BYOM Converter
Bring Your Own Model (BYOM) is a Python-based package that converts any open-source ONNX model to a
TAO-comaptible model. The TAO BYOM Converter provides a CLI to import an ONNX model and convert it to
Keras. The converted model is stored in .tltb format, which is based on EFF.
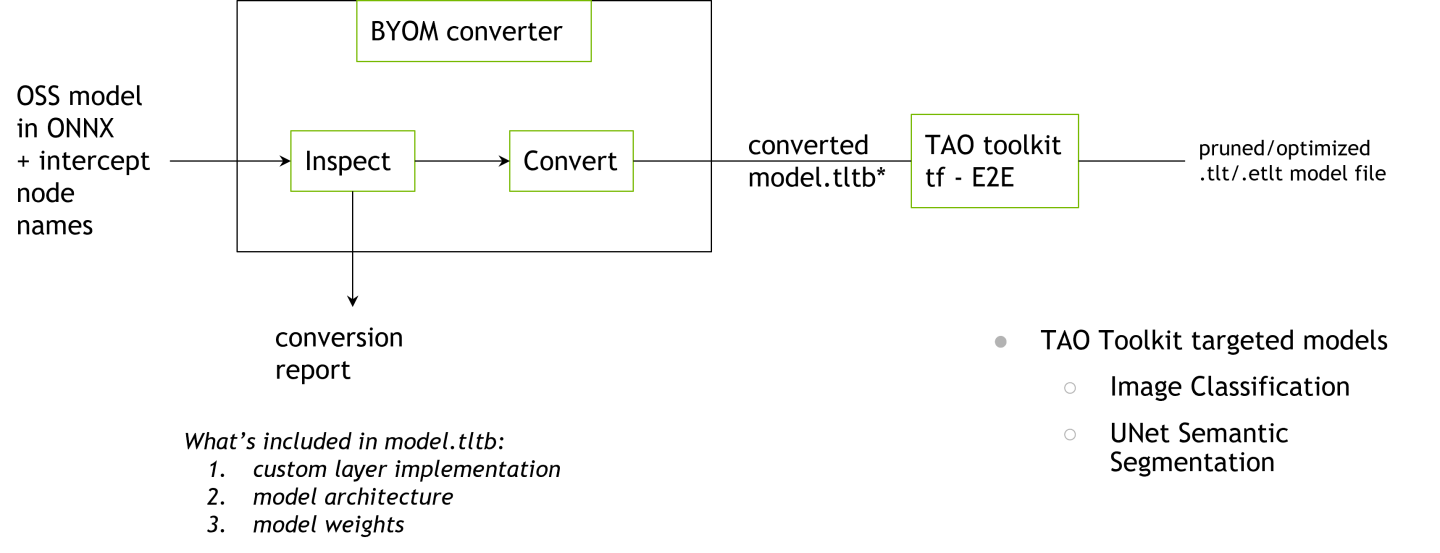
Currently, the following models are supported by the TAO BYOM Converter:
Classification
UNet
More tasks supported by the TAO Toolkit, such as Object Detection, will be added in future releases.
Software Requirements
Software |
Version |
python |
>=3.6.9 <3.7 |
python-pip |
>21.06 |
nvidia-pyindex |
>=1.0 |
Installing through pip
The TAO BYOM Converter is a Python pip package that is hosted on the official PyPI. It is a Python 3 only package, capable of running on python 3.6.
Create a new
condaenvironment usingminiconda.Follow the instructions in this link to set up a conda environemnt using a miniconda.
Once you have installed
miniconda, create a new environment by setting the Python version to 3.6.conda create -n launcher python=3.6
Activate the
condaenvironment that you have just created.conda activate launcher
Once you have activated your
condaenvironemnt, the command prompt should show the name of your conda environment.(launcher) py-3.6.9 desktop:
When you are done with you session, you may deactivate your
condaenvironemnt using thedeactivatecommand:conda deactivate
You may re-instantiate this created
condaenvironemnt using the following command.
conda activate launcher
Install the Tensorflow 1.15.x package from NVIDIA, which is hosted on
nvidia-pyindex.pip3 install nvidia-pyindex pip3 install nvidia-tensorflow
Install the TAO BYOM Converter Python package, called
nvidia-tao-byom.pip3 install nvidia-tao-byom
NoteIf you had installed an older version of the
nvidia-tao-byomlauncher, you may upgrade to the latest version by running the following command.pip3 install --upgrade nvidia-tao-byom
Invoke the entrypoints using the
tao_byomcommand.tao_byom --help
The sample output of the above command is as follows:
usage: BYOM Converter [-h] -m ONNX_MODEL_FILE -n MODEL_NAME -r RESULTS_DIR [--verbose] [-c CUSTOM_META] [-k KEY] [-p PENULTIMATE_NODE] [-ki {glorot_uniform,glorot_normal,he_uniform,he_normal, \ zeros,random_uniform,random_normal,constant,ones,identity}] [-fn [FREEZE_NODE [FREEZE_NODE ...]]] [-fb] Convert onnx model into TAO Model. optional arguments: -h, --help show this help message and exit -m ONNX_MODEL_FILE, --onnx_model_file ONNX_MODEL_FILE Onnx model path to the pre-trained weights. -n MODEL_NAME, --model_name MODEL_NAME Name of the architecure inside onnx file -r RESULTS_DIR, --results_dir RESULTS_DIR Path to a folder where converted Keras model will be stored. --verbose log level NOTSET -c CUSTOM_META, --custom_meta CUSTOM_META Path to custom meta json file that contains info about custom layer implementation -k KEY, --key KEY Key to encrpyt tltb file -p PENULTIMATE_NODE, --penultimate_node PENULTIMATE_NODE Name of ONNX node corresponding to the penultimate layer -ki {glorot_uniform,glorot_normal,he_uniform,he_normal,zeros,random_uniform,\ random_normal,constant,ones,identity}, \ --kernel_initializer {glorot_uniform,glorot_normal, he_uniform,\ he_normal,zeros,random_uniform,random_normal,constant,ones,identity} Type of kernel initializer used to initialize Conv, ConvTranspose, and Gemm -fn [FREEZE_NODE [FREEZE_NODE ...]], --freeze_node [FREEZE_NODE [FREEZE_NODE ...]] List of ONNX nodes to freeze. Examples: -i item1 item2 -fb, --freeze_bn Whether to freeze every BatchNorm in the model.
If you install the TAO BYOM Converter in the native Python 3 enivornment on your host machine , as
opposed to the recommended route of using a virtual environment, you may get an error stating that
the tao_byom binary wasn’t found. This is because the path to your tao_byom binary
installed by pip wasn’t added to the PATH environment variable in your local machine. In
this case, run the following command:
export PATH=$PATH:~/.local/bin
You will need an ONNX model to run the TAO BYOM Converter. There are multiple ways to get an ONNX model for model architectures you want. You may first look through models supported in the official ONNX model zoo. ONNX provides various vision model architectures that were exported from different Deep Learning frameworks.
In addition to the official ONNX model website, you can also export your model from the framework of your choice to ONNX. For PyTorch, refer to their API for exporting to ONNX. For Tensorflow, refer to ONNX supported library called tensorflow-onnx.
Currently, only channel_first models are supported. This means that the input shape of your model should be
(N, C, H, W). If you wish to convert a TensorFlow-based model, set the keras.backend.set_image_data_format('channels_first')
property. In addition, TAO BYOM Converter has been tested on opset version from 9 to 13.
If your opset version is either lower than 9 or higher than 13, run this version conversion script
from ONNX to convert the ONNX model to an appropriate version.
Use the tao_byom command to convert an open-source ONNX model to TAO comaptible model:
tao_byom [-h] -m <onnx model path>
-k <encoding key>
-r <result directory>
-n <name of the model>
[-p <name of penultimate ONNX node>]
[-c <custom meta json>]
[-ki <type of kernel initialization>]
[-fn <list of ONNX nodes to freeze>]
[-fb]
[--verbose]
Required Arguments
-m, --onnx_model_file: The path to an ONNX model file-k, --key: A user-specific encoding key to save a.tltbmodel-r, --results_dir: The path to a folder where the converted outputs should be written-n, --model_name: The name of the model architecure
Optional Arguments
--penultimate_node, -p: The name of ONNX node corresponding to the penultimate. If provided, the converter will interecept the output to the provided node. Provide this argument if you want to finetune the open source model on a different dataset through the TAO Toolkit. The definition of--penultimate_nodecan vary depending on the task. For classification, it is often the last activation before the global average pooling. TAO Toolkit will add a layer at the end to update the size of the classification head depending on the number of classes in the target dataset. For UNet, it is the last convolution before the last softmax/sigmoid (if there’s an activation before the output).--custom_meta, -c: The path to a custom meta JSON file that contains information about custom layer implementation. Provide this argument if there’s an ONNX node that the BYOM Converter doesn’t currently support. You can bring your own implementations to extend the functionality of BYOM Converter. For more details, refer to the BYOM Example repo.--kernel_initializer, -ki: The type of kernel initializer used to initialize Conv, ConvTranspose, and Gemm. Available options are glorot_uniform, glorot_normal, he_uniform, he_normal, zeros, random_uniform, random_normal, constant, ones, identity. For more information about kernel initialization, refer to the Keras documentation.--freeze_node, -fn: A list of ONNX nodes to freeze. ONNX nodes are limited to trainable nodes (e.g. Conv, ConvTranspose, and Gemm). The weights of layers correspoinding to the provided ONNX nodes will not be updated during training. This argument is similar tofreeze_blocksin the classification model_config.--freeze_bn, -fb: A flag specifying whether to freeze every Batch Normalization in the model. This argument is similar tofreeze_bnin the classification model_config.--verbose: Prints detailed output. The log level is set toNOTSET.-h, --help: Prints the help message.
The BYOM package checks the correctness of the conversion by comparing the outputs of the original ONNX model with the converted TAO model. If the difference is larger than the set threshold of 1e-4, you will see the following message.
INFO: Difference between the original ONNX and converted Keras model is larger than the set threshold 0.0001 with error of 0.000356.
INFO: This may be due to difference in deep learning frameworks. If the error is not far from the threshold, you may proceed with
training with TAO Toolkit. If difference is large, please post an issue on the forum and link your original model.
As shown in the log message, you may proceed with finetuning the BYOM model through TAO Toolkit if the difference is below the threshold. Through the course of finetuning, the effect of this discrepency may diminish. If the difference is too large, please post an issue in the TAO Forum.
A sample workflow for converting open-source models through TAO BYOM Converter is described in the TAO BYOM Example repository.
The below table shows all supported ONNX operators in TAO BYOM. This may be updated in future releases. If you wish to add a new ONNX operator to TAO BYOM, refer to the example in the Bring your Own Layer section of the TAO BYOM documentation.
ONNX Operator |
Support Status |
Note |
|---|---|---|
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
Doesn’t support dilation!=1, group!=1, output_padding!=0 |
|
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
Doesn’t support multiple axes |
|
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |
||
Yes |