Activation Recomputation#
The input activations of network layers are stored in device memory and are used to compute gradients during back-propagation. When training a model with long sequences, large micro-batches, or heavy MoE memory pressure, these activations can quickly saturate device memory. Checkpointing some activations and recomputing the rest is a common way to trade extra compute for lower memory use.
Activation recomputation in Megatron Bridge is configured through the model
provider’s recomputation parameters, which are based on Megatron Core’s
TransformerConfig.
Quick Guidance#
As a rule of thumb:
start with selective recomputation before using full recomputation
use full recomputation only when selective recomputation still does not fit
for MoE and long-context training, prefer recomputing smaller modules such as normalization, activation, MoE-side, or model-specific up-projection work rather than recomputing the whole layer
revisit recomputation after enabling CUDA graphs, because TE-scoped graphs and full recomputation are not always compatible
Transformer Layer Recomputation#
Megatron Bridge supports transformer layer recomputation, which checkpoints the input of each transformer layer and recomputes the activations for the remaining layers. This technique significantly reduces activation memory usage. However, it also adds a large compute cost because the whole layer forward is executed again during backward.
Megatron Bridge also supports partial transformer layer recomputation, which is useful when recomputing only some layers is enough to make the model fit.
Configuration#
Transformer layer recomputation is configured through the model provider’s recomputation parameters:
from megatron.bridge.models import GPTModelProvider
# Full recomputation - recompute all layers
model_config = GPTModelProvider(
recompute_granularity="full", # Enable full layer recomputation
recompute_method="uniform", # Uniform distribution across layers
recompute_num_layers=4, # Number of layers per recomputation block
# ... other model parameters
)
Recomputation Methods#
Block Method#
Recomputes a specific number of transformer layers per pipeline stage:
model_config = GPTModelProvider(
recompute_granularity="full",
recompute_method="block", # Block-wise recomputation
recompute_num_layers=4, # Recompute 4 layers per pipeline stage
)
Uniform Method#
Uniformly divides the total number of transformer layers and recomputes input activations for each divided chunk:
model_config = GPTModelProvider(
recompute_granularity="full",
recompute_method="uniform", # Uniform distribution
recompute_num_layers=8, # Number of layers per recomputation block
)
Pipeline Parallelism Considerations#
When training with pipeline parallelism:
recompute_num_layersindicates the layers per pipeline stageWhen using virtual pipelining,
recompute_num_layersspecifies the number of layers per virtual pipeline stageThe framework automatically handles recomputation coordination across pipeline stages
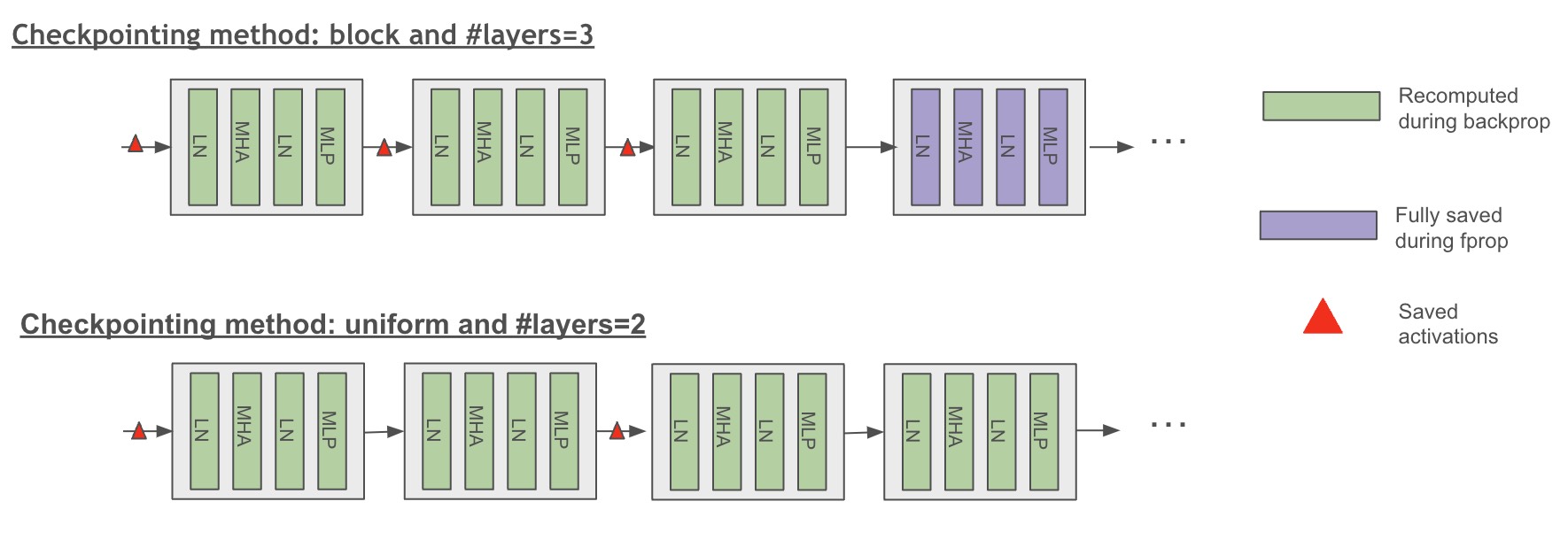 Figure 1: Scheme of uniform and block checkpointing method (full checkpointing granularity)
Figure 1: Scheme of uniform and block checkpointing method (full checkpointing granularity)
Self-attention Recomputation#
Megatron Bridge supports selective self-attention recomputation that checkpoints the inputs of each self-attention block and recomputes the intermediate input activations. This cost-efficient method achieves high memory savings with minimal recomputation cost.
The intermediate layers of the self-attention block account for a large share of activation memory because softmax, dropout, and QKV dot-product attention scale with sequence length squared. Their recomputation cost is often lower than recomputing the larger projection-heavy parts of the layer.
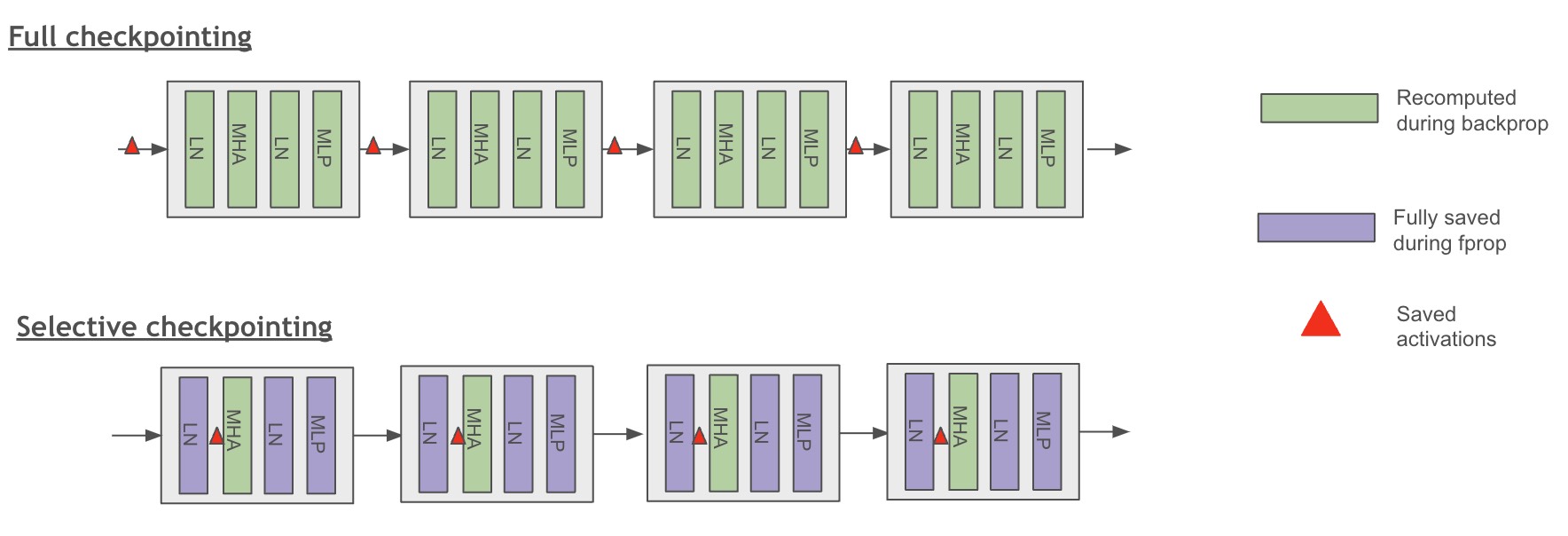 Figure 2: Scheme of full and selective checkpointing granularity
Figure 2: Scheme of full and selective checkpointing granularity
Configuration#
Self-attention recomputation is enabled using selective granularity:
from megatron.bridge.models import GPTModelProvider
model_config = GPTModelProvider(
recompute_granularity="selective", # Enable selective recomputation
recompute_modules=["core_attn"], # Recompute attention modules (default)
# ... other model parameters
)
Recomputation Modules#
Megatron Bridge supports selective recomputation for various modules:
model_config = GPTModelProvider(
recompute_granularity="selective",
recompute_modules=[
"core_attn", # Core attention computation (default)
"mlp", # MLP layers
"layernorm", # Layer normalization
"moe", # Mixture of Experts layers
"moe_act", # MoE activation functions
"shared_experts", # Shared expert layers
"mla_up_proj", # Multi-Latent Attention up projection
],
)
Flash Attention Integration#
Self-attention recomputation is automatically enabled when using Flash Attention through Transformer Engine. Flash Attention already recovers some memory by recomputing attention scores rather than storing them, so extra explicit attention recomputation is often less important than recomputing other modules.
Advanced Recomputation Configuration#
Distributed Activation Checkpointing#
For models using model parallelism, you can distribute saved activations across the model parallel group:
model_config = GPTModelProvider(
recompute_granularity="selective",
distribute_saved_activations=True, # Distribute across model parallel group
# Note: Cannot be used with sequence_parallel=True
)
Memory vs Computation Trade-offs#
Different recomputation strategies offer different memory-computation trade-offs:
Selective recomputation: Usually the best first choice. Targets the most memory-expensive operations while keeping the compute penalty relatively low.
Full recomputation: Strongest memory reduction, but also the highest compute overhead.
No recomputation: Best for throughput when the model already fits.
MoE-Specific Recomputation#
For Mixture of Experts models, specialized recomputation options are available:
model_config = GPTModelProvider(
# MoE configuration
num_moe_experts=8,
expert_model_parallel_size=2,
# MoE recomputation
recompute_granularity="selective",
recompute_modules=["moe", "moe_act"], # Recompute MoE-specific modules
)
For MoE training, it is often better to start with selective recomputation of MoE-side modules, normalization, activation functions, or model-specific up-projection modules than to enable blanket full recomputation immediately.
Feature Interactions#
TE-scoped CUDA graphs are usually paired with selective recomputation rather than full recomputation.
MoE communication overlap paths often require recomputation settings that are more selective than “full.”
At long context, recomputing SDPA-heavy attention internals can cost more than recomputing smaller supporting modules.