Models#
This section provides a brief overview of TTS models that NeMo’s TTS collection currently supports.
Model Recipes can be accessed through examples/tts/*.py.
Configuration Files can be found in the directory of examples/tts/conf/. For detailed information about TTS configuration files and how they should be structured, please refer to the section NeMo TTS Configuration Files.
Pretrained Model Checkpoints are available for any users for immediately synthesizing speech or fine-tuning models on your custom datasets. Please follow the section Checkpoints for instructions on how to use those pretrained models.
Mel-Spectrogram Generators#
FastPitch#
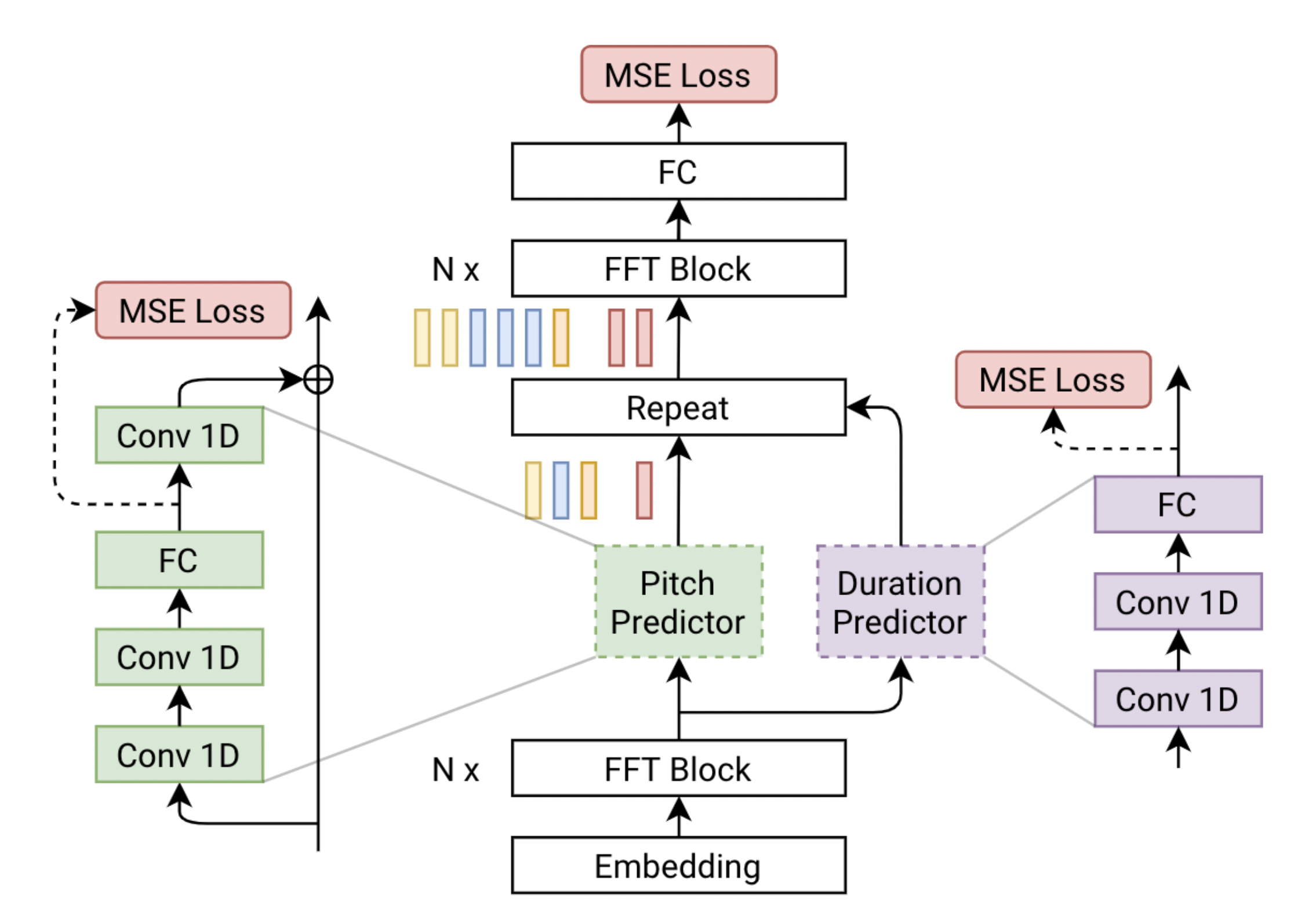
FastPitch is a fully-parallel text-to-speech synthesis model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference. By altering these predictions, the generated speech can be more expressive, better match the semantic of the utterance, and in the end more engaging to the listener. Uniformly increasing or decreasing pitch with FastPitch generates speech that resembles the voluntary modulation of voice. Conditioning on frequency contours improves the overall quality of synthesized speech, making it comparable to the state of the art. It does not introduce an overhead, and FastPitch retains the favorable, fully-parallel Transformers architecture, with over 900x real-time factor for mel-spectrogram synthesis of a typical utterance. The architecture of FastPitch is shown below. It is based on FastSpeech and consists of two feed-forward Transformer (FFTr) stacks. The first FFTr operates in the resolution of input tokens, and the other one in the resolution of the output frames. Please refer to [TTS-MODELS12] for details.
Mixer-TTS/Mixer-TTS-X#
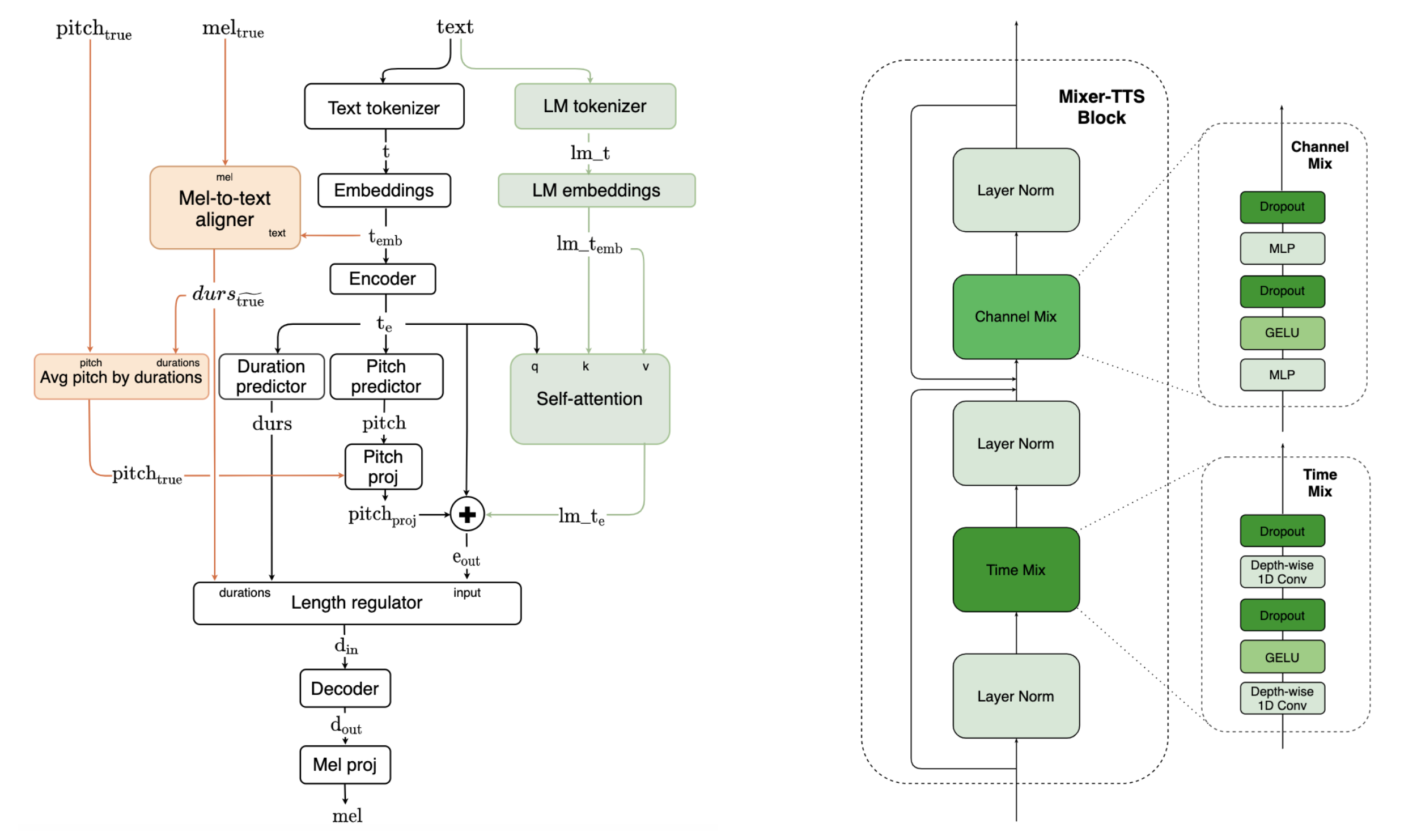
Mixer-TTS is a non-autoregressive model for mel-spectrogram generation. The model is based on MLP-Mixer architecture adapted for speech synthesis. The basic Mixer-TTS contains pitch and duration predictors, with the latter being trained with supervised TTS alignment framework. Alongside the basic model, we propose the extended version, Mixer-TTS-X, which additionally uses token embeddings from a pre-trained language model. Basic Mixer-TTS and its extended version have a small number of parameters and enable much faster speech synthesis compared to the models with similar quality. The model architectures of basic Mixer-TTS is shown below (left). The basic Mixer-TTS uses the same architectures of duration and pitch predictors as FastPitch, but it has two major changes. It replaces all feed-forward transformer-based blocks in the encoder and decoder with new Mixer-TTS blocks (right); it uses an unsupervised speech-to-text alignment framework to train the duration predictor. Please refer to [TTS-MODELS10] for details.
RAD-TTS#
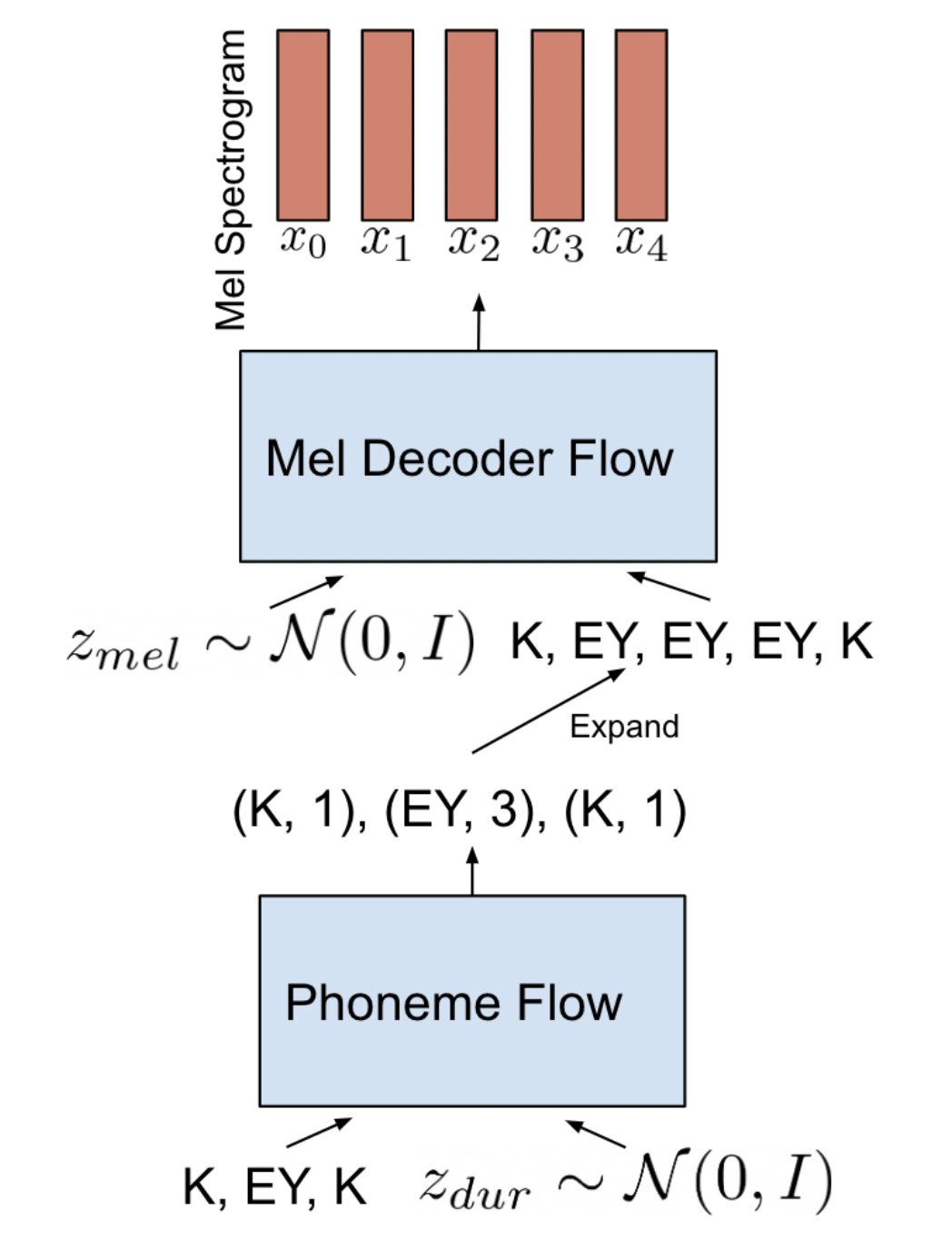
RAD-TTS introduces a predominantly parallel, end-to-end TTS model based on normalizing flows. It extends prior parallel approaches by additionally modeling speech rhythm as a separate generative distribution to facilitate variable token duration during inference. RAD-TTS further designs a robust framework for the on-line extraction of speech-text alignments, which is a critical yet highly unstable learning problem in end-to-end TTS frameworks. Overall, RAD-TTS yields improved alignment quality, better output diversity compared to controlled baselines. The following diagrams summarizes the inference pipeline for RAD-TTS. The duration normalizing flow first samples the phoneme durations which are then used to prepare the input to the parallel Mel-Decoder flow. Please refer to [TTS-MODELS9] for details.
Tacotron2#
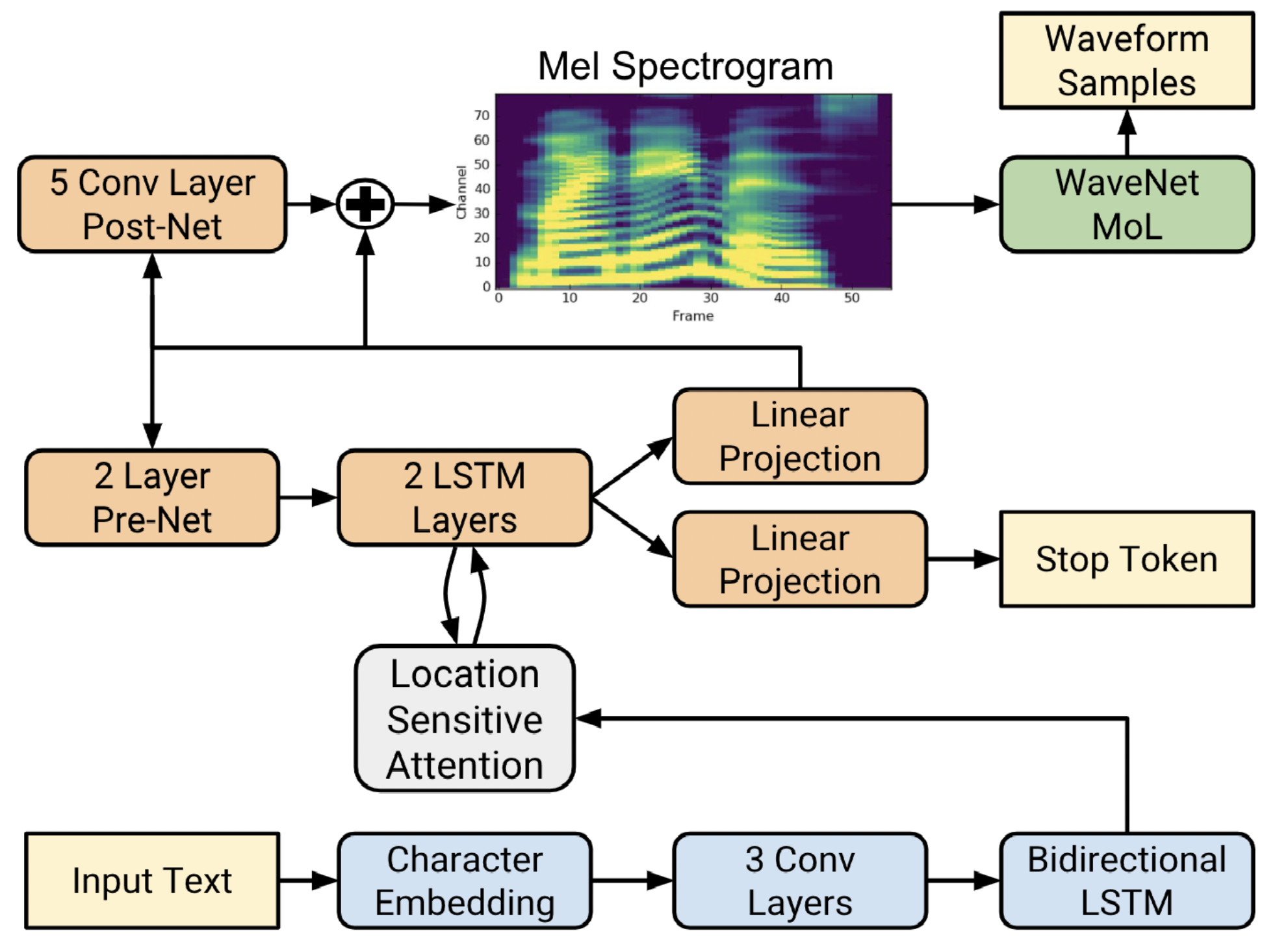
Tacotron 2 consists of a recurrent sequence-to-sequence feature prediction network with attention that maps character embeddings to mel-spectrogram frames, and a modified version of WaveNet as a vocoder that generate time-domain waveform samples conditioned on the predicted mel-spectrogram frames. This system uses mel-spectrograms as the conditioning input to WaveNet instead of linguistic, duration, and F0 features, which shows a significant reduction in the size of the WaveNet architecture. The block diagram of the Tacotron 2 architecture is shown below. Please refer to [TTS-MODELS8] for details.
SSL FastPitch#
This experimental version of FastPitch takes in content and speaker embeddings generated by an SSL Disentangler and generates mel-spectrograms, with the goal that voice characteristics are taken from the speaker embedding while the content of speech is determined by the content embedding. Voice conversion can be done using this model by swapping the speaker embedding input to that of a target speaker, while keeping the content embedding the same. More details to come.
Vocoders#
HiFiGAN#
HiFi-GAN focuses on designing a vocoder model that efficiently synthesizes raw waveform audios from the intermediate mel-spectrograms. It consists of one generator and two discriminators (multi-scale and multi-period). The generator and discriminators are trained adversarially with two additional loses for improving training stability and model performance. The generator is a fully convolutional neural network which takes a mel-spectrogram as input and upsamples it through transposed convolutions until the length of the output sequence matches the temporal resolution of raw waveforms. Every transposed convolution is followed by a multi-receptive field fusion (MRF) module. The architecture of the generator is shown below (left). Multi-period discriminator (MPD) is a mixer of sub-discriminators, each of which only accepts equally spaced samples of an input audio. The sub-discriminators are designed to capture different implicit structures from each other by looking at different parts of an input audio. While MPD only accepts disjoint samples, multi-scale discriminator (MSD) is added to consecutively evaluate the audio sequence. MSD is a mixer of 3 sub-discriminators operating on different input scales (raw audio, x2 average-pooled audio, and x4 average-pooled audio). HiFi-GAN could achieve both higher computational efficiency and sample quality than the best publicly available auto-regressive or flow-based models, such as WaveNet and WaveGlow. Please refer to [TTS-MODELS5] for details.
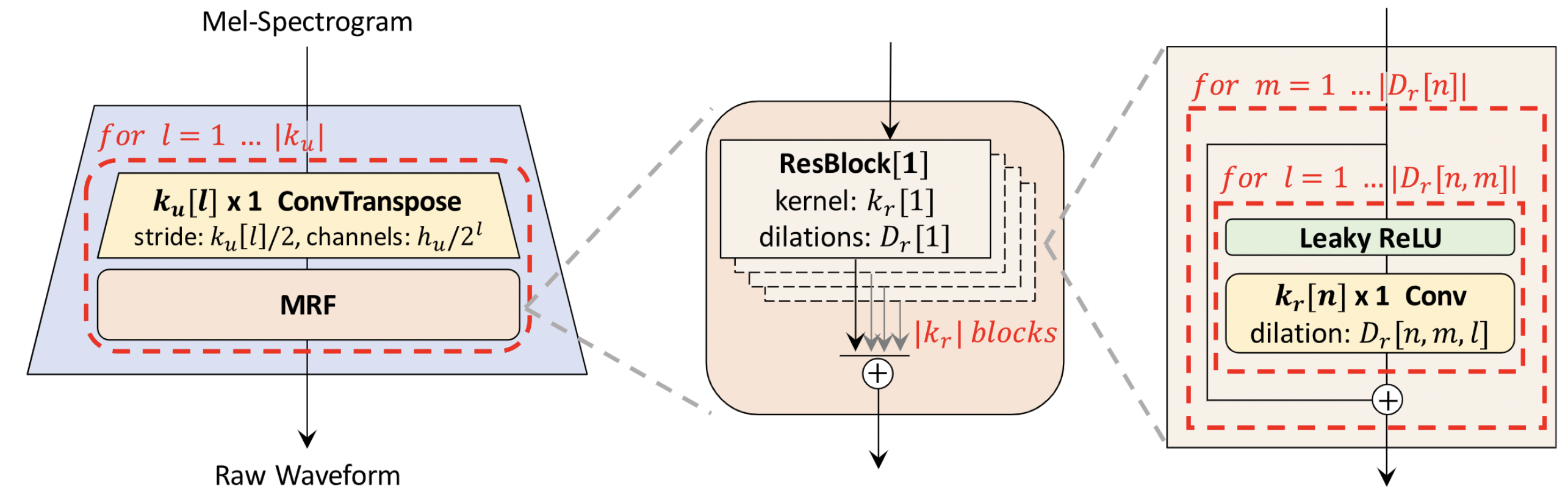
Generator
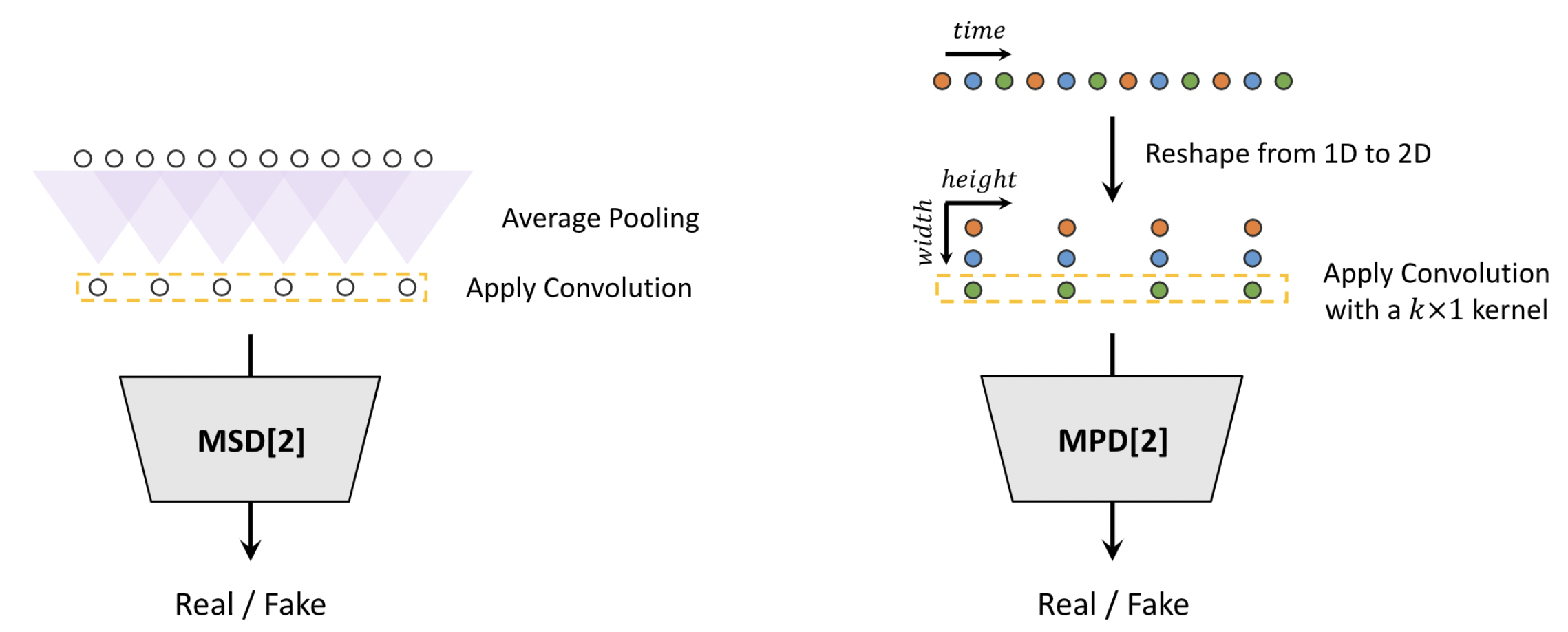
Discriminators
UnivNet#
UnivNet is a neural vocoder that synthesizes high-fidelity waveforms in real time. It consists of a generator and two waveform discriminators (multi-period and multi-resolution). The generator is inspired by MelGAN, and adds a location-variable convolution (LVC) to efficiently capture the local information of the log-mel-spectrogram. The kernels of the LVC layers are predicted using a kernel predictor that takes as input the log-mel-spectrograms. The architecture of the generator is shown below (left). Multi-resolution spectrogram discriminator (MRSD) uses multiple linear spectrogram magnitudes with various temporal and spectral resolutions so that generating high-resolution signals over the full-band is possible. Multi-period waveform discriminator (MPWD) is added to improve detailed adversarial modeling in temporal domain. The architecture of the discriminators is shown below (right). Please refer to [TTS-MODELS3] for details.
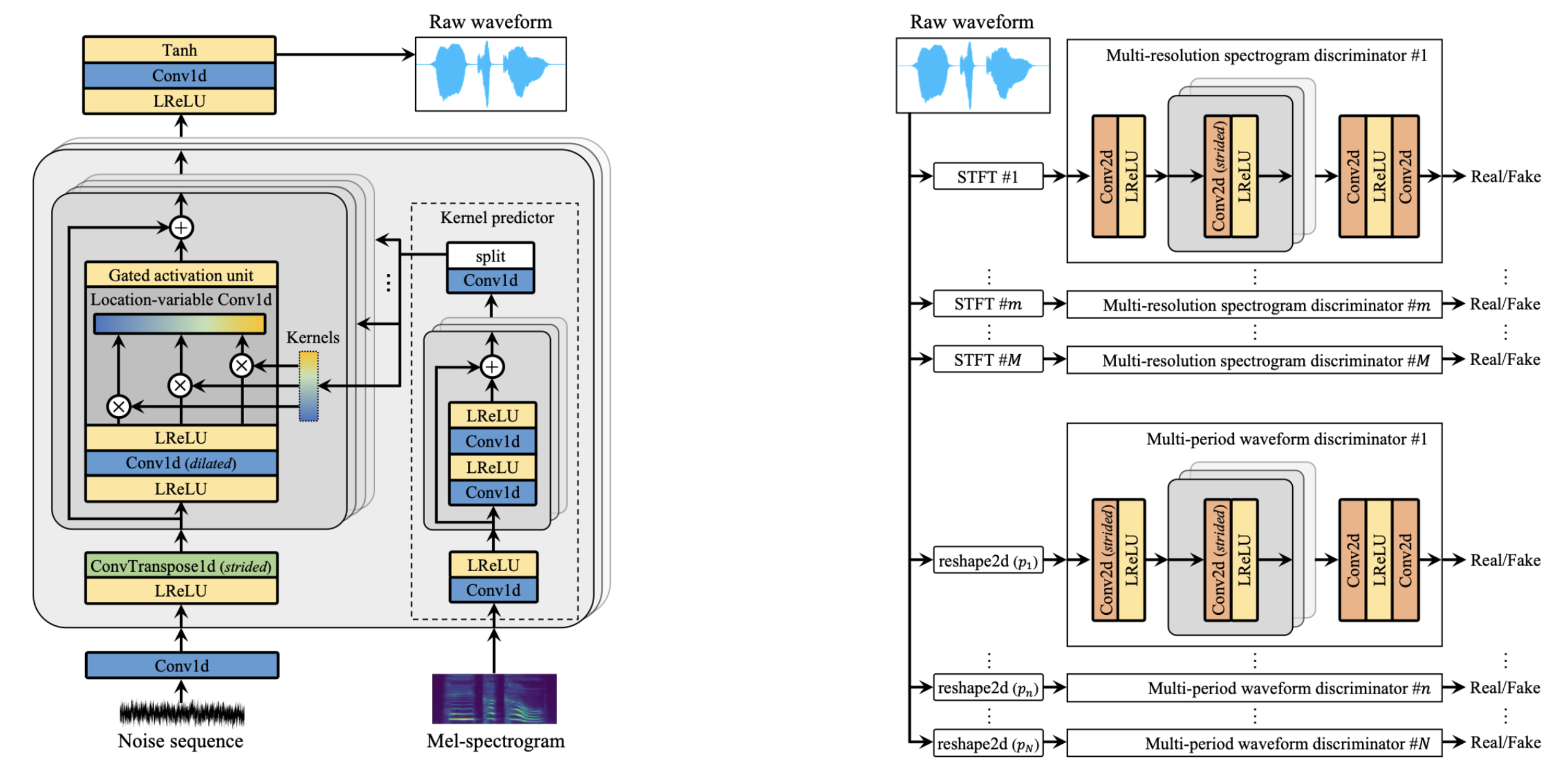
WaveGlow#
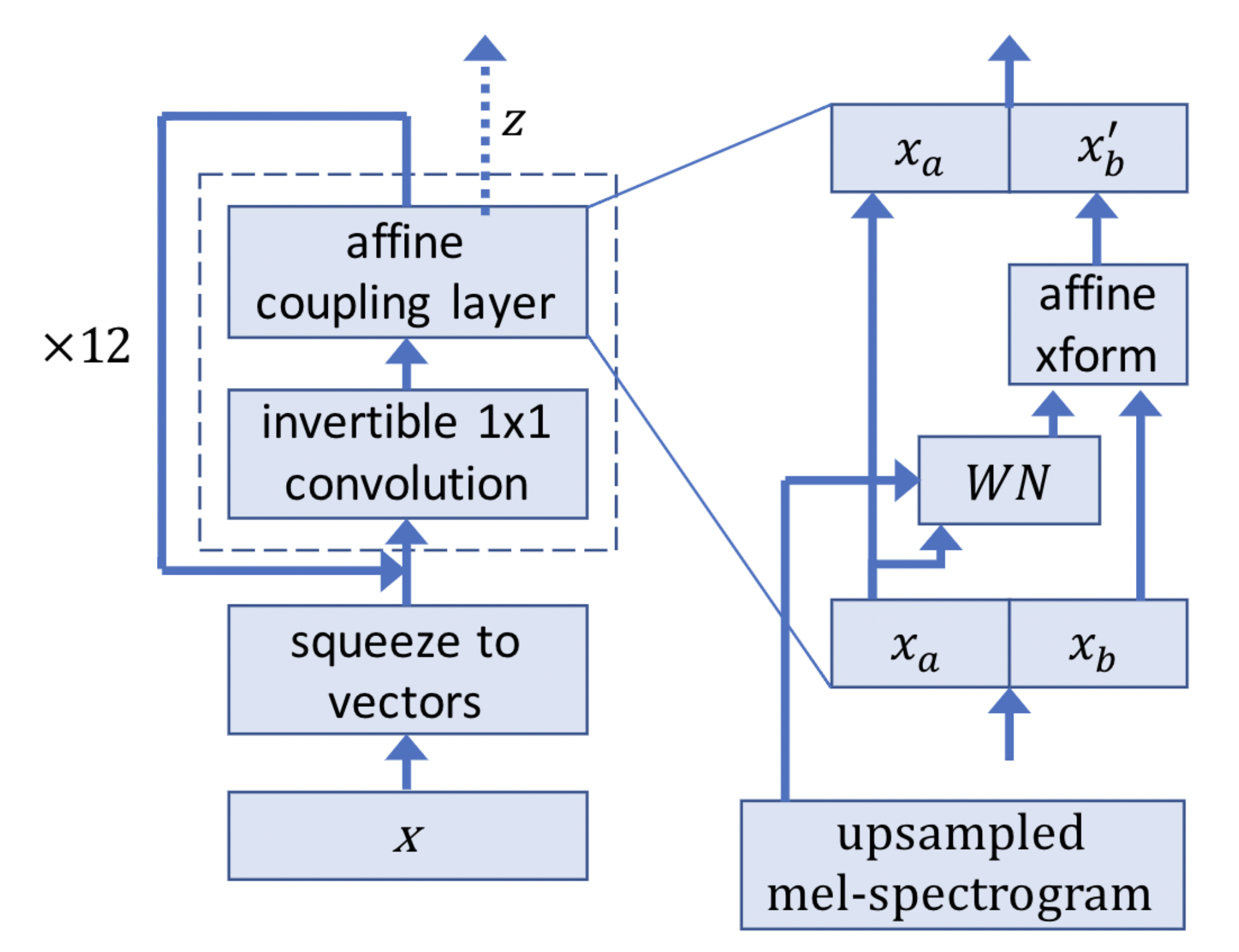
WaveGlow combines insights from Glow and WaveNet to provide fast, efficient and high quality audio synthesis without the need for auto-regression. WaveGlow is implemented using only a single network, trained using only a single cost function, i.e. maximizing the likelihood of the training data, which makes the training procedure simple and stable. Despite the simplicity of the model, our Pytorch implementation could synthesizes speech at more than 500kHz on an NVIDIA V100 GPU, and its audio quality is as good as the best publicly available WaveNet implementation trained on the same data. The model network is most similar to the recent Glow work as shown below. For the forward pass through the network, we take groups of 8 audio samples as vectors, which is called as “squeeze” operation. We then process these vectors through several “steps of flow”, each of which consists of an invertible 1x1 convolution followed by an affine coupling layer. Please refer to [TTS-MODELS7] for details.
Speech-to-Text Aligners#
RAD-TTS Aligner#
Speech-to-text alignment is a critical component of neural TTS models. Autoregressive TTS models typically use an attention mechanism to learn these alignments on-line. However, these alignments tend to be brittle and often fail to generalize to long utterances and out-of-domain text, leading to missing or repeating words. Most non-autoregressive end-to-end TTS models rely on durations extracted from external sources. RAD-TTS Aligner leverages the alignment mechanism proposed in RAD-TTS and demonstrates its applicability to wide variety of neural TTS models. The alignment learning framework combines the forward-sum algorithm, Viterbi algorithm, and an efficient static prior. RAD-TTS Aligner can improve all tested TTS architectures, both autoregressive (Flowtron, Tacotron 2) and non-autoregressive (FastPitch, FastSpeech 2, RAD-TTS). Specifically, it improves alignment convergence speed, simplifies the training pipeline by eliminating need for external aligners, enhances robustness to errors on long utterances and improves the perceived speech synthesis quality, as judged by human evaluators. The alignment framework is shown below. Please refer to [TTS-MODELS1] for details.
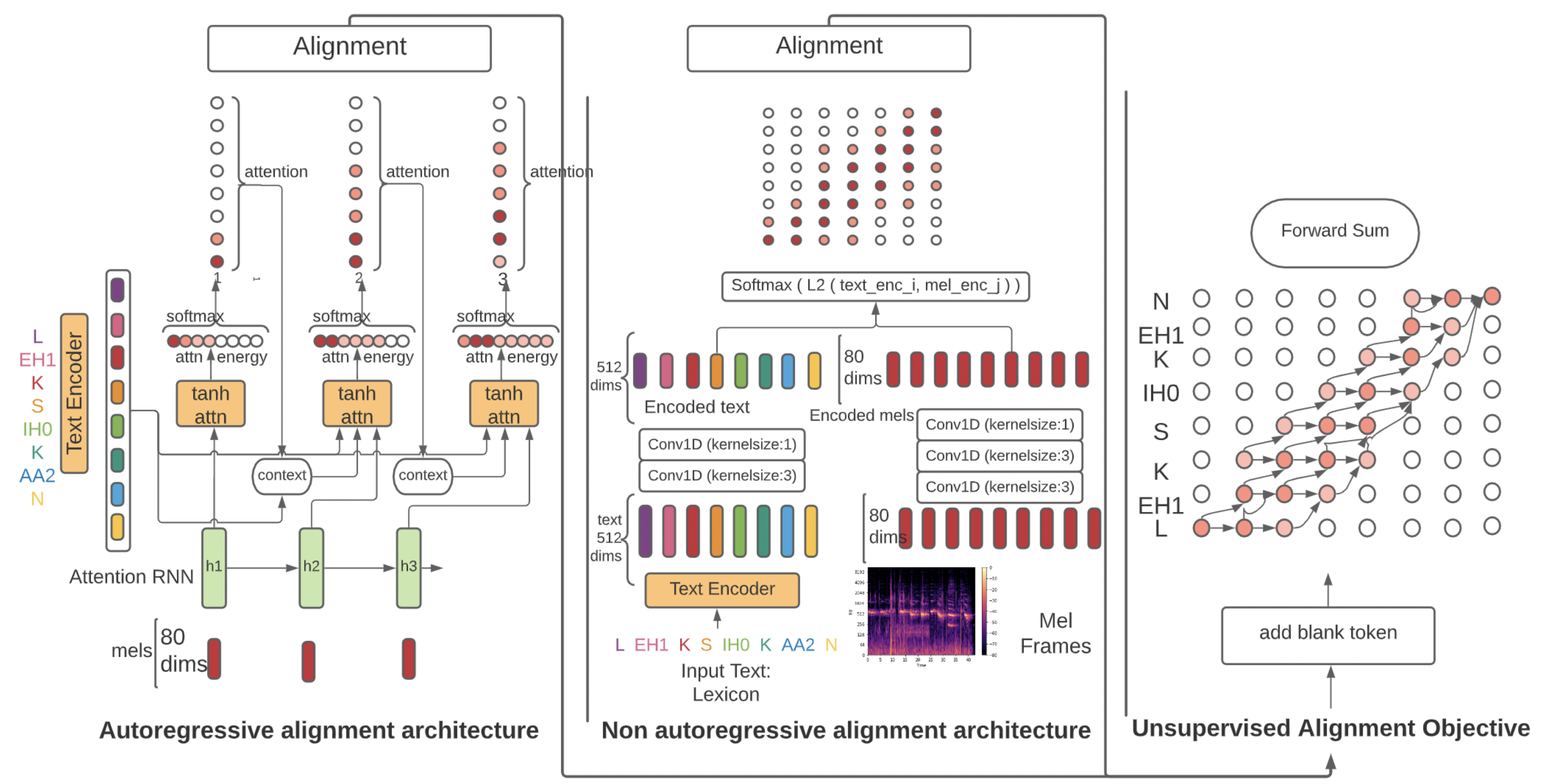
End2End Models#
VITS#
VITS is an end-to-end speech synthesis model, which generates raw waveform audios from grapheme/phoneme input. It uses Variational Autoencoder to combine GlowTTS-like spectrogram generator with HiFi-GAN vocoder model. Also, it has separate flow-based duration predictor, which samples alignments from noise with conditioning on text. Please refer to [TTS-MODELS4] for details. The model is experimental yet, so we do not guarantee clean running.
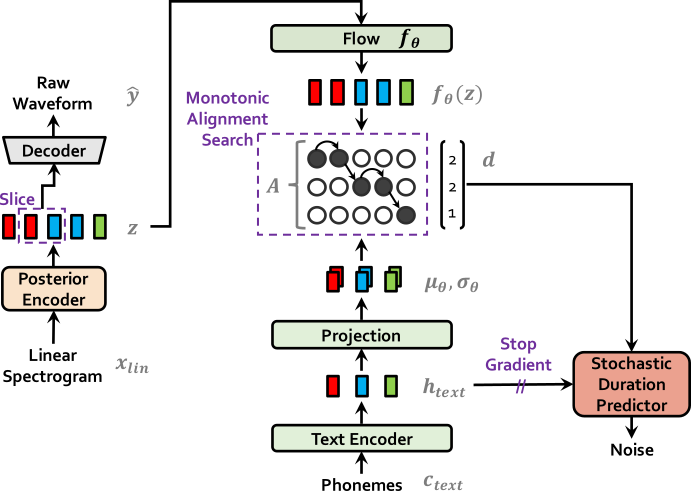
Enhancers#
Spectrogram Enhancer#
GAN-based model to add details to blurry spectrograms from TTS models like Tacotron or FastPitch.
Codecs#
Audio Codec#
The NeMo Audio Codec model is a non-autoregressive convolutional encoder-quantizer-decoder model for coding or tokenization of raw audio signals or mel-spectrogram features.
The NeMo Audio Codec model supports residual vector quantizer (RVQ) [TTS-MODELS11] and finite scalar quantizer (FSQ) [TTS-MODELS6] for quantization of the encoder output.
This model is trained end-to-end using generative loss, discriminative loss, and reconstruction loss, similar to other neural audio codecs such as SoundStream [TTS-MODELS11] and EnCodec [TTS-MODELS2].
For further information refer to the Audio Codec Training tutorial in the TTS tutorial section.
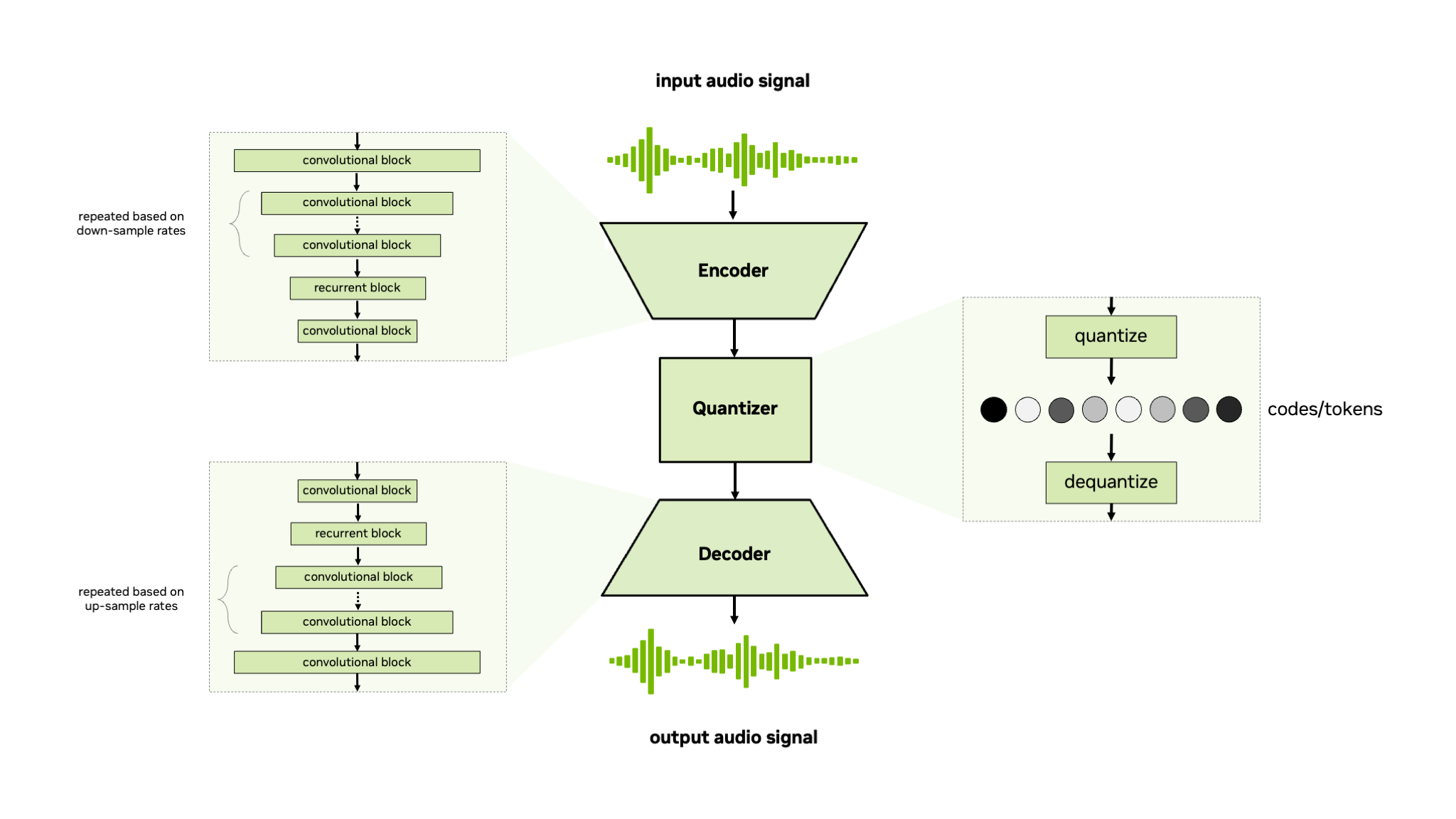
References#
Rohan Badlani, Adrian Łańcucki, Kevin J Shih, Rafael Valle, Wei Ping, and Bryan Catanzaro. One TTS alignment to rule them all. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6092–6096. IEEE, 2022.
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022.
Won Jang, Dan Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim. UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. In Proc. Interspeech 2021, 2207–2211. 2021. doi:10.21437/Interspeech.2021-1016.
Jaehyeon Kim, Jungil Kong, and Juhee Son. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In International Conference on Machine Learning, 5530–5540. PMLR, 2021.
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis. Advances in Neural Information Processing Systems, 33:17022–17033, 2020.
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: VQ-VAE made simple. arXiv preprint arXiv:2309.15505, 2023.
Ryan Prenger, Rafael Valle, and Bryan Catanzaro. Waveglow: a flow-based generative network for speech synthesis. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 3617–3621. IEEE, 2019.
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, and others. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), 4779–4783. IEEE, 2018.
Kevin J Shih, Rafael Valle, Rohan Badlani, Adrian Lancucki, Wei Ping, and Bryan Catanzaro. RAD-TTS: parallel flow-based TTS with robust alignment learning and diverse synthesis. In ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models. 2021.
Oktai Tatanov, Stanislav Beliaev, and Boris Ginsburg. Mixer-TTS: non-autoregressive, fast and compact text-to-speech model conditioned on language model embeddings. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7482–7486. IEEE, 2022.
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. SoundStream: an end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507, 2022. doi:10.1109/TASLP.2021.3129994.
Adrian Łańcucki. Fastpitch: parallel text-to-speech with pitch prediction. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6588–6592. IEEE, 2021.