Models#
Examples of config files for all the below models can be found in the <NeMo_git_root>/examples/speaker_recognition/conf directory.
For more information about the config files and how they should be structured, see the NeMo Speaker Recognition Configuration Files page.
Pretrained checkpoints for all of these models, as well as instructions on how to load them, can be found on the Checkpoints page. You can use the available checkpoints for immediate inference, or fine-tune them on your own datasets. The Checkpoints page also contains benchmark results for the available speaker recognition models.
TitaNet#
TitaNet model [SR-MODELS4] is based on the ContextNet architecture [SR-MODELS2] for extracting speaker representations. We employ 1D depth-wise separable convolutions with Squeeze-and-Excitation (SE) layers with global context followed by channel attention based statistics pooling layer to map variable-length utterances to a fixed-length embedding (tvector). TitaNet is a scalable architecture and achieves state-of-the-art performance on speaker verification and diarization tasks.
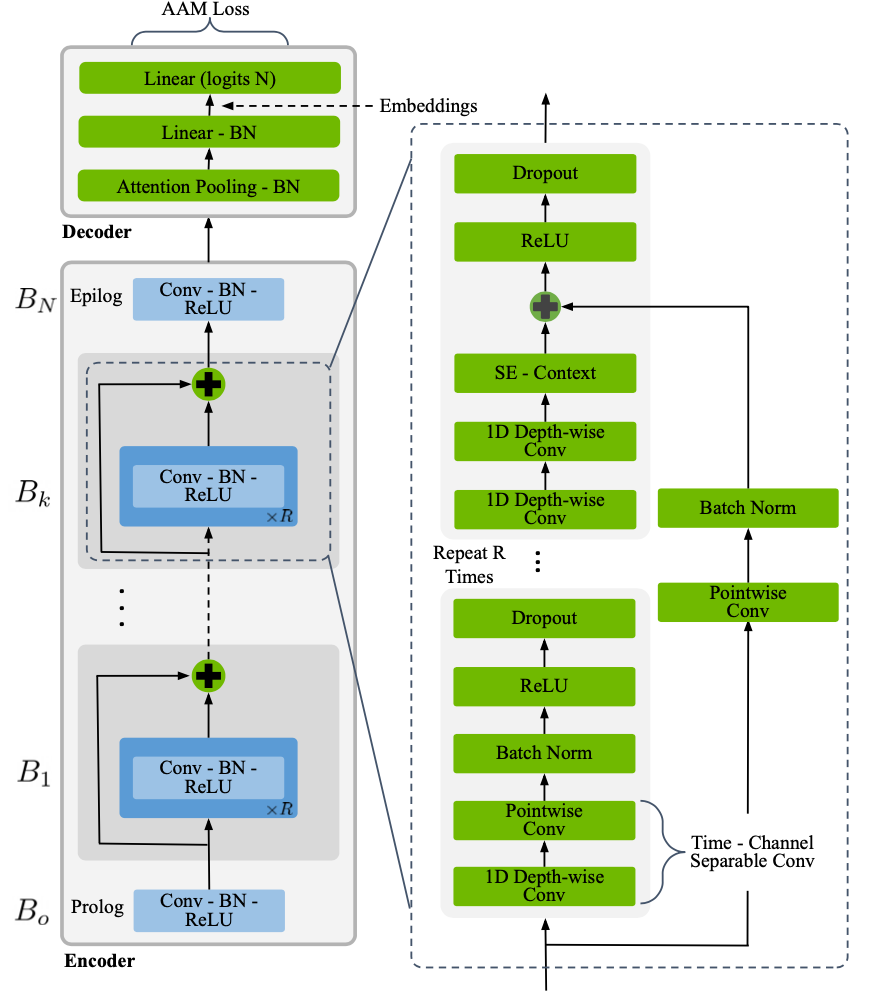
SpeakerNet models can be instantiated using the EncDecSpeakerLabelModel class.
SpeakerNet#
The model is based on the QuartzNet ASR architecture [SR-MODELS3] comprising of an encoder and decoder structure. We use the encoder of the QuartzNet model as a top-level feature extractor, and feed the output to the statistics pooling layer, where we compute the mean and variance across channel dimensions to capture the time-independent utterance-level speaker features.
The QuartzNet encoder used for speaker embeddings shown in figure below has the following structure: a QuartzNet BxR model has B blocks, each with R sub-blocks. Each sub-block applies the following operations: a 1D convolution, batch norm, ReLU, and dropout. All sub-blocks in a block have the same number of output channels. These blocks are connected with residual connections. We use QuartzNet with 3 blocks, 2 sub-blocks, and 512 channels, as the Encoder for Speaker Embeddings. All conv layers have stride 1 and dilation 1.
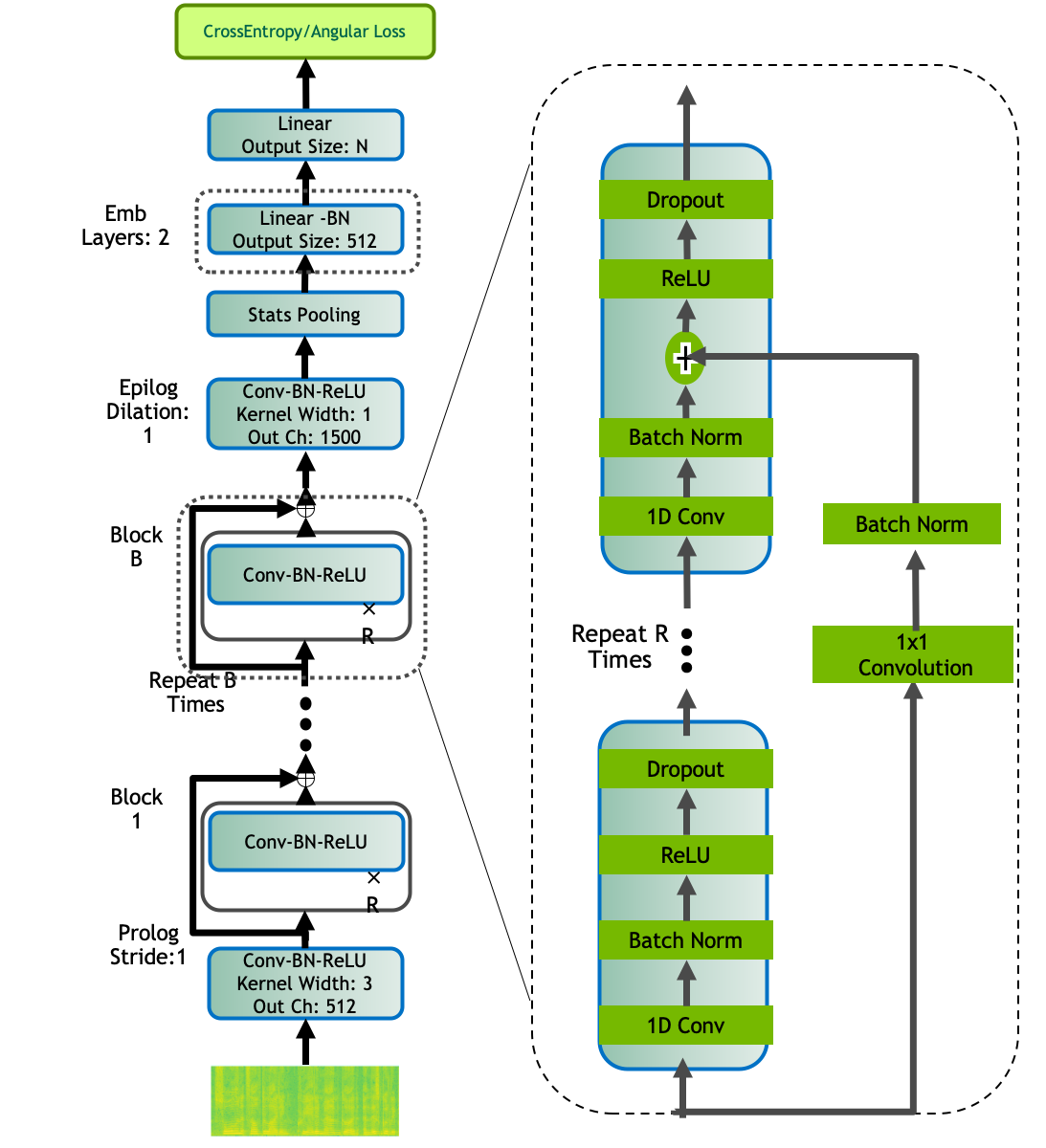
Top level acoustic Features, obtained from the output of encoder are used to compute intermediate features that are then passed to the decoder for getting utterance level speaker embeddings. The intermediate time-independent features are computed using a statistics pooling layer, where we compute the mean and standard deviation of features across time-channels, to get a time-independent feature representation S of size Batch_size × 3000. The intermediate features, S are passed through the Decoder consisting of two layers each of output size 512 for a linear transformation from S to the final number of classes N for the larger (L) model, and a single linear layer of output size 256 to the final number of classes N for the medium (M) model. We extract q-vectors after the final linear layer of fixed size 512, 256 for SpeakerNet-L and SpeakerNet-M models respectively.
SpeakerNet models can be instantiated using the EncDecSpeakerLabelModel class.
ECAPA_TDNN#
The model is based on the paper “ECAPA_TDNN Embeddings for Speaker Diarization” [SR-MODELS1] comprising an encoder of time dilation layers which are based on Emphasized Channel Attention, Propagation, and Aggregation. The ECAPA-TDNN model employs a channel and context dependent attention mechanism, Multi layer Feature Aggregation (MFA), as well as Squeeze-Excitation (SE) and residual blocks, due to faster training and inference we replacing residual blocks with group convolution blocks of single dilation. These models has shown good performance over various speaker tasks.
ecapa_tdnn models can be instantiated using the EncDecSpeakerLabelModel class.
References#
Nauman Dawalatabad, Mirco Ravanelli, François Grondin, Jenthe Thienpondt, Brecht Desplanques, and Hwidong Na. Ecapa-tdnn embeddings for speaker diarization. Interspeech 2021, Aug 2021. URL: http://dx.doi.org/10.21437/Interspeech.2021-941, doi:10.21437/interspeech.2021-941.
Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu. Contextnet: improving convolutional neural networks for automatic speech recognition with global context. arXiv:2005.03191, 2020.
Nithin Rao Koluguri, Jason Li, Vitaly Lavrukhin, and Boris Ginsburg. Speakernet: 1d depth-wise separable convolutional network for text-independent speaker recognition and verification. arXiv preprint arXiv:2010.12653, 2020.
Nithin Rao Koluguri, Taejin Park, and Boris Ginsburg. Titanet: neural model for speaker representation with 1d depth-wise separable convolutions and global context. arXiv preprint arXiv:2110.04410, 2021.