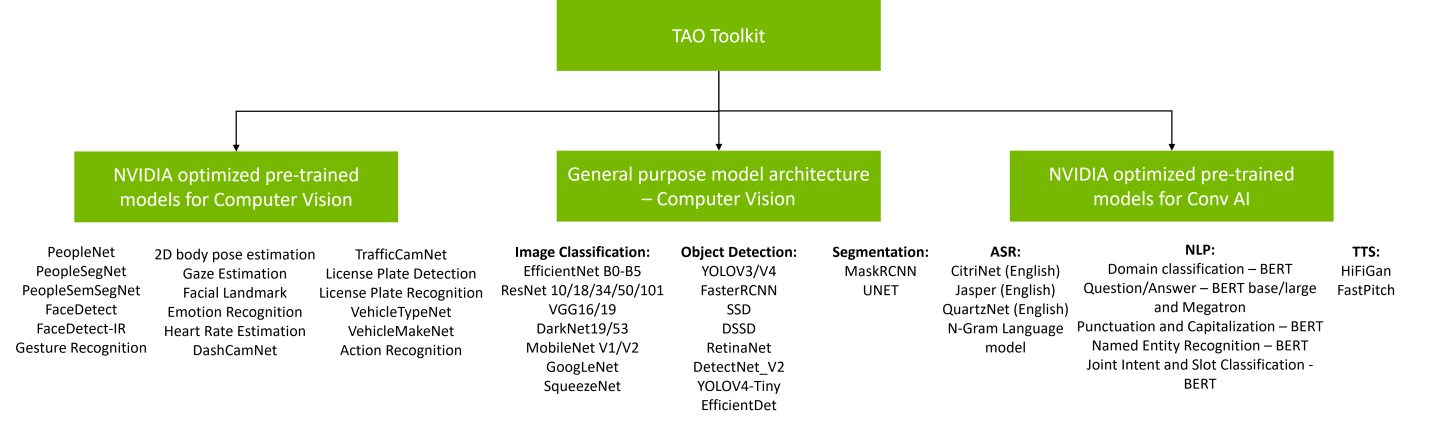
Overview
TAO Toolkit provides an extensive model zoo containing pretrained models for both computer vision and conversational AI use cases.
There are two types of pre-trained models that you can start with:
General-purpose vision models: The pre-trained weights for these models merely act as a starting point to build more complex models. For computer vision use cases, these pre-trained weights are trained on Open Image datasets, and they provide a much better starting point for training versus starting from a random initialization of weights.
Purpose-built pre-trained models: These are highly accurate models that are trained on thousands of data inputs for a specific task. These domain-focused models can either be used directly for inference or can be used with TAO Toolkit for transfer learning on your own dataset.
* New in TAO Toolkit 3.0-21.08 GA
You can choose from 100+ permutations of model architecture and backbone with the general purpose vision models. For more information on fine tuning models for conversational AI use cases, see the pretrained models section for Conversational AI.
Purpose-built models
Purpose-built models are built for high accuracy and performance. You can deploy these models out of the box for applications such as smart city, retail, public safety, and healthcare, or you can retrain them with your own data. All models are trained on thousands of proprietary images and achieve very high accuracy on NVIDIA test data. More information about each of these models is available in ndividual model cards. Typical use cases and some model KPIs are provided in the table below. PeopleNet can be used for detecting and counting people in smart buildings, retail, hospitals, etc. For smart traffic applications, TrafficCamNet and DashCamNet can be used to detect and track vehicles on the road.
Model Name |
Network Architecture |
Number of classes |
Accuracy |
Use Case |
|---|---|---|---|---|
DetectNet_v2-ResNet18 |
4 |
84% mAP |
Detect and track cars. |
|
DetectNet_v2-ResNet18/34 |
3 |
84% mAP |
People counting, heatmap generation, social distancing. |
|
DetectNet_v2-ResNet18 |
4 |
80% mAP |
Identify objects from a moving object. |
|
DetectNet_v2-ResNet18 |
1 |
96% mAP |
Detect face in a dark environment with IR camera. |
|
ResNet18 |
20 |
91% mAP |
Classifying car models. |
|
ResNet18 |
6 |
96% mAP |
Classifying type of cars as coupe, sedan, truck, etc. |
|
MaskRCNN-ResNet50 |
1 |
85% mAP |
Creates segmentation masks around people, provides pixel |
|
Vanilla Unet Dynamic |
2 |
92% mIOU |
Creates semantic segmentation masks for people. |
|
Shuffle Unet |
2 |
87% mIOU |
Creates semantic segmentation masks for people. |
|
DetectNet_v2-ResNet18 |
1 |
98% mAP |
Detecting and localizing License plates on vehicles |
|
Tuned ResNet18 |
36(US) / 68(CH) |
97%(US)/99%(CH) |
Recognize License plates numbers |
|
Four branch AlexNet based model |
NA |
6.5 RMSE |
Detects person’s eye gaze |
|
Recombinator networks |
NA |
6.1 pixel error |
Estimates key points on person’s face |
|
Two branch model with attention |
NA |
0.7 BPM |
Estimates person’s heartrate from RGB video |
|
ResNet18 |
6 |
0.85 F1 score |
Recognize hand gestures |
|
5 Fully Connected Layers |
6 |
0.91 F1 score |
Recognize facial Emotion |
|
DetectNet_v2-ResNet18 |
1 |
85.3 mAP |
Detect faces from RGB or grayscale image |
|
Single shot bottom-up |
18 |
56.1% mAP* |
Estimates body key points for persons in the image |
|
ST-Graph Convolutional Network |
6 |
89.53% |
Classify poses of people from their skeletons |
|
PointPillars |
65.22 mAP |
Detect objects from Lidar point cloud |
The accuracy reported for BodyPoseNet is based on a model trained using the COCO dataset. To reproduce the same accuracy, use the sample notebook.
Performance Metrics
The performance of these pretrained models across various NVIDIA platforms is summarized in the table below. The numbers in the table are the inference performance measured using the trtexec tool in TensorRT samples.
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
8 |
218 |
8 |
128 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
8 |
169 |
8 |
94 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
8 |
79 |
8 |
46 |
TrafficCamNet |
960x544x3 |
INT8 |
8 |
251 |
8 |
174 |
DashCamNet |
960x544x3 |
INT8 |
16 |
251 |
32 |
172 |
FaceDetect-IR |
384x240x3 |
INT8 |
32 |
1407 |
32 |
974 |
VehilceMakeNet |
224x224x3 |
INT8 |
32 |
2434 |
32 |
1166 |
VehicleTypeNet |
224x224x3 |
INT8 |
32 |
1781 |
32 |
1064 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
16 |
395 |
16 |
268 |
License Plate Detection |
640x480x3 |
INT8 |
16 |
784 |
16 |
388 |
License Plate Recognition |
96x48x3 |
FP16 |
16 |
706 |
– |
– |
Facial landmark |
80x80x1 |
FP16 |
16 |
1105 |
– |
– |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
32 |
812 |
– |
– |
GestureNet |
160x160x3 |
FP16 |
32 |
2585 |
– |
– |
BodyPose |
288x384x3 |
INT8 |
4 |
104 |
– |
– |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
16 |
245 |
– |
– |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
21 |
– |
– |
Action Recognition 2D OF |
224x224x96 |
FP16 |
16 |
317 |
– |
– |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
8 |
25 |
– |
– |
Point Pillar |
FP16 |
1 |
25 |
– |
– |
|
Pose classification |
FP16 |
8 |
87 |
– |
– |
|
3D Pose - Accuracy |
FP16 |
16 |
117 |
– |
– |
|
3D Pose - Performance |
FP16 |
16 |
147 |
– |
– |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
16 |
199 |
– |
– |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
4 |
15 |
– |
– |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
16 |
390 |
16 |
164 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
16 |
296 |
16 |
122 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
8 |
136 |
4 |
58 |
TrafficCamNet |
960x544x3 |
INT8 |
16 |
458 |
16 |
220 |
DashCamNet |
960x544x3 |
INT8 |
16 |
442 |
16 |
228 |
FaceDetect-IR |
384x240x3 |
INT8 |
64 |
2575 |
64 |
1266 |
VehilceMakeNet |
224x224x3 |
INT8 |
64 |
4342 |
64 |
1508 |
VehicleTypeNet |
224x224x3 |
INT8 |
64 |
3281 |
64 |
1412 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
32 |
719 |
32 |
354 |
License Plate Detection |
640x480x3 |
INT8 |
32 |
1370 |
32 |
512 |
License Plate Recognition |
96x48x3 |
FP16 |
32 |
1190 |
– |
– |
Facial landmark |
80x80x1 |
FP16 |
32 |
2069 |
– |
– |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
64 |
1387 |
– |
– |
GestureNet |
160x160x3 |
FP16 |
64 |
4429 |
– |
– |
BodyPose |
288x384x3 |
INT8 |
8 |
172 |
– |
– |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
16 |
471 |
– |
– |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
32 |
– |
– |
Action Recognition 2D OF |
224x224x96 |
FP16 |
16 |
658 |
– |
– |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
4 |
41 |
– |
– |
Point Pillar |
FP16 |
1 |
40 |
– |
– |
|
Pose classification |
FP16 |
8 |
150 |
– |
– |
|
3D Pose - Accuracy |
FP16 |
16 |
188 |
– |
– |
|
3D Pose - Performance |
FP16 |
16 |
235 |
– |
– |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
16 |
356 |
– |
– |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
4 |
25 |
– |
– |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
16 |
400 |
16 |
300 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
314 |
32 |
226 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
16 |
140 |
32 |
70 |
TrafficCamNet |
960x544x3 |
INT8 |
16 |
457 |
16 |
352 |
DashCamNet |
960x544x3 |
INT8 |
32 |
479 |
64 |
358 |
FaceDetect-IR |
384x240x3 |
INT8 |
64 |
2588 |
64 |
1700 |
VehilceMakeNet |
224x224x3 |
INT8 |
64 |
4261 |
64 |
2218 |
VehicleTypeNet |
224x224x3 |
INT8 |
64 |
3391 |
64 |
2044 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
32 |
613 |
32 |
492 |
License Plate Detection |
640x480x3 |
INT8 |
32 |
32 |
||
License Plate Recognition |
96x48x3 |
FP16 |
128 |
1498 |
– |
– |
Facial landmark |
80x80x1 |
FP16 |
32 |
1606 |
– |
– |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
64 |
1241 |
– |
– |
GestureNet |
160x160x3 |
FP16 |
64 |
5420 |
– |
– |
BodyPose |
288x384x3 |
INT8 |
16 |
195 |
– |
– |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
32 |
577 |
– |
– |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
38 |
– |
– |
Action Recognition 2D OF |
224x224x96 |
FP16 |
16 |
826 |
– |
– |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
4 |
42 |
– |
– |
Point Pillar |
FP16 |
1 |
38 |
– |
– |
|
Pose classification |
FP16 |
8 |
105 |
– |
– |
|
3D Pose - Accuracy |
FP16 |
16 |
241 |
– |
– |
|
3D Pose - Performance |
FP16 |
16 |
295 |
– |
– |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
16 |
289 |
– |
– |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
4 |
27 |
– |
– |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
DLA1 + DLA2 BS |
DLA1 + DLA2 FPS |
|---|---|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
32 |
1116 |
32 |
528 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
890 |
32 |
404 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
16 |
421 |
32 |
104 |
TrafficCamNet |
960x544x3 |
INT8 |
32 |
1268 |
32 |
594 |
DashCamNet |
960x544x3 |
INT8 |
32 |
1308 |
64 |
587 |
FaceDetect-IR |
384x240x3 |
INT8 |
128 |
7462 |
128 |
2720 |
VehilceMakeNet |
224x224x3 |
INT8 |
128 |
11872 |
128 |
3956 |
VehicleTypeNet |
224x224x3 |
INT8 |
128 |
9815 |
128 |
3494 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
64 |
1700 |
64 |
870 |
License Plate Detection |
640x480x3 |
INT8 |
64 |
64 |
||
License Plate Recognition |
96x48x3 |
FP16 |
128 |
4118 |
– |
– |
Facial landmark |
80x80x1 |
FP16 |
64 |
– |
– |
|
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
128 |
3226 |
– |
– |
GestureNet |
160x160x3 |
FP16 |
128 |
15133 |
– |
– |
BodyPose |
288x384x3 |
INT8 |
16 |
559 |
– |
– |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
64 |
1577 |
– |
– |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
8 |
105 |
– |
– |
Action Recognition 2D OF |
224x224x96 |
FP16 |
32 |
1702 |
– |
– |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
4 |
109 |
– |
– |
Point Pillar |
FP16 |
1 |
90 |
– |
– |
|
Pose classification |
FP16 |
16 |
262 |
– |
– |
|
3D Pose - Accuracy |
FP16 |
16 |
597 |
– |
– |
|
3D Pose - Performance |
FP16 |
16 |
711 |
– |
– |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
32 |
703 |
– |
– |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
4 |
75 |
– |
– |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
64 |
1379 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
1064 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
32 |
465 |
TrafficCamNet |
960x544x3 |
INT8 |
64 |
1725 |
DashCamNet |
960x544x3 |
INT8 |
64 |
1676 |
FaceDetect-IR |
384x240x3 |
INT8 |
128 |
9810 |
VehilceMakeNet |
224x224x3 |
INT8 |
256 |
16500 |
VehicleTypeNet |
224x224x3 |
INT8 |
128 |
12500 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
64 |
2578 |
License Plate Detection |
640x480x3 |
INT8 |
128 |
6123 |
License Plate Recognition |
96x48x3 |
FP16 |
128 |
3959 |
Facial landmark |
80x80x1 |
FP16 |
128 |
4622 |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
512 |
4563 |
GestureNet |
160x160x3 |
FP16 |
512 |
15377 |
BodyPose |
288x384x3 |
INT8 |
32 |
598 |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
16 |
1897 |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
139 |
Action Recognition 2D OF |
224x224x96 |
FP16 |
32 |
3320 |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
16 |
192 |
Point Pillar |
FP16 |
1 |
111 |
|
Pose classification |
FP16 |
64 |
376.4 |
|
3D Pose - Accuracy |
FP16 |
32 |
614.98 |
|
3D Pose - Performance |
FP16 |
32 |
712.94 |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
64 |
1027.85 |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
16 |
79.08 |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
128 |
8500 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
64 |
6245 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
64 |
3291 |
TrafficCamNet |
960x544x3 |
INT8 |
256 |
9717 |
DashCamNet |
960x544x3 |
INT8 |
256 |
9500 |
FaceDetect-IR |
384x240x3 |
INT8 |
256 |
51600 |
VehilceMakeNet |
224x224x3 |
INT8 |
1024 |
88300 |
VehicleTypeNet |
224x224x3 |
INT8 |
512 |
72300 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
256 |
14900 |
License Plate Detection |
640x480x3 |
INT8 |
256 |
23200 |
License Plate Recognition |
96x48x3 |
FP16 |
256 |
27200 |
Facial landmark |
80x80x1 |
FP16 |
256 |
19600 |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
1024 |
25394 |
GestureNet |
160x160x3 |
FP16 |
1024 |
94555 |
BodyPose |
288x384x3 |
INT8 |
16 |
3180 |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
32 |
12600 |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
16 |
797 |
Action Recognition 2D OF |
224x224x96 |
FP16 |
64 |
17535 |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
16 |
899 |
Point Pillar |
FP16 |
1 |
425 |
|
Pose classification |
FP16 |
64 |
2144.84 |
|
3D Pose - Accuracy |
FP16 |
32 |
3466.34 |
|
3D Pose - Performance |
FP16 |
32 |
4176.37 |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
64 |
5745.79 |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
16 |
496.34 |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
64 |
4228 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
3160 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
32 |
1603 |
TrafficCamNet |
960x544x3 |
INT8 |
64 |
5082 |
DashCamNet |
960x544x3 |
INT8 |
64 |
4900 |
FaceDetect-IR |
384x240x3 |
INT8 |
128 |
27100 |
VehilceMakeNet |
224x224x3 |
INT8 |
256 |
46200 |
VehicleTypeNet |
224x224x3 |
INT8 |
128 |
37200 |
PeopleSegNet |
960x576x3 |
INT8 |
8 |
158529 |
FaceDetect |
736x416x3 |
INT8 |
64 |
7700 |
LPD |
640x480x3 |
INT8 |
128 |
12500 |
LPR |
96x48x3 |
FP16 |
128 |
12400 |
Facial landmark |
80x80x1 |
FP16 |
128 |
12400 |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
512 |
12321 |
GestureNet |
160x160x3 |
FP16 |
512 |
47361 |
BodyPose |
288x384x3 |
INT8 |
32 |
1596 |
AR 2D |
224x224x96 |
FP16 |
16 |
6000 |
AR 3D |
224x224x32x3 |
FP16 |
4 |
380 |
AR 2D OF |
224x224x96 |
FP16 |
32 |
8940 |
AR 3D OF |
224x224x32x3 |
FP16 |
16 |
461 |
Point Pillar |
FP16 |
1 |
271 |
|
Pose classification |
FP16 |
64 |
1121.68 |
|
3D Pose - Accuracy |
FP16 |
32 |
1913.92 |
|
3D Pose - Performance |
FP16 |
32 |
2241.83 |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
64 |
2862.76 |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
16 |
253.77 |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
64 |
3819 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
2568 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
32 |
1007 |
TrafficCamNet |
960x544x3 |
INT8 |
64 |
4754 |
DashCamNet |
960x544x3 |
INT8 |
64 |
4600 |
FaceDetect-IR |
384x240x3 |
INT8 |
128 |
26900 |
VehilceMakeNet |
224x224x3 |
INT8 |
256 |
44800 |
VehicleTypeNet |
224x224x3 |
INT8 |
256 |
31500 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
64 |
6000 |
License Plate Detection |
640x480x3 |
INT8 |
256 |
13900 |
License Plate Recognition |
96x48x3 |
FP16 |
256 |
9000 |
Facial landmark |
80x80x1 |
FP16 |
512 |
9600 |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
512 |
10718 |
GestureNet |
160x160x3 |
FP16 |
512 |
35371 |
BodyPose |
288x384x3 |
INT8 |
32 |
1334 |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
16 |
4600 |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
265 |
Action Recognition 2D OF |
224x224x96 |
FP16 |
32 |
6500 |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
16 |
284 |
Point Pillar |
FP16 |
1 |
246 |
|
Pose classification |
FP16 |
64 |
825.75 |
|
3D Pose - Accuracy |
FP16 |
32 |
1286.05 |
|
3D Pose - Performance |
FP16 |
32 |
1558.21 |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
64 |
2429.62 |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
16 |
180.04 |
Model arch |
Inference resolution |
Precision |
GPU BS |
GPU FPS |
|---|---|---|---|---|
PeopleNet-ResNet18 |
960x544x3 |
INT8 |
32 |
749 |
PeopleNet-ResNet34 (v2.3) |
960x544x3 |
INT8 |
32 |
581 |
PeopleNet-ResNet34 (v2.5 unpruned) |
960x544x3 |
INT8 |
32 |
231 |
TrafficCamNet |
960x544x3 |
INT8 |
32 |
916 |
DashCamNet |
960x544x3 |
INT8 |
32 |
865 |
FaceDetect-IR |
384x240x3 |
INT8 |
64 |
4982 |
VehilceMakeNet |
224x224x3 |
INT8 |
128 |
8000 |
VehicleTypeNet |
224x224x3 |
INT8 |
128 |
6302 |
FaceDetect (pruned) |
736x416x3 |
INT8 |
32 |
1174 |
License Plate Detection |
640x480x3 |
INT8 |
128 |
2570 |
License Plate Recognition |
96x48x3 |
FP16 |
128 |
2180 |
Facial landmark |
80x80x1 |
FP16 |
256 |
2800 |
GazeNet |
224x224x1, 224x224x1, 224x224x1, 25x25x1 |
FP16 |
256 |
2488 |
GestureNet |
160x160x3 |
FP16 |
256 |
7690 |
BodyPose |
288x384x3 |
INT8 |
16 |
278 |
Action Recognition 2D RGB |
224x224x96 |
FP16 |
8 |
1044 |
Action Recognition 3D RGB |
224x224x32x3 |
FP16 |
4 |
56 |
Action Recognition 2D OF |
224x224x96 |
FP16 |
16 |
1419 |
Action Recognition 3D OF |
224x224x32x3 |
FP16 |
2 |
58 |
Point Pillar |
FP16 |
1 |
63 |
|
Pose classification |
FP16 |
64 |
211.5 |
|
3D Pose - Accuracy |
FP16 |
32 |
370.13 |
|
3D Pose - Performance |
FP16 |
32 |
471.81 |
|
PeopleSemSegNet_v2 - Shuffle |
960x544x3 |
FP16 |
16 |
631.31 |
PeopleSemSegNet_v2 - Vanilla |
960x544x3 |
FP16 |
16 |
44.09 |
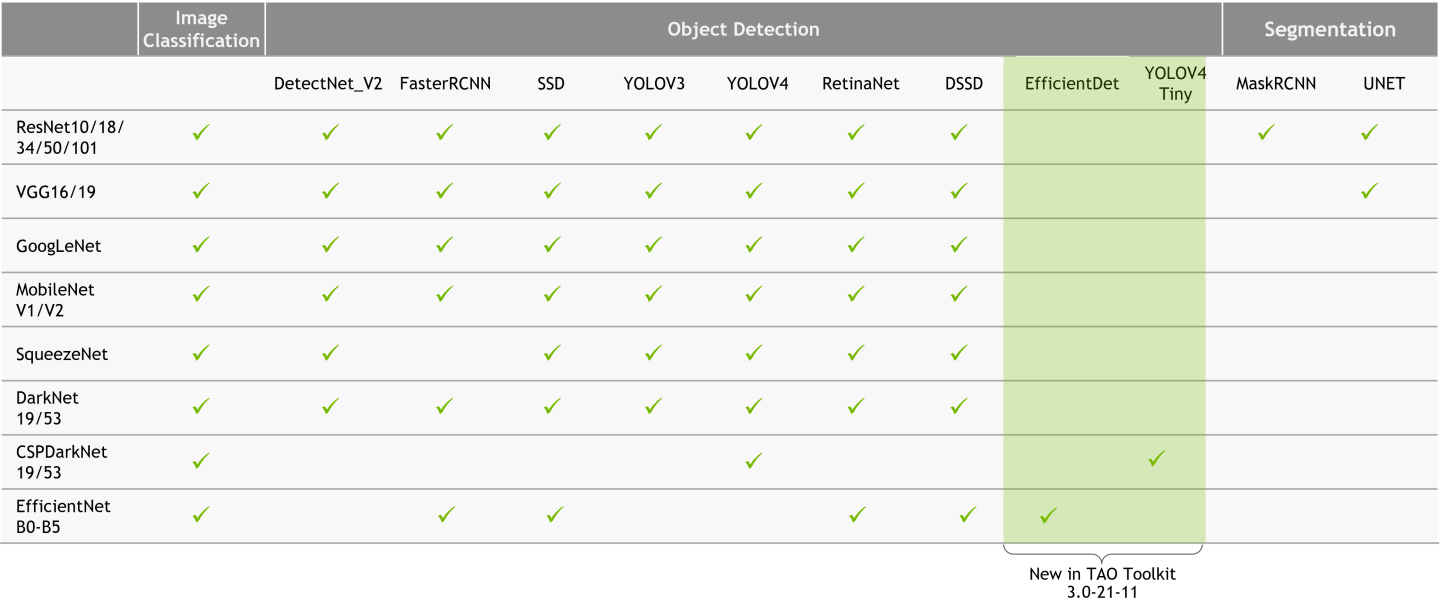
General purpose computer vision models
With general purpose models, you can train an image classification model, object detection model, or an instance segmentation model.
For classification, you can train using one of the available architectures such as ResNet, EfficientNet, VGG, MobileNet, GoogLeNet, SqueezeNet, or DarkNet.
For object detection tasks, you can choose from the popular YOLOv3/v4/v4-tiny, FasterRCNN, SSD, RetinaNet, and DSSD architectures, as well as NVIDIA’s own DetectNet_v2 architecture.
For instance segmentation, you can use MaskRCNN for instance segmentation or UNET for semantic segmentation.
This gives you the flexibility and control to build AI models for any number of applications, from smaller, light-weight models for edge GPUs to larger models for more complex tasks. For all the permutations and combinations, refer to the table below and see the Open Model Architectures section.
TAO Toolkit 3.0-22.05
Computer Vision Feature Summary
The table below summarizes the computer vision models and the features enabled.
CV Task |
Model |
New in 22-04 |
Pruning |
QAT |
REST API |
Channel-wise QAT |
Class weighting |
Visualization |
BYOM |
Multi-node |
Multi-GPU |
AMP |
Early Stopping |
Framework |
Annotation Format |
DLA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Classification |
ResNet10/18/34/50/101 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
VGG16/19 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
GoogleNet |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
MobileNet_v1/v2 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
SqueezeNet |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
DarkNet19/53 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
EfficientNet_B0-B7 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
CSPDarkNet19/53 |
No |
yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Classification |
CSPDarkNet-Tiny |
No |
Yes |
No |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
No |
tf1 |
ImageNet |
yes |
Object Detection |
YoloV3 |
No |
yes |
yes |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
No |
tf1 |
KITTI/COCO |
yes |
Object Detection |
YoloV4 |
No |
yes |
yes |
yes |
no |
yes |
yes |
No |
yes |
yes |
yes |
Yes |
tf1 |
KITTI/COCO |
yes |
Object Detection |
YoloV4 - Tiny |
No |
yes |
yes |
yes |
no |
yes |
yes |
No |
yes |
yes |
yes |
Yes |
tf1 |
KITTI/COCO |
yes |
Object Detection |
FasterRCNN |
No |
yes |
yes |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
yes |
tf1 |
KITTI/COCO |
yes |
Object Detection |
EfficientDet |
No |
yes |
no |
yes |
no |
no |
no |
No |
yes |
yes |
yes |
no |
tf1 |
COCO |
yes |
Object Detection |
RetinaNet |
No |
yes |
yes |
yes |
no |
yes |
yes |
No |
yes |
yes |
yes |
yes |
tf1 |
KITTI/COCO |
yes |
Object Detection |
DetectNet_v2 |
No |
yes |
yes |
yes |
no |
yes |
yes |
No |
yes |
yes |
yes |
no |
tf1 |
KITTI/COCO |
yes |
Object Detection |
SSD |
No |
yes |
yes |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
yes |
tf1 |
KITTI/COCO |
yes |
Object Detection |
DSSD |
No |
yes |
yes |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
yes |
tf1 |
KITTI/COCO |
yes |
Multitask classification |
All classification |
No |
yes |
no |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
no |
tf1 |
Custom |
yes |
Instance Segmentation |
MaskRCNN |
No |
yes |
no |
yes |
no |
no |
yes |
No |
yes |
yes |
yes |
no |
tf1 |
COCO |
no |
Semantic Segmentation |
UNET |
No |
yes |
yes |
yes |
no |
no |
yes |
yes |
yes |
yes |
yes |
no |
tf1 |
CityScape - PNG |
no |
Character Recognition |
LPRNet |
No |
no |
no |
yes |
no |
no |
yes |
no |
yes |
yes |
yes |
yes |
tf1 |
Custom - txt file |
no |
Key Points |
2D body pose |
No |
yes |
no, but PTQ |
no |
no |
no |
no |
no |
yes |
yes |
yes |
no |
tf1 |
COCO |
no |
Key Points |
2D body pose |
No |
yes |
no, but PTQ |
no |
no |
no |
no |
no |
yes |
yes |
yes |
no |
tf1 |
COCO |
no |
Point Cloud |
PointPillars |
Yes |
Yes |
no |
no |
no |
no |
no |
no |
yes |
yes |
yes |
no |
pyt |
KITTI |
no |
Action Recognition |
2D action recognition RGB |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
pyt |
Custom |
no |
Action Recognition |
3D action recognition RGB |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
pyt |
Custom |
no |
Action Recognition |
2D action recognition OF |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
pyt |
Custom |
no |
Action Recognition |
3D action recognition OF |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
pyt |
Custom |
no |
Other |
Pose action classification |
Yes |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
pyt |
COCO |
no |
Other |
HeartRateNet |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
tf1 |
NVIDIA Defined |
no |
Other |
GazeNet |
No |
no |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
no |
tf1 |
NVIDIA Defined |
no |
Other |
EmotionNet |
No |
no |
no |
no |
no |
no |
yes |
no |
no |
no |
yes |
no |
tf1 |
NVIDIA Defined |
no |
Other |
GestureNet |
No |
no |
no |
no |
no |
no |
no |
no |
yes |
yes |
yes |
no |
tf1 |
NVIDIA Defined |
no |
Model Name |
Base Architecture |
Dataset |
Purpose |
|---|---|---|---|
Jasper |
ASR Set 1.2 with Noisy (profiles: room reverb, echo, wind, keyboard, baby crying) - 7K hours |
Speech Transcription |
|
Quartznet |
ASR Set 1.2 |
Speech Transcription |
|
CitriNet |
ASR Set 1.4 |
Speech Transcription |
|
Conformer |
ASR Set 1.4 |
Speech Transcription |
|
BERT |
SQuAD 2.0 |
Answering questions in SQuADv2.0, a reading comprehension dataset consisting of Wikipedia articles. |
|
BERT Large |
SQuAD 2.0 |
Answering questions in SQuADv2.0, a reading comprehension dataset consisting of Wikipedia articles. |
|
Megatron |
SQuAD 2.0 |
Answering questions in SQuADv2.0, a reading comprehension dataset consisting of Wikipedia articles. |
|
BERT |
GMB (Gronigen Meaning Book) |
Identifying entities in a given text (Supported Categories: Geographical Entity, Organization, Person , Geopolitical Entity, Time Indicator, Natural Phenomenon/Event) |
|
BERT |
Proprietary |
Classifying an intent and detecting all relevant slots (Entities) for this Intent in a query. Intent and slot names are usually task specific. This model recognizes weather related intents like weather, temperature, rainfall etc. and entities like place, time, unit of temperature etc. For a comprehensive list, please check the corresponding model card. |
|
BERT |
Tatoeba sentences, Books from the Project Gutenberg that were used as part of the LibriSpeech corpus, Transcripts from Fisher English Training Speech |
Add punctuation and capitalization to text. |
|
BERT |
Proprietary |
For domain classification of queries into the 4 supported domains: weather, meteorology, personality, and none. |