ViT#
Model Introduction#
The Vision Transformer, commonly referred to as ViT [VISION-MODELS-VIT1], serves as a foundational model for image classification tasks in NeMo. Unlike conventional convolutional neural networks, ViT adopts a transformer-like architecture to process image data. In this approach, an image is divided into fixed-size patches, typically 14x14 or 16x16. These patches are linearly embedded and augmented with position embeddings. The resulting sequence of vectors is passed through a standard transformer encoder. In order to facilitate classification, a “classification token” that is learnable is incorporated into the sequence.
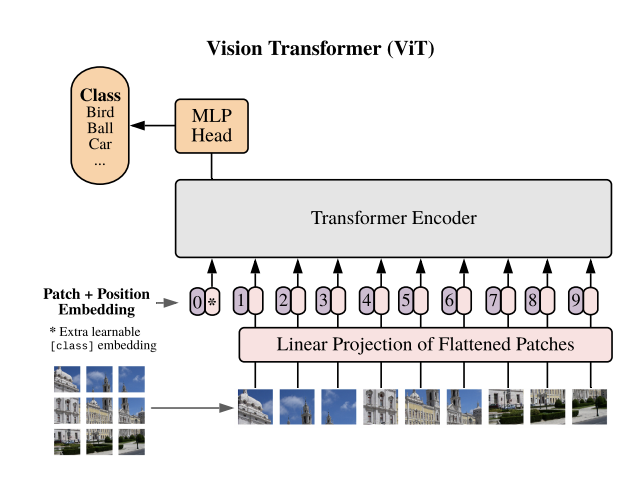
ViT models can be instantiated using the MegatronVitClassificationModel class.
Transformer Encoder#
NeMo’s implementation of the ViT model leverages its parallel transformer implementation, specifically the nemo.collections.nlp.modules.common.megatron.transformer.ParallelTransformer, to enable model parallelism support in the transformer encoder. This design choice ensures efficient scaling and utilization of resources during training.
Model |
Model size (M) |
Hidden size |
FFN_dim |
Attention heads |
Number of layers |
PatchDim |
Num Batches (Seq) |
B/16 |
86 |
768 |
3072 |
12 |
12 |
16 |
204 |
L/16 |
303 |
1024 |
4096 |
16 |
24 |
16 |
204 |
H/16 |
632 |
1280 |
5120 |
16 |
32 |
16 |
204 |
H/14 |
632 |
1280 |
5120 |
16 |
32 |
14 |
264 |
g/14 |
1011 |
1408 |
6144 |
16 |
40 |
14 |
264 |
G/14 |
1843 |
1664 |
8192 |
16 |
48 |
14 |
264 |
Model Configuration#
Transformer Encoder#
encoder_seq_length: 196
max_position_embeddings: ${.encoder_seq_length}
num_layers: 12
hidden_size: 768
ffn_hidden_size: 3072
num_attention_heads: 12
hidden_dropout: 0.1
attention_dropout: 0.
encoder_seq_length: Sequence length for the transformer encoder.num_layers,hidden_size,ffn_hidden_size,num_attention_heads: Parameters defining the architecture of the text transformer. Theffn_hidden_sizeis typically 4 times thehidden_size.hidden_dropoutandattention_dropout: Dropout probabilities for the hidden state and attention in the transformer respectively.
Patch & Positional Embedding#
vision_pretraining_type: "classify"
num_classes: 1000
patch_dim: 16
img_h: 224
img_w: 224
num_channels: 3
vision_pretraining_type: Type of MLP head, with support limited to classification tasks nownum_classes: Number of labels used for classificationpatch_dim: Size of the patches the image is divided into.img_handimg_w: Height and width of the input images.num_channels: Number of channels in the input image (e.g., 3 for RGB images).
Optimizations#
Feature |
Description |
To Enable |
|---|---|---|
Data parallelism |
Dataset is read concurrently across multiple GPUs or nodes, allowing for faster data loading and processing. |
Automatically when training on multi GPUs/nodes |
Tensor parallelism |
Each tensor is split up into multiple chunks, allowing for horizontal parallelism across GPUs. This technique, known as TensorParallel (TP), distributes the model’s tensors across multiple GPUs. During processing, each shard gets processed separately and in parallel on different GPUs, and the results are synced at the end of the step. This approach is inspired by NVIDIA’s Megatron implementation. [Reference](NVIDIA/Megatron-LM) |
|
Activation Checkpointing |
To reduce memory usage, activations of certain layers are cleared and recomputed during a backward pass. This technique is particularly useful for training large models that wouldn’t fit in GPU memory using traditional methods. |
|
Bfloat16 Training |
Training is conducted in Bfloat16 precision, which offers a balance between the higher precision of FP32 and the memory savings and speed of FP16. |
|
BF16 O2 |
Enables O2-level automatic mixed precision, optimizing Bfloat16 precision for better performance. |
|
Distributed Optimizer |
The optimization process is distributed across multiple GPUs, reducing memory requirements. This technique distributes the optimizer state across data parallel ranks, rather than replicating it, offering significant memory savings. This approach is inspired by the ZeRO optimization described in the paper “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models” and implemented in NVIDIA’s Megatron. [Reference](NVIDIA/Megatron-LM) |
|
Flash Attention V2 |
FlashAttention is a fast and memory-efficient algorithm to compute exact attention. It speeds up model training and reduces memory requirement by being IO-aware. This approach is particularly useful for large-scale models and is detailed further in the repository linked. [Reference](Dao-AILab/flash-attention) |
|
Model Training#
Below are the highlights of the training and fine-tuning recipe we used:
Model: ViT B/16
Dataset: ImageNet 1K
Pretraining:
Epochs: 300
Batch Size: 4096
Training Resolution: 224
Optimizer: Adam (0.9, 0.999)
Base Learning Rate: 3.00E-03
Learning Rate Decay: Cosine
Weight Decay: 0.3
Dropout: 0.1
Fine-tuning:
Steps: 20,000
Batch Size: 512
Fine-tuning Resolution: 512
Optimizer: SGD (0.9)
Base Learning Rate: 0.003 - 0.06
Learning Rate Decay: Cosine
Weight Decay: 0
Reference#
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. 2022. arXiv:2205.11487.