Diffusion Training Framework#
Overview#
The NeMo Diffusion Training Framework provides a scalable training platform for diffusion models with transformer backbones. Our new features streamline the training process, allowing developers to efficiently train state-of-the-art models with ease.
Some of the features we currently support include:
Energon Dataloader for Webscale Dataloading
Model and Data Parallelism
Model Architectures: Original Diffusion Transformer (DiT), MovieGen 30B+ parameters, Spatio-Temporal DiT
Performance#
We benchmarked 7B and 28B DiT cross-attention models with context lengths of 8k and 64k on 32 H100 DGX nodes.
8k context length corresponds to a latent representation of 256 frames of 256px video.
64k context length corresponds to a latent representation of 256 frames of 1024px video.
Model size |
Context length |
Training config |
GPU util. (TFLOPS/s) |
Throughput (token/s/GPU) |
|---|---|---|---|---|
DiT 7B |
8k |
baseline, no optimization |
OOM |
|
DiT 7B |
8k |
TP=2 SP |
519 |
10052 |
DiT 7B |
74k |
TP=2 SP CP=4 |
439 |
3409 |
DiT 28B |
8k |
TP4 PP4 |
468 |
2510 |
DiT 28B |
64k |
FSDP act ckpt |
445 |
1386 |
Legend: - FSDP: Fully Sharded Data Parallelism - CP: Context Parallelism - TP: Tensor Parallelism - SP: Sequence Parallelism - PP: Pipeline Parallelism - EP: Expert Parallelism - distop: mcore distributed optmizer - act ckpt: activation checkpointing
Features Status#
We support image/video diffusion training with all parallelism strategies.
Parallelism |
Status |
|---|---|
FSDP |
✅ Supported |
CP+TP+SP+FSDP |
✅ Supported |
CP+TP+SP+distopt |
✅ Supported |
CP+TP+SP+PP+distopt |
✅ Supported |
CP+TP+SP+PP+distopt+EP |
✅ Supported |
CP+TP+SP+FSDP+EP |
✅ Supported |
Training Stages#
Model Size |
Modality |
sequence length |
Status |
|---|---|---|---|
DiT 5B, 30B+ |
256px image |
256 |
✅ Supported |
DiT 5B, 30B+ |
256px image+video |
8k |
✅ Supported |
DiT 5B, 30B+ |
768px image+video |
74k+ |
✅ Supported |
Energon Dataloader for Webscale Dataloading#
Webscale Dataloading#
Megatron-Energon is an optimized multi-modal dataloader for large-scale deep learning with Megatron. Energon allows for distributed loading of large training training data for multi-modal model training. Energon allows for blending many datasets together and distributing the dataloading workflow across multiple cluster nodes/processes while ensuring reproducibility and resumability. You can learn more about how to prepare your own image/video webdataset for diffusion training here <data/readme.rst>_.
Dataloader Checkpointing#
One of Energon’s key features is its ability to save and restore its state. This functionality is crucial for long-running training processes, making the dataloader robust and recoverable after interruptions. By allowing checkpointing of the dataloader status, Energon ensures that training can be resumed from where it left off, saving time and computational resources in case of unexpected shutdowns or planned pauses in the training process. This makes it especially useful for large-scale training as it requires several training jobs for end-to-end training. Parallel Configuration ^^^^^^^^^^^^^^^^^^^^^^
Energon’s architecture allows it to efficiently distribute data across multiple processing units, ensuring that each GPU or node receives a balanced workload. This parallelization not only increases the overall throughput of data processing, but also helps in maintaining high utilization of available computational resources.
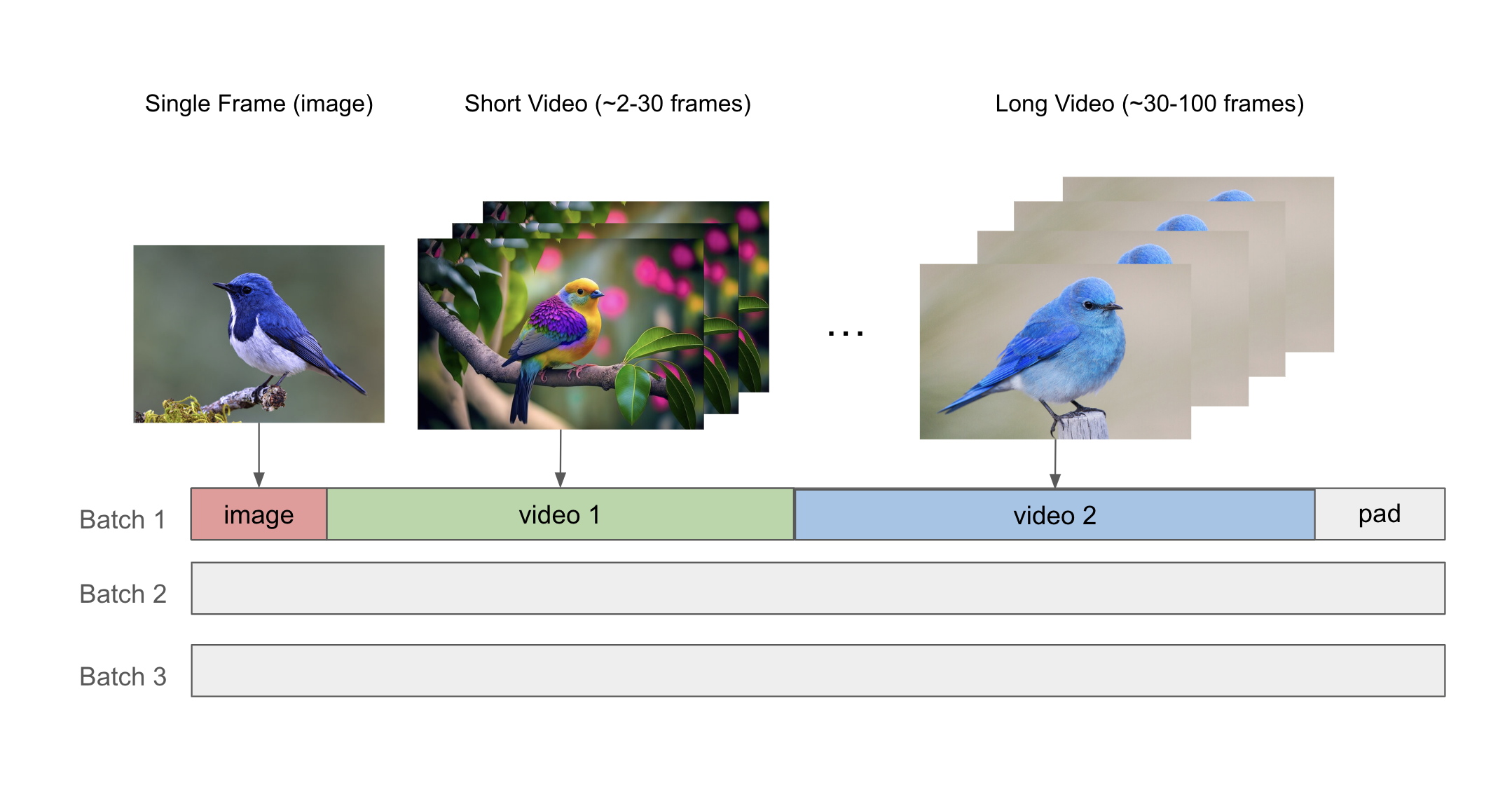
Mixed Image-Video Training#
Our dataloader provides support for mixed image-video training by using the NeMo packed sequence feature to pack together images and videos of varying length into the same microbatch. The sequence packing mechanism uses the THD attention kernel, which allows us to increase the model FLOPs utilization (MFU) and efficiently process data with varying length.
Model and Data Parallelism#
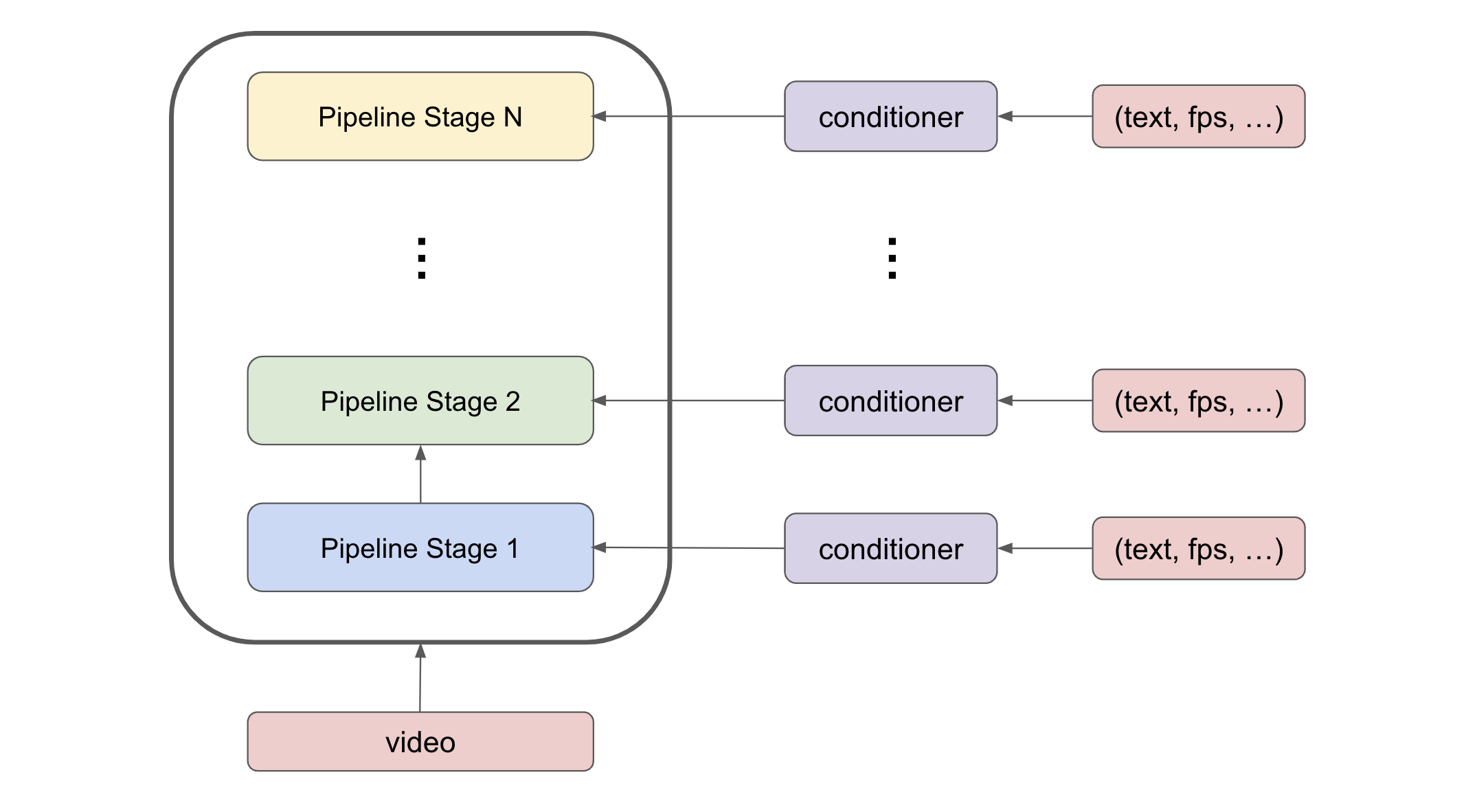
- NeMo provides support for training models using tensor parallelism, sequence parallelism, pipeline parallelism, and context parallelism. To support pipeline parallelism with conditional diffusion training, we duplicate the conditional embeddings across the pipeline stages and perform an all-reduce during the backward pass. This approach uses more compute, but it has a lower communication cost than sending the conditional embeddings through different pipeline stages.
Model Architectures#
DiT#
We implement an efficient version of the Diffusion Transformer (DiT) [1] with several variants to provide users with flexibility in exploring various model architectures.
The current supported architectures include:
DiT adaLN-Zero (original DiT) [1]
DiT adaLN-Zero with Cross attention
MovieGen [2]
Spatio-Temporal DiT (ST-DiT)
In the architectures using DiT adaLN-Zero, we also use a QK-layernorm for training stability for video diffusion training. We also provide an option to use cross-attention with additional conditioning information (i.e. text embeddings) for text-to-video training with the original DiT formulation.
We also support MovieGen [2] training with a Llama-based model architecture that leverages FSDP for large model training (i.e. 30B+ parameters).
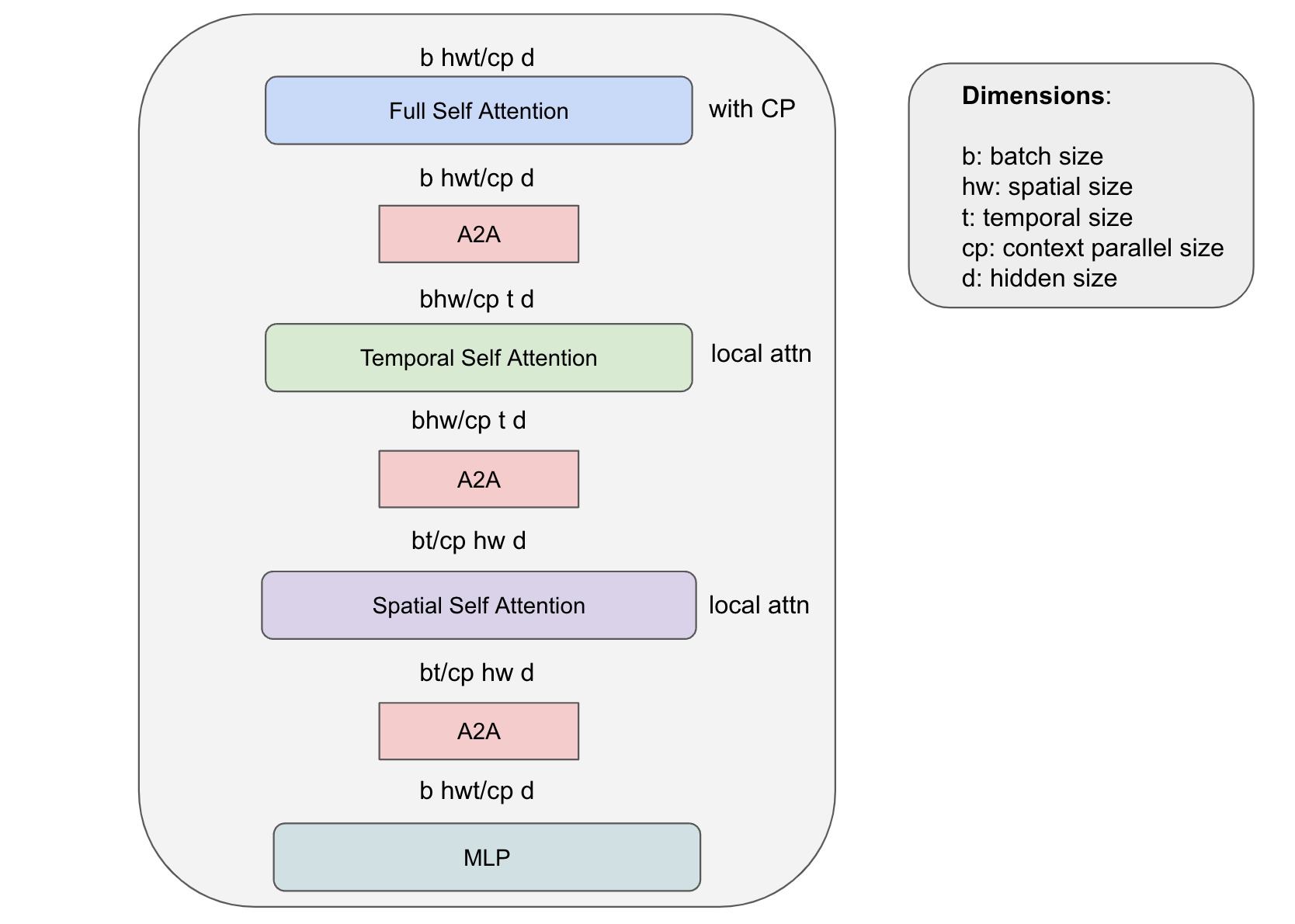
Our framework allows for customizing the DiT architecture while maintaining its scalability, enabling training large DiT models on long sequence lengths. We provide functionality for ST-DiT, which utilizes spatial self attention and temporal self attention blocks operating on the spatial and temporal sequence dimensions, respectively. There are various challenges that emerge with specialized architectures. In the case of ST-DiT, one major challenge is that the spatial and temporal context lengths are much smaller than full input sequence length. This leads to a large communication cost when using CP for a small amount of computation. The P2P communication in context parallel is exposed and leads to longer training step times. For efficient training of ST-DiT, we propose a novel hybrid parallelism strategy, which leverages A2A communication and local attention computation for spatial and temporal self attention while using P2P communications with context parallelism in a ring topology. This approach reduces the bandwidth requirement by factor of hw/cp for temporal attention and t/cp for spatial attention while enjoying the benefits of context parallelism to split the workload of computing full self attention.
Model Training#
To launch training on one node:
torchrun --nproc-per-node 8 nemo/collections/diffusion/train.py --yes --factory pretrain_xl
To launch training on multiple nodes using Slurm:
sbatch nemo/collections/diffusion/scripts/train.sh --factory pretrain_xl