BruteForceMatcher#
Overview#
The Brute Force Matcher [1] finds optimal matches between two sets of BRIEF (Binary Robust Independent Elementary Features) descriptors [2]. These sets are the query descriptor and reference descriptor. Optimal matching means finding the minimum Hamming distance between descriptors. The output is the index of the best matched reference descriptor(s) for each query descriptor and the corresponding Hamming distance.
The Brute Force Matcher operates in two modes: cross check and non-cross check. When cross check is disabled, it outputs a configured number of best matches for each query descriptor. When cross check is enabled, a match is valid only if query descriptor i best matches reference descriptor j and reference descriptor j best matches query descriptor i. Invalid matches are indicated with a reference index of -1.
Design Requirements#
BRIEF descriptor size is fixed at 256 bits.
Distance metric is Hamming distance.
Cross check can be enabled or disabled. When disabled, up to 3 matches per query can be configured.
Both query and reference descriptor sizes are limited to 1024, allowing storage in one VMEM super bank.
Implementation Details#
Sort Metric#
Hamming distance is calculated by XORing the query and reference descriptors and counting the number of 1s in the result. When distances are equal, the entry with the smaller index ranks higher. Two implementation approaches are possible:
Traverse the array to find the minimum distance, then traverse again to find the first element with this distance.
Create a combined array of type
uint32_twith distance in the high 16 bits and index in the low 16 bits, then find the minimum element in a single traversal. 16-bit is sufficient to store the distance since the maximum value of Hamming distance is 256. 16-bit is also sufficient to store the index since the maximum number of reference descriptor is 1024.
Both two above approaches have the same complexity of O(n) where n is the number of descriptors. Experiment results show that the second approach is faster, so it is used in the current implementation.
Tiling Method#
Both query and reference descriptors are transferred from DRAM to VMEM using sequence dataflow. The maximum descriptor size of 1024 results in 32KB. With 10GB/s DMA bandwidth, transferring one set of descriptors takes approximately 3.3 μs, which is negligible compared to the VPU’s compute time.
When cross check is disabled, tiling query descriptors is possible but provides no performance benefit since the entire reference descriptors must be transferred to VMEM. When cross check is enabled, tiling either descriptor set requires an iterative algorithm, as each output needs both complete descriptor sets.
Output tiling experiments show no performance benefits. In the non-cross check case, the overhead from extra trigger/sync operations outweigh the benefits. For cross check mode, output tiling has a negative performance impact since distances are calculated across all descriptors before producing outputs. Thus, the current implementation does not use output tiling.
VPU computation occurs in tiles for efficiency, even though inputs and outputs are transmitted once between DRAM and VMEM.
When cross check is disabled, processing one output at a time doesn’t fully utilize VLIW compute slots. The implementation calculates distances and finds minimums for groups of 2 query descriptors across all reference descriptors, with the latter rounded to multiples of 16 to match SIMD width. Special code paths handle cases when query descriptors aren’t multiples of 2 or reference descriptors aren’t multiples of 16.
When cross-check is enabled, the ideal tile size would encompass all query and reference descriptors. However, with up to 1024 query descriptors and 1024 reference descriptors, and each distance requiring 16 bits, the resulting distance matrix could reach 2MB. This size exceeds VMEM capacity, necessitating a tiling approach. The implementation uses tile sizes of TILE_X=64 and TILE_Y=16, with additional buffers to track the best match index and distance for each descriptor. These buffers update iteratively when processing the inputs.
Tiling also optimizes instruction-level parallelism and avoids redundant distance calculations, since the distance between query descriptor i and reference descriptor j equals the distance between reference descriptor j and query descriptor i. The following figure illustrates the tiling method when cross check is enabled.
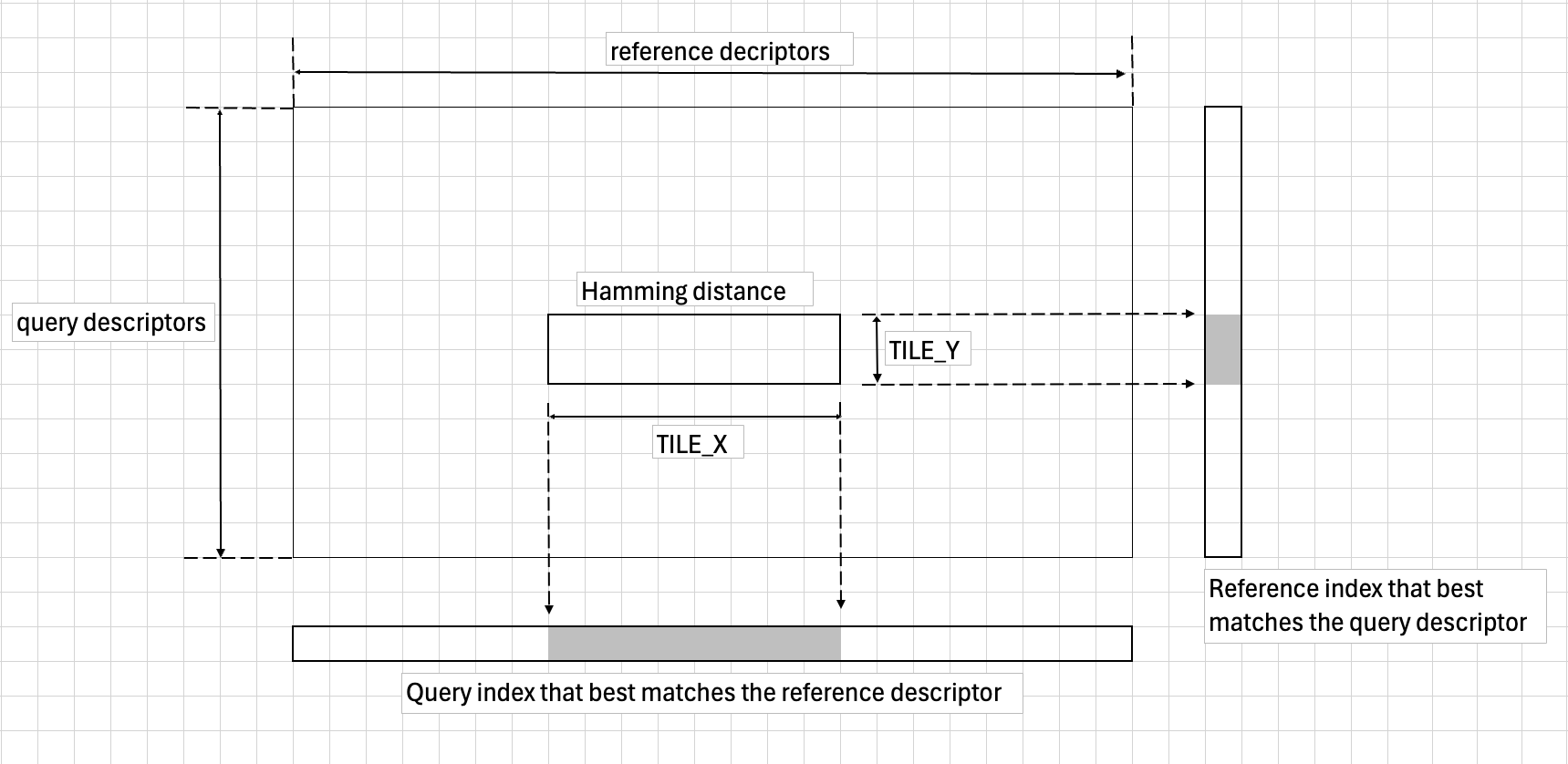
Figure 1: Brute Force Matcher Tiling Illustration#
Vectorized Finding Top-2 and Top-3 Minimum Values#
The implementation finds Top-2 and Top-3 minimum values by traversing the array once and tracking minimum values with several variables.
For Top-2 minimum values, assuming a uint32_t array with 16 elements per vector width, the algorithm produces two vector registers v0 and v1 where v0 ≤ v1 and v1 is less than or equal to all array elements (per lane comparison). Finding the actual Top-2 minimum values requires reduction: first identifying the minimum across all 16 elements, replacing that value with a large number, then finding the minimum again. The VPU intrinsics vminrid_s is used to find both the minimum value and the corresponding index. And the VPU intrinsics dvCmpLT_andL is used to merge the if-else conditions to make the code path SIMD friendly.
Performance#
Execution Time is the average time required to execute the operator on a single VPU core.
Note that each PVA contains two VPU cores, which can operate in parallel to process two streams simultaneously, or reduce execution time by approximately half by splitting the workload between the two cores.
Total Power represents the average total power consumed by the module when the operator is executed concurrently on both VPU cores.
For detailed information on interpreting the performance table below and understanding the benchmarking setup, see Performance Benchmark.
QueryCount |
ReferenceCount |
MaxMatches |
CrossCheck |
Execution Time |
Submit Latency |
Total Power |
|---|---|---|---|---|---|---|
512 |
512 |
1 |
OFF |
0.278ms |
0.013ms |
9.962W |
512 |
1024 |
1 |
OFF |
0.516ms |
0.013ms |
9.861W |
1024 |
512 |
1 |
OFF |
0.542ms |
0.013ms |
9.962W |
1024 |
1024 |
1 |
OFF |
1.017ms |
0.013ms |
9.761W |
1024 |
1024 |
1 |
ON |
1.319ms |
0.013ms |
9.861W |
1024 |
1024 |
2 |
OFF |
1.191ms |
0.013ms |
9.861W |
1024 |
1024 |
3 |
OFF |
1.438ms |
0.013ms |
9.761W |