Body Pose Estimation
BodyPoseNet is an NVIDIA-developed multi-person body pose estimation network included in the TAO Toolkit. It aims to predict the skeleton for every person in a given input image, which consists of keypoints and the connections between them. BodyPoseNet follows a single-shot, bottom-up methodology, so there is no need for a person detector. The pose/skeleton output is commonly used as input for applications like activity/gesture recognition, fall detection, and posture analysis, among others.
BodyPoseNet supports the following sub-tasks:
dataset_converttrainevaluateinferencepruneexport
These tasks may be invoked from the TAO Toolkit Launcher using the following command line convention:
tao bpnet <sub_task> <args_per_subtask>
where args_per_subtask are the command line arguments required for a given subtask. Each of
these sub-tasks are explained in detail below.
The BodyPoseNet apps in TAO Toolkit expect data in COCO format for training and evaluation.
See the Data Annotation Format page for more information about the COCO data format.
The Sloth and Label Studio tools may be used for labeling.
The BodyPoseNet app requires the data in a specific JSON format to be converted to TFRecords using thedataset_convert tool, which requires a configuration file as input. The configuration file details and sample usage examples are included in the following sections.
The dataset_convert tool takes in a defined JSON data format and converts it to the
TFRecords format that the BpNet model ingests. See the following sections for sample usage examples.
Create a Configuration File for the Dataset Converter
The dataset_convert tool provides several configurable parameters. The parameters are encapsulated in a spec file, which defines the dataset structure needed to convert data from COCO format to the TFRecords format that the BodyPoseNet trainer can ingest. This spec file is required to run any of the dataset_convert, train, evaluate, or inference commands for BpNet.
A sample dataset configuration file is shown below.
{
"dataset": "coco",
"root_directory_path": "/workspace/tao-experiments/bpnet/data",
"train_data": {
"images_root_dir_path": "train2017",
"mask_root_dir_path": "train_mask2017",
"annotation_root_dir_path": "annotations/person_keypoints_train2017.json"
},
"test_data": {
"images_root_dir_path": "val2017",
"mask_root_dir_path": "val_mask2017",
"annotation_root_dir_path": "annotations/person_keypoints_val2017.json"
},
"duplicate_data_with_each_person_as_center": true,
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person",
"num_joints": 17,
"keypoints": [
"nose","left_eye","right_eye","left_ear","right_ear",
"left_shoulder","right_shoulder","left_elbow","right_elbow",
"left_wrist","right_wrist","left_hip","right_hip",
"left_knee","right_knee","left_ankle","right_ankle"
],
"skeleton": [
[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],
[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]
],
"skeleton_edge_names": [
["left_ankle", "left_knee"], ["left_knee", "left_hip"], ["right_ankle", "right_knee"],
["right_knee", "right_hip"], ["left_hip", "right_hip"], ["left_shoulder", "left_hip"],
["right_shoulder", "right_hip"], ["left_shoulder", "right_shoulder"], ["left_shoulder", "left_elbow"],
["right_shoulder", "right_elbow"], ["left_elbow", "left_wrist"], ["right_elbow", "right_wrist"],
["left_eye","right_eye"], ["nose","left_eye"], ["nose","right_eye"],
["left_eye","left_ear"], ["right_eye","right_ear"], ["left_ear", "left_shoulder"],
["right_ear", "right_shoulder"]
]
}
],
"visibility_flags": {
"value": {
"visible": 2,
"occluded": 1,
"not_labeled": 0
},
"mapping": {
"visible": "visible",
"occluded": "occluded",
"not_labeled": "not_labeled"
}
},
"data_filtering_params": {
"min_acceptable_height": 32,
"min_acceptable_width": 32,
"min_acceptable_kpts": 5,
"min_acceptable_interperson_dist_ratio": 0.3
}
}
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
The name of the dataset (this will be required in other places as well) |
coco |
|
string |
The path to the root directory, relative to which the data paths are stored |
– |
|
string |
The path to the images directory relative to root_directory_path |
– |
|
string |
The path to the directory relative to root_directory_path where the masks will be saved |
– |
|
string |
The path to the annotation file relative to root_directory_path |
– |
|
boolean |
A flag specifying whether to duplicate each image N times where N is the number of persons in the image that meet the criteria specified in |
True |
|
dict |
This config describes the the keypoint convention/format in the given dataset. This follows a similar convention to the COCO categories section.
|
– |
|
dict |
The visibility flag index correspondences. The categories and the flag index used can vary based on datasets (e.g. visible, occluded, annotatable, truncated, not_labeled) This indicates the labeling convention for visibility of keypoints in the dataset. The category names can take any values as long as they are mapped to internally defined categories in the mapping section. |
– |
|
dict |
The mapping of the dataset visibility flag convention to the BodyPoseNet training convention. BodyPoseNet exposes three categories (visible, occluded, and not_labeled). All the categories used in the dataset need to be mapped to these three categories; you’ll need to determine the closest match among the the three, as in the following examples:
In the current training pipeline, occluded and visible are treated the same way, whereas keypoints tagged as not_labeled are ignored. If you would like the network to not predict occluded keypoints, then map the occluded keypoints to not_labeled. |
– |
|
dict |
Parameters used to filter training data (this section is only applicable when duplicate_data_with_each_person_as_center is enabled). These parameters are used to filter out the candidate persons in the image around whom the image will be centered.
|
– |
The test_data field in the spec file is necessary. If you do not want to use test_data, you can reuse train_data entries as dummy inputs, and there is no need to run the dataset_convert tool in test mode.
tao bpnet dataset_convert -d <path/to/dataset_spec>
-o <path_to_output_tfrecords>
-m <'train'/'test'>
--generate_masks
Here’s an example usage of dataset converter tool to convert a COCO-trained dataset to TFRecords:
tao bpnet dataset_convert -d /workspace/examples/bpnet/data_pose_config/coco_spec.json
-o /workspace/tao-experiments/bpnet/data/train
-m 'train'
--generate_masks
Required Arguments
-d, --dataset_spec: The path to the JSON dataset spec containing the config for exporting.tfrecords.-o, --output_filename: The output file name. Note that this will be appended with-fold-<num>-of-<total>
Optional Arguments
-h, --help: Show the help message.-m, --mode: This corresponds to the train_data and test_data fields in the spec. The default value istrain.--check_files: Check if the files, including images and masks, exist in the given root data directory.--generate_masks: Generate and save masks of regions with unlabeled people. This is used for training.
To perform training for BodyPoseNet, several components need to be configured, each with their own parameters.
The specification file for BodyPoseNet training configures these components of the training pipe:
Trainer
Dataloader
Augmentation
Label Processor
Model
Optimizer
Loss
Trainer
Here’s a sample list of parameters to configure the BpNet trainer.
__class_name__: BpNetTrainer
checkpoint_dir: /workspace/tao-experiments/bpnet/models/exp_m1_unpruned
log_every_n_secs: 30
checkpoint_n_epoch: 5
num_epoch: 100
summary_every_n_steps: 20
infrequent_summary_every_n_steps: 0
validation_every_n_epoch: 5
max_ckpt_to_keep: 100
random_seed: 42
pretrained_weights: null
load_graph: False
finetuning_config:
is_finetune_exp: False
checkpoint_path: null
ckpt_epoch_num: 0
use_stagewise_lr_multipliers: True
dataloader:
...
augmentation_config:
...
label_processor_config:
...
model:
...
optimizer:
...
loss:
...
The following table describes the trainer parameters:
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
The directory to save/load model checkpoints |
None |
|
int |
The frequency at which the checkpoint is saved |
5 |
|
int |
The logging frequency in seconds |
30 |
|
int |
The total number of epochs to train |
100 |
|
int |
The frequency at which to log the summary in tf.summary |
20 |
|
int |
The maximum number of checkpoints to keep |
100 |
|
string |
The absolute path to pretrained weights |
None |
|
boolean |
A flag to determine whether to load the graph from the pretrained model file, or just the weights. For a pruned model, set this parameter to True. Pruning modifies the original graph, so the pruned model graph and the weights need to be imported.
|
False |
|
boolean |
If this parameter is true, different learning rate multipliers will be used for backbone (2x) and refinement stages (4x). |
False |
|
This parameter specifies fine-tuning for a specific model config:
|
||
|
The model config |
– |
|
|
The model loss config |
– |
|
|
The optimizer config |
– |
|
|
The dataloader config |
– |
Resuming from the latest checkpoint is supported by default in the BodyPoseNet pipeline. This doesn’t require use of
finetuning_config.Currently, the validation pipeline is not supported in BodyPoseNet, so
validation_every_n_epochand other validation-related parameters can be ignored.
Model
The BodyPoseNet model can be constructed/configured using the model option in the spec file.
The following is a sample model config to instantiate bodyposenet model with pretrained weights.
pretrained_weights: /workspace/tao-experiments/bpnet/pretrained_model/tlt_bodyposenet_vtrainable_v1.0/model.tlt
load_graph: False
model:
__class_name__: BpNetLiteModel
backbone_attributes:
architecture: vgg
mtype: default
use_bias: False
stages: 3
heat_channels: 19
paf_channels: 38
use_self_attention: False
data_format: channels_last
use_bias: True
regularization_type: l1
kernel_regularization_factor: 5.0e-4
bias_regularization_factor: 0.0
kernel_initializer: random_normal
The following table describes the trainer parameters:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
string |
BpNetLiteModel |
The class module used to build the model |
[BpNetLiteModel] |
|
dict |
– |
The backbone attributes of the model
|
|
|
int |
3 |
The number of total stages for pose estimation (stages of refinement + 1) in the network |
[2, 6] |
|
int |
19 |
The number of heatmap channels. This is equivalent to the number of target keypoints (defined in pose_config) + 1 (for background) |
19 |
|
int |
38 |
The number of part affinity field channels. This is equivalent to the number of target skeleton connections * 2 (defined in pose_config) |
38 |
|
boolean |
False |
Specifies whether to use the self-attention module in the model. |
True or False |
|
string |
channels_last |
The data format to use |
channels_last |
|
boolean |
True |
Specifies whether to use bias in the rest of the model (apart from backbone). |
True or False |
|
string |
l1 |
The type of the regularizer use during training |
[l1, l2, l1_l2] |
|
float |
5.0e-4 |
The weight of regularizer use during training for the kernel weights |
– |
|
float |
0.0 |
The weight of regularizer use during training for the bias weights |
– |
|
string |
random_normal |
The kernel initializer type to use to initialize the kernel weights |
random_normal |
We suggest using the L1 regularizer when training a network before pruning, as L1
regularization makes pruning the network weights easier. After pruning,
when retraining the networks, we recommend turning regularization off by setting
the kernel_regularization_factor to 0.0.
Loss
This section describes how to configure the cost function to select the type of loss.
loss:
__class_name__: BpNetLoss
The following table describes the parameters used to configure loss:
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
string |
BpNetLoss |
The class module used to build the cost function |
BpNetLoss |
Optimizer
This section describes how to configure the optimizer and learning-rate schedule:
optimizer:
__class_name__: WeightedMomentumOptimizer
learning_rate_schedule:
__class_name__: SoftstartAnnealingLearningRateSchedule
soft_start: 0.05
annealing: 0.5
base_learning_rate: 2.e-5
min_learning_rate: 8.e-08
last_step: null
grad_weights_dict: null
weight_default_value: 1.0
momentum: 0.9
use_nesterov: False
The following table describes the parameters used to configure the optimizer:
Parameter |
Datatype |
Default |
Description |
|---|---|---|---|
|
string |
WeightedMomentumOptimizer |
The class module used to build the optimizer. |
|
learning_rate_schedule config |
soft start annealing schedule |
Configures the learning rate schedule for the trainer. This may be configured using the following parameters:
|
|
dict |
None |
The layer-wise learning rate multipliers to be used for gradient updates. Requires a mapping from layer names to lr multipliers. |
|
float |
1.0 |
The default learning rate multiplier to use |
|
float |
0.9 |
The momentum factor. The method falls back into gradient descend optimizer when momentum is set to 0. |
|
boolean |
False |
Specifies whether to use Nesterov momentum. |
BodyPoseNet currently supports the soft_start annealing learning rate schedule. The learning rate when plotted as a function of the training progress (0.0, 1.0) results in the following curve:
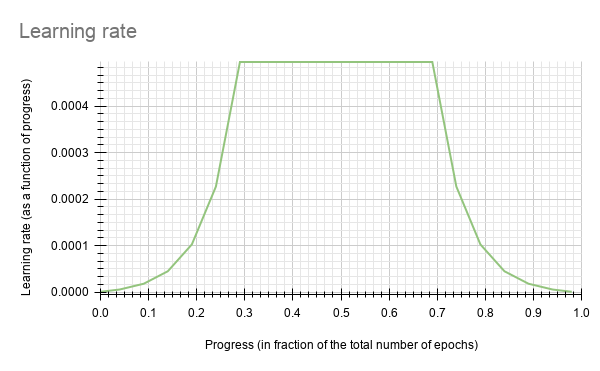
In this experiment, the soft_start was set as 0.05 and annealing as 0.5, with the minimum learning rate as 8e-8 and maximum learning rate, or base_learning_rate, as 2e-5.
The default base_learning_rate is set for a single-GPU training. If you would like
to use multi-GPU training, you may need to modify the learning_rate to get similar
accuracy to a 1 GPU training. In most cases, scaling up the learning rate by a factor of
$NUM_GPUS would be a good place to start. For instance, if you are using 2 GPUs, use
2 * base_learning_rate used in 1 GPU setting, and if you are using 4 GPUs,
use 4 * base_learning_rate used in 1 GPU setting.
Dataloader
This section helps you configure the dataloader as follows:
Defining data paths you want to train on
Image configuration
The target pose configuration to use
Normalization configuration
Augmentation configuration, which is expanded upon in the next section
The label processor or ground truth generator configuration, which is expanded upon in the next section
dataloader:
__class_name__: BpNetDataloader
batch_size: 10
shuffle_buffer_size: 20000
image_config:
image_dims:
height: 256
width: 256
channels: 3
image_encoding: jpg
pose_config:
__class_name__: BpNetPoseConfig
target_shape: [32, 32]
pose_config_path: /workspace/examples/bpnet/model_pose_config/bpnet_18joints.json
dataset_config:
root_data_path: /workspace/tao-experiments/bpnet/data/
train_records_folder_path: /workspace/tao-experiments/bpnet/data
train_records_path: [train-fold-000-of-001]
val_records_folder_path: /workspace/tao-experiments/bpnet/data
val_records_path: [val-fold-000-of-001]
dataset_specs:
coco: /workspace/examples/bpnet/data_pose_config/coco_spec.json
normalization_params:
image_scale: [256.0, 256.0, 256.0]
image_offset: [0.5, 0.5, 0.5]
mask_scale: [255.0]
mask_offset: [0.0]
augmentation_config:
...
label_processor_config:
...
The following table describes the dataloader parameters:
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
The class module used to build the dataloader |
BpNetDataloader |
|
int |
The batch size for training/evaluation |
10 |
|
int |
The buffer size to use to shuffle and repeat the dataset |
20000 |
|
dict |
The input image config:
|
|
|
dict |
The pose configuration to use:
|
|
|
dict |
The dataset and tfrecord path configuration.
|
– |
|
dict |
The data centering and normalization parameters to use for training. The operation is as follows: (data / scale) - offset.
|
|
|
The augmentation configuration |
– |
|
|
The Label Processor or Ground truth generator configuration |
– |
The
target_shapedepends on the input shape. This can be computed based on the model stride. In the default setting, the model has a stride of 8.The mask and image data directories in dataset_spec are relative to this
root_data_path.Here
datasetshould correspond to thedatasetfield in the corresponding dataset_spec.Currently, BodyPoseNet only supports the given default skeleton configuration at
pose_config_path. The inference pipelines do not support custom skeleton configuration at the moment.
Augmentation Module
The augmentation module provides some basic on-the-fly augmentation options. Here
is a sample augmentation_config element:
augmentation_config:
__class_name__: AugmentationConfig
spatial_augmentation_mode: person_centric
spatial_aug_params:
flip_lr_prob: 0.5
flip_tb_prob: 0.0
rotate_deg_max: 40.0
rotate_deg_min: -40.0
zoom_prob: 0.0
zoom_ratio_min: 1.0
zoom_ratio_max: 1.0
translate_max_x: 40.0
translate_min_x: -40.0
translate_max_y: 40.0
translate_min_y: -40.0
use_translate_ratio: False
translate_ratio_max: 0.2
translate_ratio_min: -0.2
target_person_scale: 0.6
identity_spatial_aug_params: null
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
Information on the augmentation config |
– |
|
string |
The augmentation mode to apply for the images. There are three modes available:
|
person_centric |
|
dict |
Augmentation parameters used for random spatial transformations |
– |
|
dict |
Augmentation parameters used for fixed spatial transformations. Currently, this is not supported in the BodyPoseNet pipeline. |
None |
When the train data is compiled for this mode, each image and ground truth is replicated
N times, with the first annotation varying every time. This ensures that the
augmentations are centered around each of these N persons. Here, N is the number of
people in the image that meet certain size criteria (data_filtering_params).
This mode is used in combination with duplicate_data_with_each_person_as_center
enabled in the dataset_spec. This ensures that each selected person is a person of
interest once in the replicated data.
spatial_aug_params: This module supports basic spatial augmentation such as flip, zoom,
rotate, and translate, which may be configured.
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
float |
The probability to flip an input image horizontally |
0.5 |
|
float |
The probability to flip an input image vertically |
0.0 |
|
float |
The maximum angle of rotation (in degrees) to be applied to the images and the training labels |
40 |
|
float |
The minimum angle of rotation (in degrees) to be applied to the images and the training labels |
-40 |
|
float |
The probability to apply zoom transformation |
0.0 |
|
float |
The minimum ratio by which to zoom into the images |
1.0 |
|
float |
The maximum ratio by which to zoom into the images |
1.0 |
|
float |
The maximum translation along x-axis to be applied to the images and the training labels |
40 |
|
float |
The minimum translation along x-axis to be applied to the images and the training labels |
-40 |
|
float |
The maximum translation along y-axis to be applied to the images and the training labels |
40 |
|
float |
The minimum translation along y-axis to be applied to the images and the training labels |
-40 |
|
boolean |
Specifies whether to use the translation ratio or absolute translation values |
False |
|
float |
The maximum translation ratio (w.r.t image dims) along x-axis or y-axis to be applied to the images and the training labels |
0.2 |
|
float |
The minimum translation ratio (w.r.t image dims) along x-axis or y-axis to be applied to the images and the training labels |
-0.2 |
|
float |
The image is scaled such that the scale of the person of interest in the image is adjusted to target_person_scale w.r.t the image height.
This is applicable when using |
0.6 |
A zooming ratio of 1.0 will not affect the image, while values higher than 1 will result in ‘zooming out’ (the image gets rendered smaller than the canvas), and vice versa for values below 1.0.
If
rotate_deg_minis null, the rotation range is defined between [-rotate_rad_max, rotate_rad_max].
Label Processor Module
The label processor module provides the required parameters to change ground truth feature map
generation. Here is a sample label_processor_config element:
label_processor_config:
paf_gaussian_sigma: 0.03
heatmap_gaussian_sigma: 7.0
paf_ortho_dist_thresh: 1.0
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
float |
The sigma value to use for gaussian weighting of vector fields |
0.03 |
|
float |
The sigma value to use for gaussian weighting of the heatmap |
7.0 |
|
float |
The orthogonal distance threshold for part affinity fields. Note that this will be multiplied by the stride. |
1.0 |
After following the steps to Generate Tfrecords and Masks to create TFRecords ingestible by the TAO training and setting up a train_spec, you are now ready to start training the bodypose estimation network.
The following command outlines the BodyPoseNet training command:
tao bpnet train -e <path/to/train_spec>
-r <path/to/result directory>
-k <key>
--gpus <num_gpus>
Required Arguments
-e, --experiment_spec_file: The path to the train_spec file. The path may be absolute or relative to the working directory.-r, --results_dir: The path to a folder where experiment outputs should be written, including checkpoints, logs etc.-k, –key: A user-specific encoding key to save or load a.tltmodel.
Optional Arguments
-h, --help: Prints the help message.-l, --log_level: Sets the logging level.--gpus: The number of GPUs to use and processes to launch for training. The default value is 1.--gpu_index: The indices of the GPUs to use for training. The GPUs are referenced as per the indices mentioned in the./deviceQueryCUDA samples.
BodyPoseNet supports resuming training from intermediate checkpoints. When a previously
running training experiment is stopped prematurely, you can restart the training from the
last checkpoint by simply re-running the BodyPoseNet training command with the same
command line arguments as before. The trainer for BodyPoseNet finds the last saved
checkpoint in the results directory and resumes the training from there. The interval at
which the checkpoints are saved are defined by the checkpoint_interval parameter in the
train_spec.
To perform evaluation and inference for BodyPoseNet, you need to configure several components, each with their own parameters in an inference spec file.
Here’s a sample list of parameters to config BpNet infer specification for evaluation and inference.
model_path: /workspace/tao-experiments/bpnet/models/exp_m1_unpruned/bpnet_model.tlt
train_spec: /workspace/examples/bpnet/specs/bpnet_train_m1_coco.yaml
input_shape: [368, 368]
# choose from: {pad_image_input, adjust_network_input, None}
keep_aspect_ratio_mode: adjust_network_input
output_stage_to_use: null
output_upsampling_factor: [8, 8]
heatmap_threshold: 0.1
paf_threshold: 0.05
multi_scale_inference: False
scales: [0.5, 1.0, 1.5, 2.0]
Argument |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
The path to the model directory to save/load model checkpoints |
– |
|
string |
The path to the train_spec file used for training the model to be evaluated |
– |
|
list |
The height and width (in that order) of the network input for inference (can be different from the trainining input shape) |
[368, 368] |
|
string |
The aspect ratio mode. The available modes are described below:
|
adjust_network_input |
|
int |
The output refinement stage to use. There might be multiple output refinement stages as specified in train_spec. If null, the final output stage is used. This also generally has the best accuracy. |
null |
|
list |
The output upsampling factor for the feature maps (heatmap and part affinity map) before post-processing. |
[8, 8] |
|
float |
The heatmap threshold to use for non-max suppression of keypoints. |
0.1 |
|
float |
The part affinity score threshold to use to suppress connections. |
0.05 |
|
boolean |
Toggles multi-scale refinement. If enabled, the image is inferred on provided scales and the output feature maps are averaged. |
False |
|
list |
The scales to use for multi-scale refinement. |
[0.5, 1.0, 1.5, 2.0] |
The inference task for BpNet may be used to visualize the pose predictions. An
example of the command for this task is shown below:
tao bpnet inference --inference_spec <path/to/inference_spec>
--model_filename <path/to/model_filename>
--input_type <image/dir/json>
--input <path/to/input>
--results_dir <results directory>
--dump_visualizations
-k $KEY
tao bpnet inference --inference_spec $SPECS_DIR/infer_spec.yaml \
--model_filename $USER_EXPERIMENT_DIR/models/exp_m1_unpruned/$MODEL_CHECKPOINT \
--input_type json \
--input $USER_EXPERIMENT_DIR/data/viz_example_data.json \
--results_dir $USER_EXPERIMENT_DIR/results/exp_m1_unpruned/infer_default \
--dump_visualizations \
-k $KEY
Required Parameters
-i, --inference_spec: The path to an inference spec file-k, --key: The key to load the model. This is a required parameter for an encrypted.tltmodel,but is optional for a TRT .engine.--results_dir: The path to a folder where experiment outputs should be written--input_type: The input type, eitherimage,dir, orjson--input: The absolute or relative path to the input to run inference on
Optional Parameters
-h, --help: Prints the help message.-l, --log_level: Sets the logging level.-m, --model_filename: The path to the model file to use for inference. When specified, this path overrides themodel_pathin inference spec file.--image_root_path: The root directory path to the image(s). If specified, image paths are assumed to be relative to this. This is relevant if theinput_typeis json.--dump_visualizations: If enabled, saves images with inference visualization to the results/images_annotated directory.
The inference tool produces two outputs:
Frame-by-frame keypoint labels in
<results_dir>/detection.json.Images with keypoint results rendered are saved to
<results_dir>/images_annotated(when--dump_visualizationsis enabled)
Since BodyPoseNet is a fully convolutional neural net, the model can be inferred at a different inference resolution than the resolution at which it was trained. The input dims of the network will be overridden to run inference at this resolution if they are different from the training resolution. There may be some regression in accuracy when running inference at a resolution very different from the training.
Execute evaluate on a BodyPoseNet model.
Note that you must first create TFRecords for this test set by following the steps listed in the Pre-processing the Dataset section.
tao bpnet evaluate [-h] -i <inference_spec>
-d <dataset_spec>
-m <model_file>
-r <results directory>
-k <key>
Required Arguments
-i, --inference_spec: The inference spec file to set up the evaluation experiment.-k, --key: The key to load the model. This is a required parameter for an encrypted .tlt model, but is optional for a TRT .engine.-d, --dataset_spec: The path to the datset_spec to run evaluation on. The model is evaluated on the test_data specified in the dataset_spec.-r, --results_dir: The path to a folder where experiment outputs should be written.
Optional Arguments
-h, --help: Prints the help message.-l, --log_level: Sets the logging level.-m, --model_filename: The path to the model file to use for evaluation. When specified, this path overrides themodel_pathin inference spec file.
Pruning removes parameters from the model to reduce the model size without compromising the
integrity of the model itself using the prune command.
The prune task includes these parameters:
tao bpnet prune -m <pretrained_model>
-o <output_file>
-k <key>
[-n <normalizer>]
[-eq <equalization_criterion>]
[-pg <pruning_granularity>]
[-pth <pruning threshold>]
[-nf <min_num_filters>]
[-el [<excluded_list>]
Required Arguments
-m, --model: The path to the pretrained model for pruning-o, --output_file: The path to the output pruned model-k, --key: The key to load a .tlt model
Optional Arguments
-h, --help: Prints the help message.-n, –normalizer: Specifymaxto normalize by dividing each norm by the maximum norm within a layer; specifyL2to normalize by dividing by the L2 norm of the vector comprising all kernel norms. The default value ismax.-eq, --equalization_criterion: Criteria to equalize the stats of inputs to an element-wise op layer or depth-wise convolutional layer. This parameter is useful for resnets and mobilenets. The options arearithmetic_mean,geometric_mean,union, andintersection(default:union).-pg, -pruning_granularity: The number of filters to remove at a time (default:8)-pth: The threshold to compare the normalized norm against (default:0.1)-nf, --min_num_filters: The minimum number of filters to keep per layer (default:16)-el, --excluded_layers: A list of excluded_layers (e.g.-i item1 item2) (default: [])
After pruning, the model needs to be retrained. See Re-train the Pruned Model for more details.
Using the Prune Command
Here’s an example of using the prune task:
tao bpnet prune -m /workspace/tao-experiments/bpnet/models/exp_m1_unpruned/bpnet_model.tlt
-o /workspace/tao-experiments/bpnet/models/exp_m1_pruned/bpnet_model.pruned-0.2.tlt
-eq union
-pth 0.2
-k $KEY
Once the model has been pruned, there might be a slight decrease in accuracy
because some previously useful weights may have been removed. To regain the accuracy,
we recommend retraining this pruned model over the same dataset using
the train task, as documented in the Train the model
section, with an updated spec file that points to the newly pruned model as the pretrained model
file. All other parameters may be retained in the spec file from the previous training.
To load the pruned model, set the load_graph flag in train_spec to
true.
By default, the regularization is disabled when the load_graph is set to true.
The BodyPoseNet model application in the TAO Toolkit includes an export
sub-task to export and prepare a trained BodyPoseNet model for verification and deployment.
The export sub-task optionally generates the calibration cache for TensorRT INT8 engine
calibration.
Exporting the model decouples the training process from deployment and allows conversion to
TensorRT engines outside the TAO environment. TensorRT engines are specific to each hardware
configuration and should be generated for each unique inference environment. This may be
interchangeably referred to as a .trt or .engine file. The same exported TAO model
may be used universally across training and deployment hardware. This is referred to as the
.etlt file, or encrypted TAO file. During model export, the TAO model is encrypted with a
private key, which is required when you deploy this model for inference.
Choose Network Input Resolution for Deployment
The network input resolution of the model is one of the major factors that determine the accuracy of bottom-up approaches. Bottom-up methods have to feed the whole image at once, resulting in smaller resolution per person. Hence, higher-input resolution will yield better accuracy, especially on small- and medium-scale persons (w.r.t the image scale). Also note that with higher input resolution, the runtime of the CNN will also be higher. Therefore, the accuracy/runtime tradeoff should be decided based on the accuracy and runtime requirements for the target usecase.
Height of the desired network
You will need to choose a resolution that works best depending on the target use case and the compute or latency constraints. If your application involves pose estimation for one or more persons close to the camera, such that the scale of the person is relatively large, then you can go with a smaller network input resolution. Whereas if you are targeting use for persons with smaller relative scales, as with crowded scenes, you might want to go with a higher network input resolution. For instance, if your application has a person with height of about 25% of the image, the final resized height would be as follows:
56px for network height of 224
72px for network height of 288
80px for network height of 320
The network with 320 height has maximum resolution for the person and hence would be more accurate.
Width of the desired network
Once you freeze the height of the network, the width can be decided based on the aspect ratio for your input data used during deployment time. Or you can also follow a standard multiple of 32/64 closest to the aspect ratio.
Illustration of accuracy/runtime variation for different resolutions
Note that these are approximate runtimes/accuracies for the default architecture and train_spec. Any changes to the architecture or params will yield different results. This is primarily to get a better sense of which resolution would suit your needs. The runtimes provided are for the CNN
Input Resolution |
Precision |
Runtime (GeForce RTX 2080) |
Runtime (Jetson AGX) |
|---|---|---|---|
320x448 |
FP16 |
3.13ms |
18.8ms |
288x384 |
FP16 |
2.58ms |
12.8ms |
224x320 |
FP16 |
2.27ms |
10.1ms |
320x448 |
INT8 |
1.80ms |
8.90ms |
288x384 |
INT8 |
1.56ms |
6.38ms |
224x320 |
INT8 |
1.33ms |
5.07ms |
You can expect to see a 7-10% mAP increase in the area=medium category when going from 224x320 to 288x384, and an additional 7-10% mAP when you go to 320x448. The accuracy for area=large remains almost the same across these resolutions, so you can stick to a lower resolution if this is what you need. As per COCO keypoint evaluation, the medium area is defined as persons occupying less than the area between 36^2 to 96^2. Anything above it is categorized as large.
The height and width should be a multiple of 8. Preferably, a multiple of 16/32/64
INT8 Mode Overview
TensorRT engines can be generated in INT8 mode to run with lower precision,
and thus improve performance. This process requires a cache file that contains scale factors
for the tensors to help combat quantization errors, which may arise due to low-precision arithmetic.
The calibration cache is generated using a calibration tensorfile when export is
run with the --data_type flag set to int8. Pre-generating the calibration
information and caching it removes the need for calibrating the model on the inference machine.
Moving the calibration cache is usually much more convenient than moving the calibration tensorfile
since it is a much smaller file and can be moved with the exported model. Using the calibration
cache also speeds up engine creation, as building the cache can take several minutes to generate
depending on the size of the Tensorfile and the model itself.
The export tool can generate an INT8 calibration cache by ingesting a sampled subset of training data. You need to create a sub-sampled directory of random images that best represent your test dataset. We recommend using at least 10-20% of the training data. The more data provided during calibration, the closer int8 inferences are to fp32 inferences. A helper script is provided with the sample notebook to select the subset data from the given training data based on several criteria, like minimum number of persons in the image, minimum number of keypoints per person, etc.
Based on the evaluation results of the INT8 model, you might need to adjust the number of sampled images or the kind of selected to images to better represent test dataset. You can also use a portion of data from the test data for calibration to improve the results.
FP16/FP32 Model
The calibration.bin is only required if you need to run inference at INT8 precision. For
FP16/FP32 based inference, the export step is much simpler. All that is required is to provide
a model from the train step to export to convert it into an encrypted TAO
model.
Export the BodyPoseNet Model
The following are command line arguments for the export command:
tao bpnet export [-h] -m <path to the .tlt model file generated by tao train>
-k <key>
[-o <path to output file>]
[--cal_data_file <path to tensor file>]
[--cal_image_dir <path to the directory images to calibrate the model]
[--cal_cache_file <path to output calibration file>]
[--data_type <Data type for the TensorRT backend during export>]
[--batches <Number of batches to calibrate over>]
[--max_batch_size <maximum trt batch size>]
[--max_workspace_size <maximum workspace size]
[--batch_size <batch size to TensorRT engine>]
[--experiment_spec <path to experiment spec file>]
[--engine_file <path to the TensorRT engine file>]
[--verbose Verbosity of the logger]
[--input_dims Input dimensions to use for network]
[--backend Intermediate model type to export to]
[--force_ptq Flag to force PTQ]
Required Arguments
-m, --model: The path to the.tltmodel file to be exported usingexport-k, --key: The key used to save the.tltmodel file-t, --backend: The backend type used to convert to.etltmodel file.
Currently, only tfonnx is supported as backend. Please do not use
onnx or uff.
Optional Arguments
-o, --output_file: The path to save the exported model to. The default path is<input_file>.etlt.--e, -experiment_spec: The experiment_spec used for training.--data_type: The desired engine data type. The options arefp32,fp16, andint8. A calibration cache will be generated inint8mode. The default value isfp32. If usingint8mode, the following INT8 arguments are required.-s, --strict_type_constraints: A Boolean flag to indicate whether or not to apply the TensorRTstrict_type_constraintswhen building the TensorRT engine. Note this is only for applying the strict type ofint8mode.
INT8 Export Mode Required Arguments
--cal_image_dir: The directory of images that is preprocessed and used for calibration.--cal_data_file: The tensorfile generated using images incal_image_dirfor calibrating the engine. If this already exists, it is directly used to calibrate the engine. The INT8 tensorfile is a binary file that contains the preprocessed training samples.
The --cal_image_dir parameter applies the necessary preprocessing
to generate a tensorfile at the path mentioned in the --cal_data_file
parameter, which is in turn used for calibration. The number of generated batches in the
tensorfile is obtained from the value set to the --batches parameter,
and the batch_size is obtained from the value set to the --batch_size
parameter. Ensure that the directory mentioned in --cal_image_dir has at least
batch_size * batches number of images in it. The valid image extensions are
.jpg, .jpeg, and .png.
INT8 Export Optional Arguments
--cal_cache_file: The path to save the calibration cache file to. The default value is./cal.bin. If this file already exists, the calibration step is skipped.--batches: The number of batches to use for calibration and inference testing. The default value is 10.--batch_size: The batch size to use for calibration. The default value is 1.--max_batch_size: The maximum batch size of the TensorRT engine. The default value is 1.--max_workspace_size: The maximum workspace size of the TensorRT engine. The default value is2 * (1 << 30).--experiment_spec: The experiment_spec used for training. This argument is used to obtain the parameters to preprocess the data used for calibration.--engine_file: The path to the serialized TensorRT engine file. Note that this file is hardware specific and cannot be generalized across GPUs. Use this argument to quickly test your model accuracy using TensorRT on the host. As the TensorRT engine file is hardware specific, you cannot use this engine file for deployment unless the deployment GPU is identical to the training GPU.--force_ptq: A Boolean flag to force post-training quantization on the exported.etltmodel.
Sample usage for the export sub-task
The following is a sample command to export a BodyPoseNet model in INT8 mode. This command shows
usage of the --cal_image_dir option for a BodyPoseNet model calibration.
# Export `.etlt` model, Calibrate model and Convert to TensorRT engine (INT8).
tao bpnet export
-m /workspace/tao-experiments/bpnet/models/exp_m1_retrain/bpnet_model.tlt
-o /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.etlt
-k $KEY
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
-e $SPECS_DIR/bpnet_retrain_m1_coco.txt
-t tfonnx
--data_type int8
--cal_image_dir /workspace/tao-experiments/bpnet/data/train2017/
--cal_cache_file /workspace/tao-experiments/bpnet/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.bin
--cal_data_file /workspace/tao-experiments/bpnet/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile
--batch_size 1
--batches 5000
--max_batch_size 1
--data_format channels_last
--engine_file /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.engine
The following is a sample command to export a BodyPoseNet model in INT8 mode:
# Export `.etlt` model and Convert to TensorRT engine (FP16).
tao bpnet export
-m /workspace/tao-experiments/bpnet/models/exp_m1_retrain/bpnet_model.tlt
-o /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.etlt
-k $KEY
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
-e $SPECS_DIR/bpnet_retrain_m1_coco.txt
-t tfonnx
--data_type fp16
--batch_size 1
--max_batch_size 1
--data_format channels_last
--engine_file /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.fp16.engine
Evaluate the exported TRT Model
Evaluating the exporter TRT .engine is similar to evaluating .tlt.
Follow the instructions as described in the Create an Inference Specification File
section to create the infer_spec file. Note that the adjust_network_input mode in keep_aspect_ratio_mode
is not supported for the exported TRT model, so pad_image_input (Strict mode) should be used
instead. Follow the instructions in the Evaluate the Model section
to evaluate the TRT model.
You can run evaluation of the .tlt model in strict mode as well to compare with the accuracies of the
INT8/FP16/FP32 models for any drop in accuracy. The FP16/FP32 models should have little or no drop
in accuracy when compared to the .tlt model in this step. The INT8 models would have similar
accuracies (or comparable within a 2-3% mAP range) to the .tlt model.
If the accuracy of the INT8 model seems to degrade significantly compared to the corresponding FP16 version, it could be caused by the following:
There wasn’t enough data in the calibration tensorfile used to calibrate the model.
The training data is not entirely representative of your test images, and the calibration may be incorrect. Therefore, you may either regenerate the calibration tensorfile with more batches of the training data and recalibrate the model, or add a portion of data from the test set.
This evaluation is mainly used as a sanity check for the exported TRT (INT8/FP16) models. This is done in strict mode and hence doesn’t reflect the true accuracy of the model, as the input aspect ratio can vary a lot from the aspect ratio of the images in the test set. For a dataset like COCO, there might be a collection of images with various resolutions. Here, you retain a strict input resolution and padsthe image to retrain the aspect ratio. So the accuracy here might vary based on the aspect ratio and network resolution you choose.
Export the Deployable BodyPoseNet Model
Once the INT8/FP16/FP32 model is verified, you need to re-export the model so it can be used to run
on inference platforms like Deepstream. You will use the same guidelines as
in the Exporting the Model section, but you
need to add the --sdk_compatible_model flag to the export command, which adds a few
non-traininable post-process layers to the model to enable compatibility with the inference
pipelines. You should re-use the calibration tensorfile (--cal_data_file) generated in the
previous step to keep it consistent, but you will need to regenerate the cal_cache_file
and the .etlt model.
The following is a sample command to export a BodyPoseNet model in INT8 mode (similar to previous section), which can be deployed in the inference pipelines.
tao bpnet export
-m /workspace/tao-experiments/bpnet/models/exp_m1_retrain/bpnet_model.tlt
-o /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.deploy.etlt
-k $KEY
-d $IN_HEIGHT,$IN_WIDTH,$IN_CHANNELS
-e $SPECS_DIR/bpnet_retrain_m1_coco.txt
-t tfonnx
--data_type int8
--cal_image_dir /workspace/tao-experiments/bpnet/data/train2017/
--cal_cache_file /workspace/tao-experiments/bpnet/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.deploy.bin
--cal_data_file /workspace/tao-experiments/bpnet/models/exp_m1_final/coco.$IN_HEIGHT.$IN_WIDTH.tensorfile
--batch_size 1
--batches 5000
--max_batch_size 1
--data_format channels_last
--engine_file /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.int8.deploy.engine
--sdk_compatible_model
The above exported model will not work with the bpnet inference/evaluate
tools. This is for deployment only. For inference and evaluation, use the TRT model
exported without --sdk_compatible_model.
The tao-converter tool is provided with the TAO Toolkit
to facilitate the deployment of TAO trained models on TensorRT and/or Deepstream.
This section elaborates on how to generate a TensorRT engine using tao-converter.
For deployment platforms with an x86-based CPU and discrete GPUs, the tao-converter
is distributed within the TAO docker. Therefore, we suggest using the docker to generate
the engine. However, this requires that the user adhere to the same minor version of
TensorRT as distributed with the docker. The TAO docker includes TensorRT version 8.0.
Instructions for x86
For an x86 platform with discrete GPUs, the default TAO package includes the tao-converter
built for TensorRT 8.2.5.1 with CUDA 11.4 and CUDNN 8.2. However, for any other version of CUDA and
TensorRT, please refer to the overview section for download. Once the
tao-converter is downloaded, follow the instructions below to generate a TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Instructions for Jetson
For the Jetson platform, the tao-converter is available to download in the NVIDIA developer zone. You may choose
the version you wish to download as listed in the overview section.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT comes pre-installed with Jetpack. If you are using older JetPack, upgrade to JetPack-5.0DP.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Using the tao-converter
tao converter input_file
-k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
[-h]
Required Arguments
input_file: The path to the.etltmodel exported usingexport.-k, --key: The key used to encode the.tltmodel when doing the training.
Optional Arguments
-e: The path to save the engine to. The default path is./saved.engine.-t: The desired engine data type, which generates a calibration cache if in INT8 mode. The default value isfp32. The options arefp32,fp16,int8.-w: The maximum workspace size for the TensorRT engine. The default value is1073741824(1<<30)-i: The input-dimension ordering. The default value isnchw. The options arenchw,nhwc,nc.-p: Optimization profiles for.etltmodels with dynamic shape. Use a comma-separated list of optimization profile shapes in the format<input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format:<n>x<c>x<h>x<w>. This can be specified multiple times if there are multiple input tensors for the model.-s: A Boolean value specifying whether to apply TensorRT strict-type constraints when building the TensorRT engine.-u: Use DLA core. Specify the DLA core index when building the TensorRT engine on Jetson devices.
INT8 Mode Arguments
-c: The path to calibration cache file( only used in INT8 mode). The default value is./cal.bin.-b: The batch size used during the export step for INT8 calibration cache generation. (default:8).-m: The maximum batch size for the TensorRT engine. The default value is16. If out-of-memory issues occur, decrease the batch size accordingly.
Example usage for BodyPoseNet
# Set dimensions of desired output model for inference/deployment
INPUT_SHAPE=288x384x3
# Set input name
INPUT_NAME=input_1:0
# Set opt profile shapes
MAX_BATCH_SIZE=1
OPT_BATCH_SIZE=1
# Convert to TensorRT engine (FP16).
tao converter /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.deploy.etlt
-k $KEY
-t fp16
-e /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.fp16.deploy.engine
-p ${INPUT_NAME},1x$INPUT_SHAPE,${OPT_BATCH_SIZE}x$INPUT_SHAPE,${MAX_BATCH_SIZE}x$INPUT_SHAPE
# Convert to TensorRT engine (INT8).
tao converter /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.deploy.etlt
-k $KEY
-t int8
-c /workspace/tao-experiments/bpnet/models/exp_m1_final/calibration.$IN_HEIGHT.$IN_WIDTH.deploy.bin
-e /workspace/tao-experiments/bpnet/models/exp_m1_final/bpnet_model.$IN_HEIGHT.$IN_WIDTH.fp16.deploy.engine
-p ${INPUT_NAME},1x$INPUT_SHAPE,${OPT_BATCH_SIZE}x$INPUT_SHAPE,${MAX_BATCH_SIZE}x$INPUT_SHAPE
Deploying to DeepStream 6.0
The pretrained model for BodyPoseNet provided through NGC is available by default with DeepStream 6.0.
For more details, refer to DeepStream TAO Integration for BodyPoseNet.