NeMo Megatron Bridge#
![]()
![]()
![]()

📣 News#
[07/17/2026] LongStraw (MinT-2M) is a long-context RL research system from MindLab Research that uses Megatron Bridge’s modeling and LoRA capabilities. LongStraw explores resident-prefix, response-only GRPO by capturing a shared prompt once and replaying only the trainable response branches, and reports a 2.1M-token GLM-5.2 execution path across 32 NVIDIA H20 GPUs. Learn more in the paper.
[06/22/2026] Megatron Bridge 0.5.0 released! Highlights include expanded LLM and multimodal support (Qwen3.5, DeepSeek V4, Ernie 4.5, GLM-5/4.7, StepFun Step-3.5/3.7, MiMo-V2, Gemma 4, Falcon H1, Ling MoE V2, Nemotron-3 Nano Omni, Qwen3-Omni, Qwen3-ASR, and Nemotron Diffusion), MegatronMIMO and Energon v7 training updates, evaluator backend integration, eval-time context parallelism, deterministic recipes, quantized FP8/MXFP4 export, CUDA graph/performance improvements, and Megatron Inference/tokenizer unification with Megatron-LM. Huge thanks to our community contributors: @HowardZorn, @hy2826, @bo-ke, @beccohov, @dhiaEddineRhaiem, @pavelgein, @ccclyu, @hbhflw2000, and @HollowMan6! See the full release notes.
[06/16/2026] NVIDIA topped MLPerf Training v6.0 across every benchmark, including the new DeepSeek-V3 and GPT-OSS MoE training workloads. Megatron Bridge serves as the packaging layer for the NeMo 26.06 training stack that integrates full-iteration CUDA graphs, HybridEP/router optimizations, all-to-all overlap, MXFP8 attention, and pipeline-layout balancing; the blog highlights DeepSeek-V3 training at 1,648 TFLOPS/GPU (6,338 tokens/sec/GPU) on GB300. To try related runs, start from the performance recipes; the corresponding container is expected with the NeMo 26.06 release soon.
[06/04/2026] NVIDIA Nemotron 3 Ultra is now public! Day-0 support for the 550B-A55B hybrid Mamba-Transformer MoE model is available on the
nemotron_3_ultrabranch, including checkpoint conversion, inference, SFT, PEFT (LoRA), and pretraining examples. Read the NVIDIA Technical Blog and see the examples README for the full walkthrough.[05/28/2026] Step-3.7-Flash is now merged on main! See the examples README for sft training details.
[05/26/2026] DeepSeek V4 FP8 support is now available in Megatron Bridge, including HF↔Megatron conversion, quantized checkpoint export with regenerated scale tensors, and downstream verification with Megatron-backend GRPO.
[05/20/2026] DeepSeek V4 is now merged on main! See the examples README for conversion and inference details.
[05/20/2026] Nemotron-3 Nano Omni day-0 branch support is now merged on main! The 30B-A3B MoE multimodal model supports image, video, audio, and text workflows with checkpoint conversion, inference, SFT, and PEFT (LoRA) examples. Read the NVIDIA Blog and see the examples README for the full walkthrough.
[05/19/2026] Nemotron-Labs Diffusion is now supported on main with autoregressive-to-diffusion conversion, continuous pretraining, checkpoint conversion, and inference workflows. Read the NVIDIA Research blog for the tri-mode language model overview.
[05/06/2026] Gemma 4 VL 26B-A4B is now supported! Checkpoint conversion, SFT, and PEFT (LoRA) recipes for Google’s MoE vision-language model (26B total / 4B active params, 128 experts top-k=8, dual sliding/global attention with K=V tying on full-attention layers) are available on main. See the examples README for the full walkthrough.
[04/28/2026] Day 0 support for Nemotron-3 Nano Omni, a 30B-A3B MoE multimodal model that jointly processes image, video, audio, and text. Checkpoint conversion, SFT, and LoRA recipes are available on main — see the examples README for the full walkthrough.
[04/19/2026] Qwen3.6-35B-A3B is now supported! Qwen3.6 uses the same architecture as Qwen3.5 VL MoE (
Qwen3_5MoeForConditionalGeneration) and works with the existing Qwen3.5-VL bridge out of the box — no code changes needed. HF→Megatron conversion and inference verified.[04/16/2026] Megatron Bridge 0.4.0 released! New model support (Kimi 2.5, Nemotron 3 Super, Qwen 3.5 VL, MiniMax M2, Sarvam, MiMo, and more), diffusion model collection, sequence-packing improvements, FP8 export, pruning & quantization, Transformers 5.x compatibility, and Python 3.12 migration. Huge thanks to our community contributors: @HollowMan6, @shaltielshmid, @jaeminh, @pavelgein, @ShiftyBlock, @erictang000, @eternally-z, @Hayak3, and @mohit-sarvam! See the full release notes.
[04/12/2026] MiniMax-M2.5 / M2.7 are now supported! Both models share the same architecture as MiniMax-M2 and work with the existing bridge out of the box — checkpoint conversion and inference verified on real FP8 checkpoints.
[04/10/2026] Qwen3-ASR is now supported! Checkpoint conversion and inference for Qwen3’s ASR model are available on main.
[04/09/2026] Bailing MoE V2 is now supported! Checkpoint conversion and inference for the Bailing MoE V2 model are available on main. Thank you to @ccclyu for the community contribution!
[04/07/2026] Megatron Bridge’s PEFT support was featured at PyTorch Conference Europe 2026 Talk.
[04/01/2026] Kimi K2.5 VL is now supported! Checkpoint conversion, inference, and training recipes for Moonshot AI’s Kimi-K2.5-VL vision-language model are available on main.
[03/31/2026] Agent Skills for Megatron Bridge! We’ve added a
skills/directory with structured guides that AI coding agents (Cursor, Claude Code, Codex, etc.) can use to help you add model support, set up dev environments, tune performance, and more. Try them out, and PRs to improve or add new skills are very welcome![03/26/2026] Nemotron 3 Super is now on main! Checkpoint conversion and SFT/LoRA recipes (120B-A12B) are available in the main branch. Read the blog post.
[03/12/2026] Deprecating Python 3.10 support: We’re officially dropping Python 3.10 support with the upcoming 0.4.0 release. Downstream applications must raise their lower boundary to 3.12 to stay compatible with Megatron-Bridge.
[12/16/2025] Mind Lab successfully used Megatron-bridge and VeRL to trained GRPO Lora for Trillion-parameter model on 64 H800 - See their techblog.
[12/15/2025] Day 0 support for NVIDIA-NeMotron-3-Nano-30B-A3B-FP8! Reproducible code and custom NGC container: nvcr.io/nvidia/nemo:25.11.nemotron_3_nano
Overview#
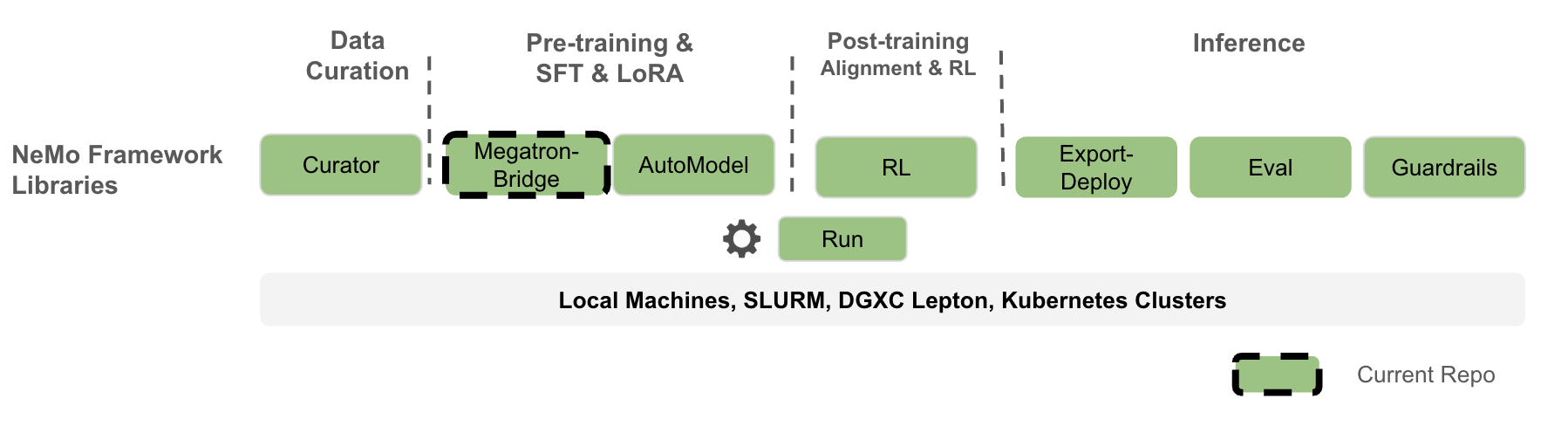
NeMo Megatron Bridge is a PyTorch-native library within the NeMo Framework that provides pretraining, SFT and LoRA for popular language, vision-language, audio, and multimodal models. It serves as a powerful bridge, conversion, and verification layer between 🤗 Hugging Face and Megatron Core. It provides bidirectional checkpoint conversion between these formats, enabling other projects to leverage Megatron Core’s parallelism capabilities or export models for various inference engines. The bridge includes built-in verification mechanisms to ensure conversion accuracy and checkpoint integrity across different model formats.
On top of the bridge, NeMo Megatron Bridge provides a performant and scalable PyTorch-native training loop that leverages Megatron Core to deliver state-of-the-art training throughput. It supports pretraining and fine-tuning with features like tensor and pipeline parallelism, and mixed precision (FP8, BF16, FP4, etc.). Users can either use existing 🤗 Hugging Face models or define custom PyTorch model definitions for flexible end-to-end workflows.
NeMo Megatron Bridge is a refactor of the previous NeMo training stack that adopts a PyTorch-native training loop to provide greater flexibility and customizability for developers.
Broad functional support matrix#
Pretrain |
SFT |
SFT LoRA |
RL |
RL LoRA |
Notes |
|
|---|---|---|---|---|---|---|
Y |
Y |
Y |
N |
N |
Megatron based pretraining library |
|
Y |
Y |
Y |
N |
N |
PyT DTensor based pretraining library |
|
N |
Y |
Y |
Y |
Y |
Post-training library with both Megatron and Automodel backends |
🔧 Installation#
🐳 NeMo Framework container#
The best experience, highest performance, and full feature support are provided by the NeMo Framework container. Fetch the most recent $TAG and run the following to start a container:
docker run --rm -it -w /workdir -v $(pwd):/workdir \
--entrypoint bash \
--gpus all \
nvcr.io/nvidia/nemo:${TAG}
For development installation and additional details, please refer to our Contribution guide.
Megatron-Core Submodule (main & dev)#
Megatron Bridge pins Megatron-Core as a git submodule at 3rdparty/Megatron-LM. The repository tracks two pinned commits — one from the upstream main branch (default) and one from dev — managed by scripts/switch_mcore.sh.
The submodule committed to the repo always points to the main commit. Use the dev commit when you need a Megatron-Core feature or fix that has not yet landed on main, or to validate forward-compatibility with upcoming MCore changes:
./scripts/switch_mcore.sh status # Show current commit
./scripts/switch_mcore.sh dev # Switch to dev; then run: uv sync
./scripts/switch_mcore.sh main # Switch back; then run: uv sync --locked
Note:
uv.lockis generated against the main commit. After switching to dev, useuv sync(without--locked). After switching back to main, useuv sync --locked.
The dev branch follows Megatron-LM’s upstream dev branch philosophy — features are experimental, follow a streamlined review process, and must graduate to stable within 6 months or be deprecated.
⚡ Quickstart#
To get started, install Megatron Bridge or download a NeMo Framework container as described above.
Log in to Hugging Face Hub:
huggingface-cli login --token <your token>
Conversion-only quickstart (✅ Core):
from megatron.bridge import AutoBridge
# 1) Create a bridge from a Hugging Face model (hub or local path)
bridge = AutoBridge.from_hf_pretrained("meta-llama/Llama-3.2-1B", trust_remote_code=True)
# 2) Get a Megatron provider and configure parallelism before instantiation
provider = bridge.to_megatron_provider()
provider.tensor_model_parallel_size = 1
provider.pipeline_model_parallel_size = 1
provider.finalize()
# 3) Materialize Megatron Core model(s)
model = provider.provide_distributed_model(wrap_with_ddp=False)
# 4a) Export Megatron → Hugging Face (full HF folder with config/tokenizer/weights)
bridge.save_hf_pretrained(model, "./hf_exports/llama32_1b")
# 4b) Or stream only weights (Megatron → HF)
for name, weight in bridge.export_hf_weights(model, cpu=True):
print(name, tuple(weight.shape))
Training quickstart using pre-configured recipes:
from megatron.bridge import AutoBridge
from megatron.bridge.recipes.llama.h100 import llama32_1b_pretrain_1gpu_h100_bf16_config
from megatron.bridge.training.gpt_step import forward_step
from megatron.bridge.training.pretrain import pretrain
if __name__ == "__main__":
# The recipe uses the Llama 3.2 1B architecture from Hugging Face.
# This is random-init pretraining and does not require a converted Megatron checkpoint.
cfg = llama32_1b_pretrain_1gpu_h100_bf16_config()
# The recipe already sets cfg.model internally using this pattern.
# Override cfg.model to choose a different Hugging Face model ID as the architecture source.
# cfg.model = AutoBridge.from_hf_pretrained("meta-llama/Llama-3.2-1B").to_megatron_provider(load_weights=False)
# Optional: use a local Hugging Face model/config directory instead.
# cfg.model = AutoBridge.from_hf_pretrained("/path/to/local/hf_model").to_megatron_provider(load_weights=False)
# Optional: initialize weights from a converted Megatron checkpoint for SFT/PEFT
# or other pretrained-weight workflows.
# cfg.checkpoint.pretrained_checkpoint = "/path/to/megatron/checkpoint"
# Override training parameters
cfg.train.train_iters = 10
cfg.scheduler.lr_decay_iters = 10000
cfg.model.vocab_size = 8192
cfg.tokenizer.vocab_size = cfg.model.vocab_size
pretrain(cfg, forward_step)
You can launch the above script with:
uv run python -m torch.distributed.run --nproc-per-node=<num devices> /path/to/script.py
HF → Megatron conversion is workflow-specific. Use it when you need pretrained HF weights as a Megatron checkpoint,
such as for finetuning from converted weights or for checkpoint round-trip workflows. It is not required for
random-init pretraining from an HF architecture, where AutoBridge.from_hf_pretrained(...).to_megatron_provider(load_weights=False)
only reads the architecture configuration.
For runnable recipe, data preparation, and training examples, see the repository
tutorials/ directory.
The data tutorial index compares pretraining, text-only SFT, direct Hugging Face SFT, and Energon workflows.
More examples:
For a deeper dive into conversion design and advanced usage, see the models README.
🚀 Key Features#
Bridge with 🤗 Hugging Face: Seamless bidirectional conversion between 🤗 Hugging Face and Megatron formats for interoperability (model bridges, auto bridge, conversion examples)
Online import/export without intermediate full checkpoints
Parallelism-aware (TP/PP/VPP/CP/EP/ETP) during conversion
Memory-efficient per-parameter streaming
Simple high-level
AutoBridgeAPI with architecture auto-detectionOptimized paths when Transformer Engine is available
Flexible to Customize: Lightweight custom training loop making it easy to configure custom logic in data loading, distributed training, checkpointing, evaluation and logging (training framework, training utilities)
Supervised & Parameter-Efficient Finetuning: SFT & PEFT implementation tailored for Megatron-based models that supports LoRA, DoRA, and user-defined PEFT methods (PEFT implementations, finetune module, SFT dataset)
SOTA Training Recipes: Pre-configured production-ready training recipes for popular models like Llama 3, with optimized hyperparameters and distributed training configuration (Llama recipes, recipe examples)
Performance Optimization: Built-in support for FP8 training, model parallelism, and memory-efficient techniques to offer high utilization and near-linear scalability to thousands of nodes. (mixed precision, communication overlap, optimizer utilities)
Supported Models#
Megatron Bridge provides out-of-the-box bridges and training recipes for a wide range of models, built on top of base model architectures from Megatron Core. Refer to the models directory for the full list of model bridges.
Family |
Supported variants |
|---|---|
Ling 2.0 / Ling MoE V2 (Bailing) |
|
DeepSeek V2 / V2 Lite, DeepSeek V3, DeepSeek V4 / V4 Flash |
|
FLUX, LLaDA 1.5, Nemotron-Labs Diffusion, WAN |
|
Ernie |
|
Falcon H1 |
|
Gemma / Gemma 2, Gemma 3, Gemma 3-VL, Gemma 4 (26B-A4B MoE / 31B dense), Gemma 4-VL (26B-A4B MoE) |
|
GLM-4.5 / 4.7 / 4.7-Flash, GLM-4.5V, GLM-5 / 5.1 |
|
GPT-oss |
|
Hy3 preview-Base (HF → Megatron checkpoint conversion) |
|
Kimi K2, Kimi-K2.5-VL |
|
Llama 2, Llama 3 / 3.1 / 3.2 / 3.3 |
|
MiniMax-M2 / M2.5 / M2.7 |
|
Mistral, Ministral 3 (3B/8B/14B) |
|
Xiaomi-MiMo, MiMo-V2-Flash |
|
Moonlight |
|
Nemotron H, Nemotron Nano v2, Nemotron-3 Nano, Nemotron-3 Super, Llama Nemotron, Nemotron Nano v2 VL, Nemotron-3 Nano Omni |
|
OLMoE |
|
Qwen2 / Qwen2.5, Qwen3, Qwen3-MoE, Qwen3 Next, Qwen3.5 (dense/MoE), Qwen2.5-VL, Qwen3-VL, Qwen3.5-VL, Qwen3.6-VL, Qwen2 Audio, Qwen2.5-Omni, Qwen3-Omni, Qwen3-ASR |
|
Sarvam |
|
Step-3.5-Flash, Step-3.7-Flash |
Launching Recipes#
For a conceptual overview of how recipes are structured, overridden, and launched with either torchrun or NeMo-Run, read the Using Recipes guide.
Runnable tutorials live in tutorials/recipes/llama that covers:
00_quickstart_pretrain.pyfor mock-data pretraining01_quickstart_finetune.py+ LoRA configsYAML-driven flows and launch helpers
Dataset preparation tutorials live in tutorials/data, including local/materialized text-only SFT and direct Hugging Face SFT examples.
Performance Benchmarks#
For detailed performance benchmarks including throughput metrics across different GPU systems (DGX-GB200, DGX-B200, DGX-H100) and model configurations, see the Performance Summary in our documentation.
Project Structure#
Megatron-Bridge/
├── examples/
│ ├── models/ # Bridge usage examples
│ └── recipes/ # Training examples
├── src/megatron/bridge/
│ ├── data/ # Dataloaders and iterators
│ ├── models/ # Hugging Face bridge infrastructure and model-specific implementations
│ │ ├── llama/ # Llama model providers
│ │ └── .../ # Other models (gpt, t5, etc.)
│ ├── peft/ # PEFT transformations and wrappers
│ ├── recipes/ # Complete training recipes
│ ├── training/ # Training loop components
│ │ ├── tokenizers/ # Tokenizer library
│ │ └── utils/ # Training-specific utilities
│ └── utils/ # Generic utilities for repo-wide usage
└── tests/ # Comprehensive test suite
Acknowledgement & Contributing#
Megatron-Bridge is the continuation of MBridge by Yan Bai. We appreciate all the contribution and adoptions by the community partners:
Mind Lab successfully used Megatron-bridge and VeRL to trained GRPO Lora for Trillion-parameter model on 64 H800 - See their techblog.
VeRL has adopted Megatron-Bridge as a connector to Megatron-Core and for LoRA support.
Slime has adopted Megatron-Bridge as Megatron-Core checkpoint converter.
SkyRL has adopted Megatron-Bridge as Megatron-Core connector.
Nemo-RL has adopted Megatron-Bridge as Megatron-Core connector.
Community contributions: Special thanks to Guanyou He and Junyu Wu from Weixin Group Infrastructure Center.
Please see our Contributor Guidelines for more information on how to get involved.