Models#
This section gives a brief overview of the models that NeMo’s ASR collection currently supports.
Each of these models can be used with the example ASR scripts (in the <NeMo_git_root>/examples/asr directory) by
specifying the model architecture in the config file used. Examples of config files for each model can be found in
the <NeMo_git_root>/examples/asr/conf directory.
For more information about the config files and how they should be structured, refer to the NeMo ASR Configuration Files section.
Pretrained checkpoints for all of these models, as well as instructions on how to load them, can be found in the Checkpoints section. You can use the available checkpoints for immediate inference, or fine-tune them on your own datasets. The checkpoints section also contains benchmark results for the available ASR models.
Spotlight Models#
Canary#
Canary is the latest family of models from NVIDIA NeMo. Canary models are encoder-decoder models with a FastConformer Encoder and Transformer Decoder [ASR-MODELS10]. They are multi-lingual, multi-task model, supporting automatic speech-to-text recognition (ASR) in 25 EU languages as well as translation between English and the 24 other supported languages.
Models:
Canary-1B V2 model card
Canary-1B Flash model card
Canary-180M Flash model card
Canary-1B model card
Spaces:
Canary models support the following decoding methods for chunked and streaming inference:
Parakeet#
Parakeet is the name of a family of ASR models with a FastConformer Encoder and a CTC, RNN-T, or TDT decoder.
Model checkpoints:
Parakeet-TDT-0.6B V2 model card
this model sits top of the HuggingFace OpenASR Leaderboard at time of writing (May 2nd 2025)
Parakeet-CTC-0.6B and Parakeet-CTC-1.1B model cards
Parakeet-RNNT-0.6B and Parakeet-RNNT-1.1B model cards
Parakeet-TDT-1.1B model card
HuggingFace Spaces to try out Parakeet models in your browser:
Parakeet-TDT-0.6B V2 space
Conformer#
Conformer-CTC#
Conformer-CTC is a CTC-based variant of the Conformer model introduced in [ASR-MODELS1]. Conformer-CTC has a similar encoder as the original Conformer but uses CTC loss and decoding instead of RNNT/Transducer loss, which makes it a non-autoregressive model. We also drop the LSTM decoder and instead use a linear decoder on the top of the encoder. This model uses the combination of self-attention and convolution modules to achieve the best of the two approaches, the self-attention layers can learn the global interaction while the convolutions efficiently capture the local correlations. The self-attention modules support both regular self-attention with absolute positional encoding, and also Transformer-XL’s self-attention with relative positional encodings.
Here is the overall architecture of the encoder of Conformer-CTC:
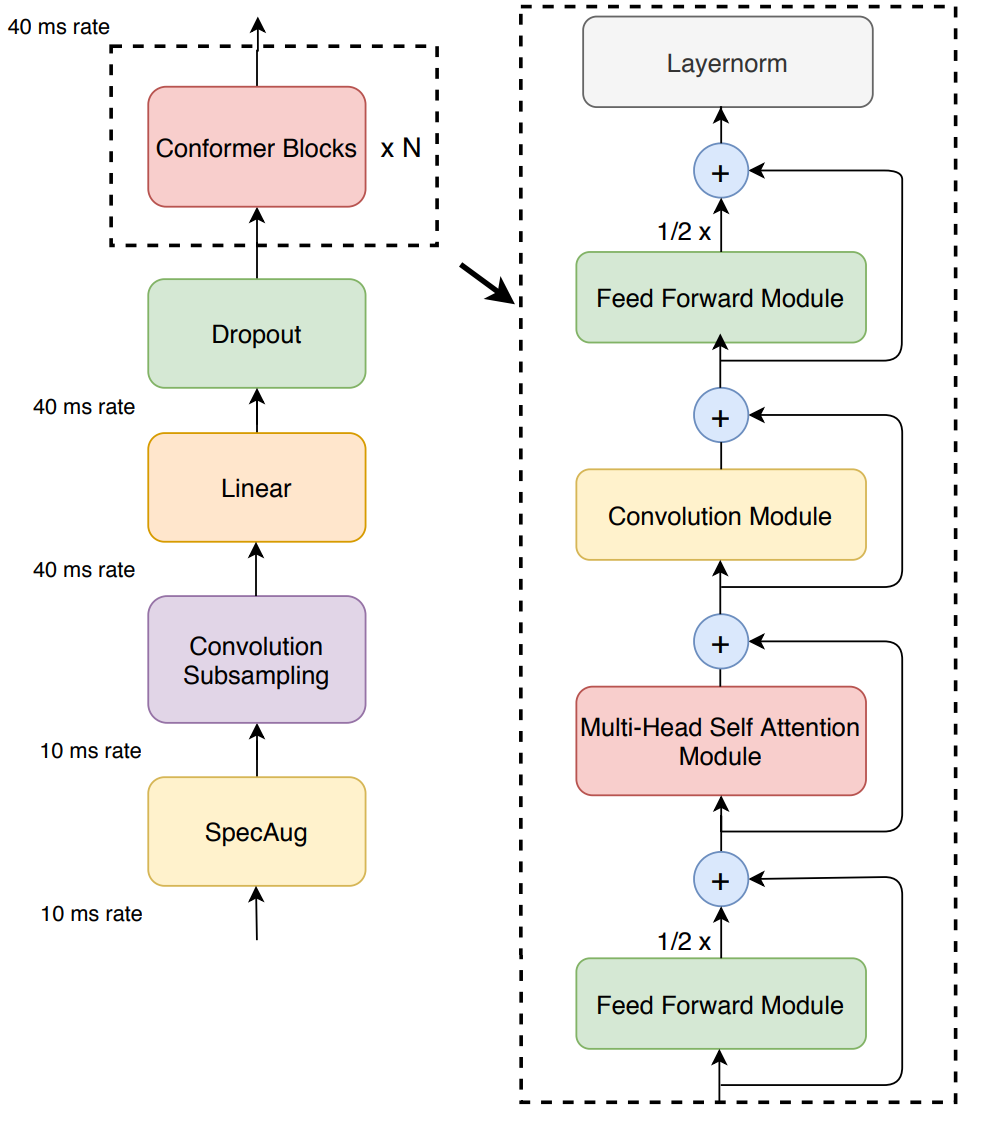
This model supports both the sub-word level and character level encodings. You can find more details on the config files for the
Conformer-CTC models in the Conformer-CTC configuration documentation. The variant with sub-word encoding is a BPE-based model
which can be instantiated using the EncDecCTCModelBPE class, while the
character-based variant is based on EncDecCTCModel.
You may find the example config files of Conformer-CTC model with character-based encoding at
<NeMo_git_root>/examples/asr/conf/conformer/conformer_ctc_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/conformer/conformer_ctc_bpe.yaml.
Conformer-Transducer#
Conformer-Transducer is the Conformer model introduced in [ASR-MODELS1] and uses RNNT/Transducer loss/decoder. It has the same encoder as Conformer-CTC but utilizes RNNT/Transducer loss/decoder which makes it an autoregressive model.
Most of the config file for Conformer-Transducer models are similar to Conformer-CTC except the sections related to the decoder and loss: decoder, loss, joint, decoding. You may take a look at our tutorials page on Transducer models to become familiar with their configs: Introduction to Transducers and ASR with Transducers You can find more details on the config files for the Conformer-Transducer models in the Conformer-CTC configuration documentation.
This model supports both the sub-word level and character level encodings. The variant with sub-word encoding is a BPE-based model
which can be instantiated using the EncDecRNNTBPEModel class, while the
character-based variant is based on EncDecRNNTModel.
You may find the example config files of Conformer-Transducer model with character-based encoding at
<NeMo_git_root>/examples/asr/conf/conformer/conformer_transducer_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/conformer/conformer_transducer_bpe.yaml.
Conformer-HAT#
Conformer HAT (Hybrid Autoregressive Transducer) model (do not confuse it with Hybrid-Transducer-CTC) is a modification of Conformer-Transducer model based on this previous work. The main idea is to separate labels and blank score predictions, which allows to estimate the internal LM probabilities during decoding. When external LM is available for inference, the internal LM can be subtracted from HAT model prediction in beamsearch decoding to improve external LM efficiency. It can be helpful in the case of text-only adaptation for new domains.
The only difference from the standard Conformer-Transducer model (RNNT) is the use of “HATJoint” class (instead of “RNNTJoint”) for joint module. The all HAT logic is implemented in the “HATJoint” class.
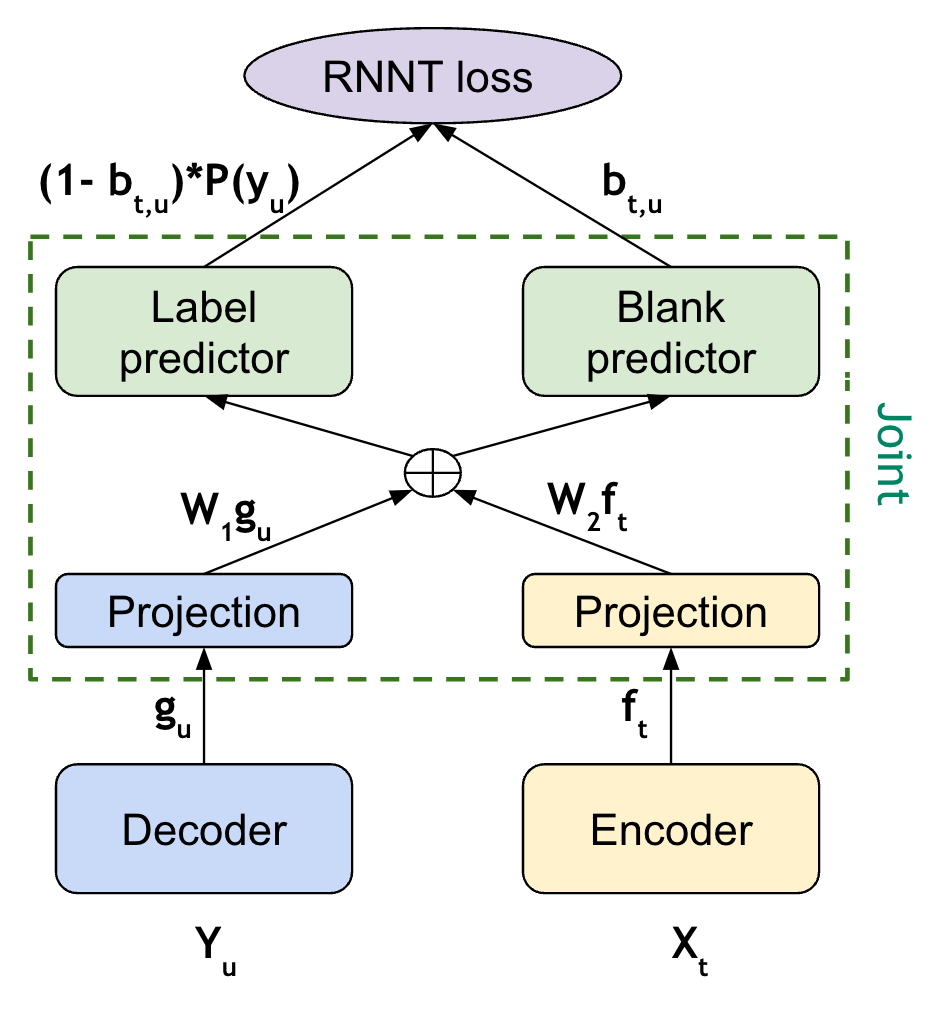
You may find the example config files of Conformer-HAT model with character-based encoding at
<NeMo_git_root>/examples/asr/conf/conformer/hat/conformer_hat_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/conformer/hat/conformer_hat_bpe.yaml.
By default, the decoding for HAT model works in the same way as for Conformer-Transducer.
In the case of external ngram LM fusion you can use <NeMo_git_root>/scripts/asr_language_modeling/ngram_lm/eval_beamsearch_ngram_transducer.py.
To enable HAT internal LM subtraction set hat_subtract_ilm=True and find more appropriate couple of beam_alpha and hat_ilm_weight values in terms of the best recognition accuracy.
Fast-Conformer#
The Fast Conformer (CTC and RNNT) models have a faster version of the Conformer encoder and differ from it as follows:
8x depthwise convolutional subsampling with 256 channels
Reduced convolutional kernel size of 9 in the conformer blocks
The Fast Conformer encoder is about 2.4x faster than the regular Conformer encoder without a significant model quality degradation. 128 subsampling channels yield a 2.7x speedup vs baseline but model quality starts to degrade. With local attention, inference is possible on audios >1 hrs (256 subsampling channels) / >2 hrs (128 channels).
Fast Conformer models were trained using CosineAnnealing (instead of Noam) as the scheduler.
You may find the example CTC config at
<NeMo_git_root>/examples/asr/conf/fastconformer/fast-conformer_ctc_bpe.yaml and
the transducer config at <NeMo_git_root>/examples/asr/conf/fastconformer/fast-conformer_transducer_bpe.yaml
Note that both configs are subword-based (BPE).
You can also train these models with longformer-style attention (https://arxiv.org/abs/2004.05150) using the following configs: CTC config at
<NeMo_git_root>/examples/asr/conf/fastconformer/fast-conformer-long_ctc_bpe.yaml and transducer config at <NeMo_git_root>/examples/asr/conf/fastconformer/fast-conformer-long_transducer_bpe.yaml
This allows using the model on longer audio (up to 70 minutes with Fast Conformer). Note that the Fast Conformer checkpoints
can be used with limited context attention even if trained with full context. However, if you also want to use global tokens,
which help aggregate information from outside the limited context, then training is required.
You may find more examples under <NeMo_git_root>/examples/asr/conf/fastconformer/.
Cache-aware Streaming Conformer#
Try real-time ASR with the Cache-aware Streaming Conformer tutorial notebook.
Buffered streaming uses overlapping chunks to make an offline ASR model usable for streaming with reasonable accuracy. However, it causes significant amount of duplication in computation due to the overlapping chunks. Also, there is an accuracy gap between the offline model and the streaming one, as there is inconsistency between how we train the model and how we perform inference for streaming. The Cache-aware Streaming Conformer models tackle and address these disadvantages. These streaming Conformers are trained with limited right context, making it possible to match how the model is being used in both training and inference. They also use caching to store intermediate activations to avoid any duplication in compute. The cache-aware approach is supported for both the Conformer-CTC and Conformer-Transducer and enables the model to be used very efficiently for streaming.
Three categories of layers in Conformer have access to right tokens: #. depthwise convolutions #. self-attention #. convolutions in the downsampling layers.
Streaming Conformer models use causal convolutions or convolutions with lower right context and also self-attention with limited right context to limit the effective right context for the input. The model trained with such limitations can be used in streaming mode and give the exact same outputs and accuracy as when the whole audio is given to the model in offline mode. These model can use caching mechanism to store and reuse the activations during streaming inference to avoid any duplications in the computations as much as possible.
We support the following three right context modeling techniques:
- Fully causal model with zero look-ahead: tokens do not see any future tokens. Convolution layers are all causal and right tokens are masked for self-attention.It gives zero latency but with limited accuracy.To train such a model, you need to set model.encoder.att_context_size=[left_context,0] and model.encoder.conv_context_size=causal in the config.
- Regular look-ahead: convolutions are able to see few future frames, and self-attention also sees the same number of future tokens.In this approach the activations for the look-ahead part are not cached, and are recalculated in the next chunks. The right context in each layer should be a small number as multiple layers would increase the effective context size and then increase the look-ahead size and latency.For example for a model of 17 layers with 4x downsampling and 10ms window shift, then even 2 right context in each layer means 17*2*10*4=1360ms look-ahead. Each step after the downsampling corresponds to 4*10=40ms.
- Chunk-aware look-ahead: input is split into equal chunks. Convolutions are fully causal while self-attention layers are able to see all the tokens in their corresponding chunk.For example, in a model with chunk size of 20 tokens, tokens at the first position of each chunk would see all the next 19 tokens while the last token would see zero future tokens.This approach is more efficient than regular look-ahead in terms of computations as the activations for most of the look-ahead part would be cached and there is close to zero duplications in the calculations.In terms of accuracy, this approach gives similar or even better results in term of accuracy than regular look-ahead as each token in each layer have access to more tokens on average. That is why we recommend to use this approach for streaming. Therefore we recommend to use the chunk-aware for cache-aware models.
Note
Latencies are based on the assumption that the forward time of the network is zero and it just estimates the time needed after a frame would be available until it is passed through the model.
Approaches with non-zero look-ahead can give significantly better accuracy by sacrificing latency. The latency can get controlled by the left context size. Increasing the right context would help the accuracy to a limit but would increase the computation time.
In all modes, left context can be controlled by the number of tokens visible in self-attention and the kernel size of the convolutions. For example, if the left context of self-attention in each layer is set to 20 tokens and there are 10 layers of Conformer, then the effective left context is 20*10=200 tokens. Left context of self-attention for regular look-ahead can be set as any number, while it should be set as a multiple of the right context in chunk-aware look-ahead. For convolutions, if we use a left context of 30, then there would be 30*10=300 effective left context. Left context of convolutions is dependent on their kernel size while it can be any number for self-attention layers. Higher left context for self-attention means larger cache and more computations for the self-attention. A self-attention left context of around 6 secs would give close results to unlimited left context. For a model with 4x downsampling and shift window of 10ms in the preprocessor, each token corresponds to 4*10=40ms.
If striding approach is used for downsampling, all the convolutions in downsampling would be fully causal and don’t see future tokens.
Multiple Look-aheads#
We support multiple look-aheads for cahce-aware models. You may specify a list of context sizes for att_context_size. During the training, different context sizes would be used randomly with the distribution specified by att_context_probs. For example you may enable multiple look-aheads by setting model.encoder.att_context_size=[[70,13],[70,6],[70,1],[70,0]] for the training. The first item in the list would be the default during test/validation/inference. To switch between different look-aheads, you may use the method asr_model.encoder.set_default_att_context_size(att_context_size) or set the att_context_size like the following when using the script speech_transcribe.py:
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py \
pretrained_name="stt_en_fastconformer_hybrid_large_streaming_multi" \
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>" \
att_context_size=[70,0]
You may find the example config files for cache-aware streaming FastConformer models at
<NeMo_git_root>/examples/asr/conf/fastconformer/cache_aware_streaming/conformer_transducer_bpe_streaming.yaml for Transducer variant and
at <NeMo_git_root>/examples/asr/conf/conformer/cache_aware_streaming/conformer_ctc_bpe.yaml for CTC variant. It is recommended to use FastConformer as they are more than 2X faster in both training and inference than regular Conformer.
The hybrid versions of FastConformer can be found here: <NeMo_git_root>/examples/asr/conf/conformer/hybrid_cache_aware_streaming/
Examples for regular Conformer can be found at
<NeMo_git_root>/examples/asr/conf/conformer/cache_aware_streaming/conformer_transducer_bpe_streaming.yaml for Transducer variant and
at <NeMo_git_root>/examples/asr/conf/conformer/cache_aware_streaming/conformer_ctc_bpe.yaml for CTC variant.
To simulate cache-aware streaming, you may use the script at <NeMo_git_root>/examples/asr/asr_cache_aware_streaming/speech_to_text_cache_aware_streaming_infer.py. It can simulate streaming in single stream or multi-stream mode (in batches) for an ASR model.
This script can be used for models trained offline with full-context but the accuracy would not be great unless the chunk size is large enough which would result in high latency.
It is recommended to train a model in streaming model with limited context for this script. More info can be found in the script.
Note cache-aware streaming models are being exported without caching support by default.
To include caching support, model.set_export_config({‘cache_support’ : ‘True’}) should be called before export.
Or, if <NeMo_git_root>/scripts/export.py is being used:
python export.py cache_aware_conformer.nemo cache_aware_conformer.onnx –export-config cache_support=True
Multitalker Cache-aware Streaming FastConformer#
This model is a streaming multitalker ASR model based on the Cache-aware Streaming FastConformer architecture. The model only takes the speaker diarization outputs as external information and eliminates the need for explicit speaker queries or enrollment audio [ASR-MODELS11]. Unlike conventional target-speaker ASR approaches that require speaker embeddings, this model dynamically adapts to individual speakers through speaker-wise speech activity prediction.
Self-Speaker Adaptation Technique#
The key innovation involves injecting learnable speaker kernels into the pre-encode layer of the FastConformer encoder [ASR-MODELS9]. These speaker kernels are generated via speaker supervision activations, enabling instantaneous adaptation to target speakers. This approach leverages the inherent tendency of streaming ASR systems to prioritize specific speakers, repurposing this mechanism to achieve robust speaker-focused recognition.
The model architecture requires deploying one model instance per speaker, meaning the number of model instances matches the number of speakers in the conversation. While this necessitates additional computational resources, it achieves state-of-the-art performance in handling fully overlapped speech in both offline and streaming scenarios.
This self-speaker adaptation approach offers several advantages over traditional multitalker ASR methods:
- No Speaker Enrollment: Unlike target-speaker ASR systems that require pre-enrollment audio or speaker embeddings, this model only needs speaker activity information from diarization
- Handles Severe Overlap: Each instance focuses on a single speaker, enabling accurate transcription even during fully overlapped speech
- Streaming Capable: Designed for real-time streaming scenarios with configurable latency-accuracy tradeoffs
- Leverages Single-Speaker Models: Can be fine-tuned from strong pre-trained single-speaker ASR models, and single speaker ASR performance is also preserved
Speaker Kernel Injection#
The streaming multitalker Parakeet model employs a speaker kernel injection mechanism at some layers of the FastConformer encoder. The learnable speaker kernels are injected into selected encoder layers, enabling the model to dynamically adapt to specific speakers.
The speaker kernels are generated through speaker supervision activations that detect speech activity for each target speaker. This enables the encoder states to become more responsive to the targeted speaker’s speech characteristics, even during periods of fully overlapped speech.
Multi-Instance Architecture#
The model is based on the Parakeet architecture and consists of a NeMo Encoder for Speech Tasks (NEST) [ASR-MODELS5] which is based on FastConformer [ASR-MODELS9] encoder. The key architectural park2024nestinnovation is the multi-instance approach, where one model instance is deployed per speaker.
Each model instance has the following characteristics:
- Receives the identical speaker-mixed audio input.
- Injects speaker-specific kernels at the pre-encode layer.
- Produces transcription output specific to its target speaker.
- Operates independently and can run in parallel with other instances.
This architecture enables the model to handle severe speech overlap by having each instance focus exclusively on one speaker, eliminating the permutation problem that affects other multitalker ASR approaches. Find more details in the [ASR-MODELS11] paper.
The real-time multitalker ASR model is built on RNNT model structure. EncDecMultiTalkerRNNTBPEModel class inherits from EncDecRNNTBPEModel class and speaker kernel SpeakerKernel class.
Try real-time multitalker ASR with the tutorial notebook: Streaming Multitalker ASR tutorial notebook.
You can simulate the streaming audio stream and streaming multitalker ASR with the script:
<NeMo_git_root>/examples/asr/asr_cache_aware_streaming/speech_to_text_multitalker_streaming_infer.py
For an individual audio file:
python <NeMo_git_root>/examples/asr/asr_cache_aware_streaming/speech_to_text_multitalker_streaming_infer.py \
asr_model="/path/to/multitalker-parakeet-streaming-0.6b-v1.nemo" \
diar_model="/path/to/nvidia/diar_streaming_sortformer_4spk-v2.nemo" \
audio_file="/path/to/your/example.wav" \
output_path="/path/to/your/example_output.json"
If you want to simulate the system on multiple files, use NeMo manifest:
python <NeMo_git_root>/examples/asr/asr_cache_aware_streaming/speech_to_text_multitalker_streaming_infer.py \
asr_model="/path/to/multitalker-parakeet-streaming-0.6b-v1.nemo" \
diar_model="/path/to/nvidia/diar_streaming_sortformer_4spk-v2.nemo" \
manifest_file="/path/to/your/example_manifest.json" \
output_path="/path/to/your/example_output.json"
Download model checkpoint and more details can be found on Huggingface model card: Multitalker Parakeet (Cache-aware FastConformer) Streaming.
Hybrid-Transducer-CTC#
Hybrid RNNT-CTC models is a group of models with both the RNNT and CTC decoders. Training a unified model would speedup the convergence for the CTC models and would enable
the user to use a single model which works as both a CTC and RNNT model. This category can be used with any of the ASR models.
Hybrid models uses two decoders of CTC and RNNT on the top of the encoder. The default decoding strategy after the training is done is RNNT.
User may use the asr_model.change_decoding_strategy(decoder_type='ctc' or 'rnnt') to change the default decoding.
The variant with sub-word encoding is a BPE-based model
which can be instantiated using the EncDecHybridRNNTCTCBPEModel class, while the
character-based variant is based on EncDecHybridRNNTCTCModel.
You may use the example scripts under <NeMo_git_root>/examples/asr/asr_hybrid_transducer_ctc for both the char-based encoding and sub-word encoding.
These examples can be used to train any Hybrid ASR model like Conformer, Citrinet, QuartzNet, etc.
You may find the example config files of Conformer variant of such hybrid models with character-based encoding at
<NeMo_git_root>/examples/asr/conf/conformer/hybrid_transducer_ctc/conformer_hybrid_transducer_ctc_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/conformer/hybrid_transducer_ctc/conformer_hybrid_transducer_ctc_bpe.yaml.
Similar example configs for FastConformer variants of Hybrid models can be found here:
<NeMo_git_root>/examples/asr/conf/fastconformer/hybrid_transducer_ctc/
<NeMo_git_root>/examples/asr/conf/fastconformer/hybrid_cache_aware_streaming/
Note Hybrid models are being exported as RNNT (encoder and decoder+joint parts) by default.
To export as CTC (single encoder+decoder graph), model.set_export_config({‘decoder_type’ : ‘ctc’}) should be called before export.
Or, if <NeMo_git_root>/scripts/export.py is being used:
python export.py hybrid_transducer.nemo hybrid_transducer.onnx –export-config decoder_type=ctc
Hybrid-Transducer-CTC with Prompt Conditioning#
The Hybrid RNNT-CTC model with prompt conditioning (EncDecHybridRNNTCTCBPEModelWithPrompt) extends the base Hybrid-Transducer-CTC model
to support multi-language and multi-domain ASR through prompt conditioning. This model leverages prompts to guide the transcription process,
enabling language-specific or domain-specific transcription from a single unified model.
Key features of this model include:
Prompt Feature: Uses learnable prompt embeddings that are concatenated with acoustic features to guide transcription
Multi-language Support: Can transcribe audio in multiple languages based on language prompts
Offline and Buffered Streaming Inference Support: Can be used in offline and buffered streaming mode
The model can be instantiated using the EncDecHybridRNNTCTCBPEModelWithPrompt class.
Architecture Overview#
The model architecture builds upon the standard Hybrid-Transducer-CTC model by incorporating prompt information directly into the decoder through a concatenation-based approach. This design enables scalable multilingual ASR/AST capabilities.
Core Components:
Prompt Supervision Source: Prompt label information extracted from training and inference manifests or provided as an input
Prompt Vector Representation: One-hot binary vectors where one element is 1 (prompt) and all others are 0
Concatenation-Based Prompt Encoding: Direct combination of prompt vectors with acoustic features
Detailed Architecture:
Prompt Vector Design: - Dimensionality: Default to 128-dimensional vectors for scalability (supports current target language and future prompts) without the need to change the architecture - Representation: Binary one-hot encoding where each position represents a prompt ID - Expansion: Prompt vectors are expanded at each time step to match acoustic feature temporal dimensions
Concatenation Method Implementation: The model adopts a concatenation approach where language vectors and ASR acoustic features are directly combined:
Feature Stacking: Language vectors and encoded acoustic features are stacked along the feature dimension
Projection: The concatenated representation passes through a projection network (
prompt_kernel)
Inference Capabilities:
The model supports both offline and buffered streaming inference modes:
Offline Mode: Full context processing for maximum accuracy
Buffered Streaming: Real-time multilingual speech-to-text processing with language-aware decoding
Configuration#
The model supports several prompt-specific configuration parameters:
initialize_prompt_feature: Boolean flag to enable prompt conditioningnum_prompts: Number of supported prompt categories (default: 128)prompt_dictionary: Mapping from language/domain identifiers to prompt indicesprompt_field: Field name used for prompt extraction from manifest files
Example config files for this model can be found at:
<NeMo_git_root>/examples/asr/conf/fastconformer/hybrid_transducer_ctc/fastconformer_hybrid_transducer_ctc_bpe_prompt.yaml
Training#
To train the Hybrid-Transducer-CTC model with prompt feature, use the training script:
<NeMo_git_root>/examples/asr/asr_hybrid_transducer_ctc/speech_to_text_hybrid_rnnt_ctc_bpe_prompt.py
Example training command:
python <NeMo_git_root>/examples/asr/asr_hybrid_transducer_ctc/speech_to_text_hybrid_rnnt_ctc_bpe_prompt.py \
--config-path=<NeMo_git_root>/examples/asr/conf/fastconformer/hybrid_transducer_ctc/ \
--config-name=fastconformer_hybrid_transducer_ctc_bpe_prompt.yaml \
model.train_ds.manifest_filepath=<path_to_train_manifest> \
model.validation_ds.manifest_filepath=<path_to_val_manifest> \
model.tokenizer.dir=<path_to_tokenizer> \
model.test_ds.manifest_filepath=<path_to_test_manifest>
Usage Examples#
Basic Transcription with Language Prompts:
# Load the model
asr_model = nemo_asr.models.EncDecHybridRNNTCTCBPEModelWithPrompt.restore_from("path/to/model.nemo")
# Transcribe with specific target language
transcriptions = asr_model.transcribe(
paths2audio_files=["audio1.wav", "audio2.wav"],
target_lang="en-US", # Specify target language
)
Training Data Requirements#
The model requires training data with prompt annotations. The recommended dataset format uses Lhotse with the
LhotseSpeechToTextBpeDatasetWithPrompt dataset class.
Manifest files should include prompt information:
{
"audio_filepath": "path/to/audio.wav",
"text": "transcription text",
"duration": 10.5,
"target_lang": "en-US"
}
Hybrid ASR-TTS Model#
Hybrid ASR-TTS Model (ASRWithTTSModel) is a transparent wrapper for the ASR model with a frozen pretrained text-to-spectrogram model. The approach is described in the paper
Text-only domain adaptation for end-to-end ASR using integrated text-to-mel-spectrogram generator.
This allows using text-only data for training and finetuning, mixing it with audio-text pairs if necessary.
The model consists of three models:
ASR model (
EncDecCTCModelBPEorEncDecRNNTBPEModel)Frozen TTS Mel Spectrogram Generator (currently, only FastPitch model is supported)
Optional frozen Spectrogram Enhancer model trained to mitigate mismatch between real and generated mel spectrogram
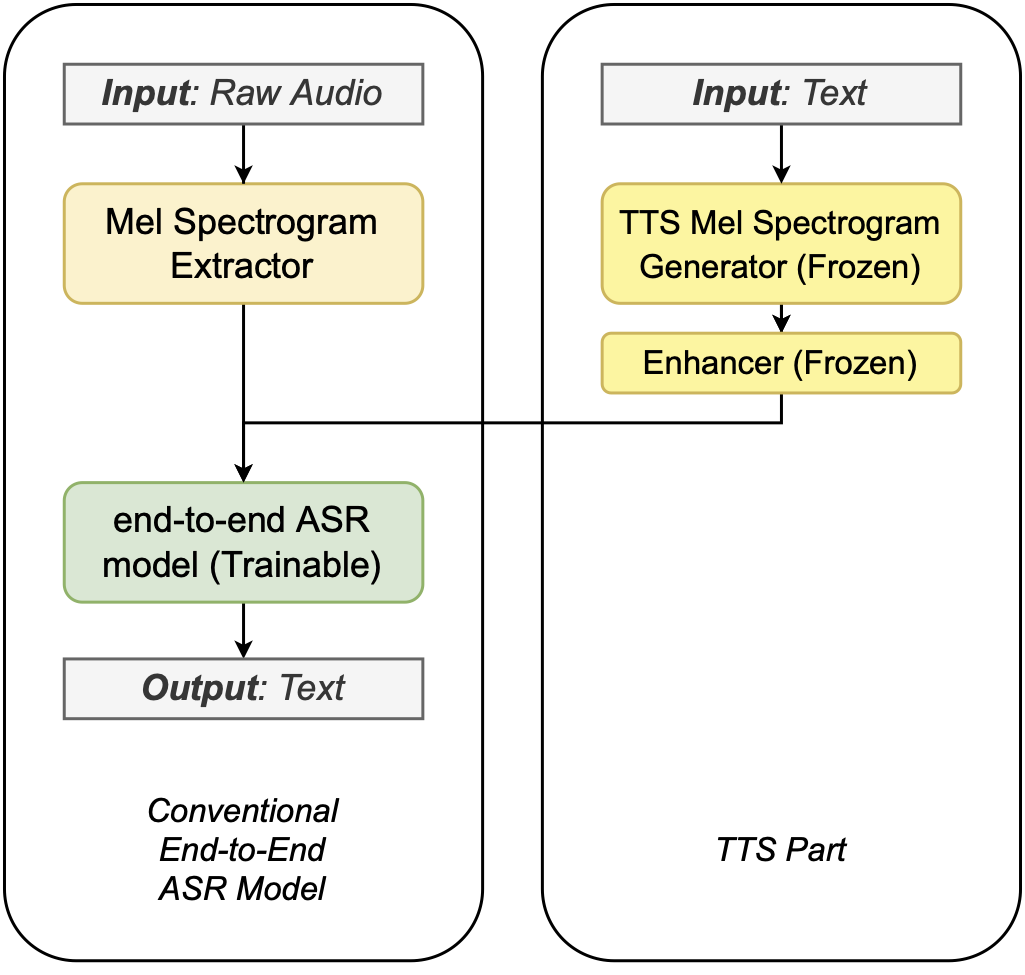
For the detailed information see:
Text-only dataset preparation
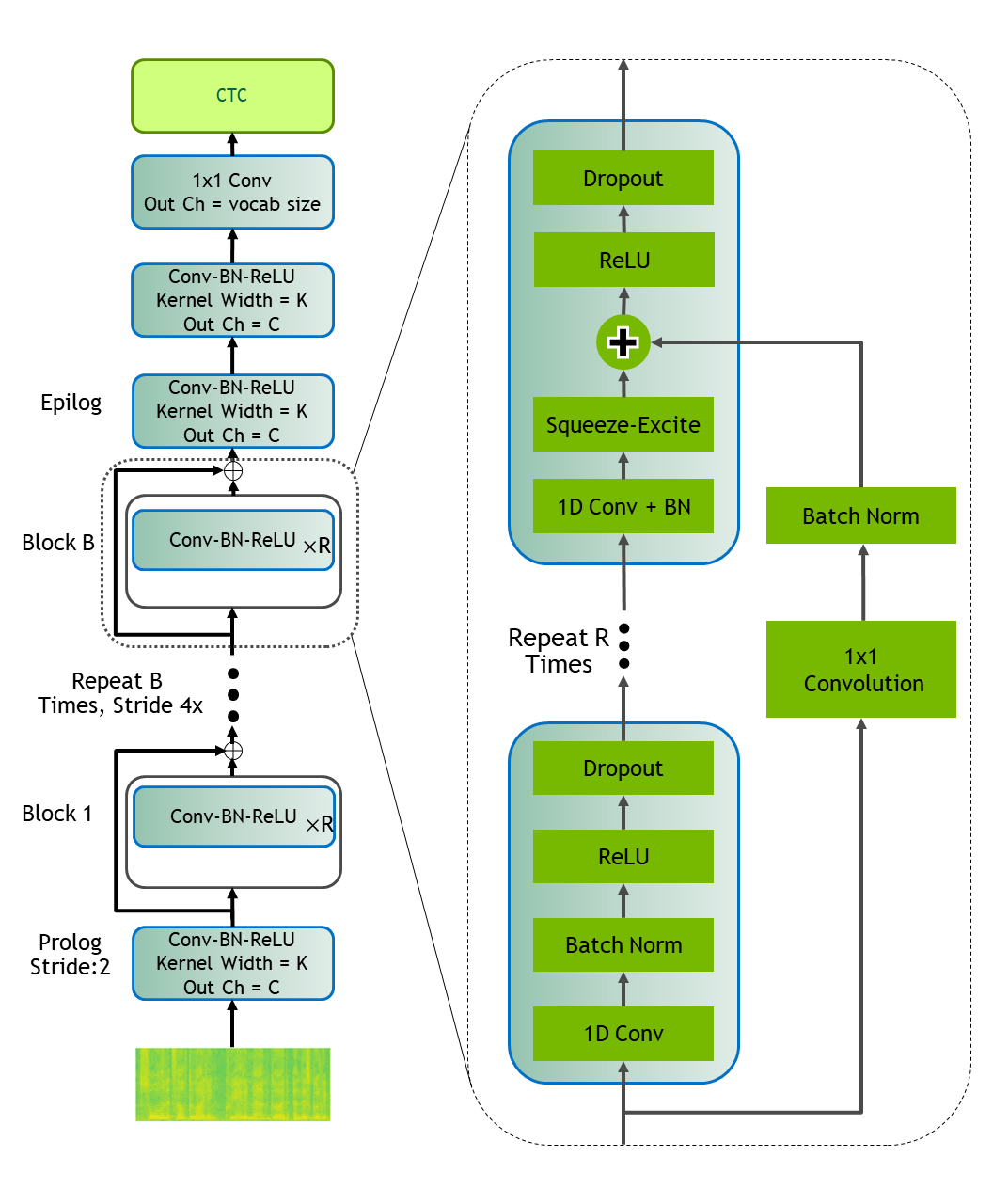
Jasper#
Jasper (“Just Another Speech Recognizer”) [ASR-MODELS8] is a deep time delay neural network (TDNN) comprising of
blocks of 1D-convolutional layers. The Jasper family of models are denoted as Jasper_[BxR] where B is the number of blocks
and R is the number of convolutional sub-blocks within a block. Each sub-block contains a 1-D convolution, batch normalization,
ReLU, and dropout:
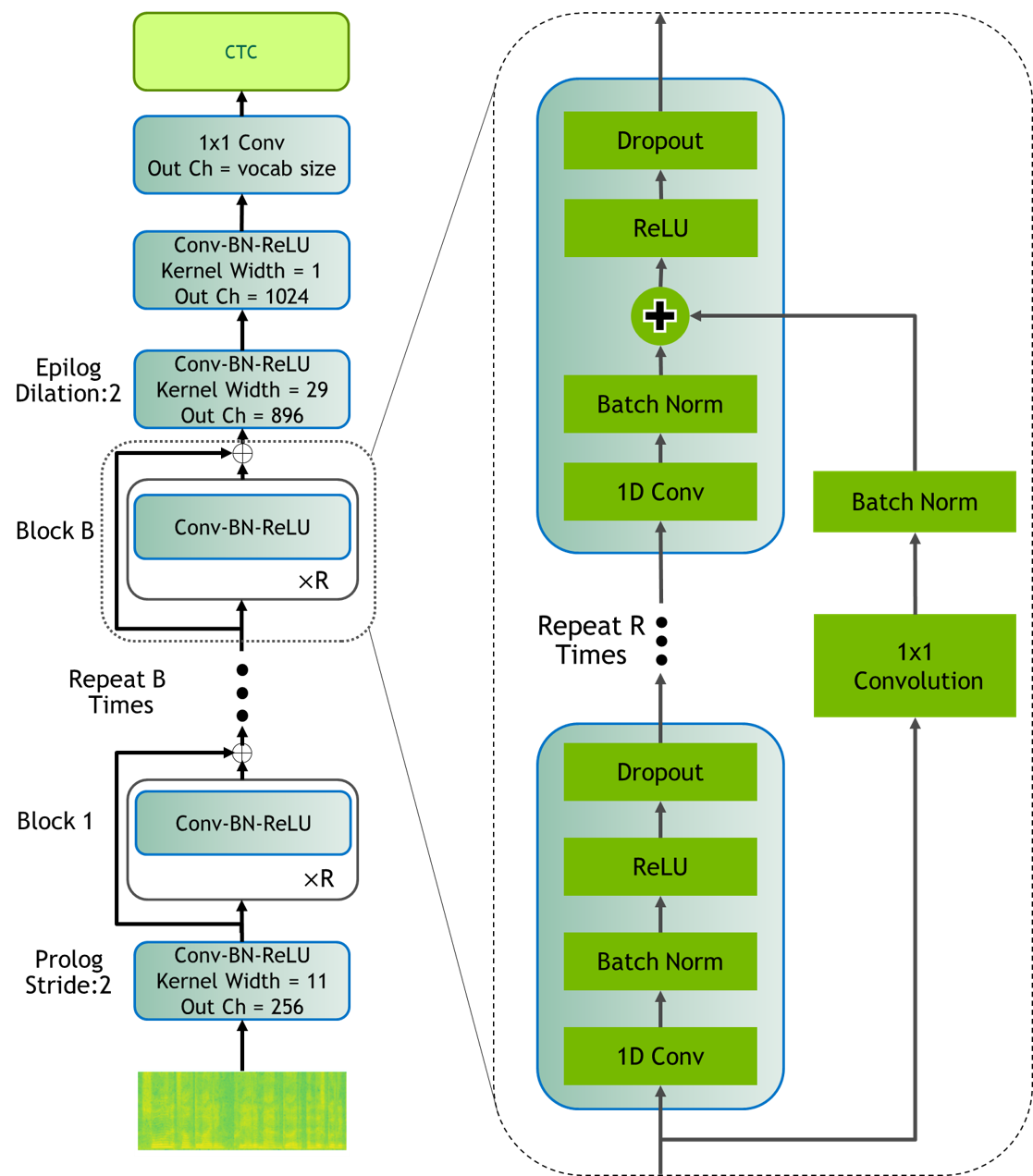
Jasper models can be instantiated using the EncDecCTCModel class.
QuartzNet#
QuartzNet [ASR-MODELS7] is a version of Jasper [ASR-MODELS8] model with separable
convolutions and larger filters. It can achieve performance similar to Jasper but with an order of magnitude fewer parameters.
Similarly to Jasper, the QuartzNet family of models are denoted as QuartzNet_[BxR] where B is the number of blocks and R
is the number of convolutional sub-blocks within a block. Each sub-block contains a 1-D separable convolution, batch normalization,
ReLU, and dropout:
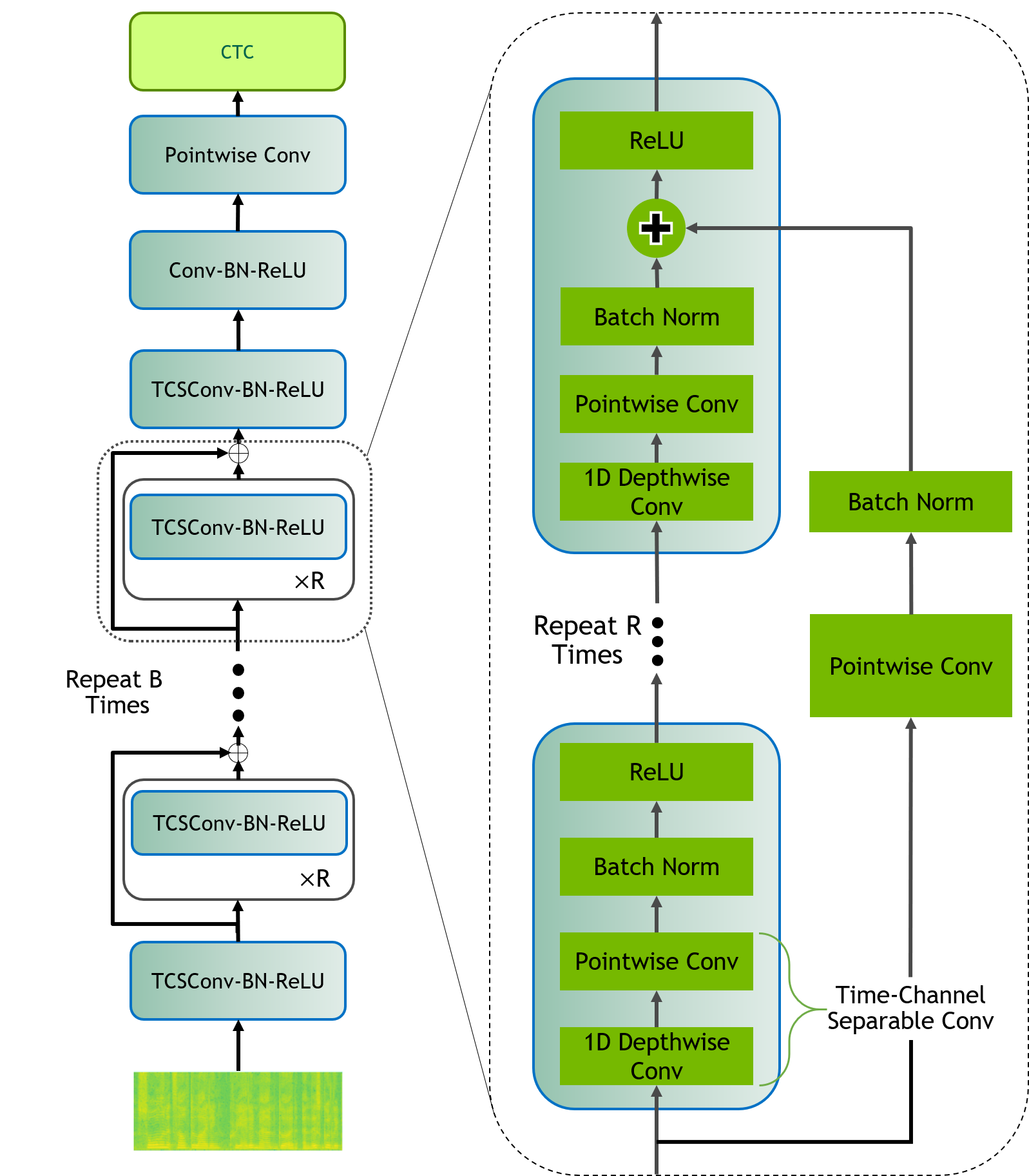
QuartzNet models can be instantiated using the EncDecCTCModel class.
Citrinet#
Citrinet is a version of QuartzNet [ASR-MODELS7] that extends ContextNet [ASR-MODELS2], utilizing subword encoding (via Word Piece tokenization) and Squeeze-and-Excitation mechanism [ASR-MODELS4] to obtain highly accurate audio transcripts while utilizing a non-autoregressive CTC based decoding scheme for efficient inference.
Citrinet models can be instantiated using the EncDecCTCModelBPE class.
ContextNet#
ContextNet is a model uses Transducer/RNNT loss/decoder and is introduced in [ASR-MODELS2]. It uses Squeeze-and-Excitation mechanism [ASR-MODELS4] to model larger context. Unlike Citrinet, it has an autoregressive decoding scheme.
ContextNet models can be instantiated using the EncDecRNNTBPEModel class for a
model with sub-word encoding and EncDecRNNTModel for char-based encoding.
You may find the example config files of ContextNet model with character-based encoding at
<NeMo_git_root>/examples/asr/conf/contextnet_rnnt/contextnet_rnnt_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/contextnet_rnnt/contextnet_rnnt.yaml.
Squeezeformer-CTC#
Squeezeformer-CTC is a CTC-based variant of the Squeezeformer model introduced in [ASR-MODELS6]. Squeezeformer-CTC has a similar encoder as the original Squeezeformer but uses CTC loss and decoding instead of RNNT/Transducer loss, which makes it a non-autoregressive model. The vast majority of the architecture is similar to Conformer model, so please refer to Conformer-CTC.
The model primarily differs from Conformer in the following ways :
Temporal U-Net style time reduction, effectively reducing memory consumption and FLOPs for execution.
Unified activations throughout the model.
Simplification of module structure, removal of redundant layers.
Here is the overall architecture of the encoder of Squeezeformer-CTC:
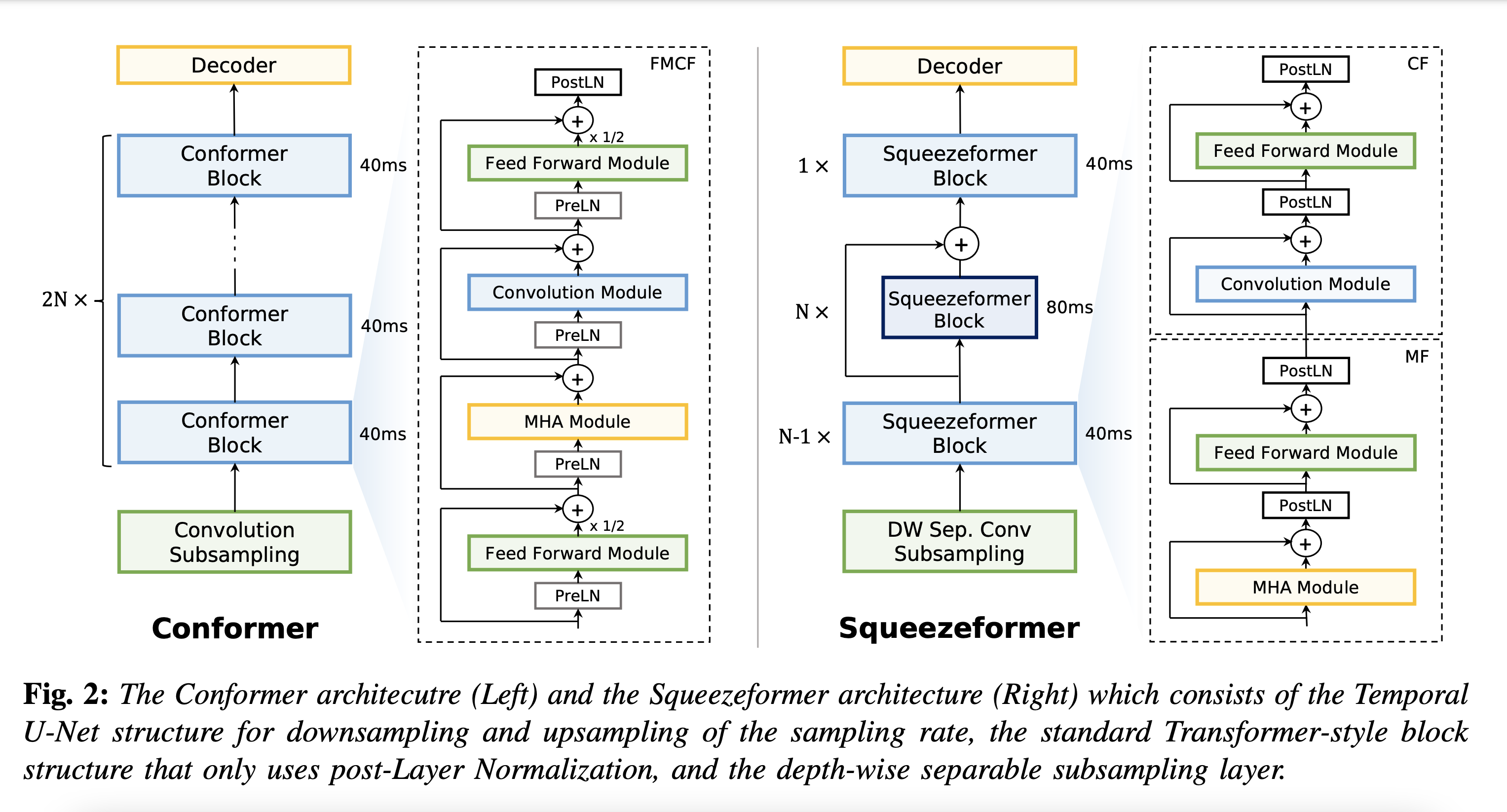
This model supports both the sub-word level and character level encodings. You can find more details on the config files for the
Squeezeformer-CTC models at Squeezeformer-CTC. The variant with sub-word encoding is a BPE-based model
which can be instantiated using the EncDecCTCModelBPE class, while the
character-based variant is based on EncDecCTCModel.
You may find the example config files of Squeezeformer-CTC model with character-based encoding at
<NeMo_git_root>/examples/asr/conf/squeezeformer/squeezeformer_ctc_char.yaml and
with sub-word encoding at <NeMo_git_root>/examples/asr/conf/squeezeformer/squeezeformer_ctc_bpe.yaml.
LSTM-Transducer#
LSTM-Transducer is a model which uses RNNs (eg. LSTM) in the encoder. The architecture of this model is followed from suggestions in [ASR-MODELS3]. It uses RNNT/Transducer loss/decoder. The encoder consists of RNN layers (LSTM as default) with lower projection size to increase the efficiency. Layer norm is added between the layers to stabilize the training. It can be trained/used in unidirectional or bidirectional mode. The unidirectional mode is fully causal and can be used easily for simple and efficient streaming. However the accuracy of this model is generally lower than other models like Conformer and Citrinet.
This model supports both the sub-word level and character level encodings. You may find the example config file of RNNT model with wordpiece encoding at <NeMo_git_root>/examples/asr/conf/lstm/lstm_transducer_bpe.yaml.
You can find more details on the config files for the RNNT models at LSTM-Transducer.
LSTM-CTC#
LSTM-CTC model is a CTC-variant of the LSTM-Transducer model which uses CTC loss/decoding instead of Transducer.
You may find the example config file of LSTM-CTC model with wordpiece encoding at <NeMo_git_root>/examples/asr/conf/lstm/lstm_ctc_bpe.yaml.
References#
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, and others. Conformer: convolution-augmented transformer for speech recognition. arXiv preprint arXiv:2005.08100, 2020.
Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu. Contextnet: improving convolutional neural networks for automatic speech recognition with global context. arXiv:2005.03191, 2020.
Yanzhang He, Tara N Sainath, Rohit Prabhavalkar, Ian McGraw, Raziel Alvarez, Ding Zhao, David Rybach, Anjuli Kannan, Yonghui Wu, Ruoming Pang, and others. Streaming end-to-end speech recognition for mobile devices. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6381–6385. IEEE, 2019.
He Huang, Taejin Park, Kunal Dhawan, Ivan Medennikov, Krishna C Puvvada, Nithin Rao Koluguri, Weiqing Wang, Jagadeesh Balam, and Boris Ginsburg. NEST: Self-supervised fast conformer as all-purpose seasoning to speech processing tasks. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1–5. IEEE, 2025.
Sehoon Kim, Amir Gholami, Albert Shaw, Nicholas Lee, Karttikeya Mangalam, Jitendra Malik, Michael W. Mahoney, and Kurt Keutzer. Squeezeformer: an efficient transformer for automatic speech recognition. 2022. URL: https://arxiv.org/abs/2206.00888, doi:10.48550/ARXIV.2206.00888.
Samuel Kriman, Stanislav Beliaev, Boris Ginsburg, Jocelyn Huang, Oleksii Kuchaiev, Vitaly Lavrukhin, Ryan Leary, Jason Li, and Yang Zhang. Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions. arXiv preprint arXiv:1910.10261, 2019.
Jason Li, Vitaly Lavrukhin, Boris Ginsburg, Ryan Leary, Oleksii Kuchaiev, Jonathan M Cohen, Huyen Nguyen, and Ravi Teja Gadde. Jasper: an end-to-end convolutional neural acoustic model. arXiv preprint arXiv:1904.03288, 2019.
Dima Rekesh, Nithin Rao Koluguri, Samuel Kriman, Somshubra Majumdar, Vahid Noroozi, He Huang, Oleksii Hrinchuk, Krishna Puvvada, Ankur Kumar, Jagadeesh Balam, and others. Fast conformer with linearly scalable attention for efficient speech recognition. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 1–8. IEEE, 2023.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, 6000–6010. 2017.
Weiqing Wang, Taejin Park, Ivan Medennikov, Jinhan Wang, Kunal Dhawan, He Huang, Nithin Rao Koluguri, Jagadeesh Balam, and Boris Ginsburg. Speaker Targeting via Self-Speaker Adaptation for Multi-talker ASR. In Interspeech 2025, 5498–5502. 2025. doi:10.21437/Interspeech.2025-2142.