Example With MCV#
Kinyarwanda ASR using Mozilla Common Voice Dataset#
In this example, we describe essential steps of training an ASR model for a new language (Kinyarwanda). Namely,
Data preprocessing
Building tokenizers
Tarred datasets and bucketing
Training from scratch and finetuning
Inference and evaluation
Kinyarwanda Speech Dataset#
We use Mozilla Common Voice dataset for Kinyarwanda which is a large dataset with 2000+ hours of audio data.
Note: You should download this dataset by yourself.
Mozilla distributes the dataset in tsv+mp3 format. After downloading and unpacking, the dataset has the following structure
├── cv-corpus-9.0-2022-04-27
│ └── rw
│ ├── clips [here are all audio files, e.g. common_voice_rw_26260276.mp3]
│ ├── dev.tsv
│ ├── invalidated.tsv
│ ├── other.tsv
│ ├── reported.tsv
│ ├── test.tsv
│ ├── train.tsv
│ └── validated.tsv
Mozilla provides train/dev/test split of the data, so we can just use it. Let’s look at the format of a .tsv file
head train.tsv
client_id path sentence up_votes down_votes age gender accents locale segment
e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a common_voice_rw_26273273.mp3 kandi tuguwe neza kugira ngo twakire amagambo y’ukuri, 2 0 twenties male rw
e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a common_voice_rw_26273478.mp3 Simbi na we akajya kwiga nubwo byari bigoye 2 0 twenties male rw
e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a common_voice_rw_26273483.mp3 Inshuti yanjye yaje kunsura ku biro byanjye. 2 0 twenties male rw
e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a common_voice_rw_26273488.mp3 Grand Canyon ni ahantu hazwi cyane ba mukerarugendo. 2 0 twenties male rw
Each line corresponds to one record (usually one sentence) and contains:
name of the audio file
corresponding transcription
meta information: client_id, age, gender, etc.
Resampling and creating manifests#
To be able to use a dataset with NeMo Toolkit, we first need to
Convert .tsv files to .json manifests
Convert .mp3 files to .wav with sample rate of 16000
To convert a .tsv file to .json manifest, we used the following script
python tsv_to_json.py \
--tsv=cv-corpus-9.0-2022-04-27/rw/train.tsv \
--folder=cv-corpus-9.0-2022-04-27/rw/clips \
--sampling_count=-1
tsv_to_json.py:
import pandas as pd
import json
import tqdm
import argparse
parser = argparse.ArgumentParser("MCV TSV-to-JSON converter")
parser.add_argument("--tsv", required=True, type=str, help="Input TSV file")
parser.add_argument("--sampling_count", required=True, type=int, help="Number of examples, you want, use -1 for all examples")
parser.add_argument("--folder", required=True, type=str, help="Relative path to folder with audio files")
args = parser.parse_args()
df = pd.read_csv(args.tsv, sep='\t')
with open(args.tsv.replace('.tsv', '.json'), 'w') as fo:
mod = 1
if args.sampling_count > 0:
mod = len(df) // args.sampling_count
for idx in tqdm.tqdm(range(len(df))):
if idx % mod != 0:
continue
item = {
'audio_filepath': args.folder + "/" + df['path'][idx],
'text': df['sentence'][idx],
'up_votes': int(df['up_votes'][idx]), 'down_votes': int(df['down_votes'][idx]),
'age': df['age'][idx], 'gender': df['gender'][idx], 'accents': df['accents'][idx],
'client_id': df['client_id'][idx]
}
fo.write(json.dumps(item) + "\n")
This script will create a corresponding train.json manifest near the initial train.tsv. It will look like this:
{"audio_filepath": "cv-corpus-9.0-2022-04-27/rw/clips/common_voice_rw_26273273.mp3", "text": "kandi tuguwe neza kugira ngo twakire amagambo y\u2019ukuri,", "up_votes": 2, "down_votes": 0, "age": "twenties", "gender": "male", "accents": NaN, "client_id": "e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a"}
{"audio_filepath": "cv-corpus-9.0-2022-04-27/rw/clips/common_voice_rw_26273478.mp3", "text": "Simbi na we akajya kwiga nubwo byari bigoye", "up_votes": 2, "down_votes": 0, "age": "twenties", "gender": "male", "accents": NaN, "client_id": "e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a"}
{"audio_filepath": "cv-corpus-9.0-2022-04-27/rw/clips/common_voice_rw_26273483.mp3", "text": "Inshuti yanjye yaje kunsura ku biro byanjye.", "up_votes": 2, "down_votes": 0, "age": "twenties", "gender": "male", "accents": NaN, "client_id": "e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a"}
{"audio_filepath": "cv-corpus-9.0-2022-04-27/rw/clips/common_voice_rw_26273488.mp3", "text": "Grand Canyon ni ahantu hazwi cyane ba mukerarugendo.", "up_votes": 2, "down_votes": 0, "age": "twenties", "gender": "male", "accents": NaN, "client_id": "e2a04c0ecacf81302f4270a3dddaa7a131420f6b7319208473af17d4adf3724ad9a3b6cdee107e2f321495db86f114a50c396e0928464a58dfad472130e7514a"}
For resampling we used the following script:
mkdir train
python ../decode_resample.py \
--manifest=cv-corpus-9.0-2022-04-27/rw/train.json \
--destination_folder=./train
decode_resample.py:
import argparse
import os
import json
import sox
from sox import Transformer
import tqdm
import multiprocessing
from tqdm.contrib.concurrent import process_map
parser = argparse.ArgumentParser()
parser.add_argument('--manifest', required=True, type=str, help='path to the original manifest')
parser.add_argument("--num_workers", default=multiprocessing.cpu_count(), type=int, help="Workers to process dataset.")
parser.add_argument("--destination_folder", required=True, type=str, help="Destination folder where audio files will be stored")
args = parser.parse_args()
def process(x):
if not isinstance(x['text'], str):
x['text'] = ''
else:
x['text'] = x['text'].lower().strip()
_, file_with_ext = os.path.split(x['audio_filepath'])
name, ext = os.path.splitext(file_with_ext)
output_wav_path = args.destination_folder + "/" + name + '.wav'
if not os.path.exists(output_wav_path):
tfm = Transformer()
tfm.rate(samplerate=16000)
tfm.channels(n_channels=1)
tfm.build(input_filepath=x['audio_filepath'],
output_filepath=output_wav_path)
x['duration'] = sox.file_info.duration(output_wav_path)
x['audio_filepath'] = output_wav_path
return x
def load_data(manifest):
data = []
with open(manifest, 'r') as f:
for line in tqdm.tqdm(f):
item = json.loads(line)
data.append(item)
return data
data = load_data(args.manifest)
data_new = process_map(process, data, max_workers=args.num_workers, chunksize=100)
with open(args.manifest.replace('.json', '_decoded.json'), 'w') as f:
for item in tqdm.tqdm(data_new):
f.write(json.dumps(item) + '\n')
It will write the resampled .wav-files to the specified directory and save a new json manifest with corrected audiopaths.
Note: You need to repeat these steps for test.tsv and dev.tsv as well.
Data Preprocessing#
Before we start training the model on the above manifest files, we need to preprocess the text data. Data pre-processing is done to reduce ambiguity in transcripts. This is an essential step, and often requires moderate expertise in the language.
We used the following script prepare_dataset_kinyarwanda.py:
import json
import os
import re
from collections import defaultdict
from nemo.collections.asr.parts.utils.manifest_utils import read_manifest, write_manifest
from tqdm.auto import tqdm
def write_processed_manifest(data, original_path):
original_manifest_name = os.path.basename(original_path)
new_manifest_name = original_manifest_name.replace(".json", "_processed.json")
manifest_dir = os.path.split(original_path)[0]
filepath = os.path.join(manifest_dir, new_manifest_name)
write_manifest(filepath, data)
print(f"Finished writing manifest: {filepath}")
return filepath
# calculate the character set
def get_charset(manifest_data):
charset = defaultdict(int)
for row in tqdm(manifest_data, desc="Computing character set"):
text = row['text']
for character in text:
charset[character] += 1
return charset
# Preprocessing steps
def remove_special_characters(data):
chars_to_ignore_regex = "[\.\,\?\:\-!;()«»…\]\[/\*–‽+&_\\½√>€™$•¼}{~—=“\"”″‟„]"
apostrophes_regex = "[’'‘`ʽ']"
data["text"] = re.sub(chars_to_ignore_regex, " ", data["text"]) # replace punctuation by space
data["text"] = re.sub(apostrophes_regex, "'", data["text"]) # replace different apostrophes by one
data["text"] = re.sub(r"'+", "'", data["text"]) # merge multiple apostrophes
# remove spaces where apostrophe marks a deleted vowel
# this rule is taken from https://huggingface.co/lucio/wav2vec2-large-xlsr-kinyarwanda-apostrophied
data["text"] = re.sub(r"([b-df-hj-np-tv-z])' ([aeiou])", r"\1'\2", data["text"])
data["text"] = re.sub(r" '", " ", data["text"]) # delete apostrophes at the beginning of word
data["text"] = re.sub(r"' ", " ", data["text"]) # delete apostrophes at the end of word
data["text"] = re.sub(r" +", " ", data["text"]) # merge multiple spaces
return data
def replace_diacritics(data):
data["text"] = re.sub(r"[éèëēê]", "e", data["text"])
data["text"] = re.sub(r"[ãâāá]", "a", data["text"])
data["text"] = re.sub(r"[úūü]", "u", data["text"])
data["text"] = re.sub(r"[ôōó]", "o", data["text"])
data["text"] = re.sub(r"[ćç]", "c", data["text"])
data["text"] = re.sub(r"[ïī]", "i", data["text"])
data["text"] = re.sub(r"[ñ]", "n", data["text"])
return data
def remove_oov_characters(data):
oov_regex = "[^ 'aiuenrbomkygwthszdcjfvplxq]"
data["text"] = re.sub(oov_regex, "", data["text"]) # delete oov characters
data["text"] = data["text"].strip()
return data
# Processing pipeline
def apply_preprocessors(manifest, preprocessors):
for processor in preprocessors:
for idx in tqdm(range(len(manifest)), desc=f"Applying {processor.__name__}"):
manifest[idx] = processor(manifest[idx])
print("Finished processing manifest !")
return manifest
# List of pre-processing functions
PREPROCESSORS = [
remove_special_characters,
replace_diacritics,
remove_oov_characters,
]
train_manifest = "train_decoded.json"
dev_manifest = "dev_decoded.json"
test_manifest = "test_decoded.json"
train_data = read_manifest(train_manifest)
dev_data = read_manifest(dev_manifest)
test_data = read_manifest(test_manifest)
# Apply preprocessing
train_data_processed = apply_preprocessors(train_data, PREPROCESSORS)
dev_data_processed = apply_preprocessors(dev_data, PREPROCESSORS)
test_data_processed = apply_preprocessors(test_data, PREPROCESSORS)
# Write new manifests
train_manifest_cleaned = write_processed_manifest(train_data_processed, train_manifest)
dev_manifest_cleaned = write_processed_manifest(dev_data_processed, dev_manifest)
test_manifest_cleaned = write_processed_manifest(test_data_processed, test_manifest)
It performs the following operations:
Remove all punctuation except for apostrophes
Replace different kinds of apostrophes by one
Lowercase
Replace rare characters with diacritics (e.g. [éèëēê] => e)
Delete all remaining out-of-vocabulary (OOV) characters
The final Kinyarwanda alphabet in all trancripts consists of Latin letters, space and apostrophe.
Building Tokenizers#
Though it is possible to train character-based ASR model, usually we get some improvement in quality and speed if we predict longer units. The commonly used tokenization algorithm is called Byte-pair encoding. This is a deterministic tokenization algorithm based on corpus statistics. It splits the words to subtokens and the beginning of word is marked by special symbol so it’s easy to restore the original words. NeMo toolkit supports on-the-fly subword tokenization, so you need not modify the transcripts, but need to pass your tokenizer via the model config. NeMo supports both Word Piece Tokenizer (via HuggingFace) and Sentence Piece Tokenizer (via Google SentencePiece library) For Kinyarwanda experiments we used 128 subtokens for the CTC model and 1024 subtokens for the Transducer model. The tokenizers for these models were built using the text transcripts of the train set with this script. For vocabulary of size 1024 we restrict maximum subtoken length to 4 symbols (2 symbols for size 128) to avoid populating vocabulary with specific frequent words from the dataset. This does not affect the model performance and potentially helps to adapt to other domain without retraining tokenizer. We used the following script from NeMo toolkit to create Sentencepiece tokenizers with different vocabulary sizes (128 and 1024 subtokens)
python ${NEMO_ROOT}/scripts/tokenizers/process_asr_text_tokenizer.py \
--manifest=dev_decoded_processed.json,train_decoded_processed.json \
--vocab_size=1024 \
--data_root=tokenizer_bpe_maxlen_4 \
--tokenizer="spe" \
--spe_type=bpe \
--spe_character_coverage=1.0 \
--spe_max_sentencepiece_length=4 \
--log
python ${NEMO_ROOT}/scripts/tokenizers/process_asr_text_tokenizer.py \
--manifest=dev_decoded_processed.json,train_decoded_processed.json \
--vocab_size=128 \
--data_root=tokenizer_bpe_maxlen_2 \
--tokenizer="spe" \
--spe_type=bpe \
--spe_character_coverage=1.0 \
--spe_max_sentencepiece_length=2 \
--log
Most of the arguments are similar to those explained in the ASR with Subword Tokenization tutorial.
The resulting tokenizer is a folder like that:
├── tokenizer_spe_bpe_v1024_max_4
│ ├── tokenizer.model
│ ├── tokenizer.vocab
│ └── vocab.txt
Remember that you will need to pass the path to tokenizer in the model config. You can see all the subtokens in the vocab.txt file.
Tarred datasets and bucketing#
There are two useful techniques for training on large datasets.
Tarred dataset allows to store the dataset as large .tar files instead of small separate audio files. It speeds up the training and minimizes the load on the network in the cluster.
Bucketing groups utterances with similar duration. It reduces padding and speeds up the training.
The NeMo toolkit provides a script to implement both of these techniques.
## create tarred dataset with 1 bucket
python ${NEMO_ROOT}/scripts/speech_recognition/convert_to_tarred_audio_dataset.py \
--manifest_path=train_decoded_processed.json \
--target_dir=train_tarred_1bk \
--num_shards=1024 \
--max_duration=11.0 \
--min_duration=1.0 \
--shuffle \
--shuffle_seed=1 \
--sort_in_shards \
--workers=-1
## create tarred dataset with 4 buckets
python ${NEMO_ROOT}/scripts/speech_recognition/convert_to_tarred_audio_dataset.py \
--manifest_path=train_decoded_processed.json \
--target_dir=train_tarred_4bk \
--num_shards=1024 \
--max_duration=11.0 \
--min_duration=1.0 \
--shuffle \
--shuffle_seed=1 \
--sort_in_shards \
--workers=-1 \
--buckets_num=4
Note: we only need to process train data, dev and test are usually much smaller and can be used as is.
Our final dataset folder looks like this:
├── dev [15988 .wav files]
├── dev_decoded_processed.json (dev manifest)
├── test [16213 .wav files]
├── test_decoded_processed.json (test manifest)
└── train_tarred_1bk
├── metadata.yaml
├── tarred_audio_manifest.json
└── [1024 .tar files]
In case of 4 buckets it will look like:
└── train_tarred_4bk
├── bucket1
├── metadata.yaml
├── tarred_audio_manifest.json
└── [1024 .tar files]
├── bucket2
...
├── bucket3
└── bucket4
Training from scratch and finetuning#
ASR models#
Our goal was to train two ASR models with different architectures: Conformer-CTC and Conformer-Transducer, with around 120 million parameters. The CTC model predicts output tokens for each timestep. The outputs are assumed to be independent of each other. As a result the CTC models work faster but they can produce outputs that are inconsistent with each other. CTC models are often combined with external language models in production. In contrast, the Transducer models contain the decoding part which generates the output tokens one by one and the next token prediction depends on this history. Due to autoregressive nature of decoding the inference speed is several times slower than that of CTC models, but the quality is usually better because it can incorporate language model information within the same model.
Training scripts and configs#
To train a Conformer-CTC model, we use speech_to_text_ctc_bpe.py with the default config conformer_ctc_bpe.yaml. To train a Conformer-Transducer model, we use speech_to_text_rnnt_bpe.py with the default config conformer_transducer_bpe.yaml. Any options of default config can be overwritten from command line. Usually we should provide the options related to the dataset and tokenizer.
This is an example of how we can run the training script:
TOKENIZER=tokenizers/tokenizer_spe_bpe_v1024_max_4/
TRAIN_MANIFEST=data/train_tarred_1bk/tarred_audio_manifest.json
TRAIN_FILEPATHS=data/train_tarred_1bk/audio__OP_0..1023_CL_.tar
VAL_MANIFEST=data/dev_decoded_processed.json
TEST_MANIFEST=data/test_decoded_processed.json
python ${NEMO_ROOT}/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py \
--config-path=../conf/conformer/ \
--config-name=conformer_ctc_bpe \
exp_manager.name="Some name of our experiment" \
exp_manager.resume_if_exists=true \
exp_manager.resume_ignore_no_checkpoint=true \
exp_manager.exp_dir=results/ \
model.tokenizer.dir=$TOKENIZER \
model.train_ds.is_tarred=true \
model.train_ds.tarred_audio_filepaths=$TRAIN_FILEPATHS \
model.train_ds.manifest_filepath=$TRAIN_MANIFEST \
model.validation_ds.manifest_filepath=$VAL_MANIFEST \
model.test_ds.manifest_filepath=$TEST_MANIFEST
The option exp_manager.resume_if_exists=true allows to resume training. Actually you can stop training at any moment and then continue from the last checkpoint. When the training is finished, the final model will be saved as .nemo file inside the folder that we specified in exp_manager.exp_dir.
Training dynamics#
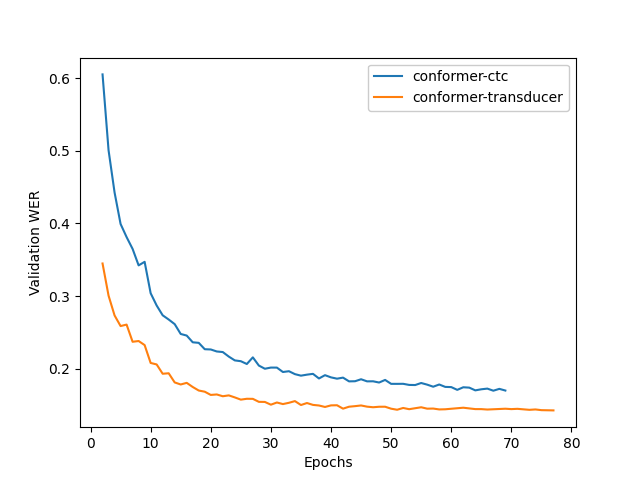
The figure below shows the training dynamics when we train Kinyarwanda models from scratch. In these experiments we used the hyperparameters from the default configs, the training was run on 2 nodes with 16 gpus per node, training batch size was 32. We see that Transducer model achieves better quality than CTC.
Finetuning from another model#
Often it’s a good idea to initialize our ASR model with the weights of some other pretrained model, for example, a model for another language. It usually makes our model to converge faster and achieve better quality, especially if the dataset for our target language is small.
Though Kinyarwanda dataset is rather large, we also tried finetuning Kinyarwanda Conformer-Transducer model from different pretrained checkpoints, namely:
English Conformer-Transducer checkpoint
Self-supervised Learning (SSL) checkpoint trained on English data
SSL checkpoint trained on multilingual data
To initialize from non-SSL checkpoint we should simply add the option +init_from_pretrained_model:
INIT_MODEL='stt_en_conformer_ctc_large'
python ${NEMO_ROOT}/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py
...[same options as in the previous example]...
+init_from_pretrained_model=${INIT_MODEL}
In that case the pretrained model stt_en_conformer_ctc_large will be automatically downloaded from NVIDIA GPU Cloud(NGC) and used to initialize weights before training.
To initialize from SSL checkpoint we should edit our training script like the following code:
import nemo.collections.asr as nemo_asr
ssl_model = nemo_asr.models.ssl_models.SpeechEncDecSelfSupervisedModel.from_pretrained(model_name='ssl_en_conformer_large')
# define fine-tune model
asr_model = nemo_asr.models.EncDecCTCModelBPE(cfg=cfg.model, trainer=trainer)
# load ssl checkpoint
asr_model.load_state_dict(ssl_model.state_dict(), strict=False)
del ssl_model
When using finetuning you probably will need to change the some hyperparameters from the default config, especially the learning rate and learning rate policy. In the experiments below we used model.optim.sched.name=CosineAnnealing and model.optim.lr=1e-3.
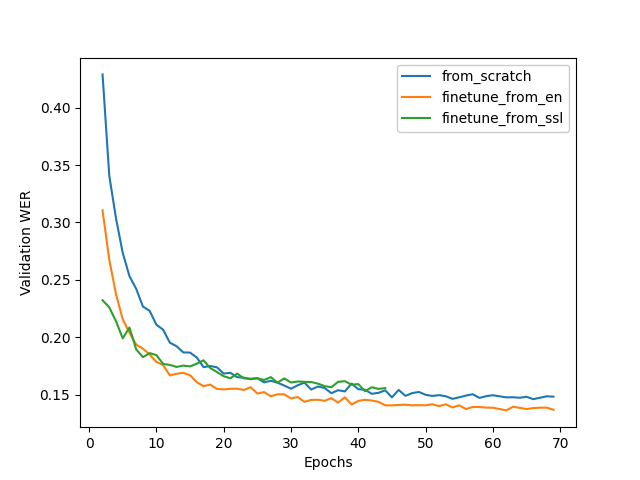
The figure below compares the training dynamics for three Conformer-Transducer models. They differ only by how they are initialized. We see that finetuning leads to faster convergence and better quality. Initializing from SSL gives lowest WER at earlier stages, but in a longer period it performs worse.
Inference and evaluation#
Running the inference#
To run the inference we need a pretrained model. This can be either a .nemo file that we get after the training is finished, or any published ASR model from HF or NGC. We run the inference using the following script:
python ${NEMO_ROOT}/examples/asr/transcribe_speech.py \
model_path=<path_to_of_your_model>.nemo \
dataset_manifest=./test_decoded_processed.json \
output_filename=./test_with_predictions.json \
batch_size=8 \
cuda=1 \
amp=True
To run inference with NVIDIA’s Kinyarwanda checkpoints STT Rw Conformer-CTC Large or STT Rw Conformer-Transducer Large use:
python ${NEMO_ROOT}/examples/asr/transcribe_speech.py \
pretrained_name="stt_rw_conformer_ctc_large" \
dataset_manifest=test_decoded_processed.json \
output_filename=./pred_ctc.json \
batch_size=8 \
cuda=1 \
amp=True
Note: If you want to transcribe new audios, you can pass a folder with audio files using audio_dir parameter instead of dataset_manifest.
After the inference is finished the output_filename is a .json manifest augmented with a new field pred_text containing the resulting transcript. Example:
{"audio_filepath": "test/common_voice_rw_19835615.wav", "text": "kw'ibumoso", "up_votes": 2, "down_votes": 0, "age": NaN, "gender": NaN, "accents": NaN, "client_id": "66675a7003e6baa3e7d4af01bff8324ac3c5f15e7f8918180799dd2928227c791f19e2811f9ec5779a2b06dac1b7a97fa7740dcfe98646ea1b5e106250c260be", "duration": 3.672, "pred_text": "n'ibumoso"}
{"audio_filepath": "test/common_voice_rw_24795878.wav", "text": "ni ryari uheruka kurya urusenda", "up_votes": 2, "down_votes": 0, "age": NaN, "gender": NaN, "accents": NaN, "client_id": "90e0438947a75b6c0cf59a0444aee3b81a76c5f9459c4b22df2e14b4ce257aeacaed8ac6092bfcd75b8e831633d58a84287fd62190c21d70d75efe8d93ed74ed", "duration": 3.312, "pred_text": "ni ryari uheruka kurya urusenda"}
{"audio_filepath": "test/common_voice_rw_24256935.wav", "text": "umunani", "up_votes": 2, "down_votes": 0, "age": NaN, "gender": NaN, "accents": NaN, "client_id": "974d4876e99e7437183c20f9107053acc9e514379d448bcf00aaaabc0927f5380128af86d39650867fa80a82525110dfc40784a5371c989de1a5bdf531f6d943", "duration": 3.24, "pred_text": "umunani"}
Word Error Rate (WER) and Character Error Rate (CER)#
As soon as we have a manifest file with text and pred_text we can measure the quality of predictions of our model.
# Calculate WER
python ${NEMO_ROOT}/examples/asr/speech_to_text_eval.py \
dataset_manifest=test_with_predictions.json \
use_cer=False \
only_score_manifest=True
# Calculate CER
python ${NEMO_ROOT}/examples/asr/speech_to_text_eval.py \
dataset_manifest=test_with_predictions.json \
use_cer=True \
only_score_manifest=True
Evaluation of NVIDIA’s Kinyarwanda checkpoints#
If you run inference and evaluation of NVIDIA’s published Kinyarwanda models, you should get metrics like these:
Model |
WER % |
CER % |
|---|---|---|
stt_rw_conformer_ctc_large |
18.22 |
5.45 |
stt_rw_conformer_trasducer_large |
16.19 |
5.7 |
Error analysis#
Still, even WER of 16% is not as good as we usually get for other languages trained with NeMo toolkit, so we may want to look at the errors that the model makes to better understand what’s the problem.
We can use Speech Data Explorer to analyze the errors.
If we run
python ${NEMO_ROOT}/tools/speech_data_explorer/data_explorer.py <your manifest file>
it will start a local server, and provide a http address to open from the browser. In the UI we can see the model predictions and their diff with the reference, and also we can listen to the corresponding audio. We also can sort the sentences by descending WER and look through the top of them.
The error analysis showed several problems concerning the Kinyarwanda dataset:
Noisy multi-speaker records (e.g. common_voice_rw_19830859.wav)
Bad quality of record (e.g. common_voice_rw_24452415.wav)
- Orthographic variability related to space/no space/apostrophe
kugira ngo / kugirango
nkuko / nk’uko
n iyo / n’iyo
- Multiple orthographic variants for foreign words
telefoni / telephone
film / filime
isiraheli / israel
radio / radiyo
kongo / congo
- l/r variability
abamalayika / abamarayika