Adapters#
In NeMo, we often train models and fine-tune them for a specific task. This is a reasonable approach when the models are just a few million parameters. However, this approach quickly becomes infeasible when approaching hundreds of millions or even billions of parameters. As a potential solution to such a scenario, where fine-tuning a massive model is no longer feasible, we look to Adapters [adapters1] to specialize our model on a specific domain or task. Adapters require a fraction of the total number of parameters as the original model and are much more efficient to fine-tune.
Note
For a detailed tutorial on adding Adapter support to any PyTorch module, please refer to the NeMo Adapter Tutorials.
What are Adapters?#
Adapters are a straightforward concept - one formulation can be shown by the diagram below. At their simplest, they are residual Feedforward layers that compress the input dimension (\(D\)) to a small bottleneck dimension (\(H\)), such that \(R^D \text{->} R^H\), compute an activation (such as ReLU), finally mapping \(R^H \text{->} R^D\) with another Feedforward layer. This output is then added to the input via a simple residual connection.
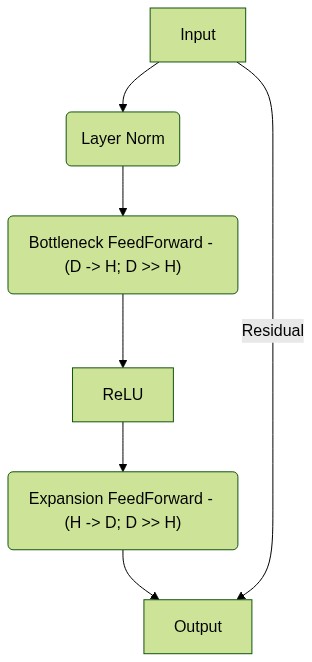
Adapter modules such as this are usually initialized such that the initial output of the adapter will always be zeros so as to prevent degradation of the original model’s performance due to addition of such modules.
torch.nn.Module with Adapters#
In NeMo, Adapters are supported via a Mixin class that can be attached to any torch.nn.Module. Such a module will
have multiple additional methods which will enable adapter capabilities in that module.
# Import the adapter mixin from NeMo
from nemo.core import adapter_mixins
# NOTE: See the *two* classes being inherited here !
class MyModule(torch.nn.Module, adapter_mixins.AdapterModuleMixin):
pass
AdapterModuleMixin#
Let’s look into what AdapterModuleMixin adds to the general PyTorch module. Some of the most important methods that are required are listed below :
add_adapter: Used to add an adapter with a unique name to the module.get_enabled_adapters: Returns a list of names of all enabled adapter modules.set_enabled_adapters: Sets whether a single (or all) adapters are enabled or disabled.is_adapter_available: Check if any adapter is available and enabled or not.
Modules that extend this mixin usually can directly use these methods without extending them, but we will cover a case below where you may wish to extend these methods.
Using the Adapter Module#
Now that MyModule supports adapters, we can easily add adapters, set their state, check if they are available and
perform their forward pass. Note that if multiple adapters are enabled, they are called in a chain, the output of the previous adapter is passed as input to the next adapter and so on.
# Import the adapter mixin and modules from NeMo
import torch
from nemo.core import adapter_mixins
from nemo.collections.common.parts import adapter_modules
class MyModule(torch.nn.Module, adapter_mixins.AdapterModuleMixin):
def forward(self, x: torch.Tensor) -> torch.Tensor:
output = self.layers(x) # assume self.layers is some Sequential() module
if self.is_adapter_available(): # check if adapters were added or not
output = self.forward_enabled_adapters() # perform the forward of all enabled adapters in a chain
return output
# Now let us create a module, add an adapter and do a forward pass with some random inputs
module = MyModule(dim) # assume dim is some input and output dimension of the module.
# Add an adapter
module.add_adapter("first_adapter", cfg=adapter_modules.LinearAdapter(in_features=dim, dim=5))
# Check if adapter is available
module.is_adapter_available() # returns True
# Check the name(s) of the enabled adapters
module.get_enabled_adapters() # returns ['first_adapter']
# Set the state of the adapter (by name)
module.set_enabled_adapters(name="first_adapter", enabled=True)
# Freeze all the weights of the original module (equivalent to calling module.freeze() for a NeuralModule)
for param in module.parameters():
param.requires_grad = False
# Unfreeze only the adapter weights (so that we finetune only the adapters and not the original weights !)
module.unfreeze_enabled_adapters()
# Now you can train this model's adapters !
input_data = torch.randn(4, dim) # assume dim is the input-output dim of the module
outputs_with_adapter = module(input_data)
# Compute loss and backward ...
Adapter Compatible Models#
If the goal was to support adapters in a single module, then the goal has been accomplished. In the real world however, we
build large composite models out of multiple modules and combine them to build a final model that we then train. We do this using the
AdapterModelPTMixin.
Note
For an in-depth guide to supporting hierarchical adapter modules, please refer to the NeMo Adapter Tutorials.
Below, we will discuss some useful functionality of Adapter Compatible Models.
Save and restore a Model with adapter capability: Any NeMo model that implements this class correctly can save and restore NeMo models with adapter capabilities, thereby allowing sharing of adapters.save_adaptersandload_adapters: Adapters are usually a very small number of parameters, there is no need for the entire model to be duplicated for each adapter. This method allows storing just the adapter module(s) separately from the Model, so that you can use the same “base” model, and share just the Adapter modules.
References#
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, 2790–2799. PMLR, 2019.