with the highest accuracy KPI for each use case. Manual parameter tuning requires in-depth knowledge on the tracker algorithm and how each parameter would affect the functionality. Given the large number of parameters, the complexity of such process would increase exponentially.
Starting from DeepStream 7.0, a new tool PipeTuner is released to allow automatic accuracy tuning. It efficiently explores the (potentially very high-dimensional) parameter space and automatically finds the optimal parameters for the pipelines, which yields the highest KPI on the dataset. Base on their use case, users can tune the tracker on public multi-object tracking datasets, such as MOT Challenge, KITTI, or create their own dataset with sample videos and ground truth (bounding box and object ID). Users can select common tracking accuracy metrics including HOTA, MOTA and IDF1 as the KPI. Visit Accuracy Tuning Tools on how to setup PipeTuner and start DeepStream tracker accuracy tuning.
How to Implement a Custom Low-Level Tracker Library#
To write a custom low-level tracker library, users are expected to implement the API defined in
sources/includes/nvdstracker.h, which is covered in an earlier section on NvDsTracker API , and parts of the API refer tosources/includes/nvbufsurface.h. Thus, the users would need to includenvdstracker.hto implement the API:#include "nvdstracker.h"Below is a sample implementation of each API. Assuming that the low-level tracker library defines and implements a custom class (e.g.,
NvMOTContextclass in the sample code below) to perform actual operations corresponding to each API call. Below is a sample code for initialization and de-initialization APIs:Note
The sample code below have some skeletons only. Users are expected to add proper error handling and additional codes as needed
NvMOTStatus NvMOT_Init(NvMOTConfig *pConfigIn, NvMOTContextHandle *pContextHandle, NvMOTConfigResponse *pConfigResponse) { if(pContextHandle != nullptr) { NvMOT_DeInit(*pContextHandle); } /// User-defined class for the context NvMOTContext *pContext = nullptr; /// Instantiate the user-defined context pContext = new NvMOTContext(*pConfigIn, *pConfigResponse); /// Pass the pointer as the context handle *pContextHandle = pContext; /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the constructor of `NvMOTContext` * to show what may need to happen when NvMOTContext is instantiated in the above code for `NvMOT_Init` API */ NvMOTContext::NvMOTContext(const NvMOTConfig &config, NvMOTConfigResponse& configResponse) { // Set CUDA device as needed cudaSetDevice(m_Config.miscConfig.gpuId) // Instantiate an appropriate localizer/tracker implementation // Load and parse the config file for the low-level tracker using the path to a config file m_pLocalizer = LocalizerFactory::getInstance().makeLocalizer(config.customConfigFilePath); // Set max # of streams to be supported // ex) uint32_t maxStreams = config.maxStreams; // Use the video frame info for(uint i=0; i<m_Config.numTransforms; i++) { // Use the expected color format from the input source images NvBufSurfaceColorFormat configColorFormat = (NvBufSurfaceColorFormat)m_Config.perTransformBatchConfig[i].colorFormat; // Use the frame width, height, and pitch as needed uint32_t frameHeight = m_Config.perTransformBatchConfig[i].maxHeight; uint32_t frameWidth = m_Config.perTransformBatchConfig[i].maxWidth; uint32_t framePitch = m_Config.perTransformBatchConfig[i].maxPitch; /* Add here to pass the frame info to the low-level tracker */ } // Set if everything goes well configResponse.summaryStatus = NvMOTConfigStatus_OK; }void NvMOT_DeInit(NvMOTContextHandle contextHandle) { /// Destroy the context handle delete contextHandle; }During the initialization stage (when
NvMOT_Init()is called), the context for the low-level tracker is expected to be instantiated, and its pointer is passed as the context handle (i.e.,pContextHandle) as the output as well as the output status inpConfigResponse. Users may allocate memories based on the information about the video frames (e.g., width, height, pitch, and colorFormat) and streams (e.g., max # of streams) from the inputNvMOTConfig *pConfigIn, where the definition of the structNvMOTConfigcan be found innvdstracker.h. The path to the config file for the low-level tracker library inpConfigIn->customConfigFilePathcan be also used to parse the config file to initialize the low-level tracker library.After initialization is finished, the tracker plugin queries parameters needed from low-level tracker library. The query function needs to be implemented like below:
NvMOTStatus NvMOT_Query(uint16_t customConfigFilePathSize, char* pCustomConfigFilePath, NvMOTQuery *pQuery) { /** * Users can parse the low-level config file in pCustomConfigFilePath to check * the low-level tracker's requirements */ /** An optional function queryParams(NvMOTQuery&) can be implemented in context handle to fill query params. */ /* if (pQuery->contextHandle) { pQuery->contextHandle->queryParams(*pQuery); } */ /** Required configs for all custom trackers. */ pQuery->computeConfig = NVMOTCOMP_GPU; // among {NVMOTCOMP_GPU, NVMOTCOMP_CPU} pQuery->numTransforms = 1; // 0 for IOU and NvSORT tracker, 1 for NvDCF or NvDeepSORT tracker as they require the video frames pQuery->supportPastFrame = true; // Set true only if the low-level tracker supports the past-frame data pQuery->batchMode = NvMOTBatchMode_Batch; // batchMode must be set as NvMOTBatchMode_Batch pQuery->colorFormats[0] = NVBUF_COLOR_FORMAT_NV12; // among {NVBUF_COLOR_FORMAT_NV12, NVBUF_COLOR_FORMAT_RGBA} #ifdef __aarch64__ pQuery->memType = NVBUF_MEM_DEFAULT; #else pQuery->memType = NVBUF_MEM_CUDA_DEVICE; #endif // among {NVBUF_MEM_DEFAULT, NVBUF_MEM_CUDA_DEVICE, NVBUF_MEM_CUDA_UNIFIED, NVBUF_MEM_CUDA_PINNED, ... } pQuery->maxTargetsPerStream = 150; // Max number of targets stored for each stream /** Optional configs to set for additional features. */ pQuery->maxShadowTrackingAge = 30; // Maximum length of shadow tracking, required if supportPastFrame is true pQuery->outputReidTensor = true; // Set true only if the low-level tracker supports outputting reid feature pQuery->reidFeatureSize = 256; // Size of Re-ID feature, required if outputReidTensor is true /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ }Once the low-level tracker library creates the tracker context and performs query during the initialization stage, it needs to implement a function to process each frame batch, which is
NvMOT_Process(). Make sure to set the stream ID properly in the output so thatpParams->frameList[i].streamIDmatches withpTrackedObjectsBatch->list[j].streamIDif they are for the same stream, regardless ofiandj. The methodNvMOTContext::processFrame()in the sample code below is expected to perform the required multi-object tracking operations with the input data of the video frames and the detector object information, while reporting the tracking outputs inNvMOTTrackedObjBatch *pTrackedObjectsBatch.Users can refer to Accessing NvBufSurface memory in OpenCV to know more about how to access the pixel data in the video frames.
NvMOTStatus NvMOT_Process(NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackedObjBatch *pTrackedObjectsBatch) { /// Process the given video frame using the user-defined method in the context, and generate outputs contextHandle->processFrame(pParams, pTrackedObjectsBatch); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::processFrame()` * to show what may need to happen when it is called in the above code for `NvMOT_Process` API */ NvMOTStatus NvMOTContext::processFrame(const NvMOTProcessParams *params, NvMOTTrackedObjBatch *pTrackedObjectsBatch) { // Make sure the input frame is valid according to the MOT Config used to create this context for(uint streamInd=0; streamInd<params->numFrames; streamInd++) { NvMOTFrame *motFrame = ¶ms->frameList[streamInd]; for(uint i=0; i<motFrame->numBuffers; i++) { /* Add something here to check the validity of the input using the following info*/ motFrame->bufferList[i]->width motFrame->bufferList[i]->height motFrame->bufferList[i]->pitch motFrame->bufferList[i]->colorFormat } } // Construct the mot input frames std::map<NvMOTStreamId, NvMOTFrame*> nvFramesInBatch; for(NvMOTStreamId streamInd=0; streamInd<params->numFrames; streamInd++) { NvMOTFrame *motFrame = ¶ms->frameList[streamInd]; nvFramesInBatch[motFrame->streamID] = motFrame; } if(nvFramesInBatch.size() > 0) { // Perform update and construct the output data inside m_pLocalizer->update(nvFramesInBatch, pTrackedObjectsBatch); /** * The call m_pLocalizer->update() is expected to properly populate the output (i.e., `pTrackedObjectsBatch`). * * One thing to not forget is to fill `pTrackedObjectsBatch->list[i].list[j].associatedObjectIn`, where * `i` and `j` are indices for stream and targets in the list, respectively. * If the `j`th target was associated/matched with a detector object, * then `associatedObjectIn` is supposed to have the pointer to the associated detector object. * Otherwise, `associatedObjectIn` shall be set NULL. */ } }The low-level tracker can send miscellaneous data to the tracker plugin by
NvMOT_RetrieveMiscData()API. Here past frame data is used as an example. Other types of customized miscellaneous data can be added inNvMOTTrackerMiscDatastruct and also be outputted inretrieveMiscData.NvMOTStatus NvMOT_RetrieveMiscData(NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackerMiscData *pTrackerMiscData) { /// Retrieve the past-frame data if there are contextHandle->retrieveMiscData(pParams, pTrackerMiscData); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::processFramePast()` * to show what may need to happen when it is called in the above code for `NvMOT_ProcessPast` API */ NvMOTStatus NvMOTContext::retrieveMiscData(const NvMOTProcessParams *params, NvMOTTrackerMiscData *pTrackerMiscData) { std::set<NvMOTStreamId> videoStreamIdList; ///\ Indicate what streams we want to fetch past-frame data for(NvMOTStreamId streamInd=0; streamInd<params->numFrames; streamInd++) { videoStreamIdList.insert(params->frameList[streamInd].streamID); } ///\ Retrieve past frame data if (pTrackerMiscData && pTrackerMiscData->pPastFrameObjBatch) { m_pLocalizer->outputPastFrameObjs(videoStreamIdList, pTrackerMiscData->pPastFrameObjBatch); } /** * Add other types of miscellaneous data here */ }For the cases where the video stream sources are dynamically removed and added, the API call
NvMOT_RemoveStreams()can be implemented to clean-up the resources no longer needed.NvMOTStatus NvMOT_RemoveStreams(NvMOTContextHandle contextHandle, NvMOTStreamId streamIdMask) { /// Remove the specified video stream from the low-level tracker context contextHandle->removeStream(streamIdMask); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::removeStream()` * to show what may need to happen when it is called in the above code for `NvMOT_RemoveStreams` API */ NvMOTStatus NvMOTContext::removeStream(const NvMOTStreamId streamIdMask) { m_pLocalizer->deleteRemovedStreamTrackers(streamIdMask); }In sum, to work with the NvDsTracker APIs, users may want to define
class NvMOTContextlike below to implement the methods in the code above. The actual implementation of each method may differ depending on the tracking algorithm the user choose to implement./** * @brief Context for input video streams * * The stream context holds all necessary state to perform multi-object tracking * within the stream. * */ class NvMOTContext { public: NvMOTContext(const NvMOTConfig &configIn, NvMOTConfigResponse& configResponse); ~NvMOTContext(); /** * @brief Process a batch of frames * * Internal implementation of NvMOT_Process() * * @param [in] pParam Pointer to parameters for the frame to be processed * @param [out] pTrackedObjectsBatch Pointer to object tracks output */ NvMOTStatus processFrame(const NvMOTProcessParams *params, NvMOTTrackedObjBatch *pTrackedObjectsBatch); /** * @brief Output the miscellaneous data if there are * * Internal implementation of retrieveMiscData() * * @param [in] pParam Pointer to parameters for the frame to be processed * @param [out] pTrackerMiscData Pointer to miscellaneous data output */ NvMOTStatus retrieveMiscData(const NvMOTProcessParams *params, NvMOTTrackerMiscData *pTrackerMiscData); /** * @brief Terminate trackers and release resources for a stream when the stream is removed * * Internal implementation of NvMOT_RemoveStreams() * * @param [in] streamIdMask removed stream ID */ NvMOTStatus removeStream(const NvMOTStreamId streamIdMask); protected: /** * Users can include an actual tracker implementation here as a member * `IMultiObjectTracker` can be assumed to an user-defined interface class */ std::shared_ptr<IMultiObjectTracker> m_pLocalizer; };