RT-Embed Performance#
Overview#
The Real-Time Embedding (RT-Embedding) microservice provides video and text embedding generation capabilities using the Cosmos-Embed1 model, enabling video search and similarity matching. Benchmarks cover two operating modes:
Streaming mode — the microservice reads live RTSP streams continuously. Every 10 seconds of video, it samples 8 frames and produces one video embedding vector. Latency is measured from when a 10-second chunk is ready until the embedding is returned.
Non-streaming mode — the microservice handles discrete embedding requests for video clips or text queries. Benchmarks measure throughput (requests per second) and latency across varying concurrency levels.
Each video embedding encodes 8 frames sampled from a 10-second chunk scaled to 448×448 resolution into a 768-dimensional vector. Text embeddings encode up to 128 tokens into the same 768-dimensional space, enabling cross-modal search.
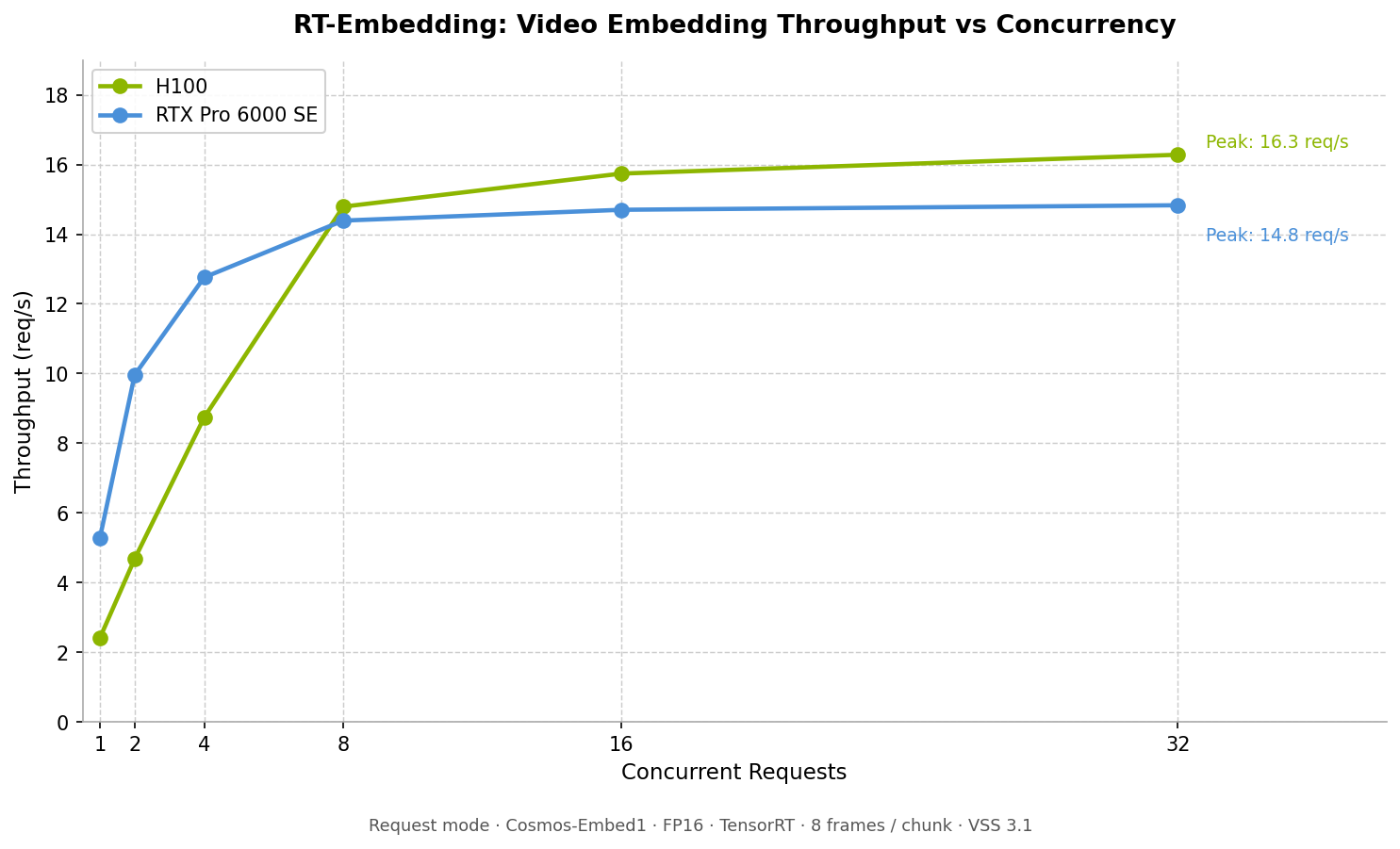
Video embedding throughput (req/s) vs. concurrent requests. The H100 reaches up to 16 req/s while the RTX Pro 6000 SE peaks near 15 req/s; the RTX Pro 6000 SE reaches peak throughput at lower concurrency and saturates earlier, while the H100 sustains throughput through higher concurrency levels.#
Test Configuration#
Parameter |
Value |
|---|---|
VSS Release |
3.2 |
Model |
Cosmos-Embed1-448p |
Model precision |
FP16 |
Inference engine |
TensorRT (TRT) |
Frames per chunk (video) |
8 |
Image resolution |
448×448 |
Embedding vector length |
768 |
Chunk duration |
10 seconds |
Text ISL (text embedding) |
20 tokens |
GPUs tested |
H100, RTX Pro 6000 SE |
Performance by GPU#
Streaming Mode
Max Concurrent Streams
Max Streams |
Avg Latency (s) |
p90 (s) |
p95 (s) |
Max (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|---|
170 |
3.00 |
6.76 |
8.62 |
12.89 |
66.3 |
93.9 |
Stream Latency Profile
Concurrent Streams |
Avg (s) |
p90 (s) |
p95 (s) |
Min (s) |
Max (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|---|---|
1 |
0.13 |
0.13 |
0.19 |
0.08 |
0.32 |
0.0 |
0.6 |
16 |
0.20 |
0.20 |
0.25 |
0.08 |
0.29 |
4.0 |
6.4 |
32 |
0.24 |
0.24 |
0.31 |
0.08 |
0.34 |
8.0 |
11.7 |
Request Mode
Video Embedding Throughput
Concurrent Requests |
Avg Latency (s) |
Throughput (req/s) |
|---|---|---|
1 |
0.41 |
2.41 |
2 |
0.42 |
4.68 |
4 |
0.44 |
8.74 |
8 |
0.50 |
14.79 |
16 |
0.94 |
15.74 |
32 |
1.81 |
16.28 |
Text Embedding Throughput (ISL = 20 tokens)
Concurrent Requests |
Avg Latency (s) |
Throughput (req/s) |
p90 (s) |
p95 (s) |
|---|---|---|---|---|
1 |
0.007 |
132.1 |
0.007 |
0.008 |
2 |
0.008 |
216.7 |
0.009 |
0.011 |
4 |
0.010 |
368.0 |
0.010 |
0.012 |
8 |
0.013 |
563.6 |
0.015 |
0.016 |
16 |
0.018 |
800.5 |
0.023 |
0.023 |
32 |
0.027 |
1044.3 |
0.031 |
0.031 |
Video File Embedding Latency (Concurrency = 1)
Video Duration |
E2E Latency (s) |
Avg Chunk Inference (s) |
Decode Latency (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|
10 s |
0.412 |
0.039 |
0.369 |
0.0 |
0.0 |
10 min |
5.203 |
0.039 |
0.615 |
48.9 |
72.6 |
60 min |
28.8 |
0.039 |
0.601 |
54.3 |
87.6 |
Streaming Mode
Max Concurrent Streams
Max Streams |
Avg Latency (s) |
p90 (s) |
p95 (s) |
Max (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|---|
149 |
2.70 |
4.92 |
6.06 |
8.92 |
93.1 |
40.2 |
Stream Latency Profile
Concurrent Streams |
Avg (s) |
p90 (s) |
p95 (s) |
Min (s) |
Max (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|---|---|
1 |
0.12 |
0.13 |
0.13 |
0.11 |
0.13 |
0.0 |
0.0 |
16 |
0.30 |
0.40 |
0.40 |
0.11 |
0.41 |
8.4 |
3.5 |
32 |
0.37 |
0.50 |
0.50 |
0.11 |
0.51 |
13.1 |
6.3 |
Request Mode
Video Embedding Throughput
Concurrent Requests |
Avg Latency (s) |
Throughput (req/s) |
|---|---|---|
1 |
0.19 |
5.28 |
2 |
0.19 |
9.96 |
4 |
0.30 |
12.76 |
8 |
0.52 |
14.39 |
16 |
1.02 |
14.70 |
32 |
2.01 |
14.83 |
Text Embedding Throughput (ISL = 20 tokens)
Concurrent Requests |
Avg Latency (s) |
Throughput (req/s) |
p90 (s) |
p95 (s) |
|---|---|---|---|---|
1 |
0.007 |
132.9 |
0.009 |
0.009 |
2 |
0.007 |
254.8 |
0.009 |
0.009 |
4 |
0.009 |
404.2 |
0.010 |
0.011 |
8 |
0.013 |
586.6 |
0.015 |
0.015 |
16 |
0.017 |
836.9 |
0.019 |
0.020 |
32 |
0.026 |
1101.1 |
0.028 |
0.028 |
Video File Embedding Latency (Concurrency = 1)
Video Duration |
E2E Latency (s) |
Avg Chunk Inference (s) |
Decode Latency (s) |
GPU Core (%) |
NVdec (%) |
|---|---|---|---|---|---|
10 s |
0.195 |
0.068 |
0.124 |
0.0 |
0.0 |
10 min |
4.166 |
0.065 |
0.290 |
77.0 |
52.8 |
60 min |
24.5 |
0.166 |
0.304 |
93.8 |
55.7 |
Note
All benchmarks use Cosmos-Embed1-448p, FP16, TensorRT, 8 frames per 10-second chunk of 1080p input resolution, scaled to 448×448 model resolution, and a 768-dimensional embedding vector. For streaming deployments, plan for 10–15% headroom below the maximum concurrent stream counts.