Speaker Diarization#
Speaker Diarization Overview#
Speaker diarization is the process of segmenting audio recordings by speaker labels and aims to answer the question “who spoke when?”. Speaker diarization makes a clear distinction when it is compared with speech recognition. As shown in the figure below, before we perform speaker diarization, we know “what is spoken” yet we do not know “who spoke it”. Therefore, speaker diarization is an essential feature for a speech recognition system to enrich the transcription with speaker labels.
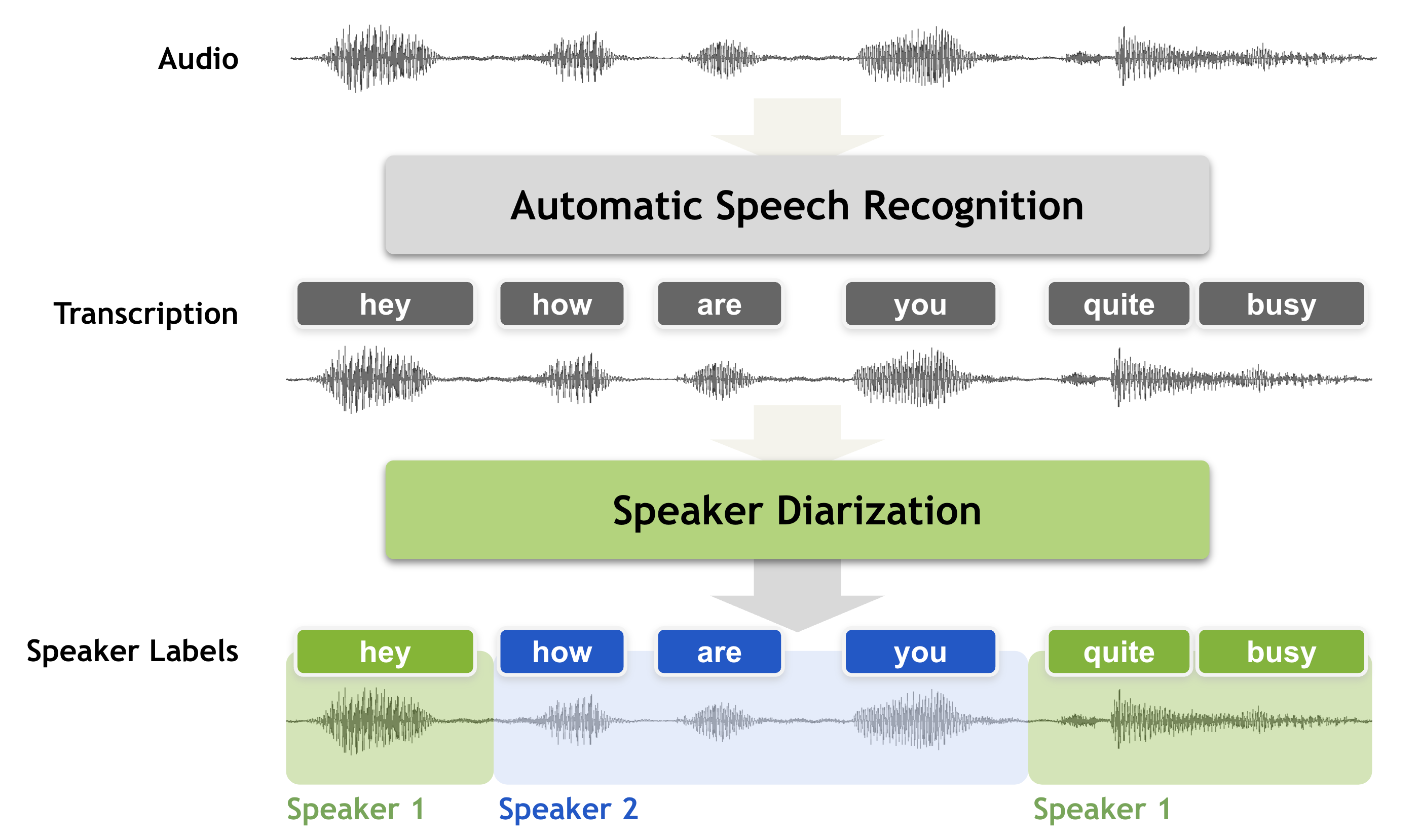
To figure out “who spoke when”, speaker diarization systems need to capture the characteristics of unseen speakers and tell apart which regions in the audio recording belong to which speaker. To achieve this, speaker diarization systems extract voice characteristics, count the number of speakers, then assign the audio segments to the corresponding speaker index.
Types of Speaker Diarization Systems#
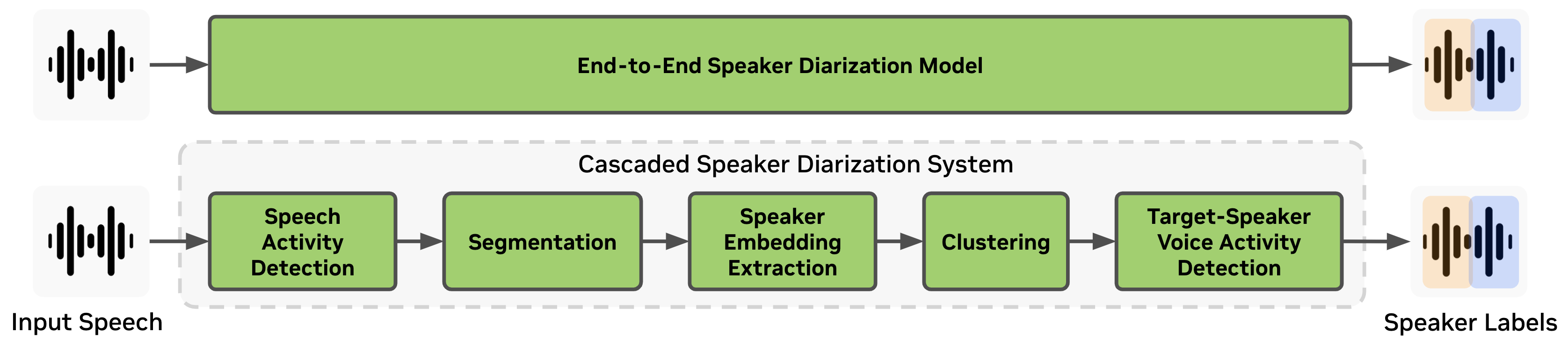
End-to-End Speaker Diarization System:
End-to-end speaker diarization systems pursue a much more simplified version of a system where a single neural network model accepts raw audio signals and outputs speaker activity for each audio frame. Therefore, end-to-end diarization models have an advantage in ease of optimization and depoloyments.
Curently, NeMo Speech AI provides the following end-to-end speaker diarization models:
Sortformer Diarizer : A transformer-based model that estimates speaker labels from the given audio input giving the speaker indexes in arrival-time order.
Cascaded Speaker Diarization System:
Traditional cascaded (also referred to as modular or pipelined) speaker diarization systems consist of multiple modules such as a speaker activity detection (SAD) module and a speaker embedding extractor module. On top of the clustering diarizer, target-speaker voice activity detection (VAD) is performed to generate the final speaker labels. Cascaded speaker diarization systems are more challenging to optimize all together and deploy but still has advantage of having less restriction on the number of speakers and session length.
Cascaded NeMo Speech AI speaker diarization system consists of the following modules:
Voice Activity Detector (VAD): A trainable model which detects the presence or absence of speech to generate timestamps for speech activity from the given audio recording.
Speaker Embedding Extractor: A trainable model that extracts speaker embedding vectors containing voice characteristics from raw audio signal.
Clustering Module: A non-trainable module that groups speaker embedding vectors into a number of clusters.
Neural Diarizer (TS-VAD): A trainable model that estimates speaker labels from the given features. In general, this module is performing target-speaker VAD task to generate the final speaker labels.
The full documentation tree is as follows:
- Models
- Datasets
- Checkpoints
- End-to-end Speaker Diarization Models
- Models for Cascaded Speaker Diarization Pipeline
- End-to-End Speaker Diarization Configuration Files
- Cascaded Speaker Diarization Configuration Files
- Hydra Configurations for Diarization Inference
- NeMo Speaker Diarization API
- Resource and Documentation Guide
Resource and Documentation Guide#
Hands-on speaker diarization tutorial notebooks for both end-to-end and cascaded systems can be found under <NeMo_root>/tutorials/speaker_tasks.
There are also tutorials for performing both end-to-end speaker diarization cascaded speaker diarization. We also provide tutorials about getting ASR transcriptions combined with speaker labels along with voice activity timestamps with NeMo ASR collections.
Most of the tutorials can be run on Google Colab by specifying the link to the notebooks’ GitHub pages on Colab.
If you are looking for information about a particular model used for speaker diarization inference, or would like to find out more about the model architectures available in the nemo_asr collection, check out the Models page.
Documentation on dataset preprocessing can be found on the Datasets page. NeMo includes preprocessing scripts for several common ASR datasets, and this page contains instructions on running those scripts. It also includes guidance for creating your own NeMo-compatible dataset, if you have your own data.
Information about how to load model checkpoints (either local files or pretrained ones from NGC), perform inference, as well as a list of the checkpoints available on NGC are located on the Checkpoints page.
Documentation for configuration files specific to the nemo_asr models can be found on the
Configuration Files page.