Speech Data Explorer#
Speech Data Explorer (SDE) is a Dash-based web application for interactive exploration and analysis of speech datasets.
SDE Features: |
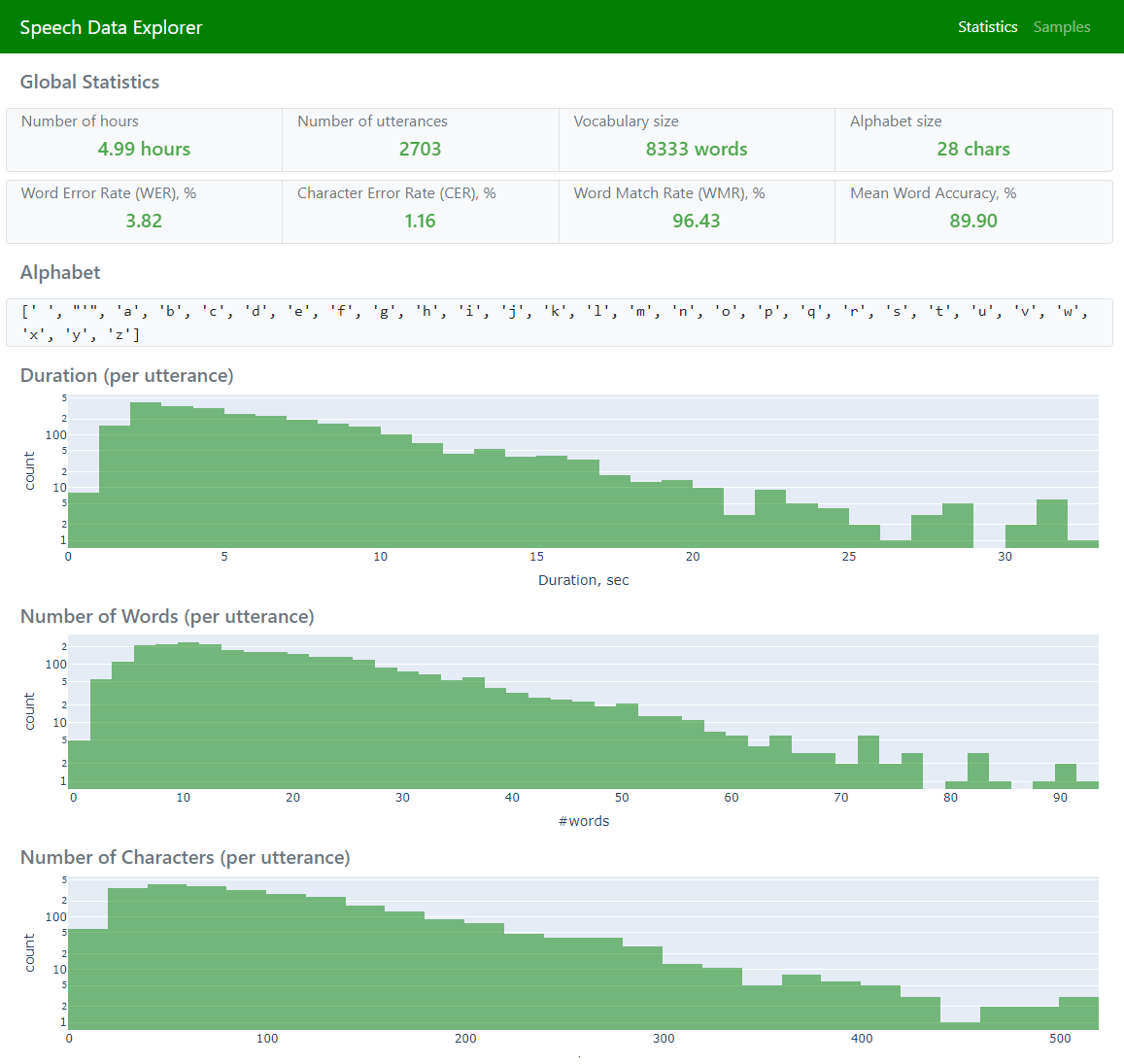
global dataset statistics [alphabet, vocabulary, duration-based histograms, number of hours, number of utterances, etc.] |
navigation across the dataset using an interactive datatable that supports sorting and filtering |
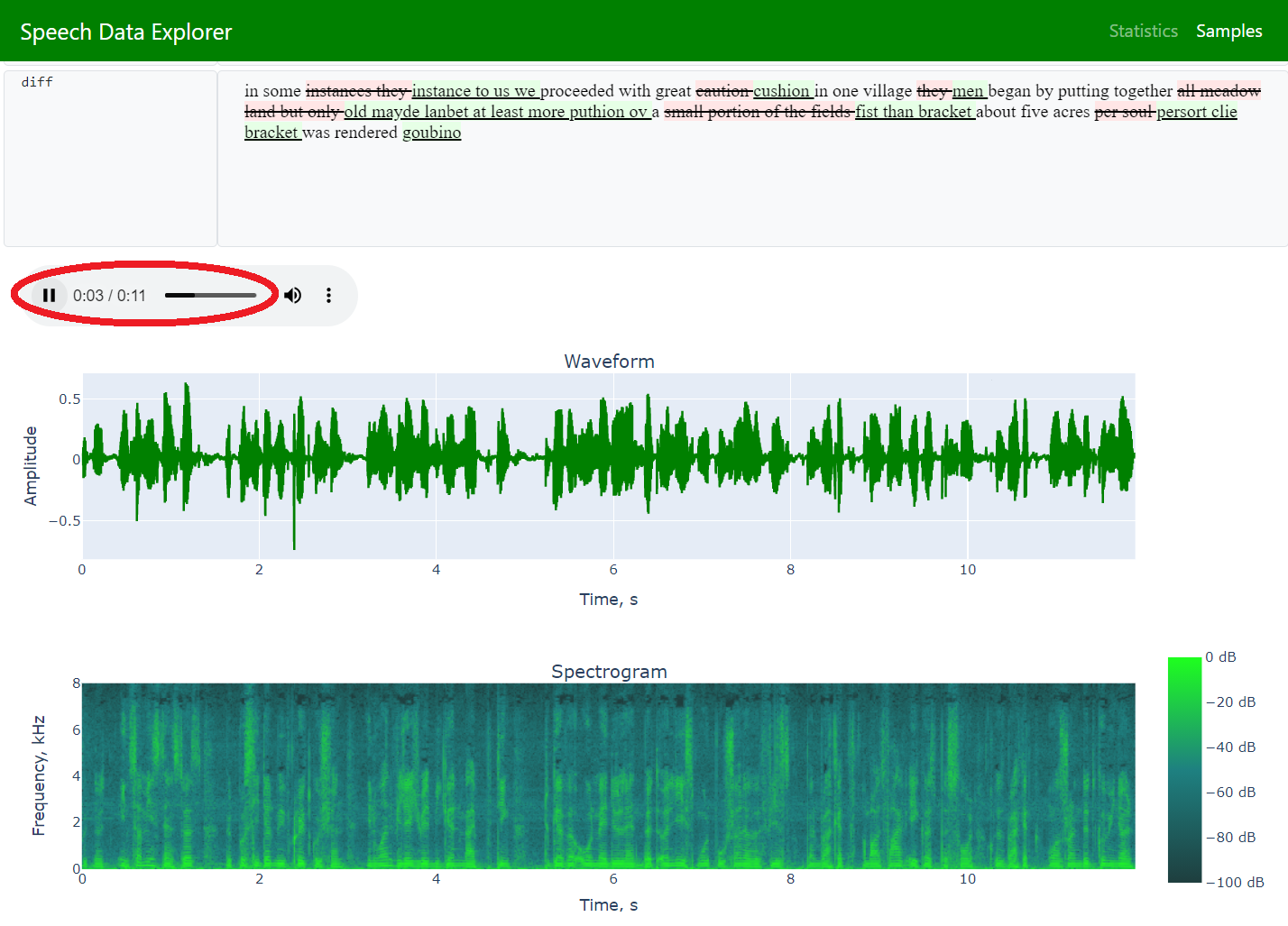
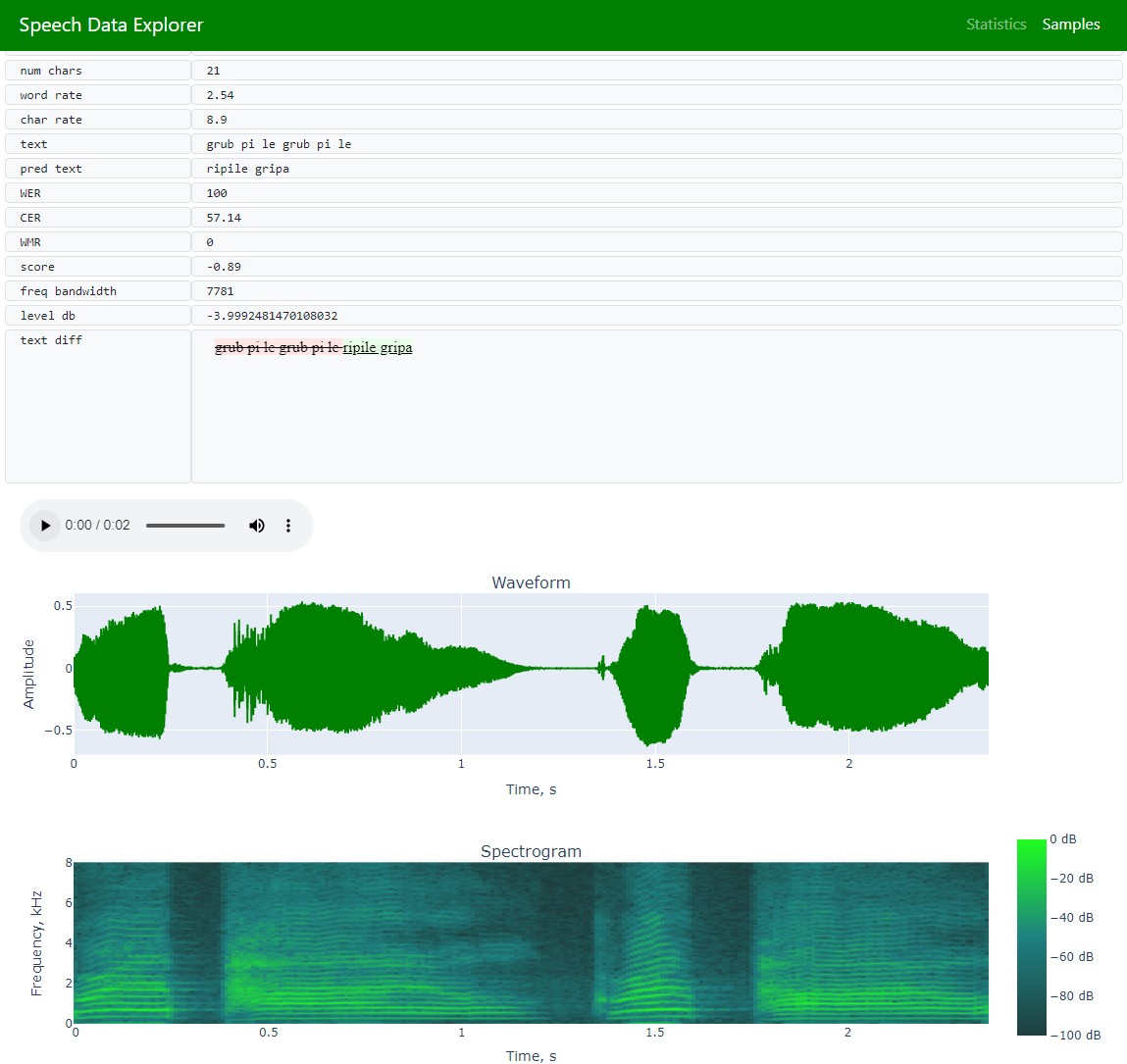
inspection of individual utterances [plotting waveforms, spectrograms, custom attributes, and playing audio] |
error analysis [word error rate (WER), character error rate (CER), word match rate (WMR), word accuracy, display highlighted the difference between the reference text and ASR model prediction] |
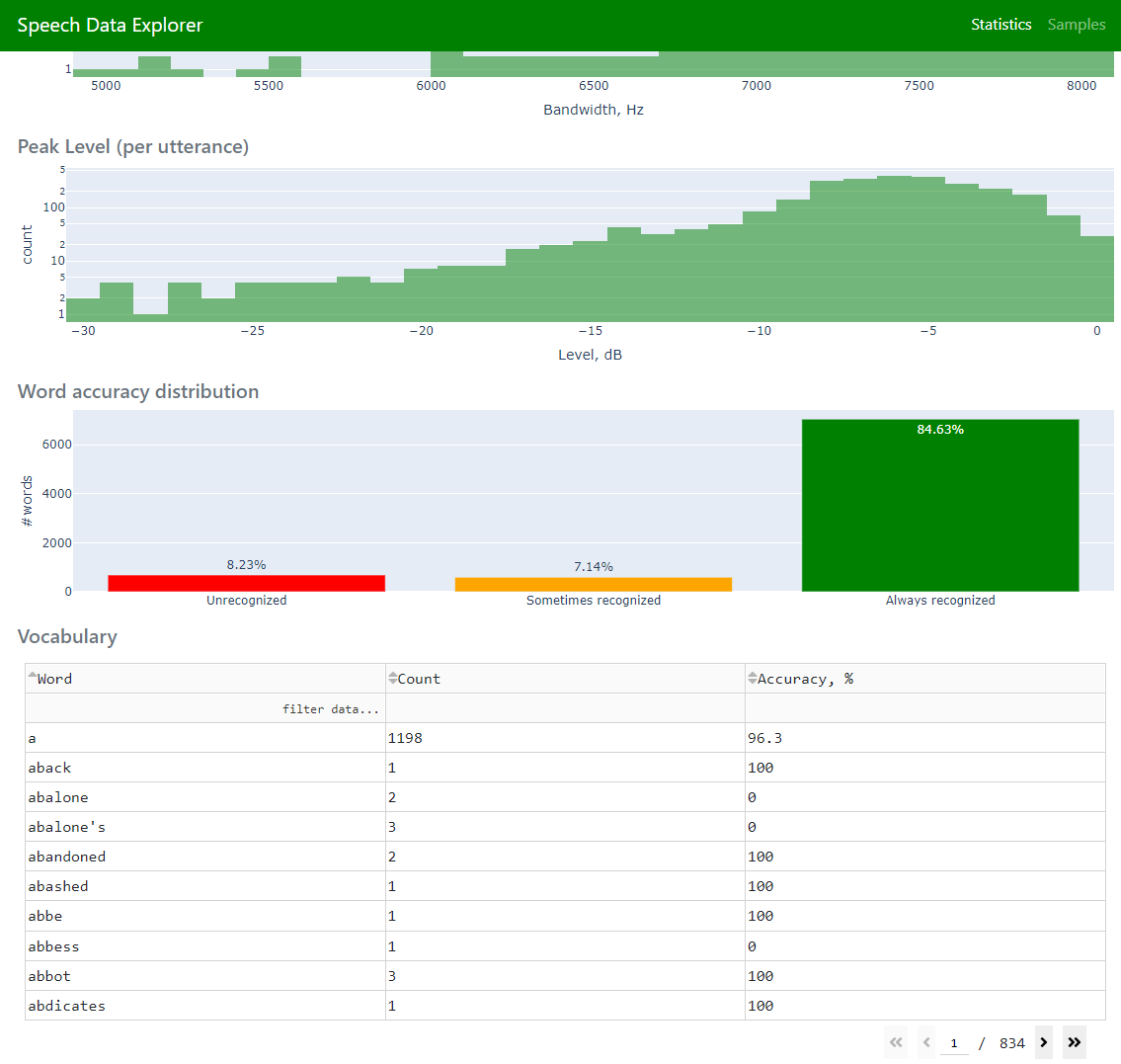
estimation of audio signal parameters [peak level, frequency bandwidth] |
Getting Started#
SDE could be found in NeMo/tools/speech_data_explorer.
Please install the SDE requirements:
pip install -r tools/speech_data_explorer/requirements.txt
Then run:
python tools/speech_data_explorer/data_explorer.py -h
usage: data_explorer.py [-h] [--vocab VOCAB] [--port PORT] [--disable-caching-metrics] [--estimate-audio-metrics] [--debug] manifest
Speech Data Explorer
positional arguments:
manifest path to JSON manifest file
optional arguments:
-h, --help show this help message and exit
--vocab VOCAB optional vocabulary to highlight OOV words
--port PORT serving port for establishing connection
--disable-caching-metrics
disable caching metrics for errors analysis
--estimate-audio-metrics, -a
estimate frequency bandwidth and signal level of audio recordings
--debug, -d enable debug mode
SDE takes as an input a JSON manifest file (that describes speech datasets in NeMo). It should contain the following fields:
audio_filepath (path to audio file)
duration (duration of the audio file in seconds)
text (reference transcript)
SDE supports any extra custom fields in the JSON manifest. If the field is numeric, then SDE can visualize its distribution across utterances.
If the JSON manifest has attribute pred_text, SDE interprets it as a predicted ASR transcript and computes error analysis metrics.
The command line option --estimate-audio-metrics allows SDE to estimate the signal’s peak level and frequency bandwidth for each utterance.
By default, SDE caches all computed metrics to a pickle file. The caching can be disabled with --disable-caching-metrics option.
User Interface#
SDE application has two pages:
Statistics (to display global statistics and aggregated error metrics)
Samples (to allow navigation across the entire dataset and exploration of individual utterances)
Plotly Dash Datatable provides core SDE’s interactive features (navigation, filtering, and sorting). SDE has two datatables:
Vocabulary (that shows all words from dataset’s reference texts on Statistics page)
Data (that visualizes all dataset’s utterances on Samples page)
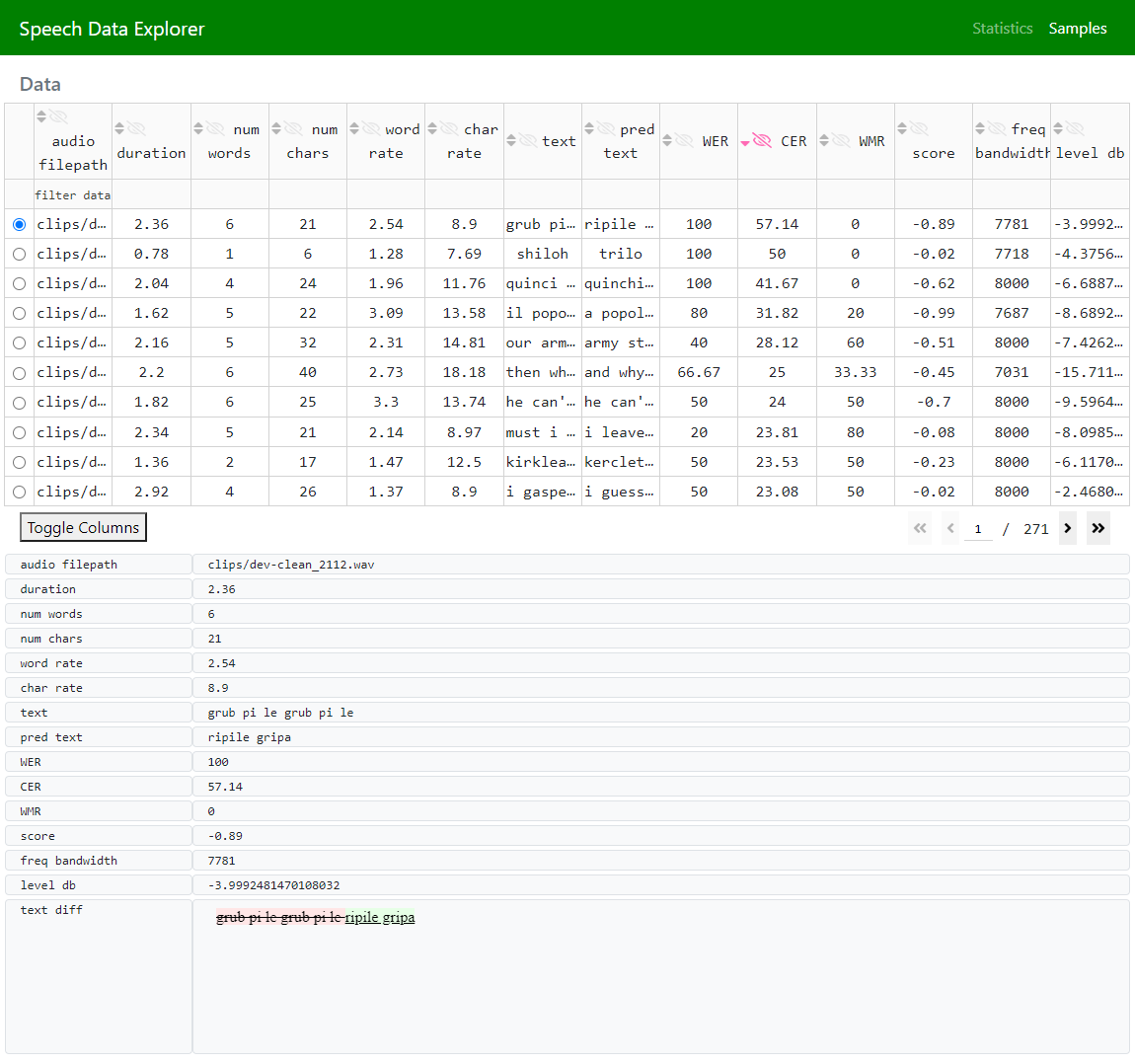
Every column of the DataTable has the following interactive features:
toggling off (by clicking on the eye icon in the column’s header cell) or on (by clicking on the Toggle Columns button below the table)
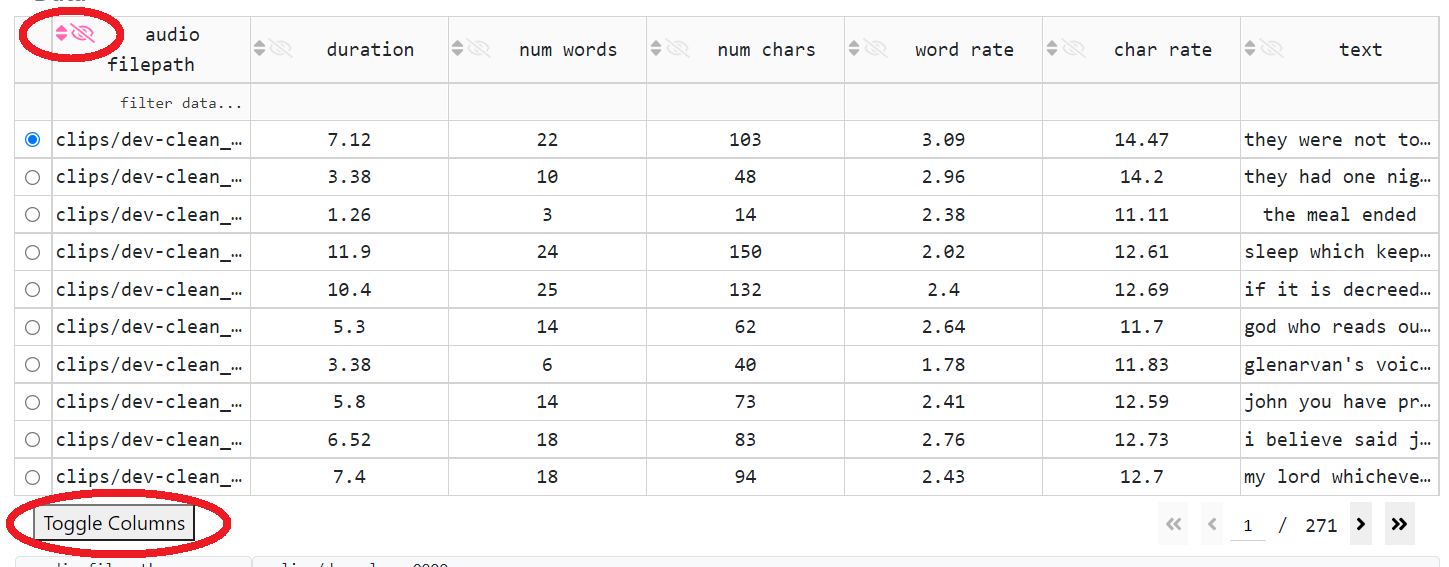
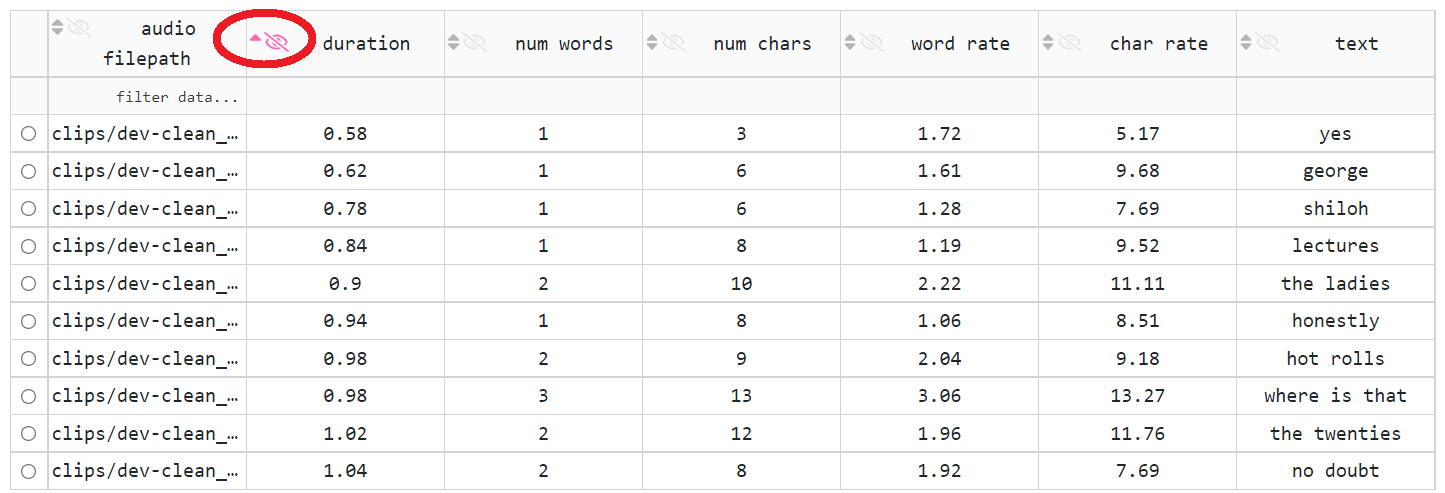
sorting (by clicking on small triangle icons in the column’s header cell): unordered (two triangles point up and down), ascending (a triangle points up), descending (a triangle points down)
filtering (by entering a filtering expression in a cell below the header’s cell): SDE supports
<,>,<=,>=,=,!=, andcontainsoperators; to match a specific substring, the quoted substring can be used as a filtering expression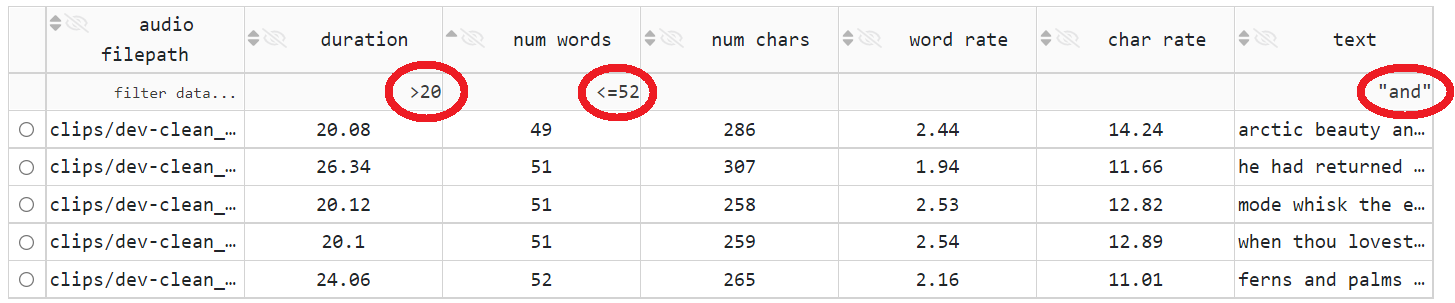
Analysis of Speech Datasets#
In the simplest use case, SDE helps to explore a speech dataset interactively and get basic statistics. If there is no available pre-trained ASR model to get predicted transcripts, there are still available heuristic rules to spot potential issues in a dataset:
Check dataset alphabet (it should contain only target characters)
Check vocabulary for uncommon words (e.g., foreign words, typos). SDE can take an external vocabulary file passed with
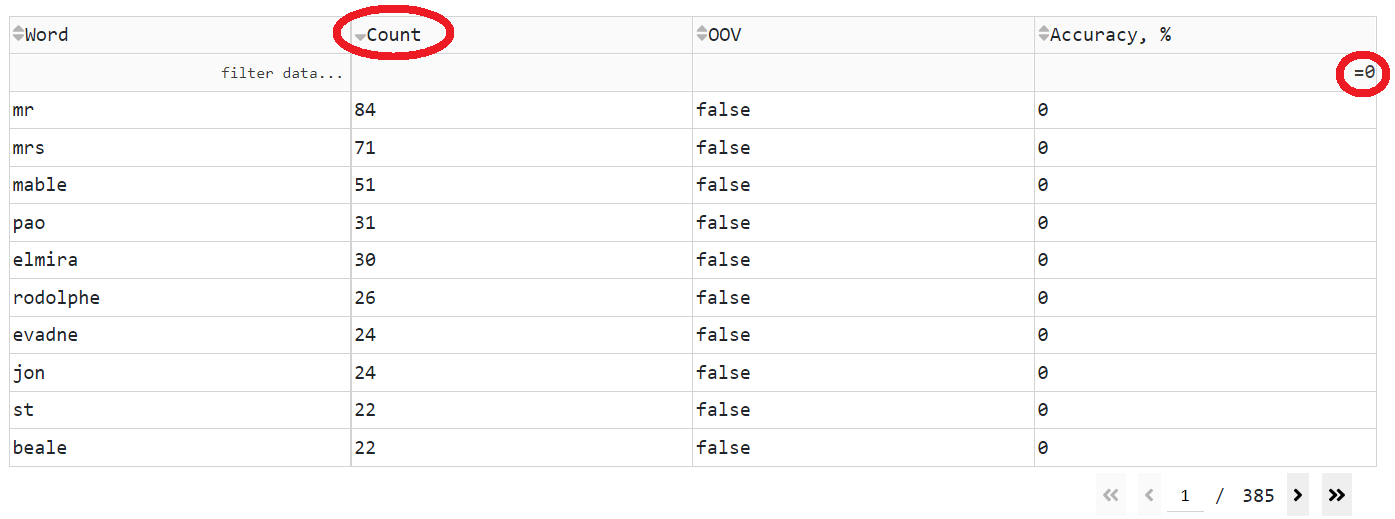
--vocaboption. Then it is easy to filter out-of-vocabulary (OOV) words in the dataset and sort them by their number of occurrences (count).Check utterances with a high character rate. A high character rate might indicate that the utterance has more words in the reference transcript than the corresponding audio recording.
If there is a pre-trained ASR model, then the JSON manifest file can be extended with ASR predicted transcripts:
python examples/asr/transcribe_speech.py pretrained_name=<ASR_MODEL_NAME> dataset_manifest=<JSON_FILENAME>
After that it is worth to check words with zero accuracy.
And then look at high CER utterances.
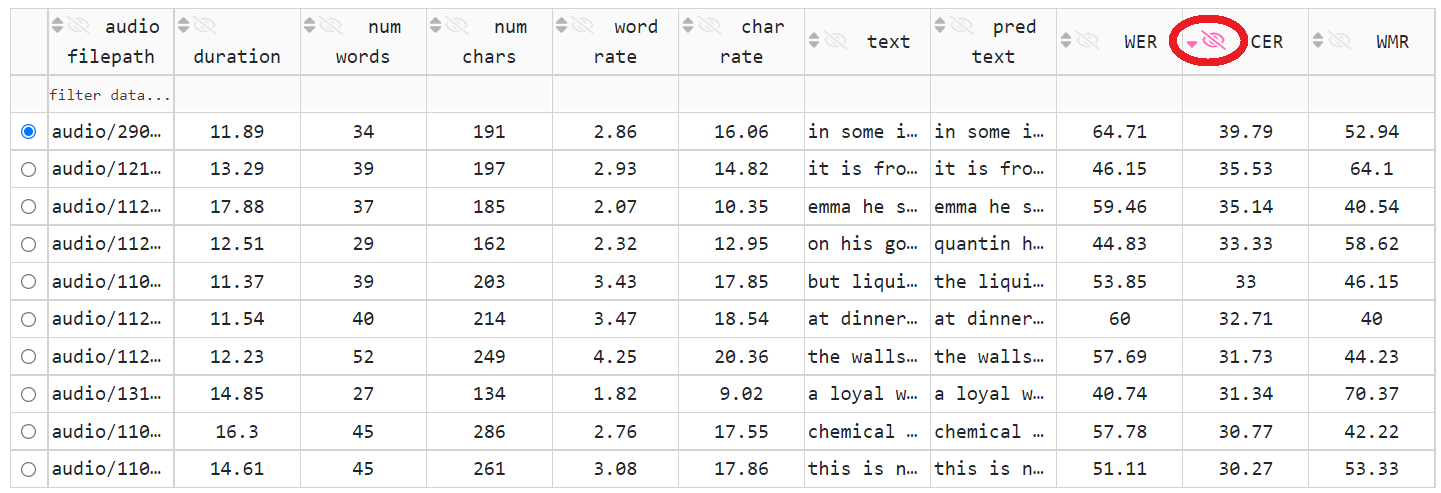
Listening to the audio recording helps to validate the corresponding reference transcript.