TensorRT
NVIDIA TensorRT is an SDK for high-performance deep learning inference. TensorRT provides APIs and parsers to import trained models from all major deep learning frameworks. It then generates optimized runtime engines deployable in the datacenter as well as in automotive and embedded environments. To understand TensorRT and it’s capabilities better, refer to the official TensorRT documentation.
The models trained in TAO Toolkit are deployed to NVIDIA’s Inference SDK’s such as DeepStream, Riva etc
via TensorRT. While the conversational AI models trained using TAO Toolkit can be consumed via TensorRT only via Riva,
the computer vision models trained by TAO Toolkit can be consumed by TensorRT, via the tao-converter tool. The
TAO Converter parses the exported .etlt model file, and generates an optimized TensorRT engine. These engines
can be generated to support inference at low precision, such as FP16 or INT8.
While most of the TAO models support direct integration of the .etlt files to DeepStream 6.0, DeepStream can also
consume the optimized engine generated by the tao-converter.
The TensorRT engines generated by this tao-converter are specific to the GPU that it was generated on. So,
based on the platform that the model is being deployed to, you will need to download the specific version of
the tao-converter and generate the engine there.
The TAO models from TAO 3.0-21.11 have been verified to integrate with TensorRT version 7.0, 7.1, 7.2 and 8.0.
Even though TensorRT contains optimized implementations for several common operations used in Deep Neural Networks(DNNs),
with Deep Learning being such a quickly evolving discipline, TensorRT provides users a method to bring in new operations
via to the model graph via custom TensorRT Plugins. Several samples of these custom plug-ins are hosted on
GitHub under the repository called TensorRT OSS.
Instructions to build and install TensorRT OSS can be found in this repository.
The TAO applications that require TensorRT OSS are:
FasterRCNN
SSD
DSSD
YOLOv3
YOLOv4
YOLOv4-tiny
RetinaNet
MaskRCNN
EfficientDet
PointPillars
The TAO Converter is distributed as a separate binary for x86 and Jetson platforms. The tao-converter binaries are available as an NGC resource.
TensorRT |
TAO converter version |
|---|---|
7.2 |
v3.21.08_trt7.2_x86 |
7.1 |
v3.21.08_trt7.1_x86 |
8.0 |
v3.21.11_trt8.0_x86 |
8.2 |
v3.21.11_trt8.2_x86 |
8.4 |
v3.21.11_trt8.4_x86 |
Platform |
TensorRT version |
TAO converter version |
|---|---|---|
Jetson |
7.1 |
v3.21.11_trt7.1_aarch64 |
Jetson |
8.0 |
v3.21.11_trt8.0_aarch64 |
Jetson |
8.4 |
v3.22.05_trt8.4_aarch64 |
AGX (Jetson + dGPU) |
7.1 |
v3.21.11_trt7.1_agx |
Installing on an x86 platform
For an x86 platform with discrete GPUs, the default TAO package includes the tao-converter
built for TensorRT 8.2.5.1 with CUDA 11.4 and CUDNN 8.2. However, for any other version of CUDA and
TensorRT, please refer to the overview section for download. Once the
tao-converter is downloaded, follow the instructions below to generate a TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/x86_64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/x86_64-linux-gnu”
Run the
tao-converterusing the sample command below and generate the engine.Instructions to build TensorRT OSS on Jetson can be found in the TensorRT OSS on x86 section above or in this GitHub repo.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Installing on an jetson platform
For the Jetson platform, the tao-converter is available to download in the NVIDIA developer zone. You may choose
the version you wish to download as listed in the overview section.
Once the tao-converter is downloaded, please follow the instructions below to generate a
TensorRT engine.
Unzip the zip file on the target machine.
Install the OpenSSL package using the command:
sudo apt-get install libssl-dev
Export the following environment variables:
$ export TRT_LIB_PATH=”/usr/lib/aarch64-linux-gnu”
$ export TRT_INC_PATH=”/usr/include/aarch64-linux-gnu”
For Jetson devices, TensorRT comes pre-installed with Jetpack. If you are using older JetPack, upgrade to JetPack-5.0DP.
Instructions to build TensorRT OSS on Jetson can be found in the TensorRT OSS on Jetson (ARM64) section above or in this GitHub repo.
Run the
tao-converterusing the sample command below and generate the engine.
Make sure to follow the output node names as mentioned in Exporting the Model
section of the respective model.
Due to changes in the TensorRT API between versions 8.0.x and 7.2.x,
the deployable models generated using the export task in TAO Toolkit 3.0-21.11+
can only be deployed in DeepStream version 6.0. Inorder to deploy the models compatible
with DeepStream 5.1 from the table above with DeepStream 5.1, you will need to run the
corresponding tao <model> export task using the TAO Toolkit 3.0-21.08 package to re-generate
a deployable model and calibration cache file that is compatible with TensorRT 7.2.
Similarly, if you have a model trained with TAO Toolkit 3.0-21.08 package and want to deploy
to DeepStream 6.0, please regenerate the deployable model.etlt and int8 calibration
file using the corresponding tao <model> export task in TAO Toolkit 3.0-21.11+
TAO Toolkit 3.0-21.11+ was built with TensorRT 8.0.1.6.
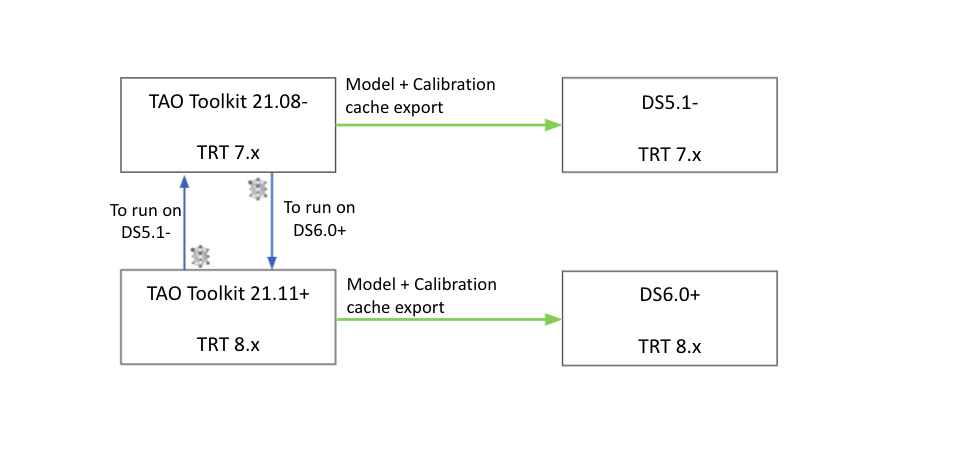
TAO Toolkit -> DeepStream version interoperability
To downgrade to the 3.0-21.08 or 3.0-21.11 package, please instantiate a new virtual environment by following the instructions in the Quick Start Guide and run the following commands
pip3 install nvidia-pyindex
pip3 install nvidia-tao==0.1.19 # for 3.0-21.08
pip3 install nvidia-tao==0.1.20 # for 3.0-21.11
Using the tao-converter
tao-converter [-h] -k <encryption_key>
-d <input_dimensions>
-o <comma separated output nodes>
[-c <path to calibration cache file>]
[-e <path to output engine>]
[-b <calibration batch size>]
[-m <maximum batch size of the TRT engine>]
[-t <engine datatype>]
[-w <maximum workspace size of the TRT Engine>]
[-i <input dimension ordering>]
[-p <optimization_profiles>]
[-s]
[-u <DLA_core>]
input_file
Required Arguments
input_file: Path to the.etltmodel exported usingtao <model> export.-k: The key used to encode the.tltmodel when doing the training.-d: Comma-separated list of input dimensions that should match the dimensions used fortao <model> export.-o: Comma-separated list of output blob names that should match the output configuration used fortao <model> export.
Optional Arguments
-e: Path to save the engine to. (default:./saved.engine)-t: Desired engine data type, generates calibration cache if in INT8 mode. The default value isfp32. The options are {fp32,fp16,int8}.-w: Maximum workspace size for the TensorRT engine. The default value is1073741824(1<<30).-i: Input dimension ordering, all other TAO commands use NCHW. The default value isnchw. The options are {nchw,nhwc,nc}.-p: Optimization profiles for.etltmodels with dynamic shape. Comma separated list of optimization profile shapes in the format<input_name>,<min_shape>,<opt_shape>,<max_shape>, where each shape has the format:<n>x<c>x<h>x<w>. Can be specified multiple times if there are multiple input tensors for the model. This is only useful for new models introduced in TAO Toolkit 3.21.08. This parameter is not required for models that are already existed in TAO Toolkit 2.0.-s: TensorRT strict type constraints. A Boolean to apply TensorRT strict type constraints when building the TensorRT engine.-u: Use DLA core. Specifying DLA core index when building the TensorRT engine on Jetson devices.
INT8 Mode Arguments
-c: Path to calibration cache file, only used in INT8 mode. The default value is./cal.bin.-b: Batch size used during the export step for INT8 calibration cache generation. (default:8).-m: Maximum batch size for TensorRT engine.(default:16). If meet with out-of-memory issue, decrease the batch size accordingly. This parameter is not required for.etltmodels generated with dynamic shape. (This is only possible for new models introduced in TAO Toolkit 3.21.08.)
The usage for each TAO Computer Vision is explained in the respective models chapter.