Parameter-Efficient Fine-Tuning (PEFT)#
This guide explains how to configure and use PEFT in Megatron Bridge—covering LoRA and DoRA, required checkpoints, example configurations, and the internal design and training workflow—so you can integrate, scale, and checkpoint adapters efficiently.
Model Customization#
Customizing models enables you to adapt a general pre-trained model to a specific use case or domain. This process produces a fine-tuned model that retains the broad knowledge from pretraining while delivering more accurate outputs for targeted downstream tasks.
Model customization is typically achieved through supervised fine-tuning, which falls into two main approaches: Full-Parameter Fine-Tuning, known as Supervised Fine-Tuning (SFT), and Parameter-Efficient Fine-Tuning (PEFT).
In SFT, all model parameters are updated to align the model’s outputs with the task-specific requirements. This approach often yields the highest performance but can be computationally intensive.
PEFT, by contrast, updates only a small subset of parameters that are inserted into the base model at strategic locations. The base model weights remain frozen, and only the adapter modules are trained. This significantly reduces the number of trainable parameters—often to less than 1%—while still achieving near-SFT levels of accuracy.
As language models continue to grow in size, PEFT is gaining popularity for its efficiency and minimal hardware demands, making it a practical choice for many real-world applications.
PEFT Configuration#
PEFT is configured as an optional attribute in ConfigContainer:
from megatron.bridge.training.config import ConfigContainer
from megatron.bridge.peft.lora import LoRA
config = ConfigContainer(
# ... other required configurations
peft=LoRA(
target_modules=["linear_qkv", "linear_proj", "linear_fc1", "linear_fc2"],
dim=16,
alpha=32,
dropout=0.1,
),
checkpoint=CheckpointConfig(
pretrained_checkpoint="/path/to/pretrained/checkpoint", # Required for PEFT
save="/path/to/peft/checkpoints",
),
)
Note
Requirements: PEFT requires checkpoint.pretrained_checkpoint to be set to load the base model weights.
Supported PEFT Methods#
LoRA: Low-Rank Adaptation of Large Language Models#
LoRA makes fine-tuning efficient by representing weight updates with two low-rank decomposition matrices. The original model weights remain frozen, while the low-rank decomposition matrices are updated to adapt to the new data, keeping the number of trainable parameters low. In contrast with adapters, the original model weights and adapted weights can be combined during inference, avoiding any architectural change or additional latency in the model at inference time.
In Megatron Bridge, you can configure both the adapter bottleneck dimension and the target modules where LoRA is applied. LoRA supports any linear layer, which in transformer models typically includes:
Query, key, and value (QKV) attention projections
The attention output projection
One or both MLP layers
Megatron Bridge fuses the QKV projections into a single linear layer. As a result, LoRA learns a unified low-rank adaptation for the combined QKV representation.
from megatron.bridge.peft.lora import LoRA
lora_config = LoRA(
target_modules=["linear_qkv", "linear_proj", "linear_fc1", "linear_fc2"],
dim=16, # Rank of adaptation
alpha=32, # Scaling parameter
dropout=0.1, # Dropout rate
)
Key Parameters#
The following table lists key hyperparameters for configuring DoRA, which control its module targeting, adaptation rank, scaling behavior, and regularization strategy.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
|
All linear layers |
Modules to apply DoRA to |
|
|
|
Rank of the low-rank adaptation |
|
|
|
Scaling parameter for DoRA |
|
|
|
Dropout rate for DoRA layers |
Target Modules#
The following table lists specific submodules within transformer architectures that are commonly targeted for LoRA, enabling efficient fine-tuning of attention and feedforward components:
Module |
Description |
|---|---|
|
Query, key, value projections in attention |
|
Attention output projection |
|
First MLP layer |
|
Second MLP layer |
Wildcard Target Modules#
For more granular targeting, individual layers can be targeted for the adapters.
# Target specific layers only
lora_config = LoRA(
target_modules=[
"*.layers.0.*.linear_qkv", # First layer only
"*.layers.1.*.linear_qkv", # Second layer only
]
)
Canonical LoRA: Performant vs Canonical Variants#
There are two variants of LoRA implemented in Megatron Bridge: “performant LoRA” (LoRA) and “canonical LoRA” (CanonicalLoRA).
The distinction comes from the fact that Megatron Core optimizes the implementation of the following two linear modules by fusing multiple linear layers into one layer. When these layers are adapted with LoRA, the performant version also uses only one adapter for the linear module. The two linear modules are:
linear_qkv: The projection matrix in self attention that transforms hidden state to query, key and value. Megatron Core fuses these three projection matrices into a single matrix to efficiently parallelize the matrix multiplication. Hence, performant LoRA applies a single adapter to the qkv projection matrix, whereas canonical LoRA applies three adapters.linear_fc1: The first linear layer in the MLP module before the intermediate activation. For gated linear activations, Megatron Core fuses the up and gate projection matrices into a single matrix for efficient parallelization. Hence, performant LoRA applies a single adapter to the up and gate projection matrices, whereas canonical LoRA applies two adapters.
The following two figures illustrate the difference between canonical and performant LoRA, using the linear_qkv layer as an example. Canonical LoRA runs three adapters sequentially, while performant LoRA runs one adapter.
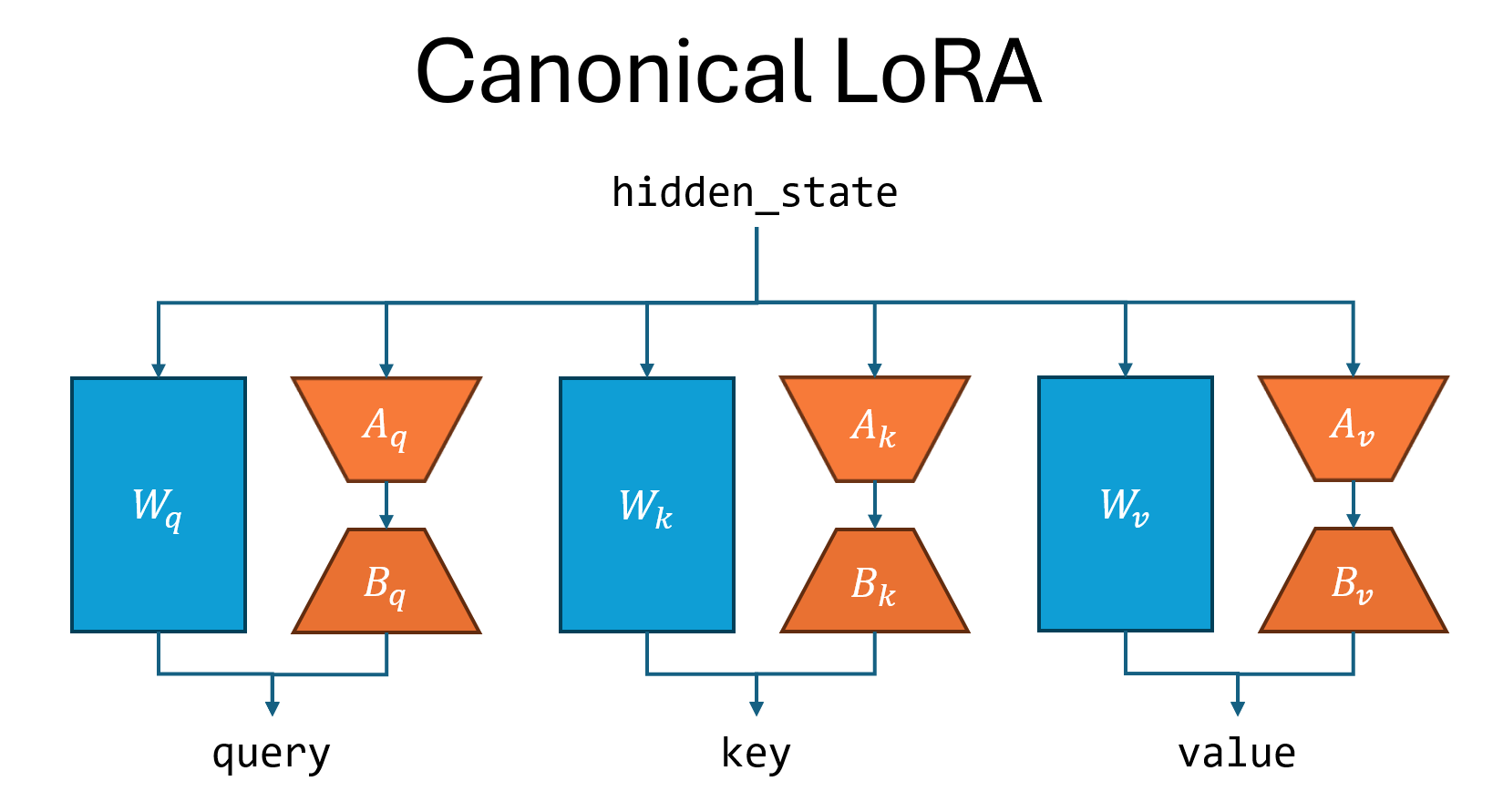
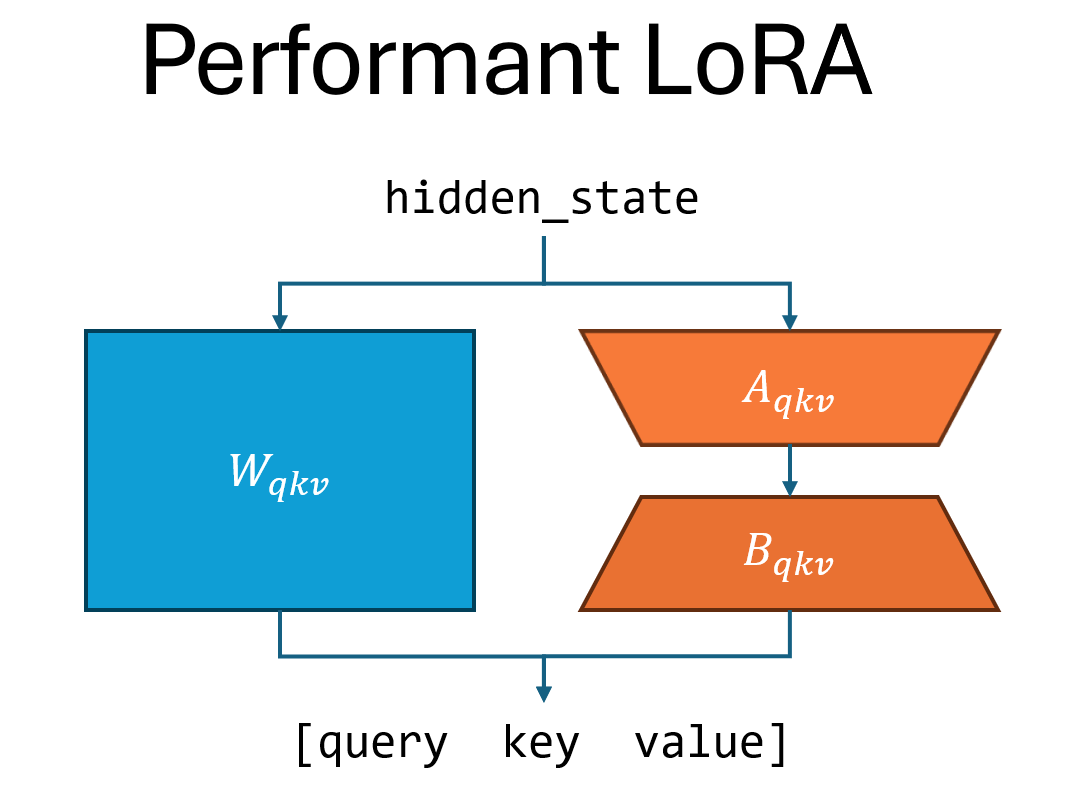
Canonical LoRA conforms more closely to reference implementations, though it is slower in comparison since it performs several matrix multiplications sequentially, as described above. Performant LoRA has fewer parameters than canonical LoRA and can often achieve the same level of accuracy as canonical LoRA.
Though not immediately apparent, performant LoRA is mathematically equivalent to canonical LoRA when the \(A_q\), \(A_k\), \(A_v\) matrices are tied (i.e. forced to share the same weight during training) in linear_qkv, and similarly when the \(A_{up}\), \(A_{gate}\) matrices are tied in linear_fc1.
Mathematical Proof: Performant LoRA Equivalence to Canonical LoRA with Tied Weights
Let \([x \quad y]\) denote matrix concatenation. (In Megatron Bridge, this concatenation is done in an interleaved fashion, but this does not affect the proof below.)
Let \(A_q = A_k = A_v = A_{qkv}\) (weight tying)
Then
Note: dimensions of weight matrices are as follows:
Where:
\(n_q\): Number of attention heads (
num_attention_heads).\(n_{kv}\): Number of key value heads (
num_query_groups). Note that if grouped query attention (GQA) is not used, \(n_{kv} = n_q\).\(h\): Transformer hidden size (
hidden_size).\(d\): Transformer head dimension (
kv_channels).\(r\): LoRA rank.
Using Canonical LoRA#
from megatron.bridge.peft.canonical_lora import CanonicalLoRA
canonical_lora_config = CanonicalLoRA(
target_modules=[
"linear_q", "linear_k", "linear_v", # Individual Q, K, V projections
"linear_proj", # Attention output projection
"linear_fc1_up", "linear_fc1_gate", # Individual up and gate projections
"linear_fc2" # Second MLP layer
],
dim=16, # Rank of adaptation
alpha=32, # Scaling parameter
dropout=0.1, # Dropout rate
)
Key Parameters#
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
|
All canonical linear layers |
Modules to apply canonical LoRA to |
|
|
|
Rank of the low-rank adaptation |
|
|
|
Scaling parameter for LoRA |
|
|
|
Dropout rate for LoRA layers |
|
|
|
Position for applying dropout |
|
|
|
Initialization method for LoRA A matrix |
|
|
|
Initialization method for LoRA B matrix |
Target Modules for Canonical LoRA#
The following table lists specific submodules within transformer architectures that are targeted for canonical LoRA:
Module |
Description |
|---|---|
|
Query projection in attention |
|
Key projection in attention |
|
Value projection in attention |
|
Attention output projection |
|
Up projection in MLP |
|
Gate projection in MLP |
|
Second MLP layer |
Note
Canonical LoRA does not support linear_qkv or linear_fc1 targets. Use the individual component targets (linear_q, linear_k, linear_v for QKV and linear_fc1_up, linear_fc1_gate for FC1) instead.
DoRA: Weight-Decomposed Low-Rank Adaptation#
DoRA decomposes the pre-trained weight into magnitude and direction. It learns a separate magnitude parameter while employing LoRA for directional updates, efficiently minimizing the number of trainable parameters. DoRA enhances both the learning capacity and training stability of LoRA, while avoiding any additional inference overhead. DoRA has been shown to consistently outperform LoRA on various downstream tasks.
In Megatron Bridge, DoRA leverages the same adapter structure as LoRA. Megatron Bridge adds support for Tensor Parallelism and Pipeline Parallelism for DoRA, enabling DoRA to be scaled to larger model variants.
from megatron.bridge.peft.dora import DoRA
dora_config = DoRA(
target_modules=["linear_qkv", "linear_proj", "linear_fc1", "linear_fc2"],
dim=16, # Rank of adaptation
alpha=32, # Scaling parameter
dropout=0.1, # Dropout rate
)
Key Parameters#
The following parameters define how LoRA is applied to your model. They control which modules are targeted, the adaptation rank, scaling behavior, and dropout configuration:
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
|
All linear layers |
Modules to apply DoRA to |
|
|
|
Rank of the low-rank adaptation |
|
|
|
Scaling parameter for DoRA |
|
|
|
Dropout rate for DoRA layers |
Full Configuration Example#
from megatron.bridge.training.config import (
ConfigContainer, TrainingConfig, CheckpointConfig
)
from megatron.bridge.data.builders.hf_dataset import HFDatasetConfig
from megatron.bridge.data.hf_processors.squad import process_squad_example
from megatron.bridge.peft.lora import LoRA
from megatron.core.optimizer import OptimizerConfig
# Configure PEFT fine-tuning
config = ConfigContainer(
model=model_provider,
train=TrainingConfig(
train_iters=1000,
global_batch_size=64,
micro_batch_size=1, # Required for packed sequences if used
eval_interval=100,
),
optimizer=OptimizerConfig(
optimizer="adam",
lr=1e-4, # Lower learning rate for fine-tuning
weight_decay=0.01,
bf16=True,
use_distributed_optimizer=True,
),
scheduler=SchedulerConfig(
lr_decay_style="cosine",
lr_warmup_iters=100,
lr_decay_iters=1000,
),
dataset=HFDatasetConfig(
dataset_name="squad",
process_example_fn=process_squad_example,
seq_length=512,
),
checkpoint=CheckpointConfig(
pretrained_checkpoint="/path/to/pretrained/model", # Required
save="/path/to/peft/checkpoints",
save_interval=200,
),
peft=LoRA(
target_modules=["linear_qkv", "linear_proj", "linear_fc1", "linear_fc2"],
dim=16,
alpha=32,
dropout=0.1,
),
# ... other configurations
)
PEFT Design in Megatron Bridge#
This section describes the internal design and architecture for how PEFT is integrated into Megatron Bridge.
Architecture Overview#
The PEFT framework introduces a modular design for integrating adapters into large-scale models. Its architecture consists of the following components:
Base PEFT Class: All PEFT methods inherit from the abstract
bridge.peft.base.PEFTbase class, which defines the core interface for module transformation.Module Transformation: PEFT traverses the model structure to identify and transform target modules individually.
Adapter Integration: Adapters are injected into selected modules using a pre-wrap hook during model initialization.
Checkpoint Integration: Only adapter parameters are saved and loaded during checkpointing; base model weights remain frozen and unchanged.
PEFT Workflow in Training#
The training workflow for PEFT follows a structured sequence that ensures efficient fine-tuning with minimal overhead:
Model Loading: The base model is initialized from a specified pretrained checkpoint.
PEFT Application: Adapter transformations are applied after Megatron Core model initialization, but before distributed wrapping.
Parameter Freezing: Base model parameters are frozen to reduce training complexity; only adapter parameters are updated.
Adapter Weight Loading: When resuming training, adapter weights are restored from the checkpoint.
Checkpoint Saving: Only adapter states are saved, resulting in significantly smaller checkpoint files.
Key Benefits#
PEFT offers several advantages for scalable and efficient model fine-tuning:
Reduced Checkpoint Size: Adapter-only checkpoints are dramatically smaller than full model checkpoints.
Memory Efficiency: Since gradients are computed only for adapter parameters, memory usage is significantly reduced.
Resume Support: Training can be resumed seamlessly using adapter-only checkpoints, without reloading full model weights.