Overview#
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and developers working on Large Language Models, Multimodal, and Speech AI (e.g. Automatic Speech Recognition and Text-to-Speech). It enables users to efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
Important
This page is focused on Speech AI, for LLM/VLM/Diffusion models support, please refer to the NeMo Framework documentation.
Speech AI#
Developing conversational AI models is a complex process that involves defining, constructing, and training models within particular domains. This process typically requires several iterations to reach a high level of accuracy. It often involves multiple iterations to achieve high accuracy, fine-tuning on various tasks and domain-specific data, ensuring training performance, and preparing models for inference deployment.
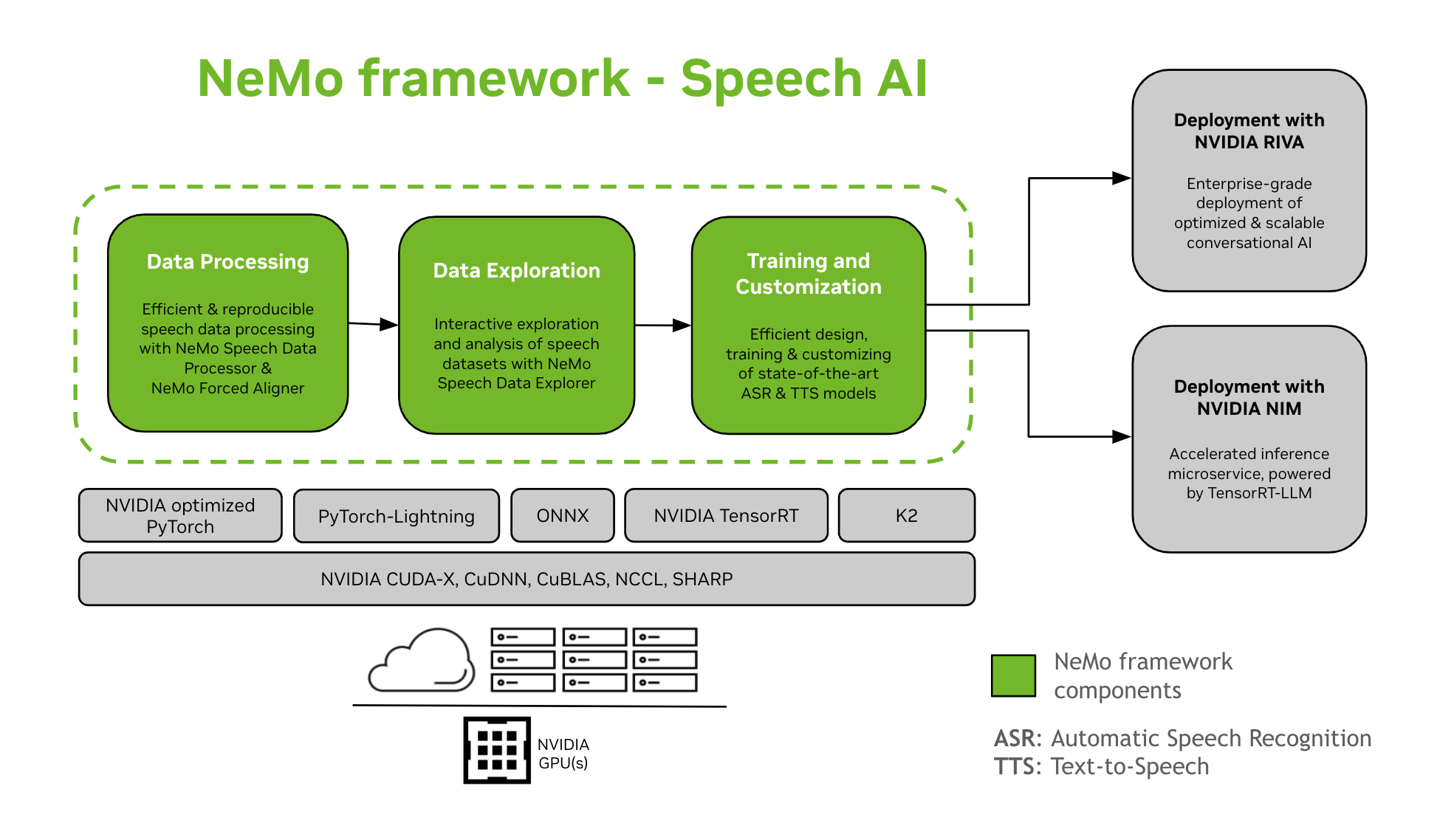
NeMo Framework provides support for the training and customization of Speech AI models. This includes tasks like Automatic Speech Recognition (ASR) and Text-To-Speech (TTS) synthesis. It offers a smooth transition to enterprise-level production deployment with NVIDIA Riva. To assist developers and researchers, NeMo Framework includes state-of-the-art pre-trained checkpoints, tools for reproducible speech data processing, and features for interactive exploration and analysis of speech datasets. The components of the NeMo Framework for Speech AI are as follows:
- Training and Customization
NeMo Framework contains everything needed to train and customize speech models (ASR, Speech Classification, Speaker Recognition, Speaker Diarization, and TTS) in a reproducible manner.
- SOTA Pre-trained Models
NeMo Framework provides state-of-the-art recipes and pre-trained checkpoints of several ASR and TTS models, as well as instructions on how to load them.
- Speech Tools
NeMo Framework provides a set of tools useful for developing ASR and TTS models, including:
NeMo Forced Aligner (NFA) for generating token-, word- and segment-level timestamps of speech in audio using NeMo’s CTC-based Automatic Speech Recognition models.
Speech Data Processor (SDP), a toolkit for simplifying speech data processing. It allows you to represent data processing operations in a config file, minimizing boilerplate code, and allowing reproducibility and shareability.
Speech Data Explorer (SDE), a Dash-based web application for interactive exploration and analysis of speech datasets.
Dataset creation tool which provides functionality to align long audio files with the corresponding transcripts and split them into shorter fragments that are suitable for Automatic Speech Recognition (ASR) model training.
Comparison Tool for ASR Models to compare predictions of different ASR models at word accuracy and utterance level.
ASR Evaluator for evaluating the performance of ASR models and other features such as Voice Activity Detection.
Text Normalization Tool for converting text from the written form to the spoken form and vice versa (e.g. “31st” vs “thirty first”).
- Path to Deployment
NeMo models that have been trained or customized using the NeMo Framework can be optimized and deployed with NVIDIA Riva. Riva provides containers and Helm charts specifically designed to automate the steps for push-button deployment.
Getting Started with Speech AI
Other Resources#
GitHub Repos#
NVIDIA-NeMo: The main repository for the NeMo Framework
Getting Help#
Engage with the NeMo community, ask questions, get support, or report bugs.
Programming Languages and Frameworks#
Python: The main interface to use NeMo Framework
Pytorch: NeMo Framework is built on top of PyTorch
Licenses#
NeMo Github repo is licensed under the Apache 2.0 license
NeMo Framework is licensed under the NVIDIA AI PRODUCT AGREEMENT. By pulling and using the container, you accept the terms and conditions of this license.
The NeMo Framework container contains Llama materials governed by the Meta Llama3 Community License Agreement.