Step #3: Dataset Creation (Download from Internet)
If the dataset you’re looking to use in Base Command isn’t already available on your local system, or would be more quickly transferred from elsewhere on the internet than from your own personal workstation, downloading the dataset from the internet in a job, saving the data to a result directory, and converting the result directory to a dataset is a great option.
First, on a system that is already authenticated to use your target environment, run this batch job - it uses the smallest available instance in this particular ACE to wget the target data (in this case, linux kernel source), un-tar the data, and delete the source tar.xz file. Remember, datasets are read-only - so it’s important to get the data in the exact form you want it to be in for future use, and remove any data you don’t want to preserve.
$ ngc batch run --name "download-the-linux-kernel-to-result-dir" --preempt RUNONCE --min-timeslice 1s --total-runtime 0s --instance dgxa100.80g.1.norm --commandline "cd /results; wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.17.3.tar.xz; tar -xvf linux-5.17.3.tar.xz; rm -rf linux-5.17.3.tar.xz" --result /results --image "nvidia/pytorch:22.04-py3"
--------------------------------------------------
Job Information
Id: 2818455
Name: download-the-linux-kernel-to-result-dir
Number of Replicas: 1
Job Type: BATCH
Submitted By: Joseph Handzik
Job Container Information
Docker Image URL: nvidia/pytorch:22.04-py3
Job Commands
Command: cd /results; wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.17.3.tar.xz; tar -xvf linux-5.17.3.tar.xz; rm -rf linux-5.17.3.tar.xz
Dockerfile Image Entrypoint: False
Datasets, Workspaces and Results
Result Mount Point: /results
Job Resources
Instance Type: dgxa100.80g.1.norm
Instance Details: 1 GPU, 30 CPU, 244 GB System Memory
ACE: nv-launchpad-bc-sjc-ace
Team: nvbc-tme
Job Status
Created at: 2022-04-18 19:13:54 UTC
Status: STARTING
Status Type: OK
Preempt Class: RUNONCE
Minimum Timeslice: 01S
--------------------------------------------------
To check on the job’s status from the command line, run ngc batch info <job id> - in the output above under the Job Information section, the Id value is 2818455:
$ ngc batch info 2818455
--------------------------------------------------
Job Information
Id: 2818455
Name: download-the-linux-kernel-to-result-dir
Number of Replicas: 1
Job Type: BATCH
Submitted By: Joseph Handzik
Job Container Information
Docker Image URL: nvidia/pytorch:22.04-py3
Container name: 0367882ff645d349a97f9fcf56e33b25bbf473907878d2797e575a0560fc7665
Job Commands
Command: cd /results; wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.17.3.tar.xz; tar -xvf linux-5.17.3.tar.xz; rm -rf linux-5.17.3.tar.xz
Dockerfile Image Entrypoint: False
Datasets, Workspaces and Results
Result Mount Point: /results
Job Resources
Instance Type: dgxa100.80g.1.norm
Instance Details: 1 GPU, 30 CPU, 244 GB System Memory
ACE: nv-launchpad-bc-sjc-ace
Team: nvbc-tme
Job Status
Created at: 2022-04-18 19:13:54 UTC
Started at: 2022-04-18 19:14:07 UTC
Ended at: 2022-04-18 19:15:53 UTC
Duration: 01M46S
Status: FINISHED_SUCCESS
Status Type: OK
Preempt Class: RUNONCE
Minimum Timeslice: 01S
--------------------------------------------------
With a Status of FINISHED_SUCCESS, we can convert the /results directory’s contents into a dataset by using the ngc dataset convert command, which relies on the same job id value.
$ ngc dataset convert --from-result 2818455 linux-kernel-from-cli
Dataset with ID: '99164' created in ACE: 'nv-launchpad-bc-sjc-ace'.
We can now list out datasets that your account owns, which will include the new dataset just created from the previous job result (look for linux-kernel-from-cli).
$ ngc dataset list –-owned
+-------------------+------------+---------------+-------------+------------------+--------+----------+-----------+--------------+-------+---------+
| Id | Integer Id | Name | Description | ACE | Shared | Size | Status | Created Date | Owned | Pre-pop |
+-------------------+------------+---------------+-------------+------------------+--------+----------+-----------+--------------+-------+---------+
| cHCMiESgRVeduwq8v | 99164 | linux-kernel- | | nv-launchpad-bc- | No | 1.03 GB | COMPLETED | 2022-04-18 | Yes | No |
| FfIRQ | | from-cli | | sjc-ace | | | | 21:11:38 UTC | | |
+-------------------+------------+---------------+-------------+------------------+--------+----------+-----------+--------------+-------+---------+
To create the same dataset using the Web UI instead, navigate to the Jobs link in the Base Command section of the NGC navigation pane.
Click on the Create Job button at the top of the Jobs page.

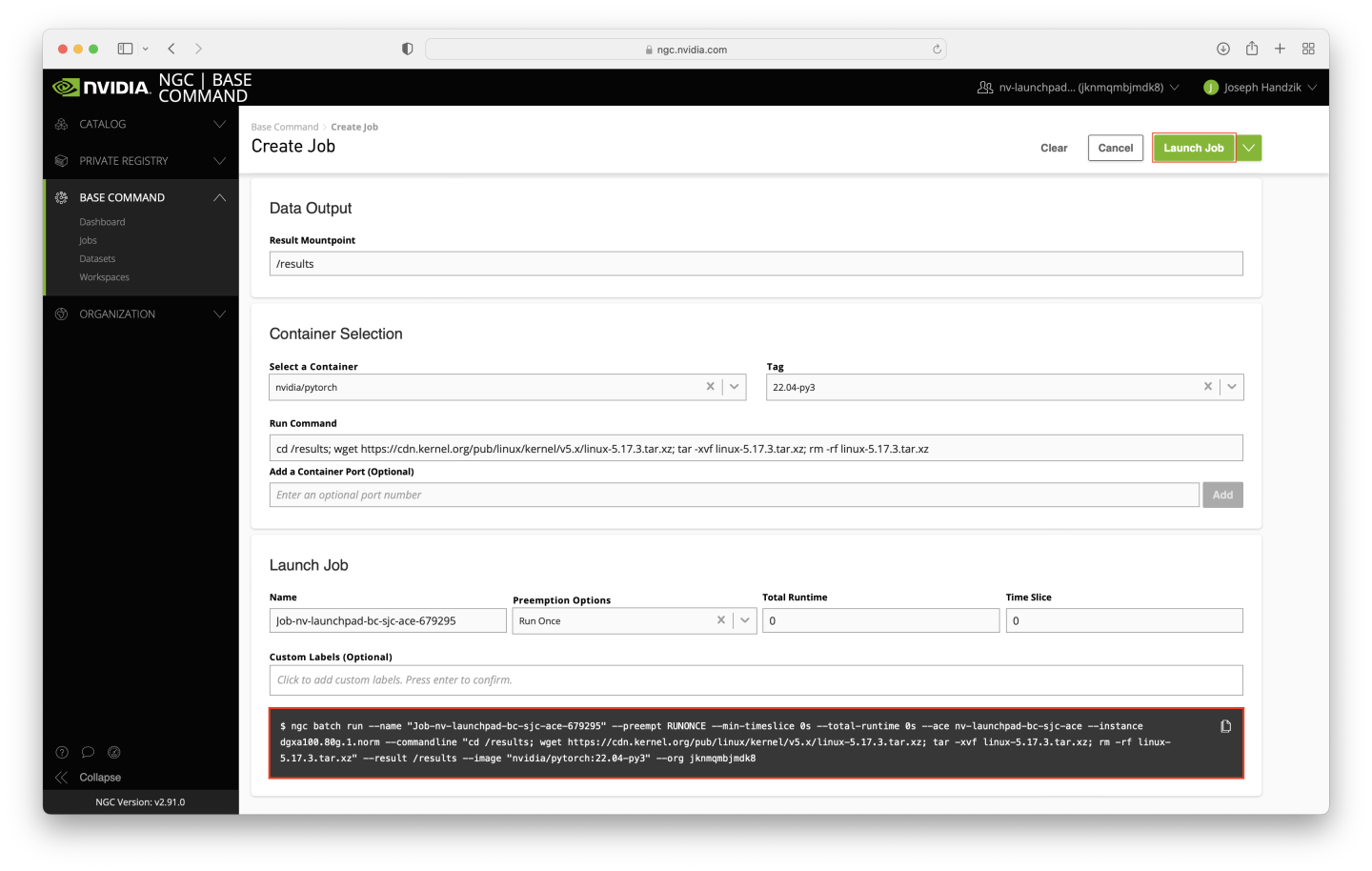
Populate the Create Job web form, using the following values (for any entries that are skipped, leave the default values as you find them):
Select your ACE from the list.
Select dgxa100.80g.1.norm in the INSTANCE table.
Ignore the Datasets and Workspaces input tables for now.
Enter
/resultsfor the Data Output field.Select the
nvidia/pytorchcontainer.Select the tag value of
22.04-py3.For the command, copy the following:
cd /results; wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.17.3.tar.xz; tar -xvf linux-5.17.3.tar.xz; rm -rf linux-5.17.3.tar.xz
The remainder of the form can be left with the default values.
To verify that the correct options were selected, check the ngc batch run command on your screen with the values in the screenshot below (the --name argument will differ, and --ace and --org arguments may differ too). When ready, click the Launch Job button near the top right corner of the page.
To view workspaces, navigate to the Workspaces link underneath the Base Command menu.
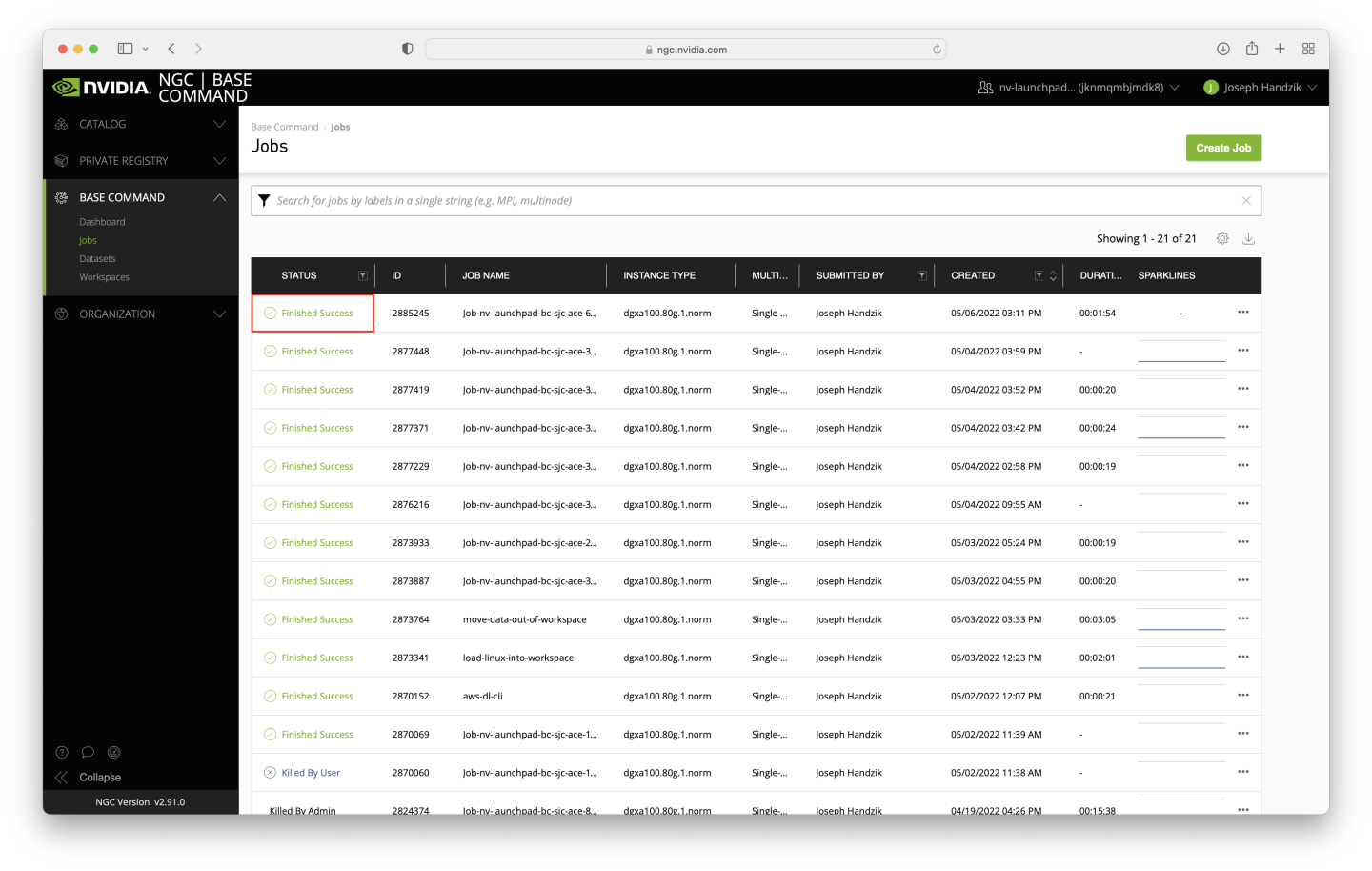
The job shouldn’t take long to run - around 5 minutes assuming the ACE is relatively idle. You may need to refresh the page to verify that the job status is Finished Success.
Click on the newly-completed job, and navigate to the Results tab to verify that the downloaded data has been successfully extracted. The presence of the joblog.log file is expected - it will become a part of the dataset, but is ignorable when reusing the dataset.
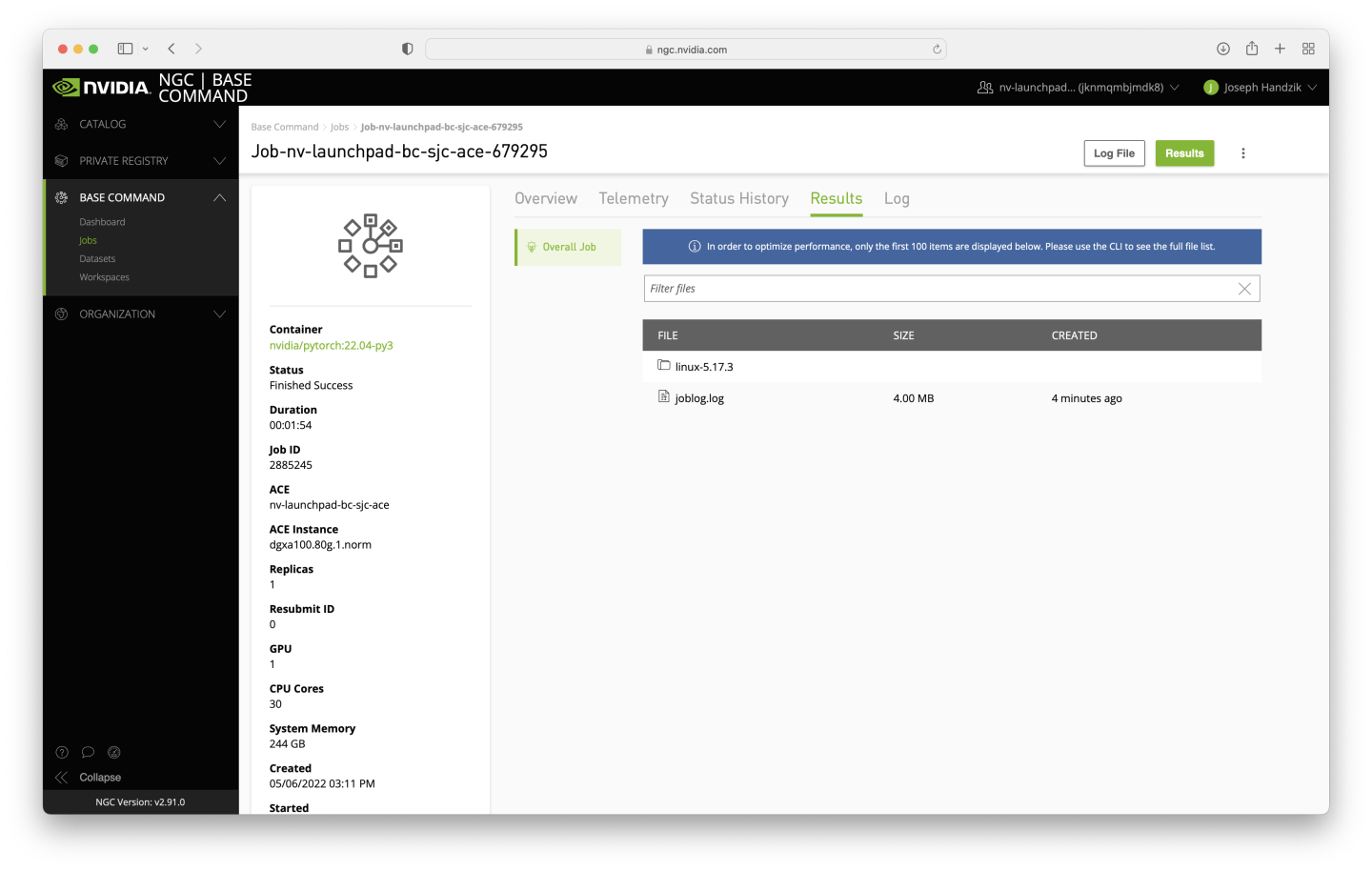
To convert the results directory to a dataset, click on the vertical ellipsis near the top right corner of the page and click the Convert Results button.
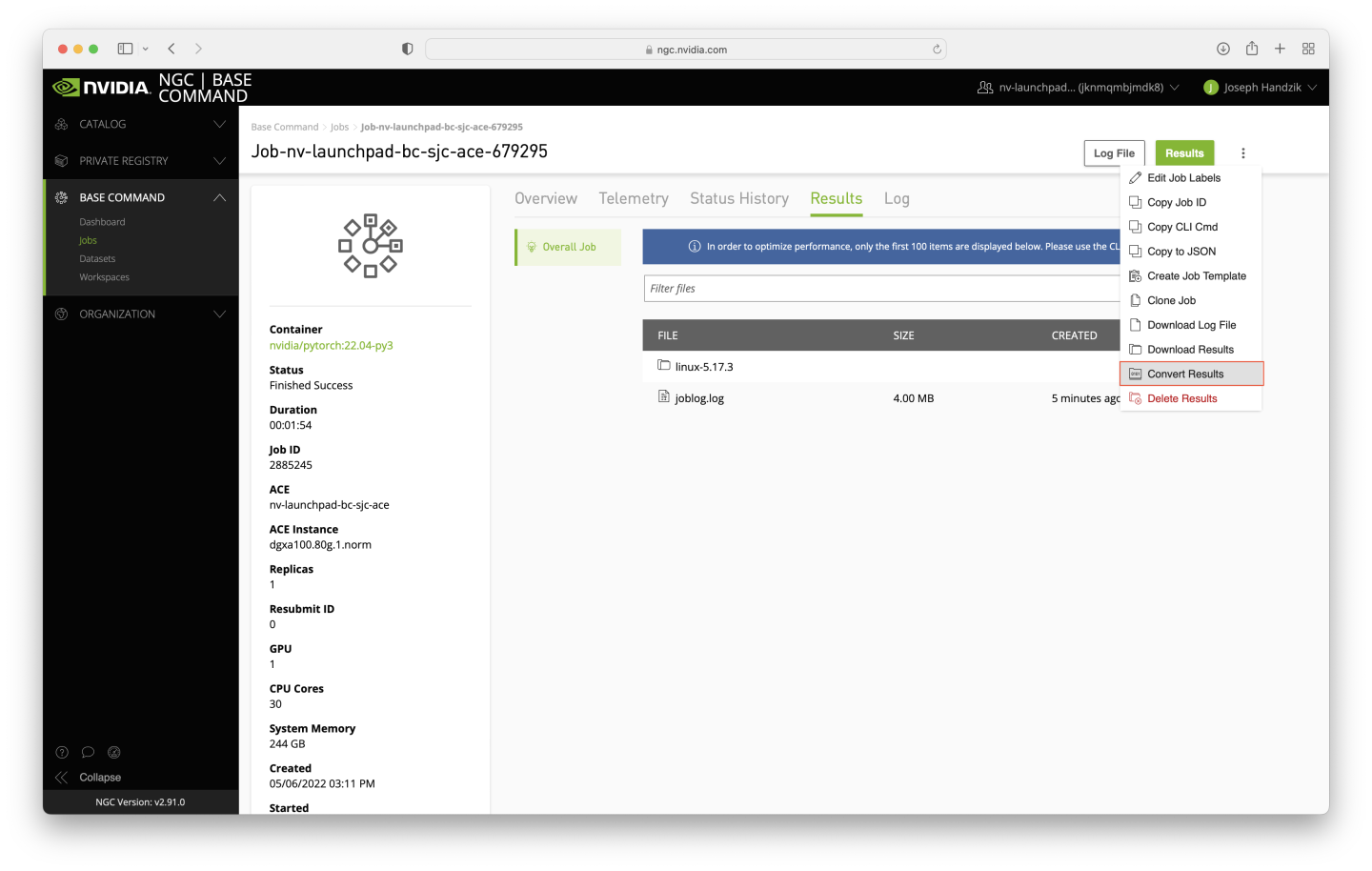
A dialog box will appear - enter linux-kernel-from-web-ui in the Name field, and click the Convert button.
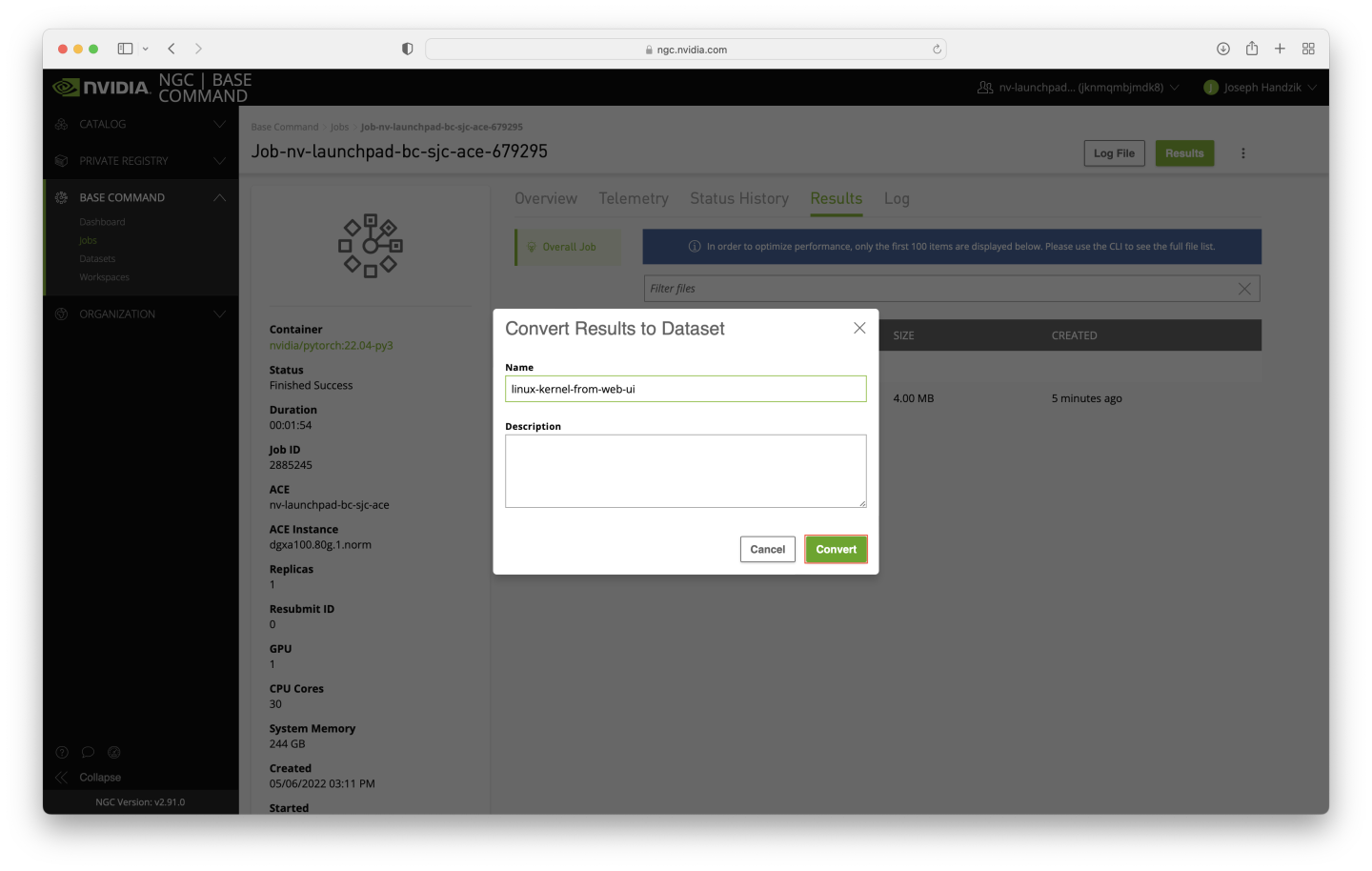
After a short period of time, the Results directory for the job used to create the dataset will become empty, which indicates the dataset conversion has been executed. Click the Datasets link in the navigation pane, just below the Jobs link that has been previously used.

The new dataset should be present in the table on the Datasets page on the top data row.
