Spectrogram Generator
Spectrogram Generator models take in text input and generate a Mel spectrogram. There are several types of Spectrogram Generator architecture; TAO Toolkit supports the FastPitch architecture.
The FastPitch model generates Mel spectrograms and predicts a pitch contour from raw input text. It allows additional control over synthesized utterances through the following options:
Modify the pitch contour to control the prosody.
Increase or decrease the fundamental frequency in a natural way, which preserves the perceived identity of the speaker.
Alter the rate of speech.
Specify input as graphemes or phonemes.
Switch speakers (if the model has been trained with data from multiple speakers).
The following tasks have been implemented for FastPitch in the TAO Toolkit
download_specs
dataset_convert
train
infer
export
finetune
pitch_stats
Example specification files for all the tasks associated with the spectrogram generator component of TTS can be downloaded using the following command:
tao spectro_gen download_specs \
-o <target_path> \
-r <results_path>
Required Arguments
-o: The target path where the spec files will be stored-r: The results and output log directory
The spectrogram generator for TAO Toolkit implements the dataset_convert task to convert and
prepare datasets that follow the LJSpeech dataset format.
The dataset_convert task generates manifest files and .txt files with normalized
transcripts.
The dataset for TTS consists of a set of utterances in individual audio files (.wav) and a
manifest that describes the dataset, with information about one utterance per line (.json).
Each line of the manifest should be in the following format:
{"audio_filepath": "/path/to/audio.wav", "text": "the transcription of the utterance", "duration": 23.147}
The audio_filepath field should provide an absolute path to the .wav file corresponding to
the utterance. The text field should contain the full transcript for the utterance, and the
duration field should reflect the duration of the utterance in seconds.
Each entry in the manifest (describing one audio file) should be bordered by { and } and
must be contained on one line. The fields that describe the file should be separated by commas
and have the form "field_name": value, as shown above.
Since the manifest specifies the path for each utterance, the audio files do not have to be located in the same directory as the manifest, or even in any specific directory structure.
The spec file for TTS using FastPitch includes the trainer, model,
training_dataset, validation_dataset, and prior_folder.
The following is a shortened example of a spec file for training on the LJSpeech dataset.
sample_rate: 22050
train_dataset: ???
validation_dataset: ???
prior_folder: ???
model:
learn_alignment: true
n_speakers: 1
symbols_embedding_dim: 384
max_token_duration: 75
n_mel_channels: 80
pitch_embedding_kernel_size: 3
n_window_size: 1024
n_window_stride: 256
pitch_fmin: 80
pitch_fmax: 640
pitch_avg: 211.27540199742586
pitch_std: 52.1851002822779
train_ds:
dataset:
_target_: "nemo.collections.asr.data.audio_to_text.AudioToCharWithPriorAndPitchDataset"
manifest_filepath: ${train_dataset}
max_duration: null
min_duration: 0.1
int_values: false
normalize: true
sample_rate: ${sample_rate}
trim: false
sup_data_path: ${prior_folder}
n_window_stride: ${model.n_window_stride}
n_window_size: ${model.n_window_size}
pitch_fmin: ${model.pitch_fmin}
pitch_fmax: ${model.pitch_fmax}
pitch_avg: ${model.pitch_avg}
pitch_std: ${model.pitch_std}
vocab:
notation: phonemes
punct: true
spaces: true
stresses: true
add_blank_at: None
pad_with_space: True
chars: true
improved_version_g2p: true
dataloader_params:
drop_last: false
shuffle: true
batch_size: 32
num_workers: 12
validation_ds:
dataset:
_target_: "nemo.collections.asr.data.audio_to_text.AudioToCharWithPriorAndPitchDataset"
manifest_filepath: ${validation_dataset}
max_duration: null
min_duration: null
int_values: false
normalize: true
sample_rate: ${sample_rate}
trim: false
sup_data_path: ${prior_folder}
n_window_stride: ${model.n_window_stride}
n_window_size: ${model.n_window_size}
pitch_fmin: ${model.pitch_fmin}
pitch_fmax: ${model.pitch_fmax}
pitch_avg: ${model.pitch_avg}
pitch_std: ${model.pitch_std}
vocab:
notation: phonemes
punct: true
spaces: true
stresses: true
add_blank_at: None
pad_with_space: True
chars: true
improved_version_g2p: true
dataloader_params:
drop_last: false
shuffle: false
batch_size: 32
num_workers: 8
preprocessor:
_target_: nemo.collections.asr.modules.AudioToMelSpectrogramPreprocessor
dither: 0.0
features: ${model.n_mel_channels}
frame_splicing: 1
highfreq: 8000
log: true
log_zero_guard_type: add
log_zero_guard_value: 1e-05
lowfreq: 0
mag_power: 1.0
n_fft: ${model.n_window_size}
n_window_size: ${model.n_window_size}
n_window_stride: ${model.n_window_stride}
normalize: null
pad_to: 1
pad_value: 0
preemph: null
sample_rate: ${sample_rate}
window: hann
window_size: null
window_stride: null
input_fft: #n_embed and padding_idx are added by the model
_target_: nemo.collections.tts.modules.transformer.FFTransformerEncoder
n_layer: 6
n_head: 1
d_model: ${model.symbols_embedding_dim}
d_head: 64
d_inner: 1536
kernel_size: 3
dropout: 0.1
dropatt: 0.1
dropemb: 0.0
d_embed: ${model.symbols_embedding_dim}
output_fft:
_target_: nemo.collections.tts.modules.transformer.FFTransformerDecoder
n_layer: 6
n_head: 1
d_model: ${model.symbols_embedding_dim}
d_head: 64
d_inner: 1536
kernel_size: 3
dropout: 0.1
dropatt: 0.1
dropemb: 0.0
alignment_module:
_target_: nemo.collections.tts.modules.aligner.AlignmentEncoder
n_text_channels: ${model.symbols_embedding_dim}
duration_predictor:
_target_: nemo.collections.tts.modules.fastpitch.TemporalPredictor
input_size: ${model.symbols_embedding_dim}
kernel_size: 3
filter_size: 256
dropout: 0.1
n_layers: 2
pitch_predictor:
_target_: nemo.collections.tts.modules.fastpitch.TemporalPredictor
input_size: ${model.symbols_embedding_dim}
kernel_size: 3
filter_size: 256
dropout: 0.1
n_layers: 2
optim:
name: lamb
lr: 1e-1
betas: [0.9, 0.98]
weight_decay: 1e-6
sched:
name: NoamAnnealing
warmup_steps: 1000
last_epoch: -1
d_model: 1 # Disable scaling based on model dim
trainer:
max_epochs: 100
The specification can be roughly grouped into three categories:
Parameters to configure the trainer
Parameters that describe the model
Parameters to configure the experiment
This specification can be used with the tao spectro_gen train command.
If you would like to change a parameter for your run without changing the specification file itself,
you can specify it on the command line directly. For example, if you would like to change the
validation batch size, you can add model.validation_ds.batch_size=1 to your command, which
would override the batch size of 32 in the configuration shown above. An example of this is shown
in the training instructions below.
Configuring the Trainer
The following parameter is used to configure the trainer element of the Spectrogram Generator.
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
int |
Specifies the maximum number of epochs to train the model. A field for the |
>0 |
Configuring the model
The parameters to help configure the FastPitch model are included in the model
element. This includes parameters for configuring the following elements:
dataset_config
preprocessor
input_fft
output_fft
alignment_module
duration_predictor
pitch_predictor
optimizer
There are also some global parameters:
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
bool |
Enable learning alignment |
Valid filepaths |
|
int |
The number of speakers in the dataset |
|
|
int |
The dimension of the symbols embedding |
|
|
int |
The maximum duration to clamp the tokens to |
|
|
int |
The kernel size of the Conv1d layer generating pitch embeddings |
|
|
float |
The fmin input to librosa.pyin. The default value is librosa.note_to_hz(‘C2’) |
|
|
float |
The fmax input to librosa.pyin. The default value is librosa.note_to_hz(‘C7’) |
|
|
float |
The average used to normalize the pitch |
|
|
float |
The std deviation used to normalize the pitch |
|
|
int |
The stride of the window for fft in samples. |
|
|
int |
The size of the window for fft in samples. |
|
|
int |
The number of Mel channels to output |
Dataset Configs
The datasets that you use should be specified by <xyz>_ds parameters, depending on the
use case:
For training using
tao spectro_gen train, you should havetraining_dsto describe your training dataset, andvalidation_dsto describe your validation dataset.
Each <xyz>_ds config contains two main groups of configuration
dataset: The configuration component describing the datasetdataloader: The configuration componenet describing the dataloader
The configurable fields for the dataset field are described in the following table:
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
string |
The filepath to the manifest (.json file) that describes the audio data |
Valid filepaths. |
|
float |
All files with a duration less than the given value (in seconds) will be dropped. The default value is 0.1. |
|
|
float |
All files with a duration greater than the given value (in seconds) will be dropped. |
|
|
int |
The target sample rate to load the audio, in Hz. |
|
|
bool |
Whether to trim silence from beginning and end of audio signal using librosa.effects.trim(). The default value is False. |
True/False |
|
bool |
If true, load samples as 32-bit integers. The default value is False. |
True/False |
|
int |
The stride of window for fft in samples. |
|
|
int |
The size of window for fft in samples. |
|
|
bool |
The flag to determine whether to normalize the transcript text |
True/False |
|
float |
The fmin input to librosa.pyin. The default value is librosa.note_to_hz(‘C2’) |
|
|
float |
The fmax input to librosa.pyin. The default value is librosa.note_to_hz(‘C7’) |
|
|
float |
The average used to normalize the pitch |
|
|
float |
The std deviation used to normalize the pitch |
The pitch_avg and pitch_std parameters provided by default are calculated for the
LJSpeech dataset. These values must be re-calculated per speaker.
Similarly, the pitch_fmin and pitch_fmax need to adjusted based on the dataset.
The default values may result in poor behaviour.
Vocabulary
This subsection under the dataset component of the <xyz>_ds config defines the
configurable fields to generate a vocabulary.
Parameter |
Datatype |
Description |
Supported Values |
|
str |
Either ‘chars` or phonemes as general notation |
phonemes |
|
bool |
Whether to reserve graphemes for basic punctuation |
True/False |
|
bool |
Whether to prepend spaces to every punctuation symbol. |
True/False |
|
bool |
Whether to additionally use chars together with phonemes |
True/False |
|
str |
Add blank to labels in the specified order. If this string is empty, then there will be no blank in the labels. |
last/last_but_one/None |
|
bool |
Whether to pad text with spaces at the beginning and at the end |
True/False |
|
bool |
Whether to use the new version of g2p |
True/False |
Dataloader
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
|
integer |
The number of worker threads for loading |
2 |
|
bool |
Whether to shuffle the data. We recommend True for training data and False for validation. |
True/False |
|
integer |
The training data batch size |
Preprocessor Config
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
float |
Amount of white-noise dithering. |
>= 0 |
|
int |
Number of mel spectrogram freq bins to output. |
derived from |
|
int |
Number of spectrogram frames per model step |
|
|
int |
Upper bound on mel basis in Hz. |
|
|
bool |
Whether to log the spectrogram |
|
|
|
str |
Need to avoid taking the log of zero. There are |
|
|
|
float, str |
Add or clamp requires the number to add with or |
|
|
int |
Lower bound on mel basis in Hz. |
|
|
|
int |
prior to multiplication with mel basis. |
|
|
|
int |
The size of window for fft in samples. Use one of |
Derived from |
|
|
int |
The size of window for fft in samples. Use one of |
Derived from |
|
int |
The stride of the window for fft. |
Derived from |
|
|
str |
other options disable feature normalization. per channel / freq instead. |
|
|
|
int |
a multiple of pad_to. |
|
|
float |
The value that shorter mels are padded with. |
|
|
|
float |
Amount of pre emphasis to add to audio. Can be |
|
|
int |
The target sample rate to load the audio, in Hz. |
Derived from |
|
|
string |
‘hamming’, ‘blackman’, ‘bartlett’] |
|
|
int |
Size of window for fft in seconds |
|
|
int |
Stride of window for fft in seconds |
INPUT / OUTPUT FFT
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
int |
Number of Transformer layers |
|
|
int |
Number of heads in the MultiHeadAttn module |
|
|
int |
Hidden size of input and output |
Derived from |
|
int |
Hidden size of attention module |
|
|
int |
Hidden size of conv layer |
|
|
int |
Kernel size of conv layer |
|
|
float |
Dropout parameter |
|
|
float |
Dropout parameter for attention |
|
|
int |
Hidden size of embeddings (input fft only) |
Derived from |
Alignment Module
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
int |
Should match d_model |
Duration Predictor / Pitch Predictor
A simple stack of conv, relu, layernorm, dropout layers.
Parameter |
Datatype |
Description |
Supported Values |
|---|---|---|---|
|
int |
Should match d_model |
Derived from |
|
int |
Kernel size for conv layers |
|
|
int |
Filter size for conv layers |
|
|
float |
Dropout parameter |
|
|
int |
Number of layers |
To train a model from scratch, use the following command:
tao spectro_gen train \
-e <experiment_spec> \
-g <num_gpus> \
-r /path/to/the/results/directory \
-k <encryption_key>
As mentioned above, you can add additional arguments to override configurations from your experiment specification file. This allows you to create valid spec files that leave these fields blank, to be specified as command line arguments at runtime.
For example, the following command can be used to override the training manifest and validation manifest, the number of epochs to train, and the place to save the model checkpoint:
tao spectro_gen train \
-e $SPECS_DIR/spectro_gen/train.yaml \
-g 1 \
-k $KEY \
-r $RESULTS_DIR/spectro_gen/train \
train_dataset=$DATA_DIR/ljspeech/ljspeech_train.json \
validation_dataset=$DATA_DIR/ljspeech/ljspeech_val.json \
prior_folder=$RESULTS_DIR/spectro_gen/train/prior_folder \
trainer.max_epochs=5
Required Arguments
-e: The experiment specification file to set up training, as in the example given above-r: The path to the results and log directory. Log files, checkpoints, etc., will be stored here-k: The key to encrypt the modelOther arguments to override fields in the specification file.
Optional Arguments
-g: The number of GPUs to be used in the training in a multi-GPU scenario. The default value is 1.
Training Procedure
At the start of each training experiment, TAO Toolkit will print out a log of the experiment specification, including any parameters added or overridden via the command line. It will also show additional information, such as which GPUs are available, where logs will be saved, how many hours are in each loaded dataset, and how much of each dataset has been filtered.
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
IPU available: False, using: 0 IPUs
[NeMo W 2021-10-29 21:29:06 exp_manager:414] Exp_manager is logging to /results/spectro_gen/train, but it already exists.
[NeMo W 2021-10-29 21:29:06 exp_manager:332] There was no checkpoint folder at checkpoint_dir :/results/spectro_gen/train/checkpoints. Training from scratch.
[NeMo I 2021-10-29 21:29:06 exp_manager:220] Experiments will be logged at /results/spectro_gen/train
[NeMo I 2021-10-29 21:29:06 exp_manager:569] TensorboardLogger has been set up
[NeMo W 2021-10-29 21:29:06 nemo_logging:349] /opt/conda/lib/python3.8/site-packages/pytorch_lightning/callbacks/model_checkpoint.py:240: LightningDeprecationWarning: `ModelCheckpoint(every_n_val_epochs)` is deprecated in v1.4 and will be removed in v1.6. Please use `every_n_epochs` instead.
rank_zero_deprecation(
[NeMo I 2021-10-29 21:29:12 collections:173] Dataset loaded with 12500 files totalling 22.84 hours
[NeMo I 2021-10-29 21:29:12 collections:174] 0 files were filtered totalling 0.00 hours
[NeMo I 2021-10-29 21:29:40 collections:173] Dataset loaded with 100 files totalling 0.18 hours
[NeMo I 2021-10-29 21:29:40 collections:174] 0 files were filtered totalling 0.00 hours
[NeMo I 2021-10-29 21:29:42 features:252] PADDING: 1
[NeMo I 2021-10-29 21:29:42 features:269] STFT using torch
initializing ddp: GLOBAL_RANK: 0, MEMBER: 1/1
Added key: store_based_barrier_key:1 to store for rank: 0
Rank 0: Completed store-based barrier for 1 nodes.
----------------------------------------------------------------------------------------------------
distributed_backend=nccl
All DDP processes registered. Starting ddp with 1 processes
-------------------------------------------------------------------------------------------------
You should next see a full printout of the number of parameters in each module and submodule, as well as the total number of trainable and non-trainable parameters in the model.
In the following table, the fastpitch module contains 45.8 million parameters and its
submodule fastpitch.encoder container 21.9 million parameters. The ReLU,
PositionalEmbedding, and Dropout modules are listed with no parameters.
| Name | Type | Params
-------------------------------------------------------------------------------------------------------
0 | mel_loss | MelLoss | 0
1 | pitch_loss | PitchLoss | 0
2 | duration_loss | DurationLoss | 0
3 | aligner | AlignmentEncoder | 1.0 M
4 | aligner.softmax | Softmax | 0
5 | aligner.log_softmax | LogSoftmax | 0
6 | aligner.key_proj | Sequential | 947 K
7 | aligner.key_proj.0 | ConvNorm | 885 K
8 | aligner.key_proj.0.conv | Conv1d | 885 K
9 | aligner.key_proj.1 | ReLU | 0
10 | aligner.key_proj.2 | ConvNorm | 61.5 K
11 | aligner.key_proj.2.conv | Conv1d | 61.5 K
12 | aligner.query_proj | Sequential | 57.9 K
13 | aligner.query_proj.0 | ConvNorm | 38.6 K
14 | aligner.query_proj.0.conv | Conv1d | 38.6 K
15 | aligner.query_proj.1 | ReLU | 0
16 | aligner.query_proj.2 | ConvNorm | 12.9 K
17 | aligner.query_proj.2.conv | Conv1d | 12.9 K
18 | aligner.query_proj.3 | ReLU | 0
19 | aligner.query_proj.4 | ConvNorm | 6.5 K
20 | aligner.query_proj.4.conv | Conv1d | 6.5 K
21 | forward_sum_loss | ForwardSumLoss | 0
22 | forward_sum_loss.log_softmax | LogSoftmax | 0
23 | forward_sum_loss.ctc_loss | CTCLoss | 0
24 | bin_loss | BinLoss | 0
25 | preprocessor | AudioToMelSpectrogramPreprocessor | 0
26 | preprocessor.featurizer | FilterbankFeatures | 0
27 | fastpitch | FastPitchModule | 45.8 M
28 | fastpitch.encoder | FFTransformerEncoder | 21.9 M
29 | fastpitch.encoder.pos_emb | PositionalEmbedding | 0
30 | fastpitch.encoder.drop | Dropout | 0
31 | fastpitch.encoder.layers | ModuleList | 21.8 M
32 | fastpitch.encoder.layers.0 | TransformerLayer | 3.6 M
33 | fastpitch.encoder.layers.0.dec_attn | MultiHeadAttn | 99.3 K
34 | fastpitch.encoder.layers.0.dec_attn.qkv_net | Linear | 73.9 K
35 | fastpitch.encoder.layers.0.dec_attn.drop | Dropout | 0
36 | fastpitch.encoder.layers.0.dec_attn.dropatt | Dropout | 0
37 | fastpitch.encoder.layers.0.dec_attn.o_net | Linear | 24.6 K
..
..
213 | fastpitch.duration_predictor.layers.1.norm | LayerNorm | 512
214 | fastpitch.duration_predictor.layers.1.dropout | Dropout | 0
215 | fastpitch.duration_predictor.fc | Linear | 257
216 | fastpitch.pitch_predictor | TemporalPredictor | 493 K
217 | fastpitch.pitch_predictor.layers | Sequential | 493 K
218 | fastpitch.pitch_predictor.layers.0 | ConvReLUNorm | 295 K
219 | fastpitch.pitch_predictor.layers.0.conv | Conv1d | 295 K
220 | fastpitch.pitch_predictor.layers.0.norm | LayerNorm | 512
221 | fastpitch.pitch_predictor.layers.0.dropout | Dropout | 0
222 | fastpitch.pitch_predictor.layers.1 | ConvReLUNorm | 197 K
223 | fastpitch.pitch_predictor.layers.1.conv | Conv1d | 196 K
224 | fastpitch.pitch_predictor.layers.1.norm | LayerNorm | 512
225 | fastpitch.pitch_predictor.layers.1.dropout | Dropout | 0
226 | fastpitch.pitch_predictor.fc | Linear | 257
227 | fastpitch.pitch_emb | Conv1d | 1.5 K
228 | fastpitch.proj | Linear | 30.8 K
-------------------------------------------------------------------------------------------------------
45.8 M Trainable params
0 Non-trainable params
45.8 M Total params
183.035 Total estimated model params size (MB)
As the model starts training, you should see a progress bar per epoch.
Epoch 0: 0%| | 0/395 [00:00<00:00, 5504.34it/s][W reducer.cpp:1151] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())
Epoch 0: 6%|▊ | 23/395 [05:06<1:19:07, 12.76s/it, loss=38, v_num=]
...
At the end of training, TAO Toolkit will save the last checkpoint at the path specified by the experiment spec file before finishing.
[NeMo I 2021-01-20 22:38:48 train:120] Experiment logs saved to '$RESULTS_DIR/spectro_gen/train'
[NeMo I 2021-01-20 22:38:48 train:123] Trained model saved to '$RESULTS_DIR/spectro_gen/train/checkpoints/trained-model.tlt'
INFO: Internal process exited
Current Limitations
Currently, only
.wavaudio files are supported.Training only supports single speaker dataset.
The spectrogram generator can only be trained from scratch.
To perform inference on individual text lines, use the following command:
tao spectro_gen infer -e <experiment_spec> \
-m <model_checkpoint> \
-g <num_gpus> \
-k $KEY \
-r </path/to/results/directory/for/logs> \
output_path=</path/to/result/directory/for/spectrogram>
Required Arguments
-e: The experiment specification file to set up inference. This spec file only needs afile_pathsparameter that contains a list of individual file paths.-m: The path to the model checkpoint, which should be a.tltfile.-k: The key to encrypt the model
Optional Arguments
-g: The number of GPUs to use for inference in a multi-GPU scenario. The default value is 1.-r: The path to the results and log directory. Log files, checkpoints, etc. will be stored here.Other arguments to override fields in the specification file.
Inference Procedure
At the start of inference, TAO Toolkit will print out the experiment specification, including the audio filepaths on which inference will be performed.
When restoring from the checkpoint, it will then log the original datasets that the checkpoint model was trained and evaluated on. This will show the vocabulary that the model was trained on.
[NeMo W 2021-10-29 23:08:27 exp_manager:26] Exp_manager is logging to `/results/spectro_gen/infer``, but it already exists.
[NeMo W 2021-10-29 23:08:33 modelPT:130] If you intend to do training or fine-tuning, please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.
Train config :
dataset:
_target_: nemo.collections.asr.data.audio_to_text.AudioToCharWithPriorAndPitchDataset
manifest_filepath: /data/ljspeech/ljspeech_train.json
...
...
dataloader_params:
drop_last: false
shuffle: true
batch_size: 32
num_workers: 12
[NeMo W 2021-10-29 23:08:33 modelPT:137] If you intend to do validation, please call the ModelPT.setup_validation_data() or ModelPT.setup_multiple_validation_data() method and provide a valid configuration file to setup the validation data loader(s).
Validation config :
dataset:
_target_: nemo.collections.asr.data.audio_to_text.AudioToCharWithPriorAndPitchDataset
...
...
dataloader_params:
drop_last: false
shuffle: false
batch_size: 32
num_workers: 8
[NeMo I 2021-10-29 23:08:43 features:252] PADDING: 1
[NeMo I 2021-10-29 23:08:43 features:269] STFT using torch
Results for by the... saved to /results/spectro_gen/infer/spectro/0.npy
Results for direct... saved to /results/spectro_gen/infer/spectro/1.npy
Results for uneasy... saved to /results/spectro_gen/infer/spectro/2.npy
[NeMo I 2021-10-29 23:08:51 infer:79] Experiment logs saved to '/results/spectro_gen/infer'
The path to the Mel spectrograms generated by the infer task are shown in the last lines of the log.
Current Limitations
Currently, only
.wav audiofiles are supported.
To fine-tune a model from a checkpoint, use the following command:
!tao spectro_gen finetune -e <experiment_spec> \
-m <model_checkpoint> \
-g <num_gpus> \
train_dataset=<train.json> \
validation_dataset=<val.json> \
prior_folder=<prior_dir, could be an empty dir> \
n_speakers=2 \
pitch_fmin=<pitch statistic, see pitch section> \
pitch_fmax=<pitch statistic, see pitch section> \
pitch_avg=<pitch statistic, see pitch section> \
pitch_std=<pitch statistic, see pitch section> \
trainer.max_steps=<num_steps>
Required Arguments
-e: The experiment specification file to set up fine-tuning.-m: The path to the model checkpoint from which to fine-tune. The model checkpoint should be a.tltfile.train_dataset: The path to the training manifest, which should be created usingdataset_convert dataset_name=merge. See the section below for more details.validation_dataset: The path to the validation manifest.prior_folder: A folder used to store dataset files. If the folder is empty, these files will be computed on the first run and saved to this directory. Future runs will load these files from the directory if they exist.n_speakers: This value should be 2: One for the original speaker, one for the new finetuning speaker.pitch_fmin: The Fmin to be used for pitch extraction. See the section below on how to set this value.pitch_fmax: The Fmax to be used for pitch extraction. See the section below on how to set this value.pitch_avg: The pitch average to be used for pitch extraction. See the section below on how to set this value.pitch_std: The pitch standard deviation to be used for pitch extraction. See the section below on how to set this value.trainer.max_steps: The number of steps used to finetune the model. We recommend adding 1000 for each minute in the finetuning data.
Optional Arguments
-g: The number of GPUs to be used for fine-tuning in a multi-GPU scenario (default: 1).-r: The path to the results and log directory. Log files, checkpoints, etc., will be stored here.Other arguments to override fields in the specification file.
In order to prevent unauthorized use of someone’s voice, TAO will only run finetuning if the text transcripts used in the finetuning data comes from the NVIDIA Custom Voice Recorder tool. Users do not have to use the tool to record their own voice, but the transcripts used must be the same.
The data from the NVIDIA Custom Voice Recorder tool cannot be used to train a FastPitch model from scratch.
Instead, use the data with the finetune endpoint of TAO Text-To-Speech with a pretrained FastPitch model.
Pitch Statistics
To fine tune FastPitch, you need to find and set 4 pitch hyperparameters:
Fmin
Fmax
Mean
Std
TAO features the pitch_stats task to help with this process. You must set Fmin and Fmax
first. You can then iterate over the finetuning dataset to extract the pitch mean and standard
deviation.
Obtaining the fmin and fmax
To get the fmin and fmax values, you will need to start with some defaults and
iterate through random samples of the dataset to ensure that the pyin function from
librosa extracts the pitch correctly. Then, look at the plotted spectrograms, as well as the
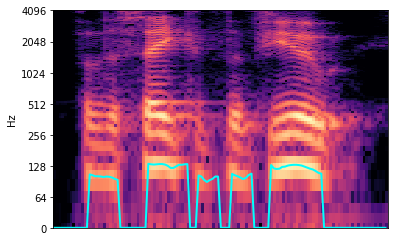
predicted f0 (the cyan line), which should match the lowest energy band in the spectrogram.
Here is an example of a good match between the predicted f0 and the spectrogram.
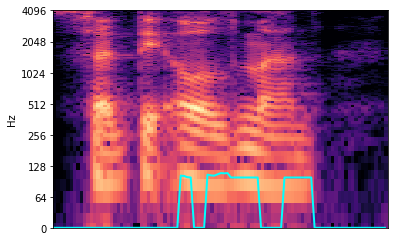
The following is an example of a bad match between the f0 and the spectrogram. The fmin
was likely set too high. The fo algorithm is missing the first two vocalizations and is
correctly matching the last half of speech. To fix this, set the fmin value lower.
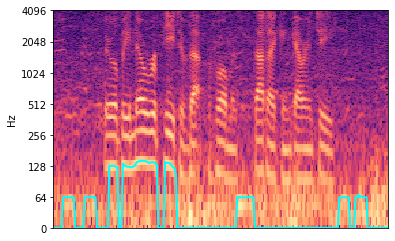
The following is an example of samples that have low frequency noise. To eliminate the effects of
noise, set the fmin value above the noise frequency. Unfortunately, this will result in
degraded TTS quality. It would be best to re-record the data in an environment with less noise.
To generate these plots, runn the pitch_stats entrypoint with the following options:
tao spectro_gen pitch_stats num_files=10 \
pitch_fmin=64 \
pitch_fmax=512 \
output_path=/results/spectro_gen/pitch_stats \
compute_stats=false \
render_plots=true \
manifest_filepath=$DATA_DIR/6097_5_mins/6097_manifest_train.json \
--results_dir $RESULTS_DIR/spectro_gen/pitch_stats
Required Arguments:
pitch_fmin: The minimum frequency value set by the user as input to extract the pitchpitch_fmax: The maximum frequence value set by the user as input to extract the pitchoutput_path: The path to the directory where the pitch plots are generatedcompute_stats: A boolean flag that specifies whether to compute thepitch_meanandpitch_stdrender_plots: A boolean flag that specifies whether to generate the pitch plots at theoutput_pathmanifest_filepath: The path to the datasetnum_files: Number of files in the input dataset to visualize thef0plot.results_dir: The path to the directory where the logs are generated
We recommend setting the compute_stats option to false so you don’t spend time
iterating over the entire dataset to compute pitch_mean and pitch_std until you
are satisfied with the fmin and fmax values.
Computing the pitch_mean and pitch_std
After you set the pitch_fmin and pitch_fmax, you need to extract the pitch over
all training files. After filtering out all 0.0 and nan values from the pitch, you will
compute the mean and standard deviation. You can then use these values to fine tune FastPitch. To
generate the mean and standard deviation, run the pitch_stats task with the following
options:
tao spectro_gen pitch_stats num_files=10 \
pitch_fmin=64 \
pitch_fmax=512 \
output_path=/results/spectro_gen/pitch_stats \
compute_stats=true \
render_plots=false \
manifest_filepath=$DATA_DIR/6097_5_mins/6097_manifest_train.json \
--results_dir $RESULTS_DIR/spectro_gen/pitch_stats
In the above example, the compute_stats option is set to true while the
render_plots option is set to false so that the spectrograms aren’t rendered and
predicted f0 again, but we do compute the mean and standard deviation values.
Manifest Creation
For best results, you should fine tune FastPitch by adding the original data as well as data
from the new speaker. To create a training manifest file that combines the data, you can
use spectro_gen dataset_convert dataset_name=merge with the following parameters:
!tao spectro_gen dataset_convert dataset_name=merge \
original_json=<original_data.json> \
finetune_json=<finetuning_data.json> \
save_path=<path_to_save_new_json> \
-r <results_dir> \
-e <experiment_spec>
The important arguments are as follows:
original_json: The.jsonfile that contains the original datafinetune_json: The.jsonfile that contains the finetuning data
A merged .json file will be saved at save_path.
The above code assumes that the original and fine-tuned dataset have gone through
dataset_convert to generate the manifest.json files, as mentioned in the
preparing the dataset section.
When merging manifest files, ensure that the audio clips from the original data and the new speaker data share the same sampling rate. If the sampling rates don’t match, you can either resample the data using the command line (method 1) or as part of the code (method 2):
Use the the sox package CLI tool.
sox input.wav output.wav rate $RATE
Where,
$RATEis the target sample frequency in Hz.Use the librosa load function.
import librosa audio, sampling_rate = librosa.load( "/path/to/audio.wav", sr=<target_sampling_rate> ) librosa.output.write_wav( "/path/to/target/audio.wav", audio, sr=sampling_rate )
You can export a trained FastPitch model to Riva format, which contains all the model artifacts necessary for deployment to Riva Services. For more details about Riva, see this page.
To export a FastPitch model to the Riva format, use the following command:
tao spectro_gen export -e <experiment_spec> \
-m <model_checkpoint> \
-r <results_dir> \
-k <encryption_key> \
export_format=RIVA \
export_to=<filename.riva>
Required Arguments
-e: The experiment specification file for export. See the Export Spec File section below for more details.-m: The path to the model checkpoint to be exported, which should be a.tltfile-k: The encryption key
Optional Arguments
-r: The path to the directory where results will be stored.
Export Spec File
The following is an example spec file for model export:
# Name of the .tlt EFF archive to be loaded/model to be exported.
restore_from: trained-model.tlt
# Set export format: RIVA
export_format: RIVA
# Output EFF archive containing model checkpoint and artifacts required for Riva Services
export_to: exported-model.riva
Parameter |
Datatype |
Description |
Default |
|---|---|---|---|
|
string |
The path to the pre-trained model to be exported |
|
|
string |
The export format |
N/A |
|
string |
The target path for the export model |
|
A successful run of the model export generates the following log:
[NeMo W 2021-10-29 23:14:22 exp_manager:26] Exp_manager is logging to `/results/spectro_gen/export``, but it already exists.
[NeMo W 2021-10-29 23:14:28 modelPT:130] If you intend to do training or fine-tuning, please call the ModelPT.setup_training_data() method and provide a valid configuration file to setup the train data loader.
Train config :
dataset:
_target_: nemo.collections.asr.data.audio_to_text.AudioToCharWithPriorAndPitchDataset
manifest_filepath: /data/ljspeech/ljspeech_train.json
max_duration: null
min_duration: 0.1
int_values: false
normalize: true
sample_rate: 22050
...
...
...
[NeMo I 2021-10-29 23:14:35 export:57] Model restored from '/results/spectro_gen/train/checkpoints/trained-model.tlt'
[NeMo W 2021-10-29 23:14:38 export_utils:198] Swapped 0 modules
Warning: Constant folding - Only steps=1 can be constant folded for opset >= 10 onnx::Slice op. Constant folding not applied.
Warning: Constant folding - Only steps=1 can be constant folded for opset >= 10 onnx::Slice op. Constant folding not applied.
Warning: Constant folding - Only steps=1 can be constant folded for opset >= 10 onnx::Slice op. Constant folding not applied.
[NeMo I 2021-10-29 23:14:58 export:72] Experiment logs saved to '/results/spectro_gen/export'
[NeMo I 2021-10-29 23:14:58 export:73] Exported model to '/results/spectro_gen/export/spectro_gen.riva'
[NeMo I 2021-10-29 23:15:03 export:80] Exported model is compliant with Riva