Creating a Distributed Application
Distributed applications refer to those where the workflow is divided into multiple fragments that may be run on separate nodes. For example, data might be collected via a sensor at the edge, sent to a separate workstation for processing, and then the processed data could be sent back to the edge node for visualization. Each node would run a single fragment consisting of a computation graph built up of operators. Thus one fragment is the equivalent of a non-distributed application. In the distributed context, the Application initializes the different fragments and then defines the connections between them to build up the full distributed application workflow.
In this section we’ll describe:
Defining distributed applications is also illustrated in the video_replayer_distributed and ping_distributed examples.
Defining a single Fragment (C++/Python) involves adding operators using make_operator() (C++) or the operator constructor (Python), and defining the connections between them using the add_flow() method (C++/Python) in the compose() method. Thus, defining a Fragment is just like defining a non-distributed Application except that the class should inherit from Fragment instead of Application.
The application will then be defined by initializing fragments within the application’s compose() method. The add_flow() method (C++/Python) can be used to define the connections across fragments.
We define the
Fragment1andFragment2classes that inherit from theFragmentbase class.We define the
Appclass that inherits from theApplicationbase class.The
Appclass initializes any fragments used and defines the connections between them. Here we have used dummy port and operator names in the exampleadd_flowcall connecting the fragments since no specific operators are shown in this example.We create an instance of the
Appclass inmain()using themake_application()function.The
run()method starts the application which will execute itscompose()method where the custom workflow will be defined.
#include <holoscan/holoscan.hpp>
class Fragment1 : public holoscan::Fragment {
public:
void compose() override {
// Define Operators and workflow for Fragment1
// ...
}
};
class Fragment2 : public holoscan::Fragment {
public:
void compose() override {
// Define Operators and workflow for Fragment2
// ...
}
};
class App : public holoscan::Application {
public:
void compose() override {
using namespace holoscan;
auto fragment1 = make_fragment<Fragment1>("fragment1");
auto fragment2 = make_fragment<Fragment2>("fragment2");
// Define the workflow: replayer -> holoviz
add_flow(fragment1, fragment2, {{"fragment1_operator_name.output_port_name",
"fragment2_operator_name.input_port_name"}});
}
};
int main() {
auto app = holoscan::make_application<App>();
app->run();
return 0;
}
We define the
Fragment1andFragment2classes that inherit from theFragmentbase class.We define the
Appclass that inherits from theApplicationbase class.The
Appclass initializes any fragments used and defines the connections between them. Here we have used dummy port and operator names in the example add_flow call connecting the fragments since no specific operators are shown in this example.We create an instance of the
Appclass in__main__.The
run()method starts the application which will execute itscompose()method where the custom workflow will be defined.
from holoscan.core import Application, Fragment
class Fragment1(Fragment):
def compose(self):
# Define Operators and workflow
# ...
class Fragment2(Fragment):
def compose(self):
# Define Operators and workflow
# ...
class App(Application):
def compose(self):
fragment1 = Fragment1(self, name="fragment1")
fragment2 = Fragment2(self, name="fragment2")
self.add_flow(fragment1, fragment2, {("fragment1_operator_name.output_port_name",
"fragment2_operator_name.input_port_name")})
if __name__ == "__main__":
app = App()
app.run()
Serialization of Custom Data Types for Distributed Applications
Transmission of data between fragments of a multi-fragment application is done via the Unified Communications X (UCX) library. In order to transmit data, it must be serialized into a binary form suitable for transmission over a network. For Tensors ({ref}C++/Python), strings and various scalar and vector numeric types, serialization is already built in. For more details on concrete examples of how to extend the data serialization support to additional user-defined classes, see the separate page on serialization.
Building a distributed application works in the same way as for a non-distributed one. See Building and running your Application
Python applications do not require building. See Building and running your Application.
Running an application in a distributed setting requires launching the application binary on all nodes involved in the distributed application. A single node must be selected to act as the application driver. This is achieved by using the --driver command-line option. Worker nodes are initiated by launching the application with the --worker command-line option. It’s possible for the driver node to also serve as a worker if both options are specified.
The address of the driver node must be specified for each process (both the driver and worker(s)) to identify the appropriate network interface for communication. This can be done via the --address command-line option, which takes a value in the form of [<IPv4 address or hostname>][:<port>] (e.g., --address 192.168.50.68:10000):
The driver’s IP (or hostname) MUST be set for each process (driver and worker(s)) when running distributed applications on multiple nodes (default:
0.0.0.0). It can be set without the port (e.g.,--address 192.168.50.68).In a single-node application, the driver’s IP (or hostname) can be omitted, allowing any network interface (
0.0.0.0) to be selected by the UCX library.The port is always optional (default:
8765). It can be set without the IP (e.g.,--address :10000).
The worker node’s address can be defined using the --worker-address command-line option ([<IPv4 address or hostname>][:<port>]). If it’s not specified, the application worker will default to the host address (0.0.0.0) and select an available port randomly from the range 10000 to 32767.
The --fragments command-line option is used in combination with --worker to specify a comma-separated list of fragment names to be run by a worker. If not specified, the application driver will assign a single fragment to the worker. To indicate that a worker should run all fragments, you can specify --fragments all.
The --config command-line option can be used to designate a path to a configuration file to be used by the application.
Below is an example launching a three fragment application named my_app on two separate nodes:
The application driver is launched at
192.168.50.68:10000on the first node (A), with a worker running two fragments, “fragment1” and “fragment3”.On a separate node (B), the application launches a worker for “fragment2”, which will connect to the driver at the address above.
# Node A
my_app --driver --worker --address 192.168.50.68:10000 --fragments fragment1,fragment3
# Node B
my_app --worker --address 192.168.50.68:10000 --fragments fragment2
# Node A
python3 my_app.py --driver --worker --address 192.168.50.68:10000 --fragments fragment1,fragment3
# Node B
python3 my_app.py --worker --address 192.168.50.68:10000 --fragments fragment2
UCX Network Interface Selection
UCX is used in the Holoscan SDK for communication across fragments in distributed applications. It is designed to select the best network device based on performance characteristics (bandwidth, latency, NUMA locality, etc). In some scenarios (under investigation) UCX cannot find the correct network interface to use, and the application fails to run. In this case, you can manually specify the network interface to use by setting the UCX_NET_DEVICES environment variable.
For example, if the user wants to use the network interface eth0, you can set the environment variable as follows, before running the application:
export UCX_NET_DEVICES=eth0
Or, if you are running a packaged distributed application with the Holoscan CLI, use the --nic eth0 option to manually specify the network interface to use.
The available network interface names can be found by running the following command:
ucx_info -d | grep Device: | awk '{print $3}' | sort | uniq
# or
ip -o -4 addr show | awk '{print $2, $4}' # to show interface name and IP
Known limitations
The following are known limitations of the distributed application support in the SDK, which will be addressed in future updates:
1. The driver calls the compose() method of the fragments.
Although the driver doesn’t execute fragments, it still invokes the compose() method of the fragments to determine the number of connections between them.
2. A connection error message is displayed even when the distributed application is running correctly.
The message Connection dropped with status -25 (Connection reset by remote peer) appears in the console even when the application is functioning properly. This is a known issue and will be addressed in future updates, ensuring that this message will only be displayed in the event of an actual connection error.
3. An operator in one fragment cannot have output port(s) connected to the multiple input ports of the operator(s) in another fragment.
The distributed application will not function if there are multiple input/output port connections between two operators in different fragments, as illustrated in the figure below.
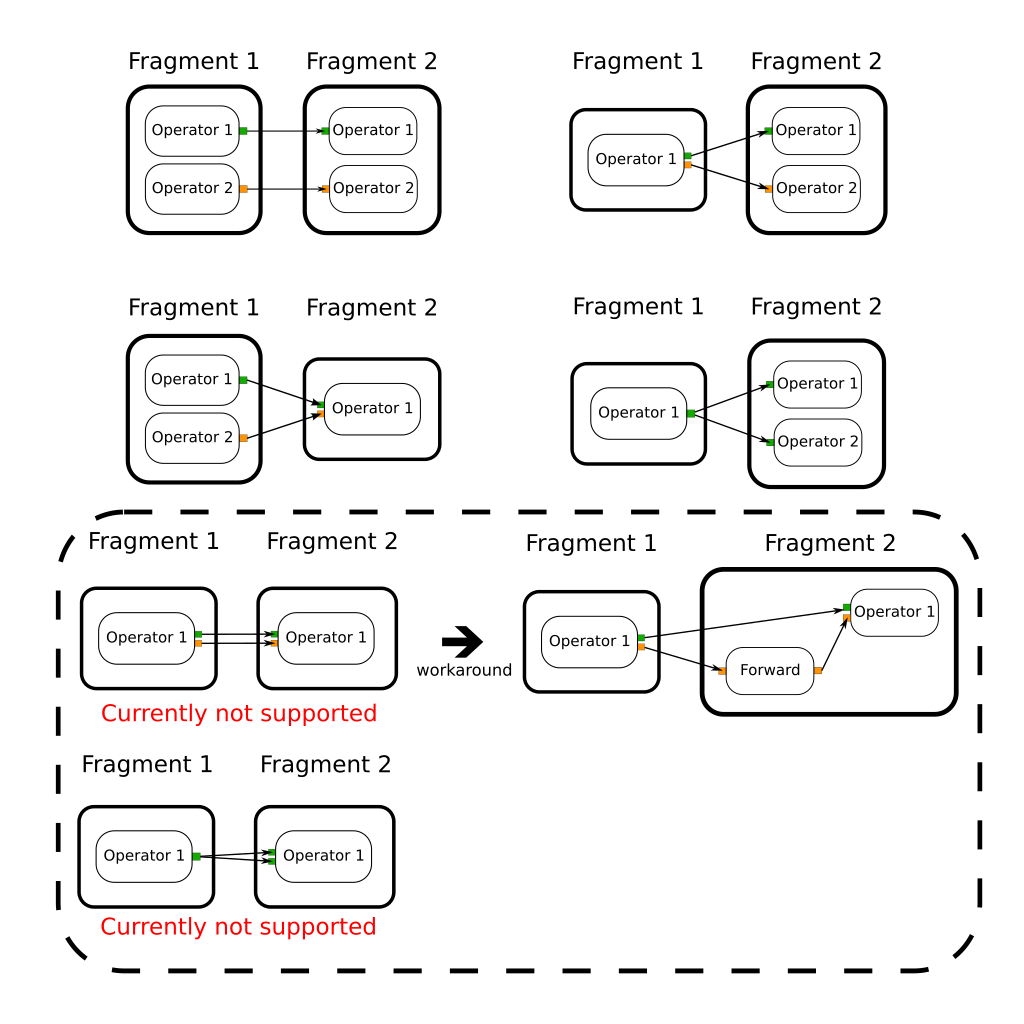
Fig. 15 Illustration of a non-working scenario: Multiple input/output ports are connected between two operators in different fragments.
The distributed application test cases shows examples of working and non-working scenarios. (ForwardedTwoMultiInputsOutputsFragmentsApp shows the workaround for this limitation.)
4. GPU tensors can only currently be sent/received by UCX from device 0.
Because the device ID associated with the network context is currently hardcoded in the executor code, GPU tensors can only be sent/received between fragments from device 0.
Given a CMake project, a pre-built executable, or a python application, you can also use the Holoscan CLI to package and run your Holoscan application in a OCI-compliant container image.
Environment Variables for Distributed Applications
Holoscan SDK environment variables.
Environment variables can be set to override the default behavior of the scheduler used when running a distributed application.
HOLOSCAN_DISTRIBUTED_APP_SCHEDULER : controls which scheduler is used for distributed applications. It can be set to either
greedyormultithread. If unspecified, the default scheduler isgreedy.HOLOSCAN_STOP_ON_DEADLOCK : can be used in combination with
HOLOSCAN_DISTRIBUTED_APP_SCHEDULERto control whether or not the application will automatically stop on deadlock. Values of “True”, “1” or “ON” will be interpreted as true (enable stop on deadlock). It is true if unspecified. This environment variable is only used whenHOLOSCAN_DISTRIBUTED_APP_SCHEDULERis explicitly set.HOLOSCAN_STOP_ON_DEADLOCK_TIMEOUT : controls the delay (in ms) without activity required before an application is considered to be in deadlock. It must be an integer value (units are ms).
HOLOSCAN_MAX_DURATION_MS : sets the application to automatically terminate after the requested maximum duration (in ms) has elapsed. It must be an integer value (units are ms). This environment variable is only used when
HOLOSCAN_DISTRIBUTED_APP_SCHEDULERis explicitly set.HOLOSCAN_CHECK_RECESSION_PERIOD_MS : controls how long (in ms) the scheduler waits before re-checking the status of operators in an application. It must be a floating point value (units are ms). This environment variable is only used when
HOLOSCAN_DISTRIBUTED_APP_SCHEDULERis explicitly set.HOLOSCAN_UCX_SERIALIZATION_BUFFER_SIZE : can be used to override the default 7 kB serialization buffer size. This should typically not be needed as tensor types store only a small header in this buffer to avoid explicitly making a copy of their data. However, other data types do get directly copied to the serialization buffer and in some cases it may be necessary to increase it.
UCX-specific environment variables
Transmission of data between fragments of a multi-fragment application is done via the Unified Communications X (UCX) library, a point-to-point communication framework designed to utilize the best available hardware resources (shared memory, TCP, GPUDirect RDMA, etc). UCX has many parameters that can be controlled via environment variables. A few that are particularly relevant to Holoscan SDK distributed applications are listed below:
The
UCX_TLSenvironment variable can be used to control which transport layers are enabled. By default,UCX_TLS=alland UCX will attempt to choose the optimal transport layer automatically.The
UCX_NET_DEVICESenvironment variable is by default set toallmeaning that UCX may choose to use any available network interface controller (NIC). In some cases it may be necessary to restrict UCX to a specific device or set of devices, which can be done by settingUCX_NET_DEVICESto a comma separated list of the device names (i.e. as obtained by linux commandifconfig -aorip link show).Setting
UCX_TCP_CM_REUSEADDR=yis recommended to enable ports to be reused without having to wait the full socket TIME_WAIT period after a socket is closed.The
UCX_LOG_LEVELenvironment variable can be used to control the logging level of UCX. The default is setting is WARN, but changing to a lower level such as INFO will provide more verbose output on which transports and devices are being used.By default, Holoscan SDK will automatically set
UCX_PROTO_ENABLE=yupon application launch to enable the newer “v2” UCX protocols. If for some reason, the older v1 protocols are needed, one can setUCX_PROTO_ENABLE=nin the environment to override this setting. When the v2 protocols are enabled, one can optionally setUCX_PROTO_INFO=yto enable detailed logging of what protocols are being used at runtime.
A list of all available UCX environment variables and a brief description of each can be obtained by running ucx_info -f from the Holoscan SDK container. Holoscan SDK uses UCX’s active message (AM) protocols, so environment variables related to other protocols such as tag-mat
Distributed applications must serialize any objects that are to be sent between the fragments of a multi-fragment application. Serialization involves binary serialization to a buffer that will be sent from one fragment to another via the Unified Communications X (UCX) library. For tensor types (e.g. holoscan::Tensor), no actual copy is made, but instead transmission is done directly from the original tensor’s data and only a small amount of header information is copied to the serialization buffer.
A table of the types that have codecs pre-registered so that they can be serialized between fragments using Holoscan SDK is given below.
Type Class |
Specific Types |
|---|---|
| integers | int8_t, int16_t, int32_t, int64_t, uint8_t, uint16_t, uint32_t, uint64_t |
| floating point | float, double, complex |
| boolean | bool |
| strings | std::string |
| std::vector |
T is std::string or any of the boolean, integer or floating point types above |
| std::vector |
T is std::string or any of the boolean, integer or floating point types above |
| std::vector |
a vector of InputSpec objects that are specific to HolovizOp |
| std::shared_ptr<%> | T is any of the scalar, vector or std::string types above |
| tensor types | holoscan::Tensor, nvidia::gxf::Tensor, nvidia::gxf::VideoBuffer, nvidia::gxf::AudioBuffer |
| GXF-specific types | nvidia::gxf::TimeStamp, nvidia::gxf::EndOfStream |
Python
For the Python API, any array-like object supporting the DLPack interface, __array_interface__ or __cuda_array_interface__ will be transmitted using Tensor serialization. This is done to avoid data copies for performance reasons. Objects of type list[holoscan.HolovizOp.InputSpec] will be sent using the underlying C++ serializer for std::vector<HolovizOp::InputSpec>. All other Python objects will be serialized to/from a std::string using the cloudpickle library. One restriction imposed by the use of cloudpickle is that all fragments in a distributed application must be running the same Python version.
C++
For any additional C++ classes that need to be serialized for transmission between fragments in a distributed application, the user must create their own codec and register it with the Holoscan SDK framework. As a concrete example, suppose that we had the following simple Coordinate class that we wish to send between fragments.
struct Coordinate {
float x;
float y;
float z;
};
To create a codec capable of serializing and deserializing this type one should define a holoscan::codec class for it as shown below.
#include "holoscan/core/codec_registry.hpp"
#include "holoscan/core/errors.hpp"
#include "holoscan/core/expected.hpp"
namespace holoscan {
template <>
struct codec<Coordinate> {
static expected<size_t, RuntimeError> serialize(const Coordinate& value, Endpoint* endpoint) {
return serialize_trivial_type<Coordinate>(value, endpoint);
}
static expected<Coordinate, RuntimeError> deserialize(Endpoint* endpoint) {
return deserialize_trivial_type<Coordinate>(endpoint);
}
};
} // namespace holoscan
where the first argument to serialize is a const reference to the type to be serialized and the return value is an expected containing the number of bytes that were serialized. The deserialize method returns an expected containing the deserialized object. The Endpoint class is a base class representing the serialization endpoint (For distributed applications, the actual endpoint class used is UcxSerializationBuffer).
The helper functions serialize_trivial_type (deserialize_trivial_type) can be used to serialize (deserialize) any plain-old-data (POD) type. Specifically, POD types can be serialized by just copying sizeof(Type) bytes to/from the endpoint. The read_trivial_type() and ~holoscan::Endpoint::write_trivial_type methods could be used directly instead.
template <>
struct codec<Coordinate> {
static expected<size_t, RuntimeError> serialize(const Coordinate& value, Endpoint* endpoint) {
return endpoint->write_trivial_type(&value);
}
static expected<Coordinate, RuntimeError> deserialize(Endpoint* endpoint) {
Coordinate encoded;
auto maybe_value = endpoint->read_trivial_type(&encoded);
if (!maybe_value) { return forward_error(maybe_value); }
return encoded;
}
};
In practice, one would not actually need to define codec<Coordinate> at all since Coordinate is a trivially serializable type and the existing codec treats any types for which there is not a template specialization as a trivially serializable type. It is, however, still necessary to register the codec type with the CodecRegistry as described below.
For non-trivial types, one will likely also need to use the read() and write() methods to implement the codec. Example use of these for the built-in codecs can be found in holoscan/core/codecs.hpp.
Once such a codec has been defined, the remaining step is to register it with the static CodecRegistry class. This will make the UCX-based classes used by distributed applications aware of the existence of a codec for serialization of this object type. If the type is specific to a particular operator, then one can register it via the register_codec() class.
#include "holoscan/core/codec_registry.hpp"
namespace holoscan::ops {
void MyCoordinateOperator::initialize() {
register_codec<Coordinate>("Coordinate");
// ...
// parent class initialize() call must be after the argument additions above
Operator::initialize();
}
} // namespace holoscan::ops
Here, the argument provided to register_codec is the name the registry will use for the codec. This name will be serialized in the message header so that the deserializer knows which deserialization function to use on the received data. In this example, we chose a name that matches the class name, but that is not a requirement. If the name matches one that is already present in the CodecRegistry class, then any existing codec under that name will be replaced by the newly registered one.
It is also possible to directly register the type outside of the context of initialize() by directly retrieving the static instance of the codec registry as follows.
namespace holoscan {
CodecRegistry::get_instance().add_codec<Coordinate>("Coordinate");
} // namespace holoscan