NeVA#
Model Introduction#
Emerging from the roots of LLaVA (Large Language and Vision Assistant) [MM-MODELS2], NeVA stands as a pioneering model in the NeMo Multimodal ecosystem. It adeptly fuses large language-centric models, such as NVGPT or LLaMA, with a vision encoder. The training utilizes machine-generated multimodal language-image instruction-following data. Remarkably, even with a limited dataset, NeVA exhibits profound capabilities in deciphering images and adeptly answering queries about them. Its prowess is especially evident in tasks requiring intricate visual comprehension and instruction-following. Intriguingly, NeVA mirrors the capabilities of advanced multimodal models like GPT-4, even when faced with novel images and instructions.
Building upon LLaVA’s foundational principles, NeVA amplifies its training efficiency by harnessing the NeMo LLM framework’s features, including model parallelism, activation checkpointing, AMP O2, Flash Attention, and more.
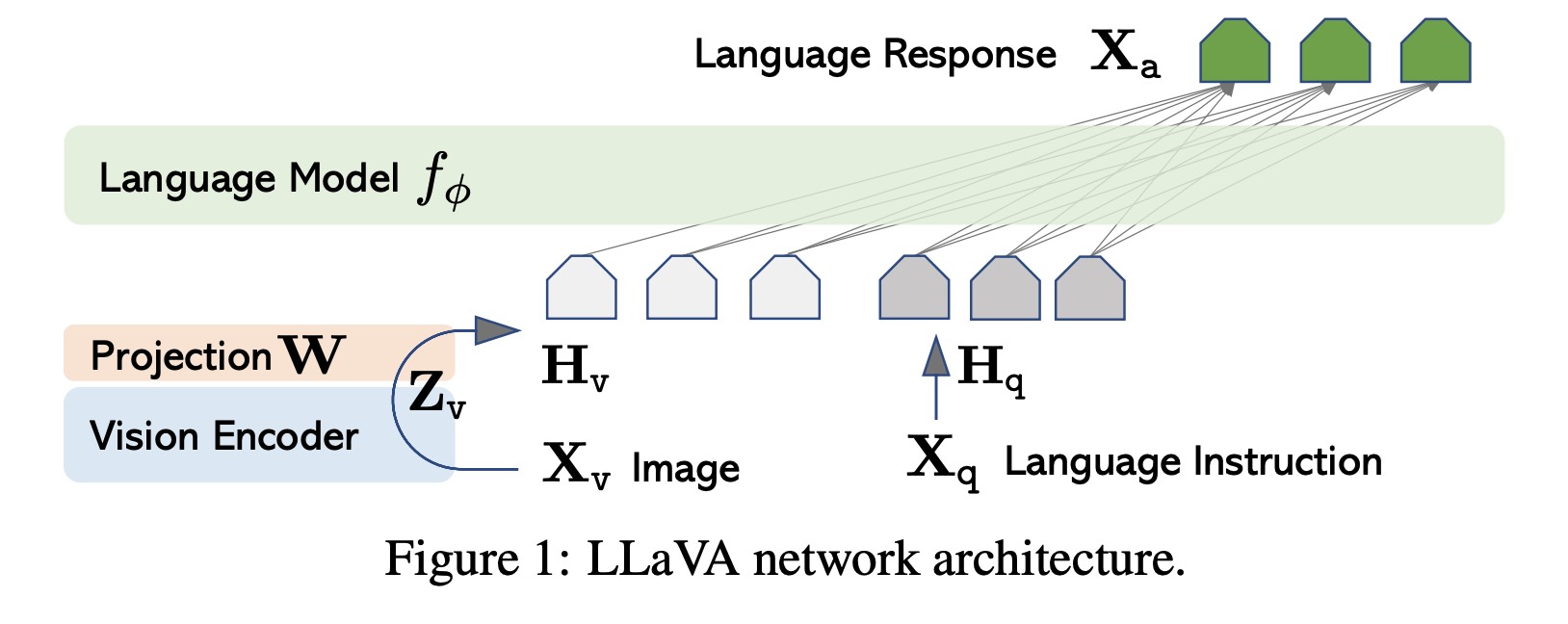
Main Language Model#
The original LLaVA model incorporates the LLaMA architecture, renowned for its prowess in open-source, language-only instruction-tuning endeavors. LLaMA refines textual input through a process of tokenization and embedding. To these token embeddings, positional embeddings are integrated, and the combined representation is channeled through multiple transformer layers. The output from the concluding transformer layer, associated with the primary token, is designated as the text representation.
In NeMo, the text encoder is anchored in the MegatronGPTModel class. This class is versatile, supporting not only NVGPT models but also LLaMA, LLaMA-2 and other community models, complete with a checkpoint conversion script. Concurrently, the vision model and projection layers enhance the primary language model’s word embedding component. For a comprehensive understanding of the implementation, one can refer to the MegatronNevaModel class.
Vision Model#
For visual interpretation, NeVA harnesses the power of the pre-trained CLIP visual encoder, ViT-L/14, recognized for its visual comprehension acumen. Images are first partitioned into standardized patches, for instance, 16x16 pixels. These patches are linearly embedded, forming a flattened vector that subsequently feeds into the transformer. The culmination of the transformer’s processing is a unified image representation. In the NeMo Framework, the NeVA vision model, anchored on the CLIP visual encoder ViT-L/14, can either be instantiated via the CLIPVisionTransformer class or initiated through the transformers package from Hugging Face.
Projection and Integration#
The encoder retrieves visual features from images and intertwines them with language embeddings using a modifiable projection matrix. This intricate projection translates visual cues into language embedding tokens, seamlessly merging text and imagery. LLaVA-1.5 [MM-MODELS1] introduces two pivotal enhancements. The integration of an MLP vision-language connector amplifies the system’s prowess. Building on the triumphs of MLPs in self-supervised learning, LLaVA-1.5 undergoes a transformative design shift. Transitioning from a linear to a dual-layer MLP projection markedly bolsters LLaVA-1.5’s multimodal faculties, empowering the model to adeptly navigate and synergize language and visual elements.
Architecture Table#
Base LLM |
Vision Encoder |
Projection |
Encoder Seq Length |
Number of Layers |
Hidden Size |
FFN Hidden Size |
Number of Attention Heads |
|---|---|---|---|---|---|---|---|
LLaMA-2-13B-Chat |
CLIP-L |
Linear |
4096 |
40 |
5120 |
13824 |
40 |
LLaMA-2-7B-Chat |
CLIP-L |
Linear |
4096 |
32 |
4096 |
11008 |
32 |
Model Configuration#
Multimodal Configuration#
mm_cfg:
use_im_start_end: False
use_im_start_end: If set to True, image start and end tokens will be used before and after image embeddings.
Language Model Configuration within Multimodal#
mm_cfg:
llm:
from_pretrained: ${data_dir}/neva/checkpoints/llama-2-13b-chat-tp8.nemo
freeze: False
model_type: llama_2
from_pretrained: Path to the pretrained NeMo language model checkpoint.freeze: If set to True, the model parameters will not be updated during training.model_type: Specifies the type of model, either nvgpt or llama_2.
Vision Encoder Configuration within Multimodal#
mm_cfg:
vision_encoder:
from_pretrained: "openai/clip-vit-large-patch14"
from_hf: True
patch_dim: 14
hidden_size: 1024
vision_select_layer: -2
class_token_length: 1
freeze: True
from_pretrained: Path or name of the pretrained vision encoder.from_hf: If set to True, the model will be loaded from the Hugging Face model hub.patch_dim: Size of the patches the image is divided into.hidden_size: Dimensionality of the hidden layers.vision_select_layer: Specifies which layer to select from the vision model.class_token_length: Length of the classification token.
Main Language Model Configuration#
mcore_gpt: False
encoder_seq_length: 4096
position_embedding_type: rope
num_layers: 40
hidden_size: 5120
ffn_hidden_size: 13824
num_attention_heads: 40
hidden_dropout: 0.0
attention_dropout: 0.0
ffn_dropout: 0.0
normalization: rmsnorm
bias: False
activation: 'fast-swiglu'
mcore_gpt: If set to True, the GPTModel from megatron.core will be used.encoder_seq_length: Sequence length for the main language model encoder.position_embedding_type: Type of position embedding used.num_layers,hidden_size,ffn_hidden_size,num_attention_heads: Parameters defining the architecture of the main language model. Theffn_hidden_sizeis typically 4 times thehidden_size.hidden_dropout,attention_dropout,ffn_dropout: Dropout probabilities for the hidden state, attention, and feed-forward layers in the transformer respectively.normalization: Type of normalization layers used.bias: If set to True, bias terms will be used in all weight matrices.activation: Activation function used in the model.
Optimizations#
Feature |
Description |
To Enable |
|---|---|---|
Data parallelism |
Dataset is read concurrently across multiple GPUs or nodes, allowing for faster data loading and processing. |
Automatically when training on multi GPUs/nodes |
Tensor parallelism |
Each tensor is split up into multiple chunks, allowing for horizontal parallelism across GPUs. This technique, known as TensorParallel (TP), distributes the model’s tensors across multiple GPUs. During processing, each shard gets processed separately and in parallel on different GPUs, and the results are synced at the end of the step. This approach is inspired by NVIDIA’s Megatron implementation. [Reference](NVIDIA/Megatron-LM) |
|
Activation Checkpointing |
To reduce memory usage, activations of certain layers are cleared and recomputed during a backward pass. This technique is particularly useful for training large models that wouldn’t fit in GPU memory using traditional methods. |
|
Selective Activation Checkpointing |
Selective granularity version of activation checkpointing. See our paper for details. [Reference](https://arxiv.org/pdf/2205.05198.pdf) |
|
Bfloat16 Training |
Training is conducted in Bfloat16 precision, which offers a balance between the higher precision of FP32 and the memory savings and speed of FP16. |
|
BF16 O2 |
Enables O2-level automatic mixed precision, optimizing Bfloat16 precision for better performance. |
|
Flash Attention V2 |
FlashAttention is a fast and memory-efficient algorithm to compute exact attention. It speeds up model training and reduces memory requirement by being IO-aware. This approach is particularly useful for large-scale models and is detailed further in the repository linked. [Reference](Dao-AILab/flash-attention) |
|
NeVA Training#
NeVA’s training encompasses two essential stages that enhance its capacity to comprehend user instructions, understand both language and visual content, and generate accurate responses:
Pre-training for Feature Alignment: In this initial stage, NeVA aligns visual and language features to ensure compatibility.
Fine-tuning End-to-End: The second training stage focuses on fine-tuning the entire model, end-to-end. While the visual encoder’s weights remain unchanged, both the projection layer’s pre-trained weights and the LLM’s parameters become subjects of adaptation. This fine-tuning can be tailored to different application scenarios, yielding versatile capabilities.
References#
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. 2023.
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. 2023. arXiv:arXiv:2304.08485.